A little bit of play with OpenPose without using their API but allowing to build / prototype pre and post-processing steps in Keras. Please keep in mind that this is more of a toy project and not anything even close to any production applications. If you are looking for something more useful please invest some time and get the actual OpenPose up and running :)
Table of contents:
- Body keypoint estimation network (coming soon)
- Face keypoint estimation network (coming soon)
- Hand keypoint estimation network
- External resources
Please check out the demo on yt: https://www.youtube.com/watch?v=FnoI8ufwhbs
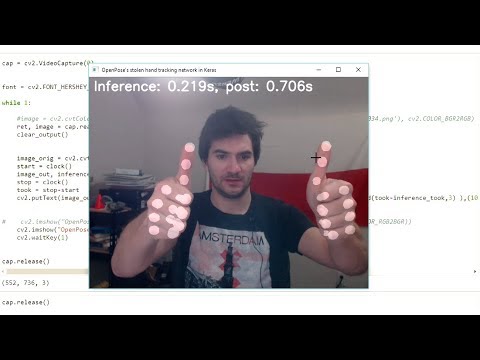
Original model can be found on the OpenPose's github. Model weights converted from Caffe model definition available for download: https://drive.google.com/file/d/1yPQFrCrDltqzYAnWBl__O7oZxGL0sQlu/view The readme on the main page says that the "hand keypoint detection" 2x21 keypoint estimation. The network itself outputs 22 channels (21 keypoints + background). The final layer feeds from the 128-deep convolutional layer (Mconv6_stage6). It is defined as follows (as defined in the models/hand/pose_deploy.prototxt):
layer {
name: "Mconv7_stage6"
type: "Convolution"
bottom: "Mconv6_stage6"
top: "net_output"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 22
pad: 0
kernel_size: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
dilation: 1
}
}
Keep in mind that this particular network does NOT produce any part affinity fields, just finger-keypoints. OpenPose's documentation contains the following picture describing the keypoint channel ids:

I believe that the natural resolution of the input images (e.g. the standard network input size) is 368 on the width and whatever turns out to be on the height. From the papers presenting this method one figure out that the authors use multi-scale inputs. Basically they go through different scales from 0.5 to 1.5 and average the heatmaps. Network accepts 3 channel RGB images with 32-bit floating point values scaled between -0.5 <= x <= 0.5.
I haven't studied the code of the OpenPose library very well (yet!) but I noticed that the returned heatmaps seem to have bi-modal distributions. E.g. some values of detections are strongly negative and some are strongly positive. I understood that it may be their way of distinguishing the left hand from the right one. I still need to investigate that.
- It seems like the model does not capture hand keypoints when exposed to images of people wearing gloves. I haven't figured out how exaclty the network was trained, but I can imagine that there was no emphasis on glove-wearing targets.
- OpenPose GitHub repo: https://github.com/CMU-Perceptual-Computing-Lab/openpose
- Origin of OpenPose: https://github.com/ZheC/Realtime_Multi-Person_Pose_Estimation
- Paper describing the method: https://arxiv.org/abs/1611.08050
- Keras implementation of the Realtime Multi-Person Pose Estimation (my major inspiration): https://github.com/michalfaber/keras_Realtime_Multi-Person_Pose_Estimation