I am a newbie, still a few months into my career as a developer in Japan. I was inspired by Nico Riedmann's Learn git concepts, not commands, and I have summarized git in my own way. Of course, I supplemented it with reading the official documentation as well. Understanding git from its system structure makes git more fun. I have recently become so addicted to git that I am in the process of creating my own git system.
- Whati is Git?
- Start new work
- Branch
- Merge
- Rebase
- Keep local repositories up-to-date
- Useful Functions
- End
- Reference
Git is a type of source code management system called a distributed version control system. Git is a tool to facilitate development work by recording and tracking the changelog (version) of files, comparing past and current files, and clarifying changes. The system also allows multiple developers to edit files at once, so the work can be distributed.
First, make a copy of the file or other files in a storage location that can be shared by everyone (from now on referred to as "remote repository") on your computer (from now on referred to as "local repository"), and then add or edit new code or files. Then, the files will be updated by registering them from the local repository to the remote repository.

When dealing with Git, it is important to follow "how to work" from "what" to "what". If you only operate commands, you may not understand what is happening and use the wrong command.
(info)
When manipulating Git, try to imagine what is happening before and after the operation.
A repository in Git is a storage for files, which can be remote or local.
Remote Repository is a repository where the source code is placed on a server on the Internet and can be shared by everyone. Local repository is a repository where the source code is located on your computer and only you can make changes.
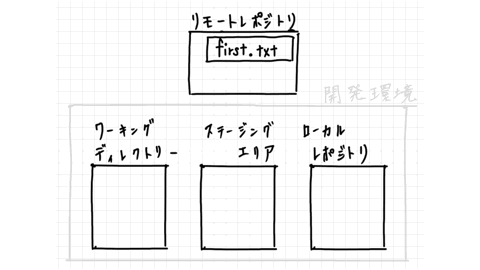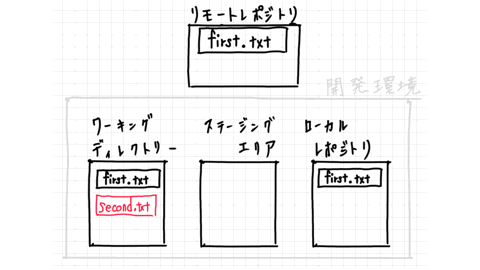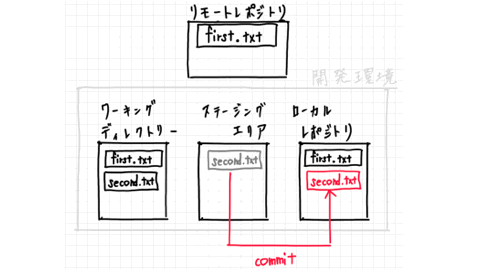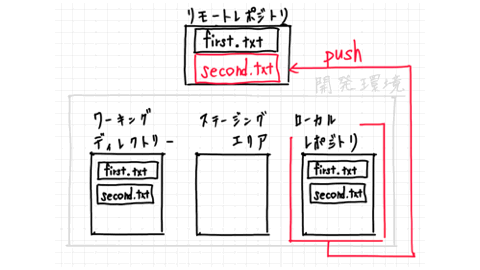
First, prepare your own development environment. All you need only to do is decide in which directory you will work. For example, your home directory is fine, or any directory you normally use.
Next, copy and bring the files from the remote repository.
This is called clone.

The remote repository called project contains only first.txt, and this is the image when you clone the remote repository.
(info)
Of course, you may create a local repository first and then reflect the remote repository.
This is called initialize and allows you to convert a directory you are already working on into a repository.
A working directory is not any special directory, but a directory where you always work on your computer.
It's easier to understand if you think of it as a directory where you can connect to the target directory that Git manages (in this case, project) with a Git staging area or local repository.

Changes to the source code are made through the working directory, the staging area. Actually, in the working directory, we work.
Let's create a new file called second.txt.

Next, move the modified file to the staging area.
This is called add.
It is a feature of Git that there is a cushion before changes are reflected in the local repository. I will explain why this cushion exists in more detail later.

