Paper list of multi-agent reinforcement learning (MARL)
- Multi-Agent-RL
- Credit Assignment Problem in MARL
- Explicit assignment
- Reward Assignment
- Distributed Welfare Games
- Difference Rewards Policy Gradients
- Social Influence as Intrinsic Motivation
- Incentivizing Collaboration in a Competition
- Social Diversity and Social Preferences in Mixed-Motive Reinforcement Learning
- Inducing Cooperation through Reward Reshaping based on Peer Evaluations
- Gifting in Multi-Agent Reinforcement Learning
- Cooperation and Reputation Dynamics with Reinforcement Learning
- Value Assignment
- MADDPG: Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
- COMA: Counterfactual Multi-Agent Policy Gradients
- Shapley Q-value: Shapley Q-value: A Local Reward Approach to Solve Global Reward Games
- CPGs: Causal Policy Gradients
- Shapley Counterfactual Credits for Multi-Agent Reinforcement Learning
- Reward Assignment
- Learning assignment
- Value Decomposition
- VDN: Value-Decomposition Networks For Cooperative Multi-Agent Learning
- QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
- DOP: Off-Policy Multi-Agent Decomposed Policy Gradients
- LICA: Learning Implicit Credit Assignment for Cooperative Multi-Agent Reinforcement Learning
- CollaQ: Multi-agent Collaboration via Reward Attribution Decomposition
- Reward shaping
- On Learning Intrinsic Rewards for Policy Gradient Methods
- LIIR: Learning Individual Intrinsic Reward in Multi-Agent Reinforcement Learning
- Adaptive Mechanism Design: Learning to Promote Cooperation
- Learning to Incentivize Other Learning Agents
- Learning to Share in Multi-Agent Reinforcement Learning
- Coordinating the Crowd: Inducing Desirable Equilibria in Non-Cooperative Systems
- D3C: Reducing the Price of Anarchy in Multi-Agent Learning
- Value Decomposition
- Explicit assignment
- Information Sharing in MARL
- Planning in MARL
- Hierarchical Reinforcement Learning
- Credit Assignment Problem in MARL
In the cooperative MARL setting, either global reward or individual reward is coupled with other agents. The Credit Assignment Problem is to assign proper reward or value to agents, so agents can make cooperative decisions individually.
- Difference reward
- Optimal Payoff Functions for Members of Collectives. 2001
- Aristocrat Utility:
- marginal contribution of agent (coalition)
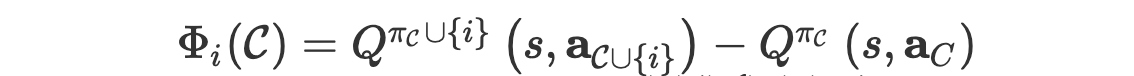
- marginal contribution of agent (coalition)
- Wonderful Life Utility:
- counterfactual baseline
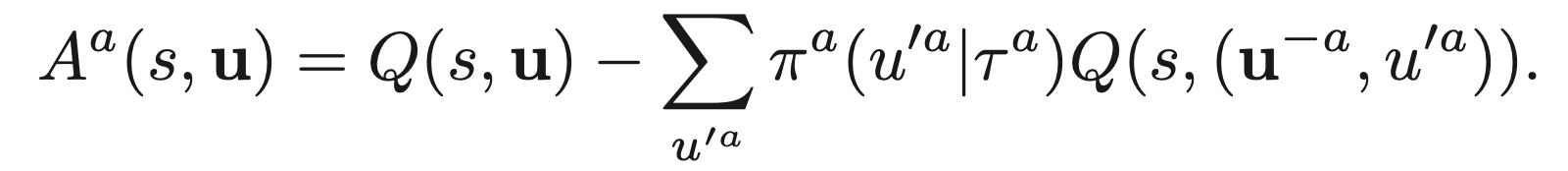
- counterfactual baseline
- Aristocrat Utility:
- Optimal Payoff Functions for Members of Collectives. 2001


Explicitly calculate the contribution of single agent
Global reward -> (explicit calculation) -> local reward
- rules of assignment
- Budget balance
- Informational dependencies
- Induced nash equilibrium
- assignments
- Equally Shared
- Marginal Contribution
- Shapley Value
- The Weighted Shapley Value
- global reward setting
- counterfactual reward
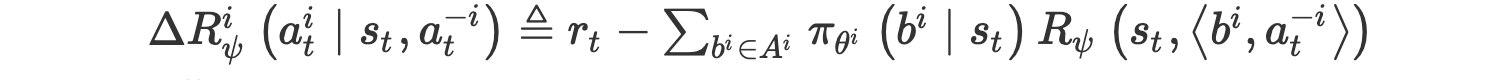
- difference return
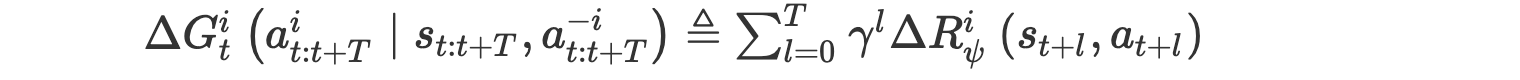
- counterfactual reward


