
这是一个关于AI-ISP模块:Noise Reduction 的工程实现文档,针对目标camera如(sensor:IMX766)梳理AI降噪的实现流程,该项目包含:数据准备、模型设计、模型训练、模型压缩、模型推理等。请先确保安装该项目的依赖项,通过git clone下载该项目,然后在该项目的根目录下执行以下命令安装依赖项。
docker pull huiiji/ubuntu_torch1.13_python3.8:latest #docker images约20G,请耐心下载
docker run -it --gpus all -v /yourpath:/mnt huiiji/ubuntu_torch1.13_python3.8:latest /bin/bash #/yourpath为你的根路径
git clone https://github.com/HuiiJi/AISP_NR.git
chmod -R 777 AISP_NR/
cd AISP_NRTips: 该项目的依赖项包括pytorch、torchvision、numpy、opencv-python、pyyaml、tensorboard、torchsummary、torchsummaryX、torch2trt、onnx、onnxruntime等,你可以通过docker pull来下载镜像images并启动容器container来完成环境配置,docker的安装请参考官方文档。
├── assets
├── IMX766
| ├── black_img
| ├── calibrate_img
| ├── test_data
| ├── train_data
├── infer_model
| ├── inference.py
| ├── infer_config.yaml
├── train_model
| ├── training
| ├── tensorboard
| ├── log
| ├── checkpoints
| ├── run.sh
| ├── train_config.yaml
| ├── train.py
| ├── make_dataloader.py
├── utils
| ├── tools.py
| ├── make_dataset.py
| ├── noise_profile.py
├── demo.py
AI降噪模型开发的第一步也是非常重要的一步,数据采集,训练数据分布与推理场景有较大的域差异则会显著降低降噪表现。 以监督学习为例,监督学习需要成对的数据,即有噪声的图像和无噪声的图像,可以通过以下方式获得。
实拍数据可来源于开源数据集,其提供了camera实拍成对的匹配数据,GT可以通过静止多帧平均、低ISO等方式得到,以下是一些开源数据集。
| Dataset | URL | Domain |
|---|---|---|
| DND | url | RAW |
| SID | url | RAW |
| SIDD | url | RAW+RGB |
| Renoir | url | RAW |
| MIT-Adobe FiveK | url | RAW+RGB |
优点:实拍数据与推理场景的域差异较小,因此不需要进行数据增强,以及噪声标定,可以直接用于训练。
缺点:数据集camera的噪声分布与推理场景有较大的域差异,通常不能直接应用于不同的camera,需要进一步处理,且拍摄负担较大。
Tips:实拍开源数据集可以作为benchmark来测试AI model的降噪表现,但一般不直接用于训练集的构建。
这里是一些关于RAW domain噪声模型的开源项目,你可以从这些介绍中了解更多关于噪声模型的知识。
| Paper | Code | Noise Model | Year&lab |
|---|---|---|---|
| UPI | code | P + G | CVPR 2019 |
| PMRID | code | P’ + G | ECCV 2020 |
| ELD | code | P’ + TL | CVPR 2021 |
| Rethinking | code | P’ + Sample | ECCV 2022 |
优点:可以根据噪声模型合成任意数量的数据,可以用于训练。
缺点:需要标定噪声模型,不合理的噪声模型直接导致降噪模型的表现不佳。
Tips:应用ELD等先进的噪声模型可以提高极暗光(<1lux)场景下的信噪比和清晰度,本文不详细讨论不同噪声模型的优劣。
噪声标定是指针对目标camera采集基准帧,计算均值方差等数据属性来拟合噪声分布,从而得到目标camera噪声模型的参数。本章采用一种普遍的RAW domain噪声模型,即Poisson-Gaussian噪声模型,具体操作如下。

- 针对目标camera:手机摄像头realme-大师探索GT(sensor:IMX766),采集一组基准黑帧,如下图所示。
- 在暗室内将摄像头盖住避免进光照射,采集camera直出的RAW,其求均值得到黑电平。
- 采集的黑帧数量越多,平均后得到的黑电平越准确,通常可以将黑帧数量设置为5,本次实验为3。

