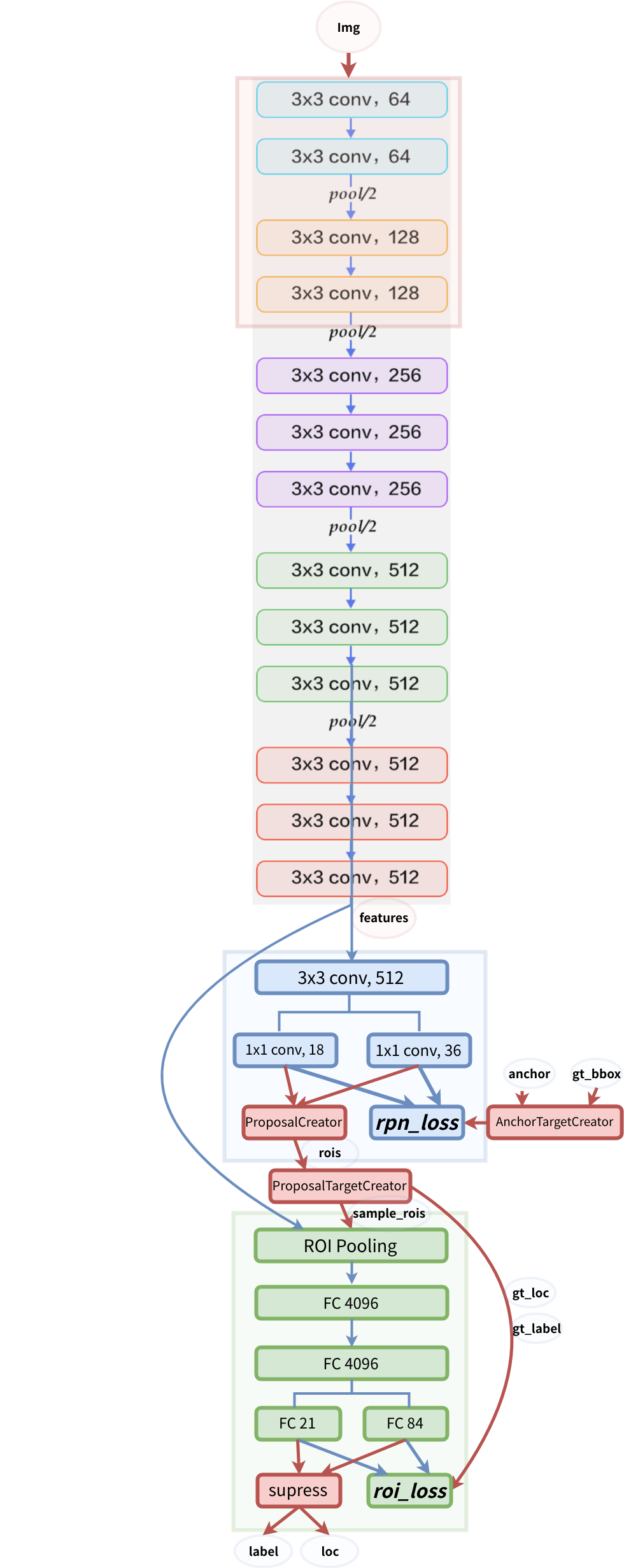
This project is a Simplified Faster R-CNN implementation based on chainercv and other projects . It aims to:
- Simplify the code (Simple is better than complex)
- Make the code more straightforward (Flat is better than nested)
- Match the performance reported in origin paper (Speed Counts and mAP Matters)
And it has the following features:
- It can be run as pure Python code, no more build affair. (cuda code moves to cupy, Cython acceleration are optional)
- It's a minimal implemention in around 2000 lines valid code with a lot of comment and instruction.(thanks to chainercv's excellent documentation)
- It achieves higher mAP than the origin implementation (0.712 VS 0.699)
- It achieve speed compariable with other implementation (6fps and 14fps for train and test in TITAN XP with cython)
- It's memory-efficient (about 3GB for vgg16)

VGG16 train on trainval and test on test split.
Note: the training shows great randomness, you may need a bit of luck and more epoches of training to reach the highest mAP. However, it should be easy to surpass the lower bound.
| Implementation | mAP |
|---|---|
| origin paper | 0.699 |
| train with caffe pretrained model | 0.700-0.712 |
| train with torchvision pretrained model | 0.685-0.701 |
| model converted from chainercv (reported 0.706) | 0.7053 |
| Implementation | GPU | Inference | Trainining |
|---|---|---|---|
| origin paper | K40 | 5 fps | NA |
| This[1] | TITAN Xp | 14-15 fps | 6 fps |
| pytorch-faster-rcnn | TITAN Xp | 15-17fps | 6fps |
[1]: make sure you install cupy correctly and only one program run on the GPU. The training speed is sensitive to your gpu status. see troubleshooting for more info. Morever it's slow in the start of the program.