- individual reward design

- extrinsic reward
- social influence
- measure the cause influence between two agents
- KL divergence of policy of one agent with/o anther agent



- individual reward design (local social welfare)
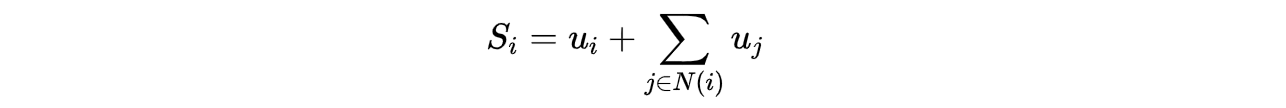
- this utility induce NE that maximize social welfare.
- potential function is the global social welfare
- this utility induce NE that maximize social welfare.

- individual reward design
- consider willingness of cooperation

- social value orientation
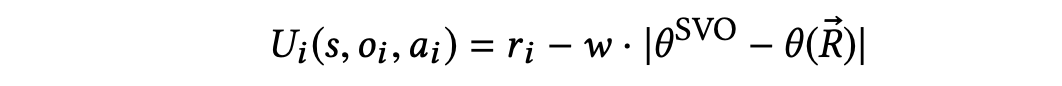
- consider willingness of cooperation


- individual reward design
- peer Evaluation: a quantification of the effect of the joint actions on agent 𝑘’s expected reward
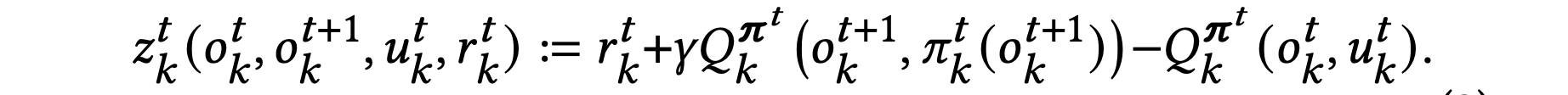
- evaluation form others
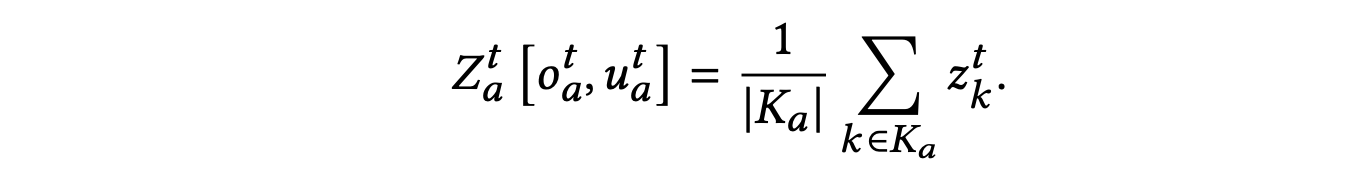
- final reward

- peer Evaluation: a quantification of the effect of the joint actions on agent 𝑘’s expected reward



- individual reward design
- zero-sum: give by accumulated reward
- fixed budget: given fixed at the start
- Replenishable Budget: accumulated, proportional to received reward
- individual reward design
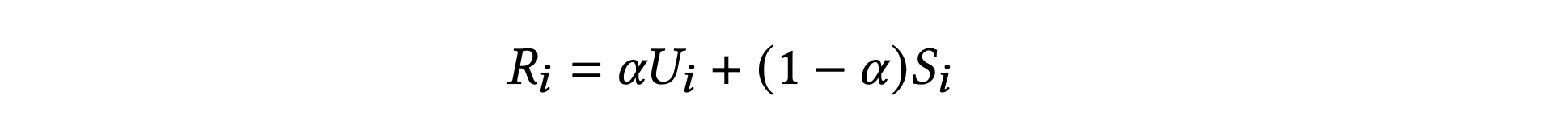
- 𝑈 is their payoff in a particular encounter,
- 𝑆 refers to the payoff they would get facing themselves

