Implementing automatic snake moving game to eat food with help of two different AI algorithms i.e. Genetic Algorithm (Reinforcement Learning) and A-Star.
Abdullah Waseem , Usman Ali , Muammad Gulraiz, Muhammad Yasoob
Computer Science Department, National University of Computer and Emerging Sciences Lahore, Pakistan
l174254@lhr.nu.edu.pk, l174369@lhr.nu.edu.pk, l174055@lhr.nu.edu.pk, l174380@lhr.nu.edu.pk
In this project our main purpose was to use different techniques of artificial intelligence for efficient movement of the snake. Therefore, we implemented the game with two different approaches, namely: Reinforcement learning, and Heuristic based learning. We, then, compared the performance through both the approaches and saw which one gave us better results, and in turn made a better and more efficient self learning snake game.
Initially we decided to build the snake game for our project of Artificial Intelligence. In this game the main goal was to use different techniques of artificial intelligence for efficient movement of the snake for eating food and avoiding obstructions. Hence we decided to use Feed Forward Neural Network for making snake learn to move in the optimal direction. For this Feed Forward Neural Network some initial data i,e training data was needed to tell the snake to move in which direction. This purpose of building the training data was fulfilled by using a genetic algorithm which then assigned labels to each move of the snake accordingly.
In addition to Feed Forward Neural Network, we also implemented the A-Star algorithm to check its performance for the snake game, just to evaluate greedy approach in this game with the help of evaluation function.
The primary purpose of our report is comparison of the performance of two different algorithms for snake game. These two algorithms include Feed Forward Neural Network and the A-Star algorithm. The comparisons that would be made in between these two algorithms (Feed Forward Neural Network and A-Star Algorithm) , will be on the basis of time taken by the snake to learn to move efficiently, time used by the snake before dying, performance in terms of score etc.
We have implemented two techniques Reinforcement Learning [1] and A-star Algorithm. Lets first discuss Reinforcement Learning whose code has been taken from a third party source and has been tested for performance by altering various parameters including mutation rate for genetic algorithm, no of hidden layers and neurons in each layer of neural network.
We have implemented this technique using Genetic Algorithm and a Feed Forward neural network. As we did not have data to train our snake so we have used Genetic algorithm to create set of moves or chromosomes that are actually the some parameters of snake.The complete description of the Genetic algorithm is as follows:
Neural Networks [2] are often used in supervised learning. You have some training data, toss in a Neural Network and have it learn the weights to help with unseen data. With Snake, however, there is no training data. Training data could be used but would require a ton of work playing Snake and labeling what the correct decision is. By using a Genetic Algorithm you can treat the weights as chromosomes of individuals and slowly evolve the population
Individuals are used to represent a snake. There are some parameters that are used to represent a snake. These parameters act as the weights of the neural network. And called chromosome here.
There are three types of the selections function. One is the elitism in which we pick n top individuals from the population. Another is the roulette wheel function in which we use the unequal distribution wheel and the chance of the selection of the individual which has the higher value is higher but the individual which has lower value can be selected. It is the same as the lucky wheel. The last one is the tournament function for the selection process. It is the same as elitism with few changes. Instead of considering the whole population we only take the K individuals from the total population and select the top n individuals from that tournament. In our problem we use the all and find some result according to our experiment. The best method for selection procedure is the roulette wheel in which we find the best score.
After the selection of the individuals we perform the crossover on the two selected parents and find the offspring of the both. As in this problem we use the simulated binary crossover and the offspring are created around the parents. The value of the eta determines the distribution of the children of the new generation. By increasing the value eta the distribution of the children becomes very accurate. The number of the offspring and the selected individuals are discussed in the section of the mutation and population rate with the help of the graph where you can easily understand this. There are two types of the selection of the individual to go to next generation one is plus in which the parents are also included in the next generation and the other is comma in which only offspring go to the next generation.
When a chromosome is chosen for mutation, we randomly change its genes. Which means that we change the weights value randomly. There is very little chance of mutation for an individual.