Then, we registere the content in the staging area to the local repository.
This is called commit.
By the way, we can comment when you commit.
In this case, we added a file, so write git commit -m 'add second.txt'.

(info)
When you commit, a commit object is created in the repository. A simple explanation of a commit object is the data that has the updater's information and the modified file. (All data is saved, not just the differences, but the entire state of the file at that moment (snapshot). Please refer to Git Objects for more information about Git objects.
Then, the work is done!
The last step is to reflect the changes in the local repository to the remote repository.
This is called push.

It may be easier to understand if you think of it as a commit to a remote repository.
Changes between the same file are called diff.
We can see the changing points in the file.
I won't go into the details of the commands, but here are three that I use frequently.
git diff --stage to see the changes from the original working directory before you add.
git diff --stage to see changes to the working directory after add.
git diff <commit> <commit> to compare commits.
As development work grows, we often make many changes in one working directory. What happens if you put all the changes in a local repository at once? In this case, when parsing the commits, you may not know where a feature was implemented.
In Git, it is recommended to do one commit per feature.
This is why there is a staging area where you can subdivide the commit unit into smaller units.

The concept of Git is to stage only what is needed, and then proceed with the work or commit ahead of time to promote efficient development that can be traced back through the history of each implementation.
The basic workflow is to clone once and then add, commit, and push for each working.
(info)
clone: Make a copy from the remote repository to your development environment (local repository and working directory).
add: Add files from the working directory to the staging area and prepare them for commit.
commit: Register the file from the staging area to the local repository. At this time, a commit object is created.
push: Register changes from the local repository to the remote repository.
We create a branch to change and add files in multiple branches.
The files saved in the main branch are in ongoing use.
The reason for the separate branches is to work without affecting the currently running source code.
Let's create the branch called develop!
We can create a branch with git branch <new branch> or git checkout -b <new branch>.
The former just create a branch, the latter create a branch and moves you to that branch.
(Branches are maintained in the repository.)