Global Q value -> (explicit calculation) -> local Q value
- use global Q value
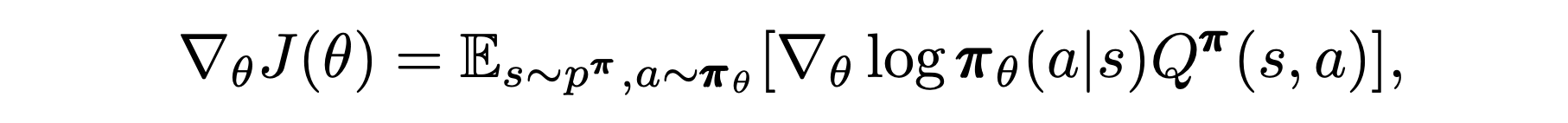

- minus a counterfactual baseline
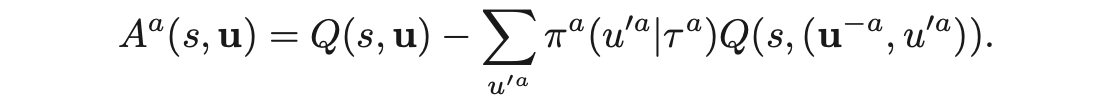
- COMA:
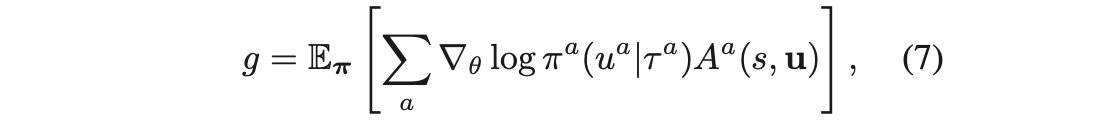


- use shapley value to calculate assignment
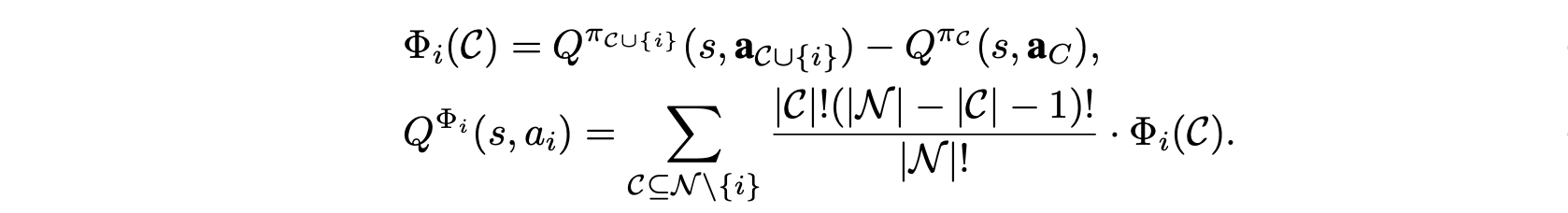

- Multi-objective MDP
- consider causal graph between actions and objectives
- causal baseline
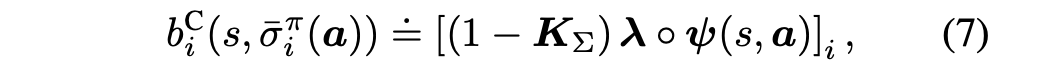

- counterfactual baseline (using default action)
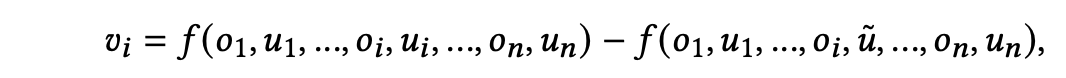
- sample approximation



Global Q value -> (learning decomposition) -> Local Q value IGM: individual-global-maximization
- Value decomposition:
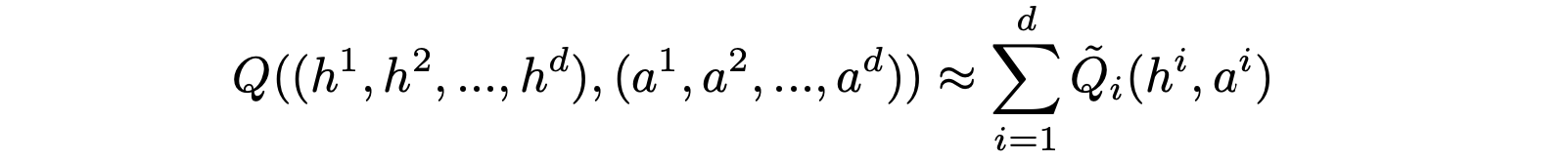