We tested this model with different mutation rates and population sizes. The results that we have obtained are as follows Note:These results are calculated with 1000 as last generation or in simple for 1000 epoch where one generation is one epoch The results of mutation rate are
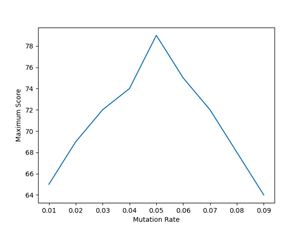 Figure 1: Results of different mutation rates
Figure 1: Results of different mutation rates
As it can be seen that the maximum score that we have achieved was at mutation rate 0.05. As we have increased mutation rate from 0.05 the maximum score starts decreasing
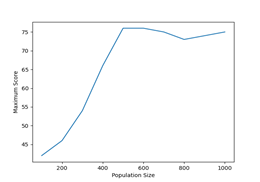 Figure 2: Results of different population sizes
The results show that we have achieved a maximum score of 76 when population size was set to 500. But after 500 the score remains almost static. Remember that for each generation of 500 1000 offsprings are created and from that 1000 offsprings 500 are selected to take part in the next generation.
Figure 2: Results of different population sizes
The results show that we have achieved a maximum score of 76 when population size was set to 500. But after 500 the score remains almost static. Remember that for each generation of 500 1000 offsprings are created and from that 1000 offsprings 500 are selected to take part in the next generation.
As we know that the fitness function of a genetic algorithm is different for every problem. For this problem the we calculate the fitness of an individual on the basic of the following rules Rules for fitness function [3] are: The fitness function that we have used is as below f(steps, apples) = steps + (2apples + 500 ∗ apples2.1)−(0.25∗steps1.3 ∗ apples1.2)
The neural network is the one which is making decisions and interacting with the snake. You can take the neural network as the brain of the snake. And every snake has the same architect of the neural network. We have used feed forward neural network.The description of neural network is as below:
Our neural network contains four layers: 1 Input Layer, 2 hidden layers, and 1 output layer. The input Layer contains 32 neurons, the first hidden layer contains 20 neurons, the second hidden layer contains 12 neurons while the output layer has 4 neurons. This one fulfills the purpose architecture of the neural network for this problem. You can change the architecture of the neural network according to your requirement.
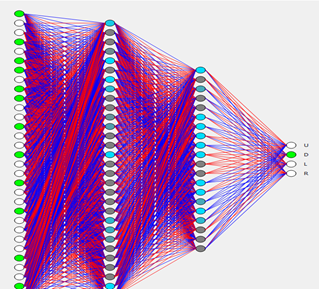 Figure 3 Neural Network
Figure 3 Neural Network
The input layer has 32 neurons. First 24 neurons are reserved for snake vision. Our snake has a vision of 8 directions. And in these 8 directions snake looks for three things 1: Distance from wall 2: Is there an apple 3: Is there any part of its body To represent these variables we have used hot encoded variables. These variables then act as an input for the neural network.The next 8 neurons in the neural network received direction of tail and direction of snake head as input. As there are 4 possible directions Up,Down,Left, Right so we have used 8 neurons to handle it. These values are the values of the surrounding of the snake or we can say that the environment of the snake on the basis of these values, the snake makes moves.
The output layer is simple it contains 4 neurons that for each direction Up,Down, Left,Right
We have used relu as an activation function for two hidden layers. While sigmoid is being used as an output layer activation function.
First a random population of 500 chromosomes is generated. These snakes take the surroundings as input and feed it to the neural network. By using these input values with the value of the weights of the neural network the neural network learns about the moves and updates the weight which are the chromosomes of the individual neurons. When all the snakes complete its learning process then make the selection of the best by using the roulette wheel method. After the selection the selected individuals are passed from the crossover process and then take all the steps which are taken in the genetic algorithm to generate the next generation. After this repeat the process from the first step. The first snake knows nothing and goes straight and kills itself by touching the boundaries. But eventually it eats snake fruit in a particular direction. It learns at that point of time how to go in that particular direction to eat fruit. If the individual that learns how to go in a particular direction and is selected for crossover then all the offspring of this individual know the same thing that parent knows and improve its knowledge from it parent by randomly.
