A demo for illustrating how to use torch.nn.parallel.DistributedDataParallel with multiple GPUs in one machine. The program is modified from PyTorch example Image classification (MNIST) using Convnets.
runMNIST.py: use single GPUrunMNIST_DDP.py: use multiple GPUs in one machinelogsfolder contains the log files
- Intel(R) Xeon(R) CPU E5-2678 v3 @ 2.50GHz
- 4 GeForce RTX 2080 Ti Graphics Cards
- 128 GB RAM
- Python 3.7.4
- PyTorch 1.4.0
For DDP example runMNIST_DDP.py, you must run the program in the terminal directly (instead of some python IDEs) if you wish to use multiple GPUs:
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE --master_port ANY_LOCAL_PORT runMNIST_DDP.py
# For example
python -m torch.distributed.launch --nproc_per_node=4 --master_port 22222 runMNIST_DDP.py
NUM_GPUS_YOU_HAVE is the number of GPUs you will use which must be consistent with line 233 of runMNIST_DDP.py. ANY_LOCAL_PORT is a random port number which is not occupied (larger than 1023).
For single GPU example runMNIST.py or runMNIST_DDP.py using CPU or single GPU, directly run it in terminal or any IDEs:
python runMNIST.py
python runMNIST_DDP.py
Compare runMNIST_DDP.py with runMNIST.py and pay attention to the comments starting with DDP Step. These are what you need to add to make your program parallelized on multiple GPUs.
- DDP Step 1: Devices and random seed are set in set_DDP_device().
- DDP Step 2: Move model to devices.
- DDP Step 3: Use DDP_prepare to prepare datasets and loaders.
- DDP Step 4: Manually shuffle to avoid a known bug for DistributedSampler.
- DDP Step 5: Only record the global loss value and other information in the master GPU.
- DDP Step 6: Collect loss value and other information from each GPU to the master GPU.
The log files in logs folder show that using single GPU costs 183.18 seconds and using 4 GPUs costs 112.59 seconds. Sometimes using more GPUs will not significantly reduce the time. Instead, more RAM is needed since some data is copied for parallelization. You must choose an appropriate number of GPUs for your program.