- 准备灰度卡,调整不同ISO进行拍摄,得到一组灰度帧,如上图所示。
- 采集的灰度帧数量越多,噪声分布越准确,通常可以采集5组不同ISO(如500~6400)档位。
- 需要确保不同ISO下的灰度帧数量相同,否则会导致噪声分布不准确。
- 适当调整环境光照和曝光,避免环境光照的变化导致灰度帧的曝光不一致。
-
-
通过基准黑帧得到黑电平,对拍摄到的灰度帧应用黑电平得到归一化的RAW。
-
标定灰度帧的ROI区域,并且记录该区域的详细坐标,作为噪声分布的采样区域,如下图红框所示。

-
不同ISO下的ROI均值作横轴,方差作纵轴,拟合一次函数得到斜率和截距,得到Poisson-Gaussian噪声模型中参数k和sigma,如下图所示。
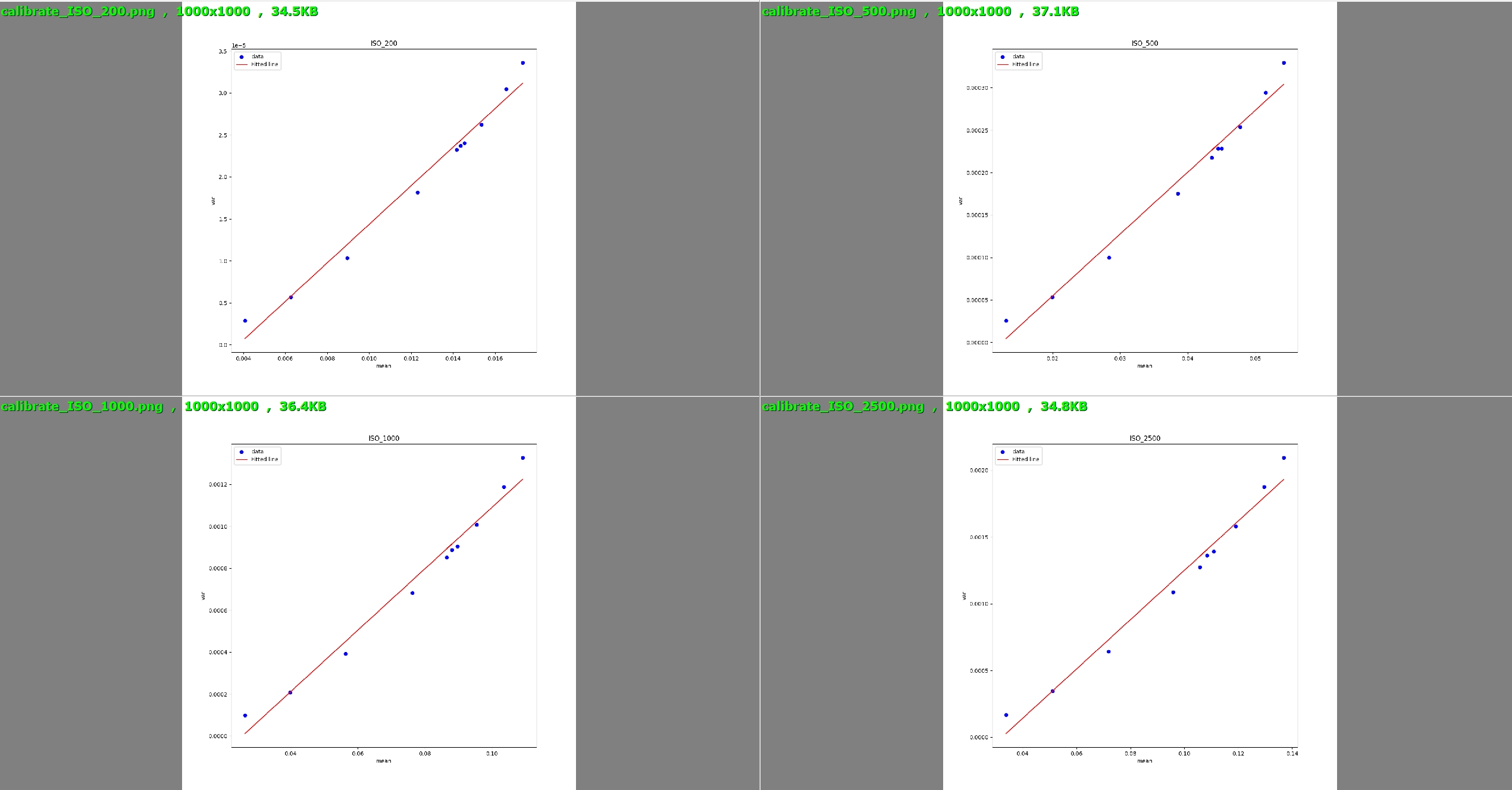
-
拟合ISO和k及ISO和sigma的关系,得到噪声模型的参数配置文件。
-
通过噪声模型参数配置文件,可以得到任意ISO下的噪声模型参数,从而可以合成匹配数据,该部分的code可参考
/utils/noise_profile.py。 -
由于已提前进行上述帧采集操作,通过运行以下code来直接生成配置文件。
python utils/noise_profile.py
运行code后生成如下yaml文件,即为噪声模型的参数配置文件。
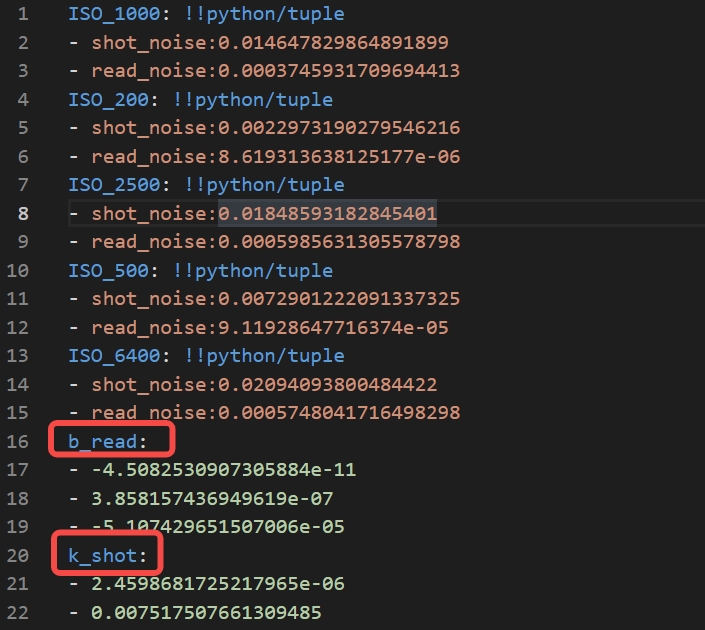
-