The key point when generating branches is which branch to derive from.
We can specify the source as git checkout -b <new branch> <from branch>.
If we don't, the branch you are currently working on becomes the <from branch>.
(info)
A branch is actually a pointer to the commit (strictly speaking, a hash of commit objects). Generating a new branch means that the new branch indicate to the commit that the from branch pointed to as well.
Moving the branch is called checking out.
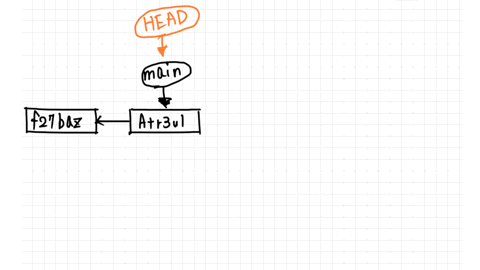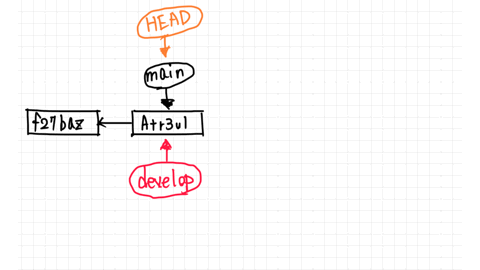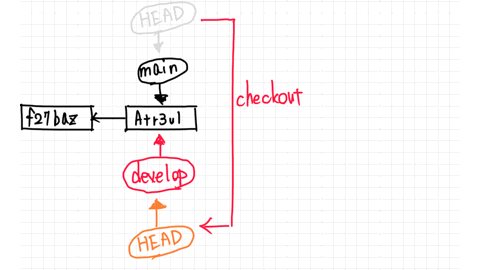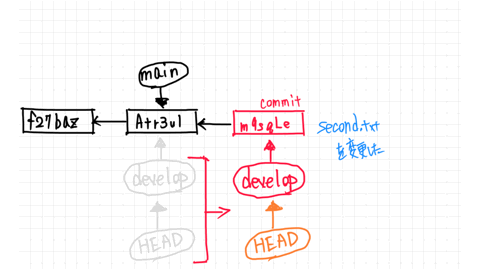
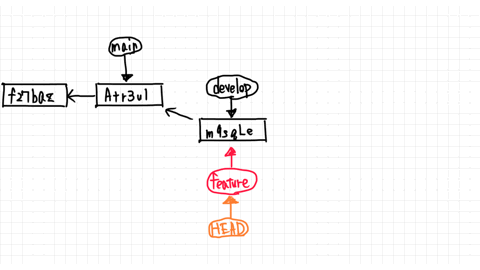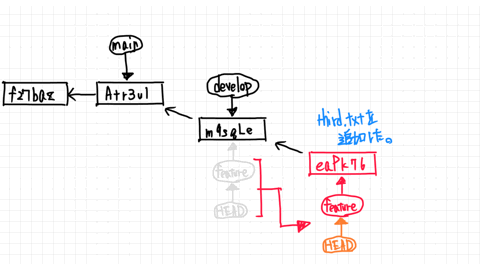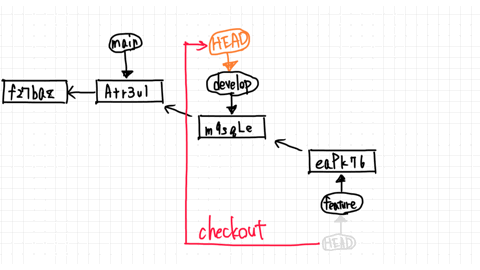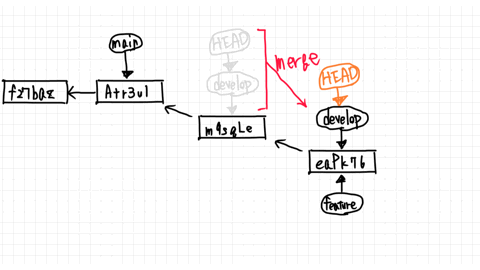
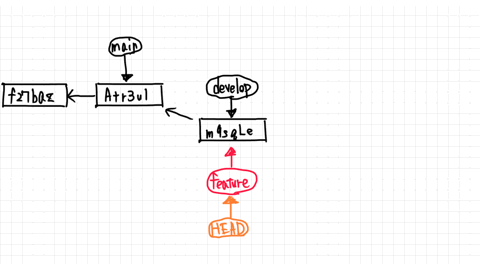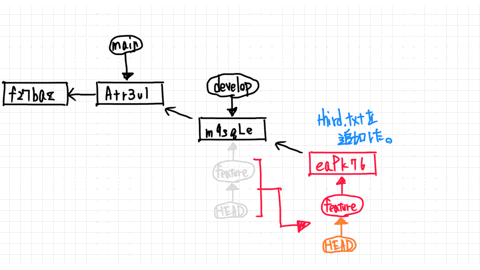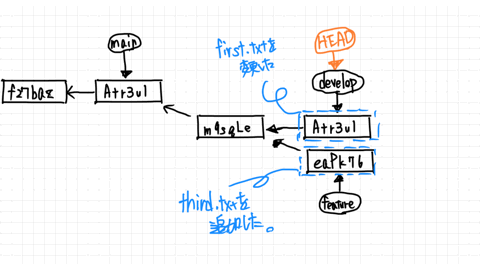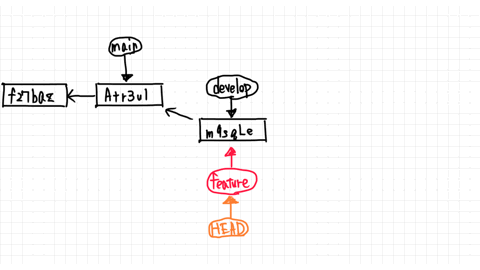
The pointer to the branch you are currently working on is called HEAD.
So, moving from the main branch to the develop branch means changing the HEAD.

Now both branches point to the commit named Atr3ul.
You just added second.txt by committing in the main branch, so you are ahead of the commit f27baz.
From here, let's say you change second.txt in the develop branch and make a new commit.

