
- Samuel Mohebban
- Raven Welch
- Ideally, customers are always satisfied with a company's services, however, this is rarely the case
- Twitter is a cornerstrone for communication as many customers share their issues on the platform. For customers, Twitter is accessible and can offer ways for a customer to directly communicate with larger companies such as Google and Apple
- Manually screening each tweet can be costly and time consuming
- We wanted to create a Machine Learning algorithm that can correctly detect sentiment within tweets.
- By accomplishing this, a company can better screen customer feedback and attend to any issues they may be having
- Brands and Product Emotion Dataset
- Comprised of 9000 tweets regarding sentiment towards Apple and Google Products
- Gathered in August 2013
- Removed 'No Emotion' and 'Unknown'
- Data was pruned to 600 Positive Tweets and 570 Negative Tweets so that our final dataset had an equal class balance for each target


- Cleaned the data to remove the following:
- names
- usernames
- non-alphabetical characters
- and stop words such as “so”, “a”, and “we”
- Stemmed each word within our data
- Ex: “Likes”, “Liked”, “Likely”, “Liking” all become “Like”
- Applied KMeans clustering with n_clusters = 6
- Split into Training and Test sets for modeling
- Train → 994 (50% Positive, 50% Negative)
- Test → 176 (50% Positive, 50% Negative)
- Using Sum of Square differences, we found the optimal cluster size to be equal to 6
- We then used PCA dimension reduction to reduce our values onto a 3-demensional plane in order to create the visualization below
- code for 3D plot


- Our base model is a stacked classifier
- Initially, we tried various models and tested each alone, and together within a stacked classifier
- We then iterated 3 times, each time pruning the least accurate models in order to increase the accuracy of our stacked classifier
- For each run, we used SKlearn's RepeatedStratifiedKFold to compare each model's accuracy.
- code
- After the first test, we pruned KNN, DecisionTree, and LDA. These models all had a majority of scores lower than 75% and very wide ranges
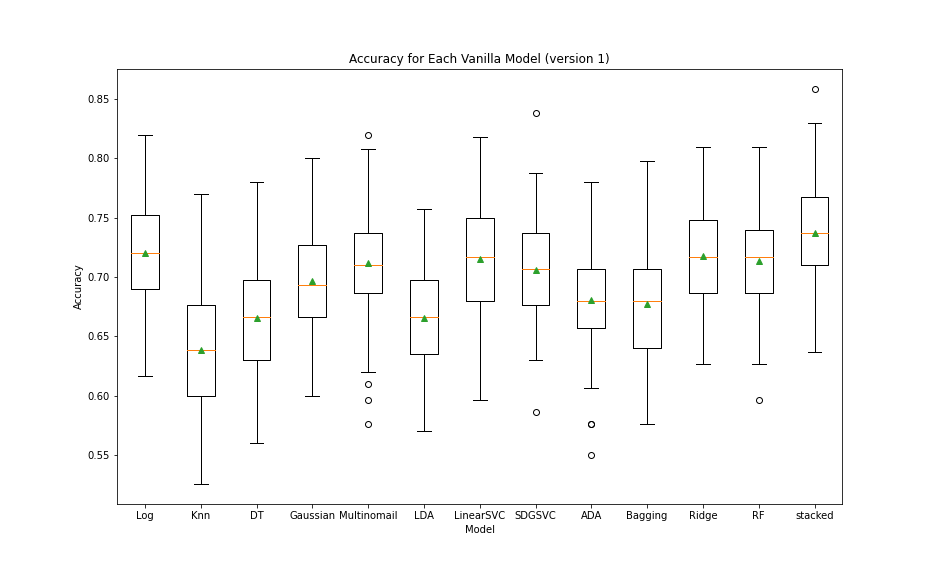