成对的匹配数据需要标签图和输入图,首先需要对标签图进行采集。
-
标签图即干净的RAW图,可以通过以下方式获得:
- 用目标camera采集一组低ISO、长曝光的RAW图,如ISO100,曝光时间为1s。
- 用目标camera采集一组静止多帧的RAW图,如ISO100,曝光时间为1/10s,采集帧数为100,通过求平均得到干净的RAW图。
- 用开源数据集中的GT作标签,但需要对一些脏数据做一些传统滤波处理,本文采取该方式进行标签图像采集,完整数据链接请参考
./IMX766/data_here.txt的内容进行下载。
应用噪声模型时需注意ISO是可调的超参,尽可能广泛选取大范围的ISO来模拟高动态的噪声分布,如ISO范围可以选取100~6400。


- 本实验选取ISO1000~6400来对每个patch加噪声得到与目标camera噪声分布匹配的带噪图,如图所示。
- 加噪声需要经过一些归一化、pack等操作,该部分code可参考
./utils/tools.py。
为了加速训练集的数据读取以提高训练效率,本实验采用LMDB格式存储数据,通过运行以下code,可以将数据集转换为LMDB格式。
python utils/make_dataset.py
- 运行code后生成如下LMDB文件,即为训练集的LMDB文件,位于
./train_data/.mdb下,需预留约20GB的存储空间。- 运行code后同时生成训练集和验证集的ID文件,位于
./train_data/valid_data_idx.txt下。- 训练时,通过ID文件读取训练集LMDB和验证集的数据。
本节介绍AI model的选择和设计方式,将model作为噪声分布拟合器来实现噪声的预测和去除。
AI降噪模型来源可以通过历年的NTIRE竞赛或者图像视觉会议(如CVPR、ECCV、AAAI等)获得,这里列举了一些开源的优秀降噪(或可适用于降噪)模型,部分code位于 ./model_zoo/下。
| Model | Paper | Code | Year & lab | Domain |
|---|---|---|---|---|
| DnCNN | paper | code | CVPR2017 | RGB |
| PMRID | paper | code | 旷视 ECCV 2020 | RAW |
| MPRNet | paper | code | UAE CVPR 2021 | RGB |
| Unprocessing | paper | code | Google CVPR 2019 | RAW |
| FFDNet | paper | code | NTIRE2018 | RGB |
| RIDNet | paper | code | NTIRE2019 | RGB |
| CycleISP | paper | code | UAE CVPR 2020 | RAW |
| GRDN | paper | code | CVPRW 2019 | RGB |
如果你想自己设计一个降噪模型,可以参考以下设计思路。
-
- 降噪模型的输入是RAW图,输出是降噪后的RAW图,因此需要注意模型的输入输出通道数为4(不建议针对RGB进行AI NR)。
- 需要注意的是backbone的参数量不能太大,否则会导致模型过于庞大,不利于部署。(计算量和参数都需要取舍)
- Network的选取需要注意尽可能避免一些不常见、效果存疑的算子。(如一些奇怪的act)
- 对于某些算子的参数不宜设置过大或过小。(如Conv的kernel和channel应适中)
- 尽可能添加一些已经被验证有效且易被量化的Block。(如C+B+R和residual等)
- 可以添加一些已经被验证有效的注意力模块。(如SE、CBAM、SK、GC等)
-
- 降噪模型的loss function可以选择MSE或者L1,也可以选择一些其他的loss function(如SSIM、Charboinner)。
- 可以选择一些已经被验证有效的训练策略(如Adam)。
- 数据预处理可以选择一些已经被验证有效的数据增强策略(如随机裁剪、随机旋转、随机翻转等)。
- 训练可以选择一些已经被验证有效的学习率策略(如warmup)。
基于以上经验,可以参考一些Unet类的结构来设计模型,基本组件为ResnetBlock2D和SelfAttnBlock2D,其中SelfAttnBlock2D选择Transformer来实现注意力模块,ResnetBlock2D选择C+R和residual等结构,详细的模型结构如下图所示。其中模型的源码位于./model_zoo/My_network.py下,该模型结构仅供参考。