- Value decomposition:
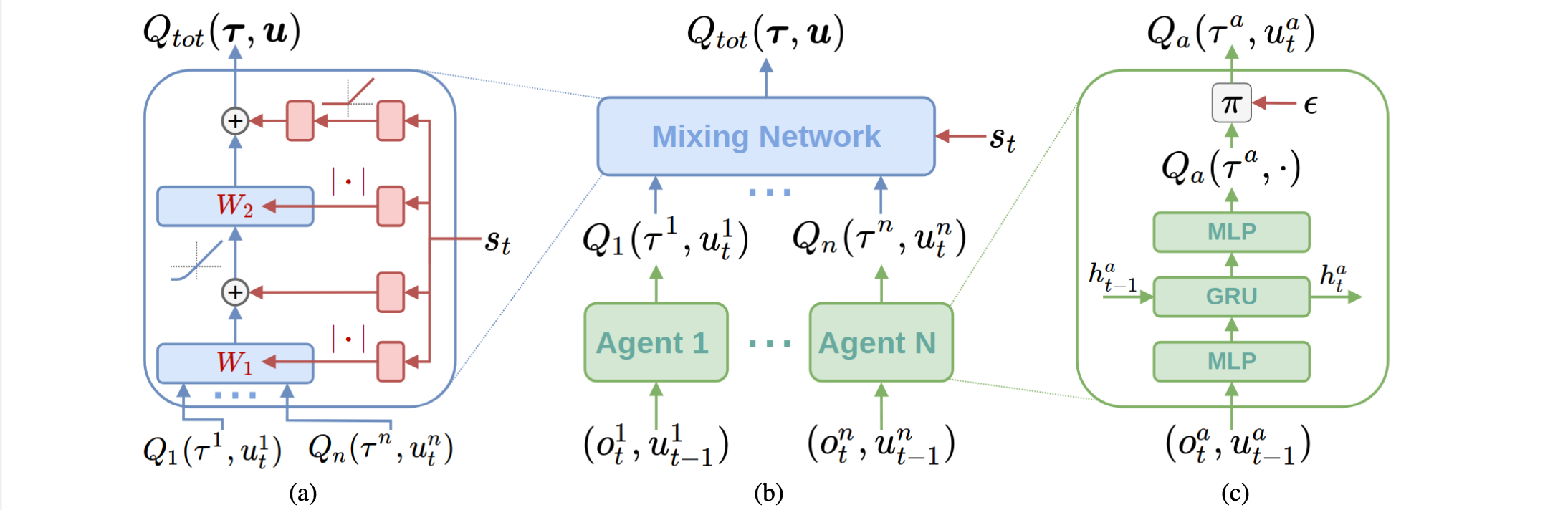

- Value decomposition + policy gradient

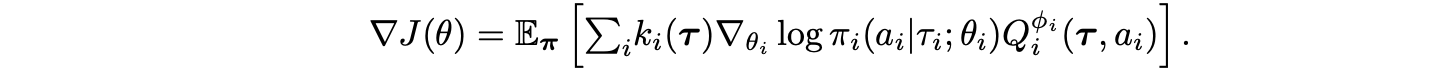


- Value decomposition + policy gradient


- learning value decomposition by taylor approximation of optimal reward

- approximate two terms directly





Shaping individual reward -> maximize real env-reward Learning shaping strategy through optimization (bi-level, black-box, evolutionary,...)
- optimal reward
- reward function maximizing extrinsic environment reward
- Gradient-based learning
- use total reward to update policy parameters:

- update Intrinsic reward use updated policy parameters

- extrinsic reward policy gradient

- chain rules + approximating second terms
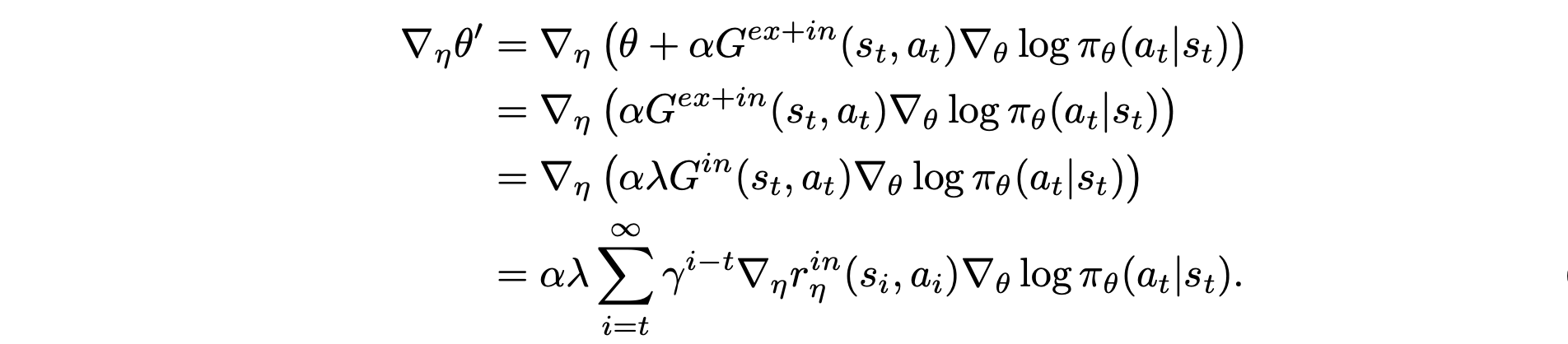
- extrinsic reward policy gradient
- use total reward to update policy parameters:




