GraphSAGE :: Graph Neural Network at RecSys
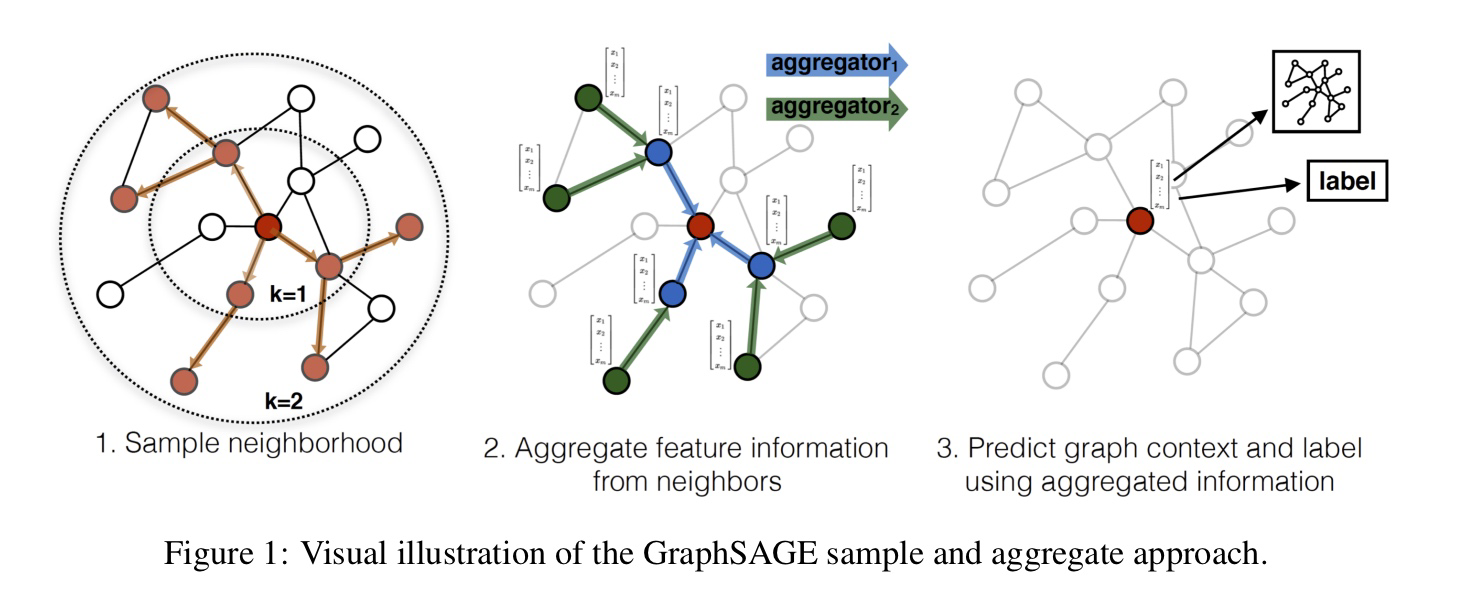
GraphSAGE 모델의 학습 프로세스는 크게 두 가지 단계로 구성된다.
-
Supervised Learning 먼저, 각 노드에 대한 Ground Truth Label을 사용하여 모델의 임베딩 벡터를 학습한다. 이 과정에서는 임베딩 벡터와 실제 레이블 간의 차이를 최소화하는 방향으로 학습이 이루어진다. 이를 위해 일반적으로 cross-entropy loss나 mean squared error loss를 사용한다.
-
Unsupervised Learning 다음으로, 이웃 노드들을 사용하여 GraphSAGE 모델이 임베딩을 얻어내는 더 일반적인 방식인 unsupervised learning 단계가 진행된다. 이 단계에서는 모델이 노드 간의 상호작용을 고려하여 임베딩 벡터를 학습한다.
-
각 노드
$v$ 를 타겟 노드로 설정하고, 그 노드를 중심으로 k-hop 이웃 노드를 선택한다. -
선택한 k-hop 이웃 노드들의 임베딩 벡터를 Aggregation Function을 사용하여 하나의 벡터로 만든다.
-
만들어진 벡터와 타겟 노드의 임베딩 벡터를 Concatenate한 후, MLP를 통해 새로운ㄴ 임베딩 벡터를 생성한다.
-
이 과정을 모든 노드에 대해 반복하며, 모든 노드의 임베딩 벡터를 갱신한다.
-
모든 노드의 임베딩 벡터가 갱신되면, 이를 다시 한 번 Supervised Learning 단계에서와 같은 방식으로 학습한다. 이 과정에서도 Cross-entropy loss나 Mean Squared Error loss 등을 사용할 수 있있다.
이와 같은 과정을 반복하면서, 모델은 점차적으로 노드 간의 상호작용을 파악하고, 이를 바탕으로 더욱 정교한 임베딩 벡터를 생성하게 된다.