中文EDA实现。本工具是论文《EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks》的中文版本实现。
原作者虽给出了针对英文语料数据增强的代码实现,但不适合中文语料。我经过对原论文附上的代码的修改,现在推出这个适合中文语料的数据增强EDA的实现。
- 先将需要处理的语料按照下面的例子处理好成固定的格式:
0 今天天气不错哦。
1 今天天气不行啊!不能出去玩了。
0 又是阳光明媚的一天!
即,标签+一个制表符\t+内容
- 命令使用例子:
$python code/augment.py --input=train.txt --output=train_augmented.txt --num_aug=16 --alpha=0.05
这里:
input参数:需要进行增强的语料文件
output参数:输出文件
num_aug参数:每一条语料将增强的个数
alpha参数:每一条语料中改动的词所占的比例
具体使用方法同英文语料情况。请参考eda_nlp。
| 词表名 | 词表文件 |
|---|---|
| 中文停用词表 | cn_stopwords.txt |
| 哈工大停用词表 | hit_stopwords.txt |
| 百度停用词表 | baidu_stopwords.txt |
| 四川大学机器智能实验室停用词库 | scu_stopwords.txt |
- 原仓库:eda_nlp。感谢原作者的付出。Thanks to the author of the paper.
《EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks》
在这篇论文中,作者提出所谓的EDA,即简单数据增强(easy data augmentation),包括了四种方法:同义词替换、随机插入、随机交换、随机删除。作者使用了CNN和RNN分别在五种不同的文本分类任务中做了实验,实验表明,EDA提升了分类效果。作者也表示,平均情况下,仅使用50%的原始数据,再使用EDA进行数据增强,能取得和使用所有数据情况下训练得到的准确率。
- 英法互译
- 同义词替换
- 数据噪声
由于没有一般的语言转换的通用规则,因此NLP中的通用数据增强技术人们探索甚少。上述若干方法,相对于其能提升的性能,实现开销更大。
作者还列举出了其他一些增强方法,而EDA的优点在于能以更简单的方法获得差不多的性能。
在本文,作者提出通用的NLP数据增强技术,命名为EDA。同时作者表示,他们是第一个给数据增强引入文本编辑技术的人。EDA的提出,也是一定程度上受计算机视觉上增强技术的启发而得到。下面详细介绍EDA的四个方法:
对于训练集中的每个句子,执行下列操作:
- 同义词替换(Synonym Replacement, SR):从句子中随机选取n个不属于停用词集的单词,并随机选择其同义词替换它们;
- 随机插入(Random Insertion, RI):随机的找出句中某个不属于停用词集的词,并求出其随机的同义词,将该同义词插入句子的一个随机位置。重复n次;
- 随机交换(Random Swap, RS):随机的选择句中两个单词并交换它们的位置。重复n次;
- 随机删除(Random Deletion, RD):以
$p$ 的概率,随机的移除句中的每个单词;
这些方法里,只有SR曾经被人研究过,其他三种方法都是本文作者首次提出。
值得一提的是,长句子相对于短句子,存在一个特性:长句比短句有更多的单词,因此长句在保持原有的类别标签的情况下,能吸收更多的噪声。为了充分利用这个特性,作者提出一个方法:基于句子长度来变化改变的单词数,换句话说,就是不同的句长,因增强而改变的单词数可能不同。具体实现:对于SR、RI、RS,遵循公式:$n$ =
作者使用了5个不同的Benchmark数据集(这里不再介绍每个数据集是什么,如果你想了解可以去查原论文,但没太大必要),这样就有5种文本分类任务,使用了两个state-of-the-art文本分类的模型:LSTM-RNN和CNNs。并将有无EDA作为对比,同时因为欲得到EDA在小数据集上的实验效果,将训练数据集大小分为500、2000、5000、完整这4个量级。每个训练效果是在5个文本分类任务上的效果均值。
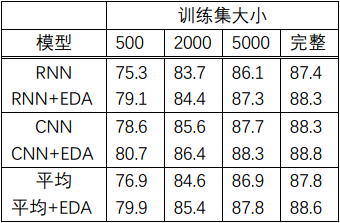
- 实验结果是:在完整的数据集上,平均性能提升0.8%;在大小为500的训练集上,提升3.0%。具体见如下表1:
-
若句子中有多个单词被改变了,那么句子的原始标签类别是否还会有效?作者做了实验:首先,使用RNN在一未使用EDA过的数据集上进行训练;然后,对测试集进行EDA扩增,每个原始句子扩增出9个增强的句子,将这些句子作为测试集输入到RNN中;最后,从最后一个全连接层取出输出向量。应用t-SNE技术,将这些向量以二维的形式表示出来。实验结果就是,增强句子的隐藏空间表征紧紧环绕在这些原始句子的周围。作者的结论是,句子中有多个单词被改变了,那么句子的原始标签类别就可能无效了。
-
对于EDA中的每个方法,单独提升的效果如何?作者做实验得出的结论是,对于每个方法在小数据集上取得的效果更明显。$\alpha$ 如果太大的话,甚至会降低模型表现效果,$\alpha$=0.1似乎是最佳值。
-
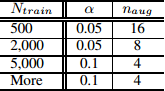
如何选取合适的增强语句个数?在较小的数据集上,模型容易过拟合,因此生成多一点的语料能取得较好的效果。对于较大的数据集,每句话生成超过4个句子对于模型的效果提升就没有太大帮助。因此,作者推荐实际使用中的一些参数选取如表2所示:
-
生成类似于原始数据的增强数据会引入一定程度的噪声,有助于防止过拟合;
-
使用EDA可以通过同义词替换和随机插入操作引入新的词汇,允许模型泛化到那些在测试集中但不在训练集中的单词;
上述的其它增强技术作者都希望你使用,它们确实在一些情况下取得比EDA较好的性能,但是,由于需要一个深度学习模型,这些技术往往在其取得的效果面前,付出的实现代价更高。而EDA的目标在于,使用简单方便的技术就能取得相接近的结果。
确实有可能。原因在于,EDA有可能在增强的过程中,改变了句子的意思,但其仍保留原始的类别标签,从而产生了标签错误的句子。