- adopt intrinsic reward in multi-agent setting (global env reward)
- maximize total env reward through individual intrinsic reward-based policy

- maximize total env reward through individual intrinsic reward-based policy
- Gradient
- update policy using prox reward (in + ex)
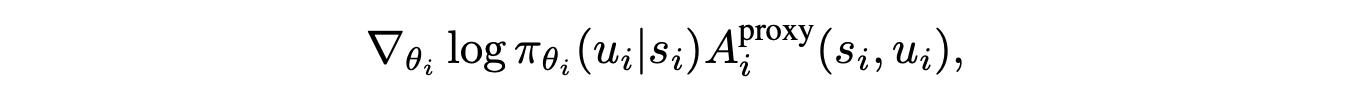
- update intrinsic reward

- first term
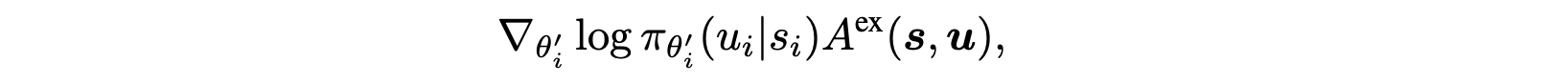
- second term
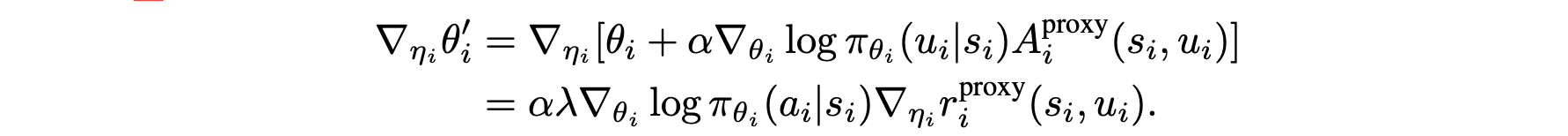
- first term
- update policy using prox reward (in + ex)





- similar as LIIR
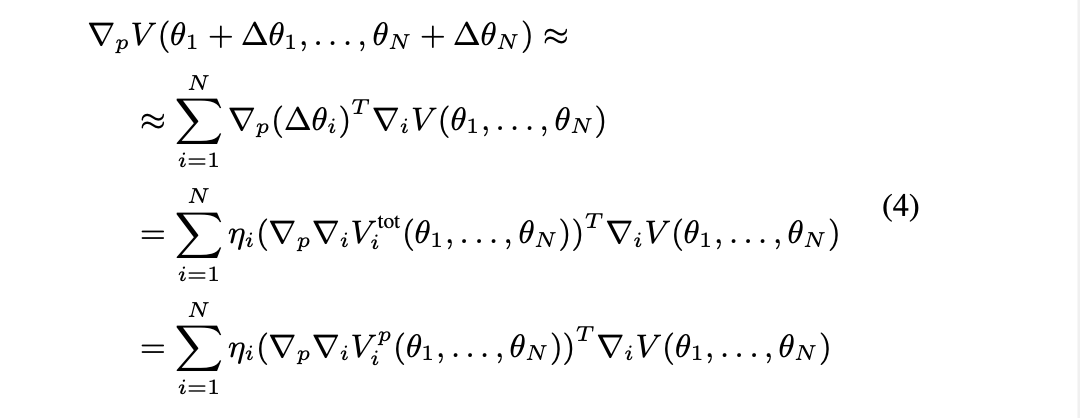

- intrinsic reward comes from other agents (has individual env reward)
- not budget balance