Then, as shown in the figure, the develop branch created a commit called m9sgle and pointed to that commit.
The current HEAD position (working branch position), what stage the file has been worked on, or the status of who is working on it is called status.
(info)
If you are familiar with object-oriented, you may understand the reason for the arrow on the commit.
It represents the relationship between a "parent" commit and a "child" commit.
The assumption is that parent←-child, that is, how much the child (commit) born from the parent (commit) has grown (changed).
The way branches to manage will vary on development team. On the other hand, like programming naming conventions, there is a general model for how to grow branches in Git. Here are two simple ones. I think it's enough to know that there is such a thing.
The "Git Flow" is a fairly complex and intricate structure. I think it's a model of how Git should be used.

Definition of each branch.
master: Branch to release a product. No working on this branch.
development: Branch to develope a product. When ready to release, merge to release. No working on this branch.
feature: Branch for adding features, merged into development when ready for release.
hotfix: For urgent post-release work (critical bug fixes, etc.), branch off from master, merge into master, and merge into develop.
release: For preparation of product release. Branch from develop with features and bug fixes to be released.
When ready for release, merge to master and merge to develop.
The "GitHub Flow" is a somewhat simplified model of the Git Flow.

As you can see, it consists of only master and feature.
The important difference is the cushion of pull requests (explained in the pull below), which allows integration between branches.
Basically, since there is no work on main (master), we create a branch for each work unit we want to do and create a new commit.
(info)
branch: New pointer to the commit
checkout: Move HEAD to change the branch to work on.
integrating the branches is called merge.
Basically, we merge into the main or develop branch.
Be careful not to mistake the subject of which branch is merging (absorbing) which branch.
We will always move (HEAD) to the branch from which you are deriving, and then do the integration from the branch from which you are deriving.
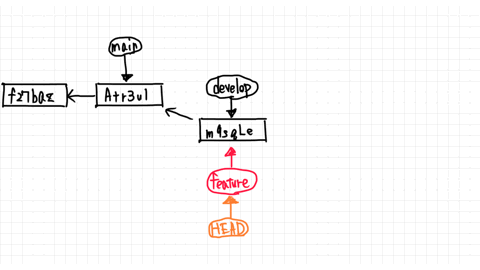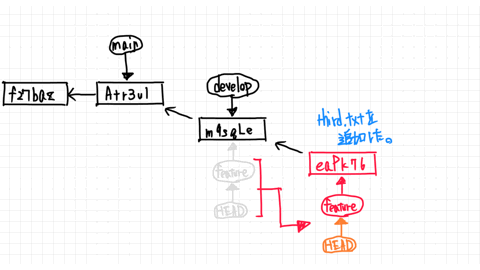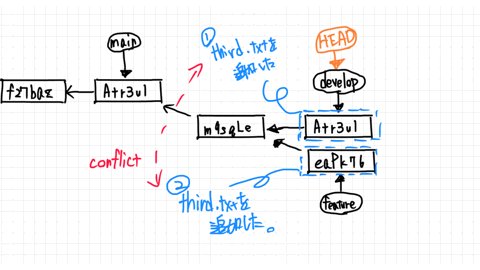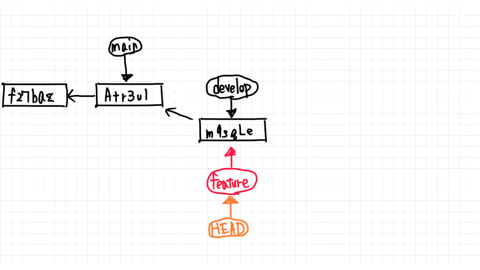
I am currently working on the feature branch and have created the following third.txt.
Hello, World! I'm noshishi, from Japan.
I like dancing on house music.
Then We `add` and finished up to `commit`.

When the feature branch points to the commit that can be traced back to the develop branch, the develop branch is in a fast-forward state.
First, move to develop with checkout.

In this case, the develop branch has not progressed at all, so to merge the feature branch will simply move the commit forward.
In this case, the develop and feature branches share the same commit.