torch.nn.DataParallelis not recommended over multiple GPUs. Check the officical documents for the reasons.- To simplify, the program assumes the batch size is divisible by the number of GPUs, e.g., batch size is 64 and 4 GPUs are used.
- Use
master_printinstead ofprintto avoid printing duplicated information. - For reproducibility, we must manually set a random seed.
set_DDP_device()function inDDPUtil.pyhas done this by callingset_seed(). This way, you will always get the same results when running the program. - Functions in
DDPUtil.pyare designed to be flexible so that it supports using CPU, using single GPU and using multiple GPUs with DDP. You can change lines 231-233 ofrunMNIST_DDP.py. Writing you program likerunMNIST_DDP.pyso that you can debug with single GPU or CPU and run program with multiple GPUs after your finish designing your program. - DataLoader has a parameter
num_workerswhich means how many processes are processing the data in CPU for loading batch data. Increasingnum_workerswill make your program faster too. Check line 206 ofrunMNIST_DDP.py. - To access custom functions except
forwardor class variables, usemodel.module.function()ormodel.module.variablesince DDP has wrapped your original model. - When running program with DDP, make sure to monitor the GPU usage with
watch -n 1 nvidia-smiand check whether all the GPUs are working properly. For example, the following picture shows the usage of GPUs when runningrunMNIST_DDP.pywith four GPUs: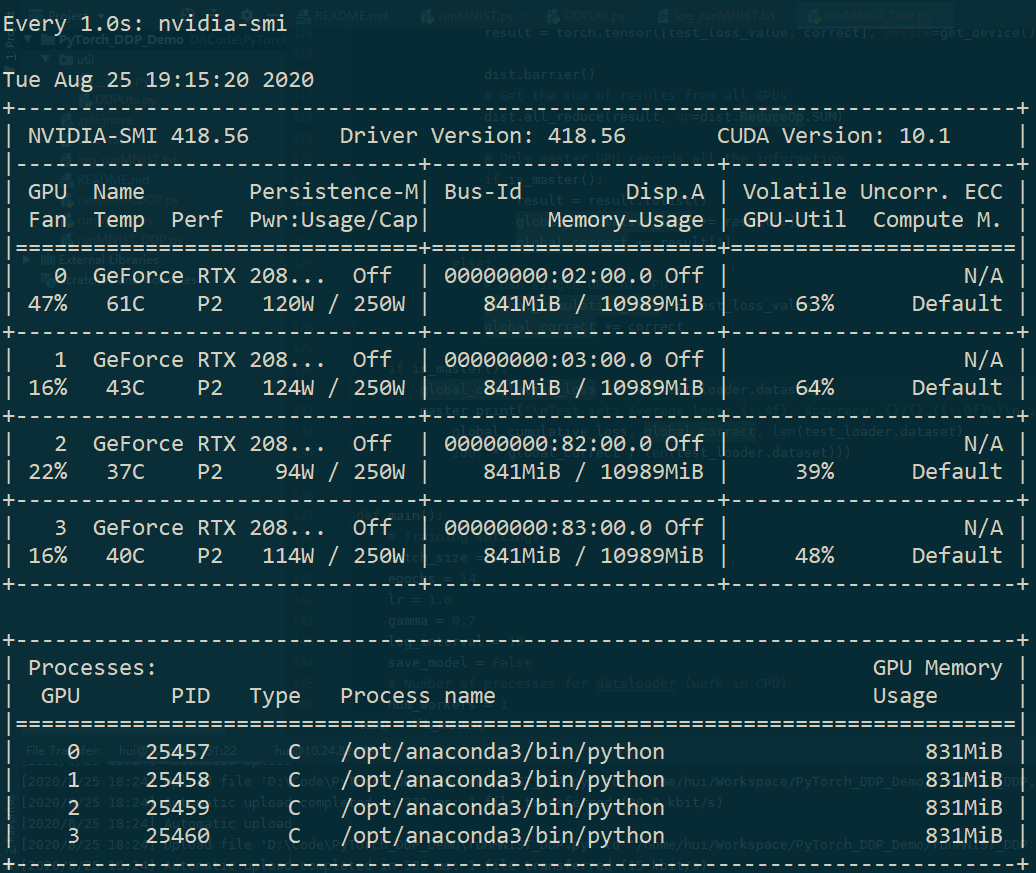
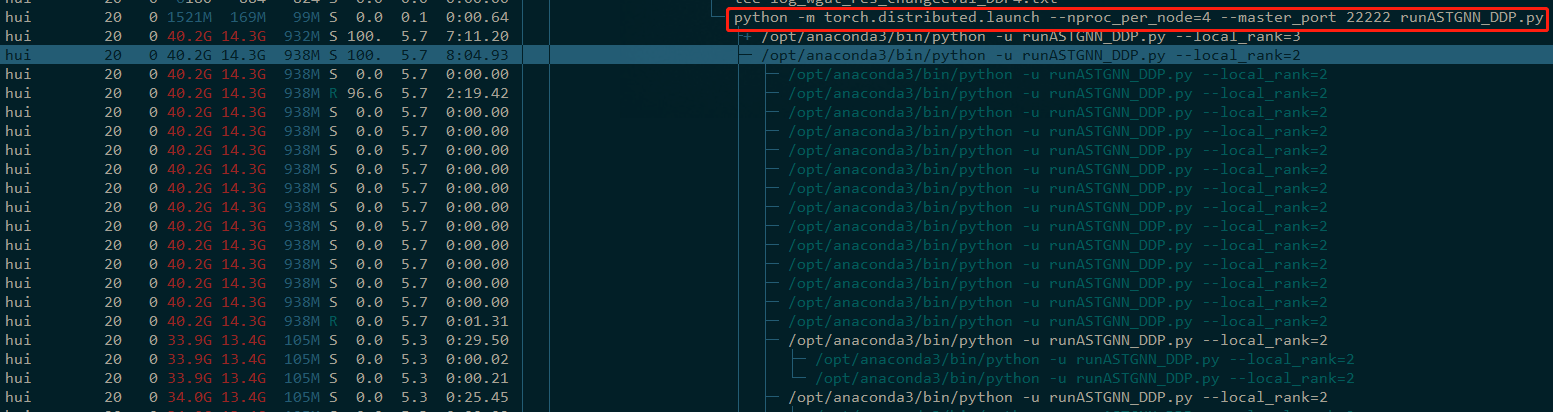
- If you manually stop the program using multiple GPUs, use
htop -u YOUR_USER_NAMEto check whether all the processes are really killed. For example, the following picture shows that my programrunASTGNN_DDP.pyhas 4 processes with different local rank numbers. You can usepkill -f "runASTGNN_DDP.py"to kill all the processes partially matching the namerunASTGNN_DDP.py.