- not budget balance
- gradient
- update individual policy
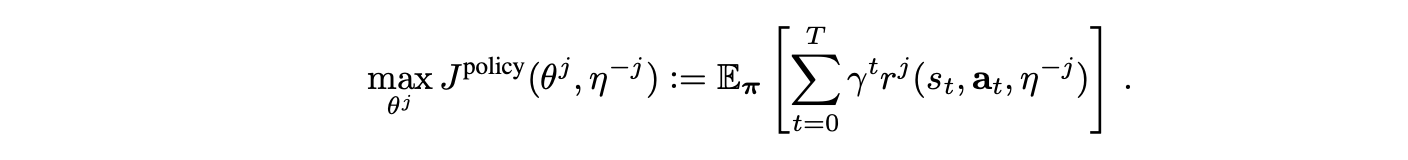
- update intrinsic (incentive) reward:
- maximize individual env reward: (not budget balance)

- the same as LIIR
- maximize individual env reward: (not budget balance)
- update individual policy



- intrinsic reward comes from other agents (has individual env reward)
- generate proportion of assignment reward
$w_{ji}$ - budget balance

- generate proportion of assignment reward
- gradient
- bi-level learning
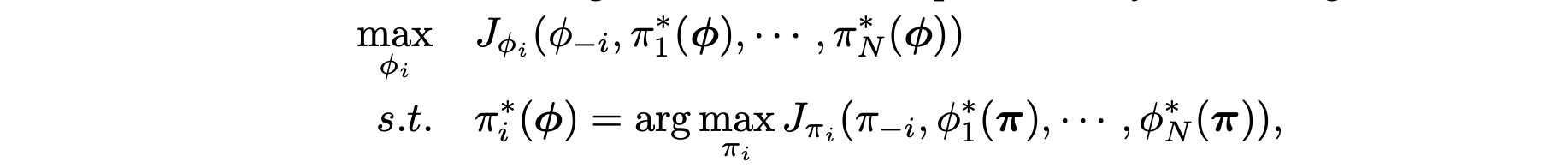
- update policy based on assigned reward
- update weight generator
- bi-level learning


- intrinsic reward
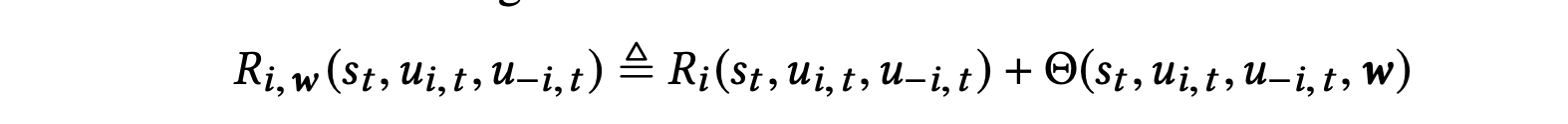
- treat agent learning process with intrinsic reward as black-box
- use bayesian optimization to optimize intrinsic reward
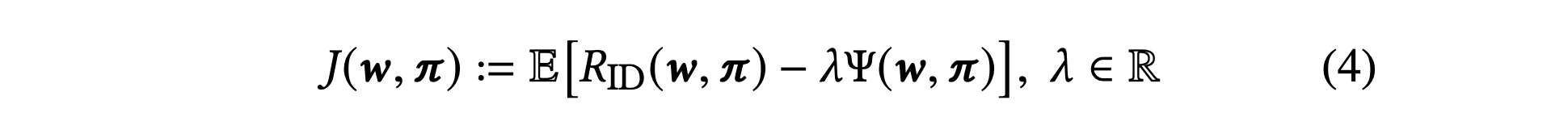
- different with LIIR, with penalty terms


- intrinsic reward
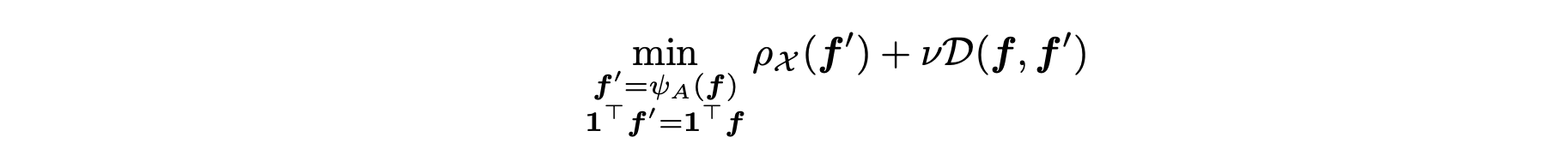
- f': linear combination of reward from other agents
- minimize the divergence of assignment matrix
- objective
- Local Price of Anarchy
- approximating its upper bound