Tips:针对2D NR可以考虑设置超参模式来控制去噪强度如(FFDNet系列),如将ISO作为先验输入network进行处理以实现非盲去噪(可以参考Stable diffusion的Unet设计ResnetBlock2D)。
-
Model PSNR SSIM Macs MPRNet 43.133 0.979 8300 G UNet 43.577 0.985 439 G PMRID 42.967 0.981 37 G NAFNet - - 2109 G CycleISP 43.512 0.991 2653 G Restormer 45.133 0.989 5400 G
Tips:PSNR和SSIM在ZTE验证集上的表现可以作为参考,其中Macs是FP32@1080P的推理量。
本节实现AI model的训练和验证,测试其在验证集的表现。训练前请先确保你已经生成了训练集和验证集,如果没有,请参考数据准备一节。
模型训练的入口文件为./train_model/run.sh,支持单机多卡训练,其调用的训练脚本为./train_model/train.py,。可以通过如下code开始训练。
bash ./run.sh在你运行./run.sh之前,请先配置training/train_config.yaml文件,配置文件如下所示。
# train config
# -------------------- base_path config --------------------
log_dir: './training/logs'
checkpoint_dir: './training/checkpoints'
tensorboard_dir: './training/tensorboard'
valid_dir: './training/valid_data'
# -------------------- hyperparamters config --------------------
network: 'Unet'
learning_rate: 0.001
weight_decay: 0.00001
save_epoch: 10
criterion: 'l1'
optimizer: 'adam'
lr_scheduler: 'cosine'
train_batch_size: 64
train_epochs: 1000
train_num_workers: 1
valid_batch_size: 1
valid_num_workers: 1
print_step: 100
seed: 2023
# -------------------- bool type setting--------------------
use_quant: false #torch.fx maybe error
use_tensorboard: True
use_summarywriter: True
use_checkpoint: True
use_lr_scheduler: True
use_warm_up: True
use_logger: True
训练时的超参通过配置文件进行设置,其中:
log_dir、checkpoint_dir、tensorboard_dir、valid_dir分别为log、权重、tensorboard和验证集的存储路径,network为模型的名称,learning_rate为学习率,weight_decay为权重衰减,criterion为loss function,optimizer为优化器,lr_scheduler为学习率策略,train_batch_size为训练batch size,train_epochs为训练epoch,train_num_workers为训练数据加载线程数,valid_batch_size为验证batch size,print_step为打印间隔。use_quant、use_tensorboard、use_summarywriter、use_warm_up、use_logger为bool类型的配置,分别表示是否启用fx量化、tensorboard、summarywriter、warmup和logger。
Tips: 你可以根据自己的需求修改配置文件,但是请确保配置文件的格式正确。
对验证集进行测试来评估训练表现,code包含在./train_model/train.py中,会在训练自动启动验证。
- 权重会保存在
./train_model/training/checkpoints文件夹下,其中xx_best.pth为最优权重,xx_last.pth为最后一次训练的权重,默认不保存最后一次训练权重。 - log会保存在
./train_model/training/log文件夹下,打印详细的时间、训练step和loss等,如下图所示。