It could be faster by removing visualization, logging, averaging loss etc.
requires python3 and PyTorch 0.3
-
install PyTorch >=0.3 with GPU (code are GPU-only), refer to official website
-
install cupy, you can install via
pip installbut it's better to read the docs and make sure the environ is correctly set -
install other dependencies:
pip install -r requirements.txt -
Optional, but strongly recommended: build cython code
nms_gpu_post:cd model/utils/nms/ python3 build.py build_ext --inplace -
start vidom for visualization
nohup python3 -m visdom.server &Download pretrained model from Google Drive or Baidu Netdisk( passwd: scxn)
See demo.ipynb for more detail.
-
Download the training, validation, test data and VOCdevkit
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
-
Extract all of these tars into one directory named
VOCdevkittar xvf VOCtrainval_06-Nov-2007.tar tar xvf VOCtest_06-Nov-2007.tar tar xvf VOCdevkit_08-Jun-2007.tar
-
It should have this basic structure
$VOCdevkit/ # development kit $VOCdevkit/VOCcode/ # VOC utility code $VOCdevkit/VOC2007 # image sets, annotations, etc. # ... and several other directories ...
-
modify
voc_data_dircfg item inutils/config.py, or pass it to program using argument like--voc-data-dir=/path/to/VOCdevkit/VOC2007/.
TBD
If you want to use caffe-pretrain model as initial weight, you can run below to get vgg16 weights converted from caffe, which is the same as the origin paper use.
python misc/convert_caffe_pretrain.pyThis scripts would download pretrained model and converted it to the format compatible with torchvision.
Then you should specify where caffe-pretraind model vgg16_caffe.pth stored in utils/config.py by setting caffe_pretrain_path
If you want to use pretrained model from torchvision, you may skip this step.
NOTE, caffe pretrained model has shown slight better performance.
NOTE: caffe model require images in BGR 0-255, while torchvision model requires images in RGB and 0-1. See data/dataset.pyfor more detail.
mkdir checkpoints/ # folder for snapshotspython3 train.py train --env='fasterrcnn-caffe' --plot-every=100 --caffe-pretrain you may refer to utils/config.py for more argument.
Some Key arguments:
--caffe-pretrain=False: use pretrain model from caffe or torchvision (Default: torchvison)--plot-every=n: visualize prediction, loss etc everynbatches.--env: visdom env for visualization--voc_data_dir: where the VOC data stored--use-drop: use dropout in RoI head, default False--use-Adam: use Adam instead of SGD, default SGD. (You need set a very lowlrfor Adam)--load-path: pretrained model path, defaultNone, if it's specified, it would be loaded.
you may open browser, visit http://<ip>:8097 and see the visualization of training procedure as below:

If you're in China and encounter problem with visdom (i.e. timeout, blank screen), you may refer to visdom issue, and see troubleshooting for solution.
-
visdom
Some js files in visdom was blocked in China, see simple solution here
Also,
updata=appenddoesn't work due to a bug brought in latest version, see issue and fixYou don't need to build from source, modifying related files would be OK.
-
dataloader:
received 0 items of ancdatasee discussion, It's alreadly fixed in train.py. So I think you are free from this problem.
-
cupy
numpy.core._internal.AxisError: axis 1 out of bounds [0, 1)bug of cupy, see issue, fix via pull request
You don't need to build from source, modifying related files would be OK.
-
VGG: Slow in construction
VGG16 is slow in construction(i.e. 9 seconds),it could be speed up by this PR
You don't need to build from source, modifying related files would be OK.
-
About the speed
One strange thing is that, even the code doesn't use chainer, but if I remove
from chainer import cuda, the speed drops a lot (train 6.5->6.1,test 14.5->10), because Chainer replaces the default allocator of CuPy by its memory pool implementation. But ever since V4.0, cupy use memory pool as default. However you need to build from souce if you are gona use the latest version of cupy (uninstall cupy -> git clone -> git checkout v4.0 -> setup.py install) @_@Another simple fix: add
from chainer import cudaat the begining oftrain.py. in such case,you'll need topip install chainerfirst.
- training on coco
- resnet
- Maybe;replace cupy with THTensor+cffi?
- Maybe:Convert all numpy code to tensor?
- check python2-compatibility
This work builds on many excellent works, which include:
- Yusuke Niitani's ChainerCV (mainly)
- Ruotian Luo's pytorch-faster-rcnn which based on Xinlei Chen's tf-faster-rcnn
- faster-rcnn.pytorch by Jianwei Yang and Jiasen Lu.It mainly refer to longcw's faster_rcnn_pytorch
- All the above Repositories have referred to py-faster-rcnn by Ross Girshick and Sean Bell either directly or indirectly.
Licensed under MIT, see the LICENSE for more detail.
Contribution Welcome.
If you encounter any problem, feel free to open an issue.
Correct me if anything is wrong or unclear.
model structure