- adopt fully connected neural network to process all information
Emergence of Human-level Coordination in Learning to Play StarCraft Combat Games
- adopt
-
Feudal Reinforcement Learning(1992)
- Reward Hidding: Managers must reward sub-managers for doing their bidding whether or not this satisfies the commands of the super-managers
-
Information Hidding: Managers only need to know the state of the system at the granularity of their own choices of tasks
 {:height="100px" width="400px"}
{:height="100px" width="400px"}
-
Reinforcement Learning with Hierarchies of Machines(1998)
-
Motivation: (a) the policies learning process are constrained by hierarchies of partially specified machines(reduce search space). (b) knowledge can be transferred across problems and in which component solutionscan be recombined to solve larger and more complicated problems

-
Motivation: (a) the policies learning process are constrained by hierarchies of partially specified machines(reduce search space). (b) knowledge can be transferred across problems and in which component solutionscan be recombined to solve larger and more complicated problems
-
Universal Value Function Approximators(2015, David Silver) -Universal value function The pseudo-discount γg takes the double role of statedependent discounting, and of soft termination, in the sense that γ(s) = 0 if and only if s is a terminal state according to goal g
$$V_{g, \pi}(s):=\mathbb{E}\left[\sum_{t=0}^{\infty} R_{g}\left(s_{t+1}, a_{t}, s_{t}\right) \prod_{k=0}^{t} \gamma_{g}\left(s_{k}\right) \mid s_{0}=s\right]$$ $$Q_{g, \pi}(s, a):=\mathbb{E}{s^{\prime}}\left[R{g}\left(s, a, s^{\prime}\right)+\gamma_{g}\left(s^{\prime}\right) \cdot V_{g, \pi}\left(s^{\prime}\right)\right]$$ -Function Approximation Architecture

-
FeUdal Networks for Hierarchical Reinforcement Learning(2017, David Silver)
-
Motivation (1) long timescale credit assignment (2) encourage the emergence of sub-policies associated with different goals set by manager (3) end-to-end HRL

-
Goal Embedding The manager internally computes a latent state representation
$s_t$ and output a goal vector$g_t$ -
Manager Learning
$$z_{t}=f^{\text {percept }}\left(x_{t}\right)$$ $$s_{t}=f^{\text {Mspace }}\left(z_{t}\right)$$ $$h_{t}^{M}, \hat{g}{t}=f^{M r n n}\left(s{t}, h_{t-1}^{M}\right) ; g_{t}=\hat{g}{t} /\left|\hat{g}{t}\right| ;$$$$h^{W}, U_{t}=f^{W r n n}\left(z_{t}, h_{t-1}^{W}\right)$$ $$\pi_{t}=\operatorname{SoftMax}\left(U_{t} w_{t}\right)$$ -
Manager Learning
$$\nabla_{\theta} \pi_{t}^{T P}=\mathbb{E}\left[\left(R_{t}-V\left(s_{t}\right)\right) \nabla_{\theta} \log p\left(s_{t+c} \mid s_{t}, \mu\left(s_{t}, \theta\right)\right)\right]$$ $$p\left(s_{t+c} \mid s_{t}, g_{t}\right) \propto e^{d_{\cos }\left(s_{t+c}-s_{t}, g_{t}\right)}$$ $$\nabla_{\theta} \pi_{t}^{T P}=\mathbb{E}\left[\left(R_{t}-V\left(s_{t}\right)\right) \nabla_{\theta} \log p\left(s_{t+c} \mid s_{t}, \mu\left(s_{t}, \theta\right)\right)\right]$$ -
Intrisic Reward In practice we take a softer approach by adding an intrinsic reward for following the goals, but retaining the environment reward as well
$$r_{t}^{I}=1 / c \sum_{i=1}^{c} d_{\cos }\left(s_{t}-s_{t-i}, g_{t-i}\right)$$ -
Worker Learning
$$\nabla \pi_{t}=A_{t}^{D} \nabla_{\theta} \log \pi\left(a_{t} \mid x_{t} ; \theta\right)$$ $$A_{t}^{D}=\left(R_{t}+\alpha R_{t}^{I}-V_{t}^{D}\left(x_{t} ; \theta\right)\right)$$
-
Motivation (1) long timescale credit assignment (2) encourage the emergence of sub-policies associated with different goals set by manager (3) end-to-end HRL
-
Hierarchical Deep Reinforcement Learning : Integrating Temporal Abstraction andIntrinsic Motivation(2017)
- Problem: sparse reward resulting in insufficient exploration
- Motivation: intrinsically motivated agents to explore new behavior for their own sake rather than directly solve the extenal goals
-
Method: hierarchical reinforcement learning with intrinsic reward