- tensorboard文件会保存在
./train_model/training/tensorboard文件夹下,存储loss/iteration、PSNR、SSIM等验证时状态,如下图所示。



Tips: tensorboard需要打开浏览器才能查看,你可以通过
tensorboard --logdir=./train_model/training/tensorboard命令来查看tensorboard。
本节介绍AI model推理前的量化和压缩,实现模型压缩并以trt推理引擎进行推理以提高效率。
对训练时FP32的模型进行量化有很多好处,如降低推理功耗、提高计算速度、减少内存和存储占用等。模型量化的对象为weights和act的FP32->INT8(即W8A8)。采用PTQ量化,入口文件为./train_model/run.sh,即已包含./train_model/train.py,通过配置文件的use_quant:True来选择是否fx量化,默认为False。
torch.fx量化后的模型为int8,但仅支持x86上INT8指令集的加速推理,若要实现GPU推理,可以考虑torch->onnx->tensorrt。
可以通过如下code来实现torch->onnx->trt的量化,Unet的onnx可视化如下图。
python ./infer_model/inference.py
同样,在你运行./infer_model/inference.py之前,请先配置./infer_model/infer_config.yaml文件,配置文件如下所示。
# -------------------- base config --------------------
network: 'Unet'
ckpt_path: '/mnt/code/AISP_NR/train_model/training/checkpoints/Unet_best_ckpt.pth'
onnx_path: '/mnt/code/AISP_NR/infer_model/onnx/Unet_simplify.onnx'
tensorrt_path: '/mnt/code/AISP_NR/infer_model/tensorrt/Unet.engine'
input_shape :
- 1
- 4
- 128
- 128
use_qtorch: False
# -------------------- forward engine setting--------------------
forward_engine: 'trt' ## must be in ['trt', 'onnx', 'torch']
其中:
network为模型的名称,ckpt_path为训练好的权重路径,onnx_path为转换后的onnx模型路径,tensorrt_path为转换后的trt模型路径,input_shape为输入的shape,use_qtorch为bool类型的配置,表示是否启用qtorch量化。forward_engine为前向推理引擎,可以选择trt、onnx和torch,分别表示tensorrt、onnx和torch,其中trt和onnx需要先转换成相应的模型,torch表示直接使用torch进行推理。
以下为不同推理框架推理同样的模型的时间对比,其中trt为tensorrt,torch为torch。
| 模型 | trt | torch | 分辨率 |
|---|---|---|---|
| Unet | 718.8 ms | 1907.7 ms | 3472×4624 |
Tips: 推理设备 CPU:Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz,GPU:NVIDIA RTX-3090-24GB。
选择IMX766的一张图像进行测试,测试图例位于./IMX766/test_data文件夹下,输出图像保存在./output文件夹下,可以通过以下code进行推理。
python demo.py输出图例如下所示。


Tips: 降噪后的图像质量有提高的空间,如降低图像的涂抹感,保持局部纹理一致性,恢复部分细节等,该部分trick可以通过对训练集进行增强或更改训练策略来实现,该文档不进一步讨论。
- AI-ISP的用途是逐步取代传统ISP链条上一些难以优化的模块如NR、HDR,以实现人眼观感提升或机器视觉指标的特定优化。
- 当前主流的方案是用AI-ISP和传统算法共同作用于一个模块来保证其稳定性,也有一些paper希望用一个Network来实现整个ISP Pipe的替代,但目前还存在无法合理tuning及不稳定等缺陷。
- AI-ISP model的应用通常是针对特定嵌入式硬件来将PC端侧的推理框架(如torch、tensorflow)转为平台自研的推理框架来实现OP的一一映射,中间可以会存在某些OP的优化和改写以实现良好的部署效果,所以也能接触一些硬件架构学习和部署相关的概念,个人认为有良好的学习前景,共勉!
MIT 感谢你的关注! 如果你有任何问题,请联系我@HuiiJi。