There are two types of the result, one in which we make changes in the neural network and do not change the properties of the genetic algorithm. These parameters or the properties are used in the algorithm in which we find the most optimized result.
Note: we only change the number of hidden layers and its density, we could not change the
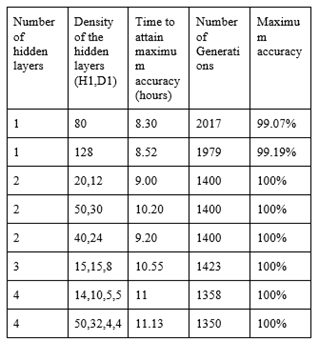 Figure 4 Showing Results
Figure 4 Showing Results
The results are the top four selected from the experiment that we made to optimize the value. There are many other results with low accuracy which are not included in this table. Another type of result is that in which we change the setting of the genetic algorithm by considering the architecture that we purpose for this problem. We find the maximum accuracy in purpose method that we describe above in the section of the genetic algorithm. And the result graphs are shown above in the section of mutation and population rate.
Another technique that we have used to create an auto player for snake game is an A star algorithm [4] but before describing the algorithm, I want to discuss our state representation.
To store state of the board we have used a grid [5] or 2d array of class Spot now Spot is a class that is just like a cell of grid and it holds several variables and arrays. Important variables that it holds are x,y that are x and y axis of grid, g which contains the step cost,h which contains the heuristic value , neighbours that contains an array of it neighbours So in our case there can be 3 or 4 neighbours depending on the location of the spot. The f variable is used to store the complete cost of including g and h of spot. The “current” array is used to save the record from which path(neighbour) it cost “f”. To store a snake we have used one D array of Spots. Where the last spot element in the array represents the snake head.
In A star implementation the main thing we need to discuss is the getPath() function that is doing all magical stuff. It takes food which is a spot as well and snake array(discussed in previous section).There are two arrays open set and closed set.which behaves just like open and closed list in A*start algorithm. It takes the minimum cost spot(which has minimum value of f) from openset and explores it. It calculates its neighbours' huresitics and remembers that as row or column changes g which is step cost gets increased by 1. After calculating the heuristic and step cost it then calculate the complete cost and store in f. It repeats the same thing for all of its neighbors. And repeat the whole process until it finds a spot which contains the food.As it finds food it stores path direction in a path array and return array. Snake then follows these directions to reach its goal.
The most important thing in A star is the heuristic function. We tried to use functions Euclidean and Manhattan distance as our heuristic functions the results are as below Test results when there a no obstacles
Heuristic Function Score Eculiden 63 Manhattan 60
After that we tested our snake with obstacles
Heuristic Function Score Eculiden 60 Manhattan 45
As the results show that Euclidean performs better than Manhattan in both scenarios so we have used Euclidean as our Heuristic Function Our Heuristic Function is :sqrt((neighbor.x - food1.x) * 2 + (neighbor.y - food1.y) * 2)
After testing and experimentation we observed that the A-Star algorithm takes on a greedy approach for the movement of the snake in optimal direction and this greediness is achieved by the heuristic function of the A-Star algorithm. Thus it was observed that this greedy approach performance might alter if we change the surrounding environment of snake. However in the case of neural network as we are using reinforcement learning so if we change the environment then in this case this algorithm will start to learn optimal movement of snake from the beginning. As for this scenario it will not have any past experiences so this learning from the beginning is justified. Thus due to this learning neural network will work fine even in the changed environment.
In addition to all this, another difference in the performance of the two algorithms was that the highest score achieved in the A-Star algorithm after several runs was 100 i.e, no of blocks present in the snake were grown to 100 after eating food. On the other hand if you allow the neural network to learn for more than 1400 generations that will take roughly 10 hours of training then score that can achieve its maximum value possible i.e, the snake could not grow further as in this case there will be no space available on the game grid.