将VOC2012数据解压到文件夹VOC2012中,注意检查下一级目录包含Annotations文件夹和JPEGImages文件夹。
使用jupyter运行tfr_generate.ipynb脚本,使用TFR格式压缩图片对于提升训练速度大有裨益
调用脚本即可
python train_ssd_network.py进入eval目录,运行:
python show_ssd_network.py在该脚本中有设置图片路径的位置,替换为想要检测的图片即可。
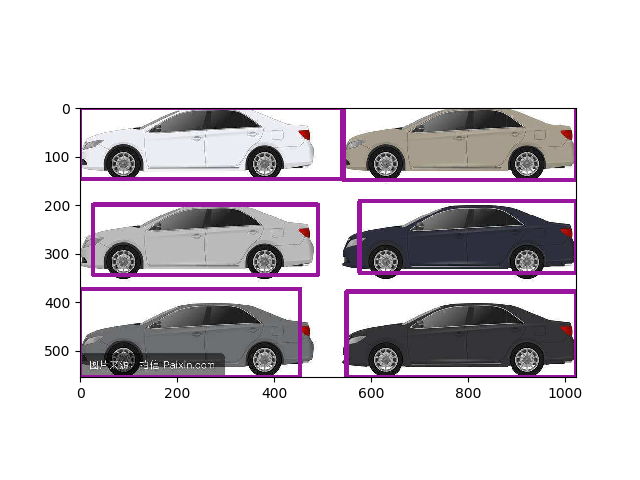
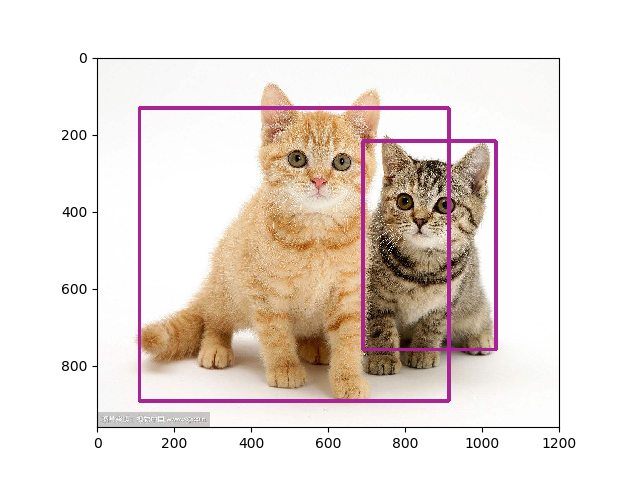
本工程17w steps后结果(框体过多的可以将NMS阈值减小):
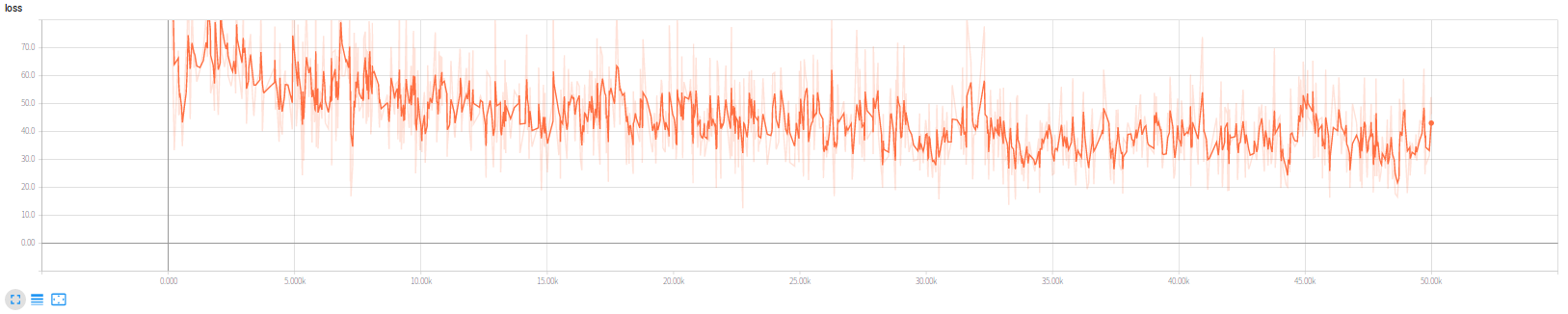
损失函数变化情况如图:
SSD架构主要有四个部分,网络设计、搜索框设计、学习目标处理、损失函数实现。
重点在于正常前向网络中挑选出的特征层分别添加两个卷积出口:分类和回归出口,用于对应后面的每个搜索框的各个类别得分、以及4个坐标值。
对应网络的特征层:每个层有若干搜索框,我们需要搜索框位置形状信息。对于tf版本我们保存了每个框的中心点以及HW信息,而mx版本我们保存的是左上右下两个的4个坐标数值,mx更为直观,但是tf版本节省空间:一组框对应同一个中心点,不过搜索框信息量不大,b无伤大雅。
个人感觉最为繁琐,我们需要的的信息包含(此时已经获得了):一组搜索框(实际上指的是全部搜索框的n4个坐标值),图片的label、图片的真实框坐标(对应label数目4),我们需要的就是找到搜索框和真是图片的标签联系,
获取:
每个搜索框对应的分类(和哪个真实框的IOU最大就选真实框的类别标注给该搜索,也就是说会出现大量的0 class搜索框)
每个搜索框的坐标的回归目标(同上的寻找方法,空位也为0)
负类掩码,虽然每张图片里面通常只有几个标注的边框,但SSD会生成大量的锚框。可以想象很多锚框都不会框住感兴趣的物体,就是说跟任何对应感兴趣物体的表框的IoU都小于某个阈值。这样就会产生大量的负类锚框,或者说对应标号为0的锚框。对于这类锚框有两点要考虑的:
1、边框预测的损失函数不应该包括负类锚框,因为它们并没有对应的真实边框
2、因为负类锚框数目可能远多于其他,我们可以只保留其中的一些。而且是保留那些目前预测最不确信它是负类的,就是对类0预测值排序,选取数值最小的哪一些困难的负类锚框
所以需要使用掩码,抑制一部分计算出来的loss。
损失函数可讲的不多,按照公式实现即可,重点也在上一步计算出来的掩码处理损失函数值一步。
截止目前,本改版网络已经可以正常运行稳定收敛,之前的问题及解决思路如下:
这个问题实际上是因为我个人的疏忽,将未预处理的图片送入ssd.bboxes_encode函数中,修正后如下,
image, glabels, gbboxes = \
tfr_data_process.tfr_read(dataset)
image, glabels, gbboxes = \
preprocess_img_tf.preprocess_image(image, glabels, gbboxes, out_shape=(300, 300))
gclasses, glocalisations, gscores = \
ssd.bboxes_encode(glabels, gbboxes, ssd_anchors)这个疏忽导致Loss值维持在200~400之间且不收敛,修改后经过300左右steps损失函数会稳定到60左右,和原SSD网络一致(示意如下)。

原SSD模型训练速度(CPU:E5-2690,GPU:1080Ti)大概50 samples/sec(实际上略高与此),我的训练速度仅仅22-24 samples/sec,经对比查验,应该是节点分配硬件设备的配置优化问题,涉及队列(主要是数据输入)、优化器设定的节点分派给CPU后(其他节点会默认优先分配给GPU),速度明显提升,大概到达44-46 samples/sec。
另外,tfr数据解析过程放在GPU下,生成队列过程放在CPU下有不明显加速,理想情况下能提升0-1 samples/sec。
综上,现阶段的程序比原程序训练阶段还是要慢5 samples/sec左右,原因还在排查中。
参考资料见博客,由于该作者写的很好,稍作调整即可使用。