What if the develop branch has progressed to a new commit by commit or merge?
This is called a no fast-forward situation.
In the develop branch, you have made changes to first.txt and have finished commit.
So the develop branch and the feature branch are completely split.

If you try to merge a feature branch from a develop branch, Git will check your changelog against each other.
If there are no conflicting edits, a merge commit is created immediately.
This is called an automatic merge.

In the no fast-forward state, the differences in work content. is called conflict.
In this case, we must manually fix the conflict content and commit.
In the develop branch, we created the following third.txt and committed.
Hello, World! I'm nope, from USA.
I like dancing on house music.
In the develop branch, I'm nope, from USA.
In the feature branch, I'm noshishi, from Japan.
The content of the first line is in conflict.
If you do a merge at this time, a conflict will occur.
Git will ask you to commit after resolving the conflict.

(The branch we work on is the develop branch)
If you look at third.txt as instructed, you will see the following additions
<<<<<<<< HEAD
Hello, World! I'm noshishi, from Japan.
=======
Hello, World! I'm nope, from USA.
>>>>>>>> feature
I like dancing on house music.
The upper HEAD, separated by =======, represents the contents of the develop branch.
The lower side represents the feature branch.
You first considered which one to adopt, and decided to adopt the changes made in the feature branch this time.
The only operation then is to edit third.txt by hand (delete unnecessary parts).
Hello, World! I'm noshishi, from Japan.
I like dancing on house music.
And the next thing you do is add and commit.
The conflict is resolved and a new merge commit is created.

Conflicts are feared by beginners, but once you learn this, you will no longer be afraid.
(info)
If you merge and resolve the conflict, why not merge again?
When you merge once, the develop branch enters the merge state, and if there are no conflicts, the new files are automatically added and commit.
So it is not a special commit after conflict is resolved.
That's why it's called merge commit.
The merged branch is basically useless, so we will delete it.
If we leave a branch alone, you can move from the branch you want to delete to another branch and git branch -d <branch>.
You may think the commits on that branch are deleted.
In fact, the commits are carried over to the merged branch.
You can use git log to see all the commits you've made on the branch and the commits on the merged branch.
We said that a branch is a pointer to a commit, but it also holds another important data. It is all the commits that have been made on that branch.
A branch is a collection of commits, and it has a pointer to the latest commit in that collection. (Strictly speaking, the commit can trace back to previous commits.)
The following diagram illustrates this.

So we can think of branches on a horizontal axis like Git Flow. By the way, if you draw the above diagram with branches on the horizontal axis, it looks like this.

fast-forward merge
no fast-forward merge
no fast-forward merge with conflict
(info)
merge: To integrate (absorb) a working branch (such as feature) into a specific branch (such as main or develop) and create a new commit.
Rebase is the process of merging branches by changing the commit from which the branch is derived.
It is similar to merge, except that the branch you are working on is the destination branch.
Suppose you are working on the develop and feature branches.

You may think to reflect the current commit on develop branch into feature branch.
You need to move feature branch from the gp55sw commit to the 3x7oit commit.
This can be moved at once from the feature branch by doing a git rebase develop.

This process is more like re-growing the feature branch from the latest commit on the develop branch than doing a merge.
The difference is that you move the entire commit and make a new commit.

One reason for such a move is that it is fast-forward and easy to merge at any time.
The other reason is that the commits are aligned so that the commit history can be easily traced and the order in which files are updated is consistent.
Of course there is also a conflict in rebase.
You added fourth.txt in the feature branch, but you didn't change fourth.txt in the develop branch.
There is conflict.
However, if the following changes are covered by each other, conflict will occur.

You can just deal with it the same way you would with merge.
However, After you have checked the diff and finished editing the file, you should finish your work with git rebase --continue.
You don't have to commit, it will commit automatically.
(info)
rebase: Move the commit from which the derived branch to a new commit.
After some local work, you may be faced with a situation where the remote repository has been updated by another developer.
In this case, you can use pull to re-install the information from the remote repository back into the local repository.
Branches are stored in each repository. This is the branch where the actual work is done.