- After the second test, we then pruned ADA, Bagging, and Gaussian classifier due to their wide ranges and low accuracies
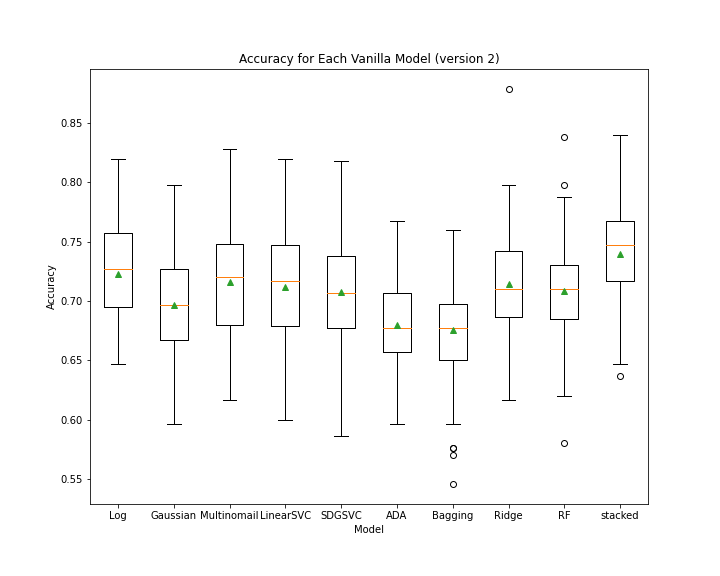

- Finally, we pruned only the Bagging Classifier, leaving us with LogisticRegression, MultinomialNB, LinearSVC, SDGSVC, RidgeClassifier, and RandomForestClassifier
- Although the stacked classifier did not perform much better than other classifiers alone, the range was tighter and provided more consistent predictions

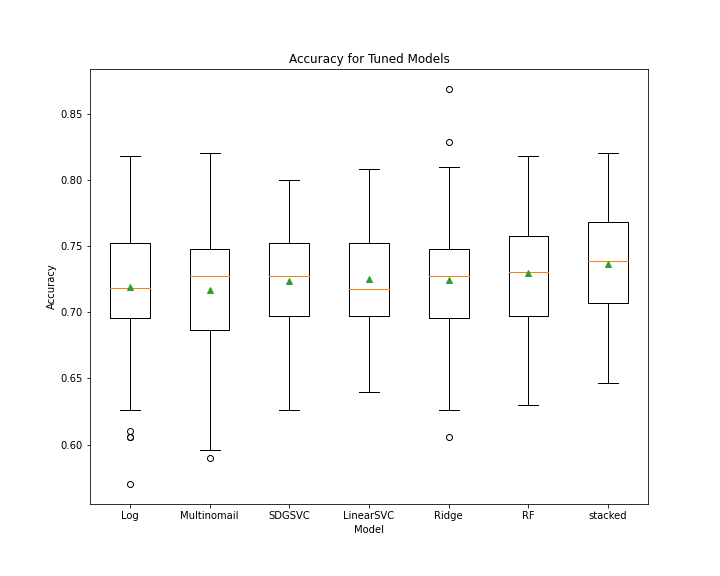
- For each model mentioned above, we tuned the hyperparameters than repeated the RepeatedStratifiedKFold
- Again, we see that the stacked classifier did not perform much better than the other classifiers alone, but there was evidence of a tighter range and thus more consistent predictions
- The stacked classifier was chosen as the final model because Stacked Classifiers improve with variation. Although we see in our example that it did not do much better, with the inclusion of more data that is unknown is might perform better than the latter.


- Train
- 97% True Negative Rate
- 3% False Negative Rate
- 98% True Positive Rate
- 2% False Positive Rate
- Test
- 83% True Negative Rate
- 17% False Negative Rate
- 81% True Positive Rate
- 19% False Positive Rate

- Because there are various models used within our stacked classifier. We found the top 50 most important features (words) for each model using SKlearn's Feature_Selection module and counted the frequency of each word.
- As seen below, the words "headache", "hate", and "battery" all showed up 6 times. This means that across all of our models within the stacked classifier, these words were among the top 50 most important features 6 times.

- For more information regarding how to use LIME please visit their GitHub Repo
- Below, you see the feature weights and their corresponding importance for making a prediction. The words seen below make sense considering their connotations within the english language

- Data was collection ~7 years ago. This can be problematic because words and phrases change year to year. So an algorithm such as this one can only be applied to understanding sentiment of Tweets that were made in 2013.
- Huge data imbalance. Our strategy to fix this imbalance was to undersample the class with the higher frequency - Positive class. However, in doing this, we limited our data to only 1000 points which could have been a bottleneck within our training
- MORE DATA!
- Refine the model to include specific slang that is relevant to the current era
- analyze specifically what the users are frustrated or happy with (Iphone, Android, etc.)
- Create a ternary classification problem that can not only detect positive and negative sentiment, but also neutral sentiment as well