- Meta-controller: The objective of meta-controller is to maximize the extrinsic reward received
$F_{t}=\sum_{t^{\prime}=t}^{\infty} \gamma^{t^{\prime}-t} f_{t^{\prime}}$ from environment and the state-action value function is: $Q_{2}^{}(s, g)=\max {\pi{g}} \mathrm{E}\left[\sum_{t^{\prime}=t}^{t+N} f_{t^{\prime}}+\gamma \max {g^{\prime}} Q{2}^{}\left(s_{t+N}, g^{\prime}\right) \mid s_{t}=s, g_{t}=g, \pi_{g}\right]$ - Controller: The objective of controller is to maximize the intrinsic reward
$R_{t}(g)=\sum_{t^{\prime}=t}^{\infty} \gamma^{t^{\prime}-t} r_{t^{\prime}}(g)$ and the state-action value function is: $\begin{aligned} Q_{1}^{}(s, a ; g) &=\max {\pi{a g}} \mathrm{E}\left[\sum_{t^{\prime}=t}^{\infty} \gamma^{t^{\prime}-t} r_{t^{\prime}} \mid s_{t}=s, a_{t}=a, g_{t}=g, \pi_{a g}\right] \ &=\max {\pi{a g}} \mathrm{E}\left[r_{t}+\gamma \max {a{t+1}} Q_{1}^{}\left(s_{t+1}, a_{t+1} ; g\right) \mid s_{t}=s, a_{t}=a, g_{t}=g, \pi_{a g}\right] \end{aligned}$
-
Hindsight Experience Replay -Motivation (1)The pivotal idea behind HER is to replay each episode with a different goal than the one the agent was trying to achieve, e.g. one of the goals which was achieved in the episode.

-
Data-Efficient Hierarchical Reinforcement Learning
- Challenge Non-stationary off-policy training between high-level controller and low-leverl controller
-
Low-level reward
$$r\left(s_{t}, g_{t}, a_{t}, s_{t+1}\right)=-\left|s_{t}+g_{t}-s_{t+1}\right|_{2}$$ - Off-Policy Corrections for Higher-Level Training Fixed low-level transition, re-label a high-level goal $\tilde{g}{t}$ $$\log \mu^{l o}\left(a{t: t+c-1} \mid s_{t: t+c-1}, \tilde{g}{t: t+c-1}\right) \propto-\frac{1}{2} \sum{i=t}^{t+c-1}\left|a_{i}-\mu^{l o}\left(s_{i}, \tilde{g}{i}\right)\right|{2}^{2}+\mathrm{const}$$








-
Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning(Sutton, 1999)
- MotivationHuman decision making routinely involves choice among temporally extended courses of action over a broad range of time scales
-
Semi-MDP(option-to-option)

-
The option-critic framework
- Motivation Internal policies and the termination conditions of options, in tandem with the policy over options, and without the need to provide any additional rewards or subgoals
-
Architecture

-
option-value function
$$Q_{\Omega}(s, \omega)=\sum_{a} \pi_{\omega, \theta}(a \mid s) Q_{U}(s, \omega, a)$$ -
state-action value function
$$Q_{U}(s, \omega, a)=r(s, a)+\gamma \sum_{s^{\prime}} \mathrm{P}\left(s^{\prime} \mid s, a\right) U\left(\omega, s^{\prime}\right)$$ $$U\left(\omega, s^{\prime}\right)=\left(1-\beta_{\omega, \vartheta}\left(s^{\prime}\right)\right) Q_{\Omega}\left(s^{\prime}, \omega\right)+\beta_{\omega, \vartheta}\left(s^{\prime}\right) V_{\Omega}\left(s^{\prime}\right)$$ $$\mathrm{P}\left(s_{t+1}, \omega_{t+1} \mid s_{t}, \omega_{t}\right)=\sum_{a} \pi_{\omega_{t}, \theta}\left(a \mid s_{t}\right) \mathrm{P}\left(s_{t+1} \mid s_{t}, a\right)($$ $$\left.\left(1-\beta_{\omega_{t}, \vartheta}\left(s_{t+1}\right)\right) \mathbf{1}{\omega{t}=\omega_{t+1}}+\beta_{\omega_{t}, \vartheta}\left(s_{t+1}\right) \pi_{\Omega}\left(\omega_{t+1} \mid s_{t+1}\right)\right)$$
-
Learning to Interrupt: A Hierarchical Deep Reinforcement Learning Framework for Efficient Exploration
-
state-value function


-
state-value function
-
STOCHASTIC NEURAL NETWORKS FOR HIERARCHICAL REINFORCEMENT LEARNING(2017, Pieter Abbeel)
- Motivation Using Stochastic Neural Networks combined with an information-theoretic regularizer to pre-train a span of skills



