Authors: Yunheng Li, Zhong-Yu Li, Quansheng Zeng, Qibin Hou*, Ming-Ming Cheng.
[paper] [github] [pretrained models] [Param. & Flops & FPS] [visualization]
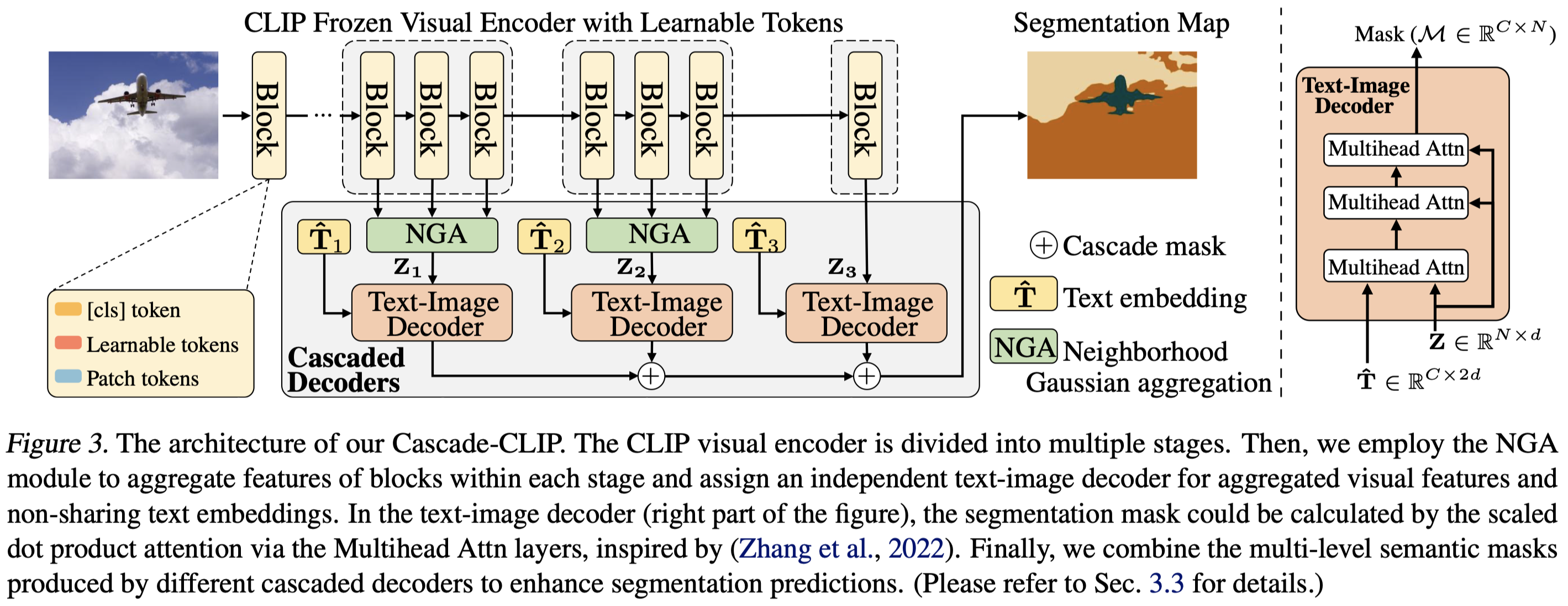
Abstract: Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context.

See installation instructions.