On the other hand, the local repository has the copied branches of the remote repository.
This is called a "remote tracking branch".
It is a branch with a name that is tied to the remote branch in remotes/<remote branch>.
This is only monitoring the remote repository.
![]()
Suppose you have a situation where the develop branch in the remote repository is one step ahead of the remote tracking branch.

Reflecting the latest status of a branch in a remote repository on a remote tracking branch is called fetch.

If you want to have it reflected in your local branch, you can do a pull.
When you pull, the local remote tracking branch is updated first.
Then merge to the local branch.

This time, there was a commit that went one branch ahead of the develop branch, so you created a new commit by merge into the local develop branch.
When a remote repository commit conflict with a local repository commit, you face the conflict between the remote tracking branch and the local branch when you pull.
In the following case, the remotes/develop and develop branches are in conflict.

Since push is fetch and merge, you can solve in the same way as conflict in merge.
This time, develop merges remotes/develop, so the working branch is develop.
Open the folder that caused the problem and commit when you have fixed it.
Basically, the relationship between remote and local is pull from the remote repository to the local repository and push from the local repository to the remote repository.
However, GitHub and other services have a mechanism to send a request before merge from a branch in a remote repository to a branch such as main.
This is because if a developer pushes to the main branch and updates the remote repository, no one can check it and a major failure may occur.
Pull request is to insert a process where a higher level developer reviews the code once.

(info)
pull: fetch + merge. pull is to reflect the state of the remote repository in the local repository.
To commit to correct a previous commit is called revert.
For example, suppose you added second.txt to your local repository with m9sgLe.
When you revert, the commit is revoked and second.txt is no longer in the local repository.

The merit of revert is that it allows you to leave commit.
Distinguish this from reset, which will be introduced later.
To undo the current latest commit and work on it again is called reset.
The --soft option allows you to go back to the stage immediately after add.
The --mixed option allows you to go back to the stage where you were working in the working directory.
The --hard <commit> option removes all commits up to the commit point you are returning to and moves head to the specified commit.

Since reset completely deletes the commit, it is recommended that you do not use it unless you have a good reason, especially for the '--hard' option.
If you want to get your commits back, you can use git reflog to see the commits you have deleted.
Since you can't move to another branch if there are change files, you have to choose between going to commit or discarding your changes.
This is where stash comes in handy.
You can temporarily evacuate files in the working directory or staging area.

When you want to move to another branch, stash and when you return, use stash pop to retrieve the evacuated files and resume work.
Bringing any commit to the current branch to create a commit is called cherry-pick.
It is a very nice feature.

This is used when you want to bring back only features previously implemented in a feature branch and use them for work in the current develop branch, for example.
I explained that HEAD is a pointer to the branch you are currently working on. I also explained that a branch is a pointer to a commit.
See the figure below.

HEAD points to the develop branch, and the develop branch points to the commit eaPk76.
So, HEAD in this situation refers to the commit eaPk76.
Have you often seen Git documentation or articles that use HEAD after a command?
For example, git revert HEAD.
This is a command that can be achieved because you can replace HEAD with commit.
Mercurial has the same history as Git. Mercurial has a very simple command line interface (CLI) that sacrifices the flexibility of Git. Recently, based on Mercurial, Meta released a new source code management system called Sapling as open source. I would like to try it again and write about my impressions.
A hosting service is a service that rents a server for a remote repository. Typical examples are GitHub, Bitbucket, and Aws Code Commit for private use. Git and Git Hub are completely different. By the way, as mentioned above, we can use our own servers for remote repositories.
If you have been exposed to programming that deals directly with memory, such as the C programming language, you will somehow know what a "pointer" is. On the other hand, for a beginning programmer, it seems very vague.
I said that commit objects are stored in the repository. If there are many commit objects in the repository, how can you select the one you want?
We need a label (address) to locate a particular commit object.

The "pointer" is a valuable data that indicates us to the label so that we don't forget it.
The label, by the way, is converted into a mysterious string through a hash function.
If you are curious, please refer to How does Git compute file hashes?.
There are many things I failed to mention in this article.
- The core of Git is a simple key-value type data store
- Details of the Git object that is the value
- How to relate with each objects. I hope to fully explore this someday.