According to MMseg: https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/dataset_prepare.md
datasets
└── coco_stuff164k
│ ├── images
│ │ ├── train2017
│ │ └── val2017
│ ├── annotations
│ │ ├── train2017
│ │ └── val2017
└── VOCdevkit
├── VOC2010
│ ├── ImageSets
│ ├── Annotations
│ ├── JPEGImages
│ ├── SegmentationClass
│ └── SegmentationClassContext
└── VOC2012
├── ImageSets
├── Annotations
├── JPEGImages
├── SegmentationClass
└── SegmentationClassAug
Download the pretrained model here: clip_pretrain/ViT-B-16.pt https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt
All experiments using a machine with 4 NVIDIA RTX 3090 GPUs. (~20 hours for COCO Inductive)
| Dataset | Setting | mIoU(S) | mIoU(U) | Traing time (hours) | Model Zoo |
|---|---|---|---|---|---|
| PASCAL VOC 2012 | Inductive | 92.5 ( |
83.0 ( |
~3 | [BaiduNetdisk] |
| PASCAL VOC 2012 | Transductive | 93.6 ( |
93.2 ( |
~1.5 | [BaiduNetdisk] |
| PASCAL Context | Inductive | 55.9 ( |
47.2 ( |
~8 | [BaiduNetdisk] |
| PASCAL Context | Transductive | 56.4 ( |
55.0 ( |
~4 | [BaiduNetdisk] |
| COCO Stuff 164K | Inductive | 41.2 ( |
43.4 ( |
~20 | [BaiduNetdisk] |
| COCO Stuff 164K | Transductive | 41.7 ( |
62.5 ( |
~10 | [BaiduNetdisk] |
Note that here we report the averaged results of several training models and provide one of them.
bash dist_train.sh configs/coco_171/vpt_seg_zero_vit-b_512x512_80k_12_100_multi.py 4 output/coco_171/inductive
bash dist_train.sh configs/context_59/vpt_seg_zero_vit-b_512x512_40k_12_10.py 4 output/context_59/inductive
bash dist_train.sh configs/voc_20/vpt_seg_zero_vit-b_512x512_20k_12_10.py 4 output/voc_20/inductivebash dist_train.sh configs/coco_171/vpt_seg_zero_vit-b_512x512_40k_12_100_multi_st.py 4 output/coco_171/transductive --load-from=output/coco_171/inductive/iter_40000.pth
bash dist_train.sh configs/context_59/vpt_seg_zero_vit-b_512x512_20k_12_10_st.py 4 output/context_59/transductive --load-from=output/context_59/inductive/iter_20000.pth
bash dist_train.sh configs/voc_20/vpt_seg_zero_vit-b_512x512_10k_12_10_st.py 4 output/voc_20/transductive --load-from=output/voc_20/inductive/iter_10000.pthpython test.py config/xxx/xxx.py ./output/model.pth --eval=mIoU
For example:
python test.py configs/coco_171/vpt_seg_zero_vit-b_512x512_80k_12_100_multi.py output/coco_171/inductive/latest.pth --eval=mIoUpython test.py configs/cross_dataset/coco-to-voc.py output/coco_171/inductive/iter_80000.pth --eval=mIoU
python test.py ./configs/cross_dataset/coco-to-context.py output/coco_171/inductive/iter_80000.pth --eval=mIoURequires fvcore to be installed
pip install fvcore
CUDA_VISIBLE_DEVICES="0" python get_flops.py configs/coco_171/vpt_seg_zero_vit-b_512x512_80k_12_100_multi.py CUDA_VISIBLE_DEVICES="0" python get_fps.py configs/coco_171/vpt_seg_zero_vit-b_512x512_80k_12_100_multi.py checkpoints/coco_171/coco_model.pth python test.py configs/coco_171/vpt_seg_zero_vit-b_512x512_40k_12_100_multi_st.py output/coco_171/transductive/latest.pth --show-dir=visualization/coco_171/transductive --eval=mIoUIf you find this project useful, please consider citing:
@inproceedings{licascade,
title={Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation},
author={Li, Yunheng and Li, Zhong-Yu and Zeng, Quan-Sheng and Hou, Qibin and Cheng, Ming-Ming},
booktitle={International Conference on Machine Learning},
year={2024}
}Our work is closely related to the following assets that inspire our implementation. We gratefully thank the authors.
Licensed under a Creative Commons Attribution-NonCommercial 4.0 International for Non-commercial use only. Any commercial use should get formal permission first.