The data i work in this project is NYC taxi data. About dataset, Yellow and green taxi trip records include fields capturing pick-up and drop-off dates/times, pick-up and drop-off locations, trip distances, itemized fares, rate types, payment types, and driver-reported passenger counts. The data used in the attached datasets were collected and provided to the NYC Taxi and Limousine Commission (TLC) by technology providers authorized under the Taxicab & Livery Passenger Enhancement Programs (TPEP/LPEP). You can dowload and use this dataset in here: https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page. The format data i use in this Project is Parquet file but you can work with CSV if you want.
Need Ubuntu 20.04 or higher and install Docker in your computer. For detail, you can follow the guide in here: https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-20-04 and after you install success, just check again to make sure Docker can working well in your local computer by command: docker ps -a.

docker compose -f docker-compose.yml -d- Push data to MinIO
The meaning of this step in here is - you can import the data - parquet file - to the MINIO bucket to manager. you can also put the data to the MINIO by manual like this. Open browser like Firefox or Chrome and access to the https://locahost:9001 (9001 is the port which run the MINIO service you define in docker-compose file)
and then use username: minio_access_key password: minio_secret_key to access MINIO service

Note: Don't forget to install dependencies from requirements.txt first (and we use python 3.9).
After putting your files to MINIO, please execute trino container by the following command:
docker exec -ti datalake-trino bashWhen you are already inside the trino container, typing trino to in an interactive mode
After that, run the following command to register a new schema for our data:
CREATE SCHEMA IF NOT EXISTS lakehouse.taxi
WITH (location = 's3://taxi/');
CREATE TABLE IF NOT EXISTS lakehouse.taxi.taxi (
VendorID VARCHAR(50),
tpep_pickup_datetime VARCHAR (50),
tpep_dropoff_datetime VARCHAR (50),
passenger_count DECIMAL,
trip_distance DECIMAL,
RatecodeID DECIMAL,
store_and_fwd_flag VARCHAR(50),
PULocationID VARCHAR(50),
DOLocationID VARCHAR(50),
payment_type VARCHAR(50),
fare_amount DECIMAL,
extra DECIMAL,
mta_tax DECIMAL,
tip_amount DECIMAL,
tolls_amount DECIMAL,
improvement_surcharge VARCHAR(50),
total_amount DECIMAL,
congestion_surcharge DECIMAL,
Airport_fee DECIMAL
) WITH (
location = 's3://taxi/part0'
);- Install
DBeaveras in the following guide - Connect to our database (type
trino) using the following information (emptypassword):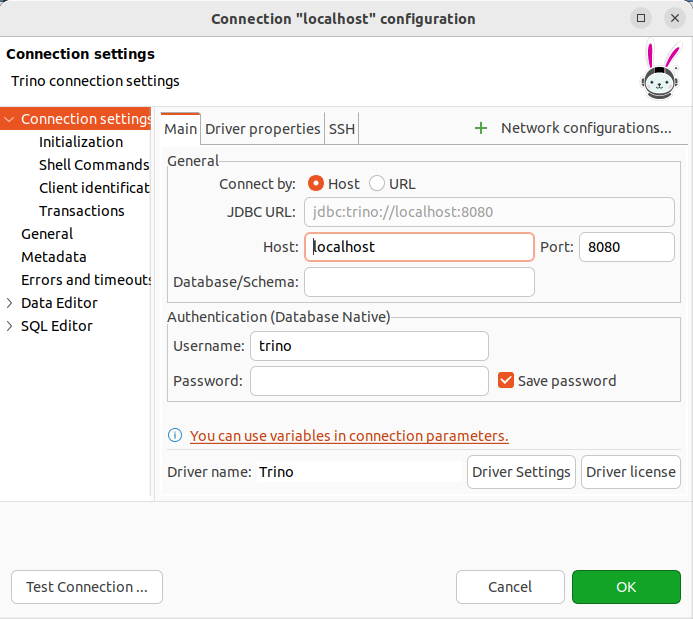

-
Note: one thing your should notice in here is the string querry you use to create data should be match with the data you import in Minio. If you execute the create table fail and not match with the data you import on minio so DBeaver will response the error. And the last, the location you storage data - the parquet file - should be match with the location in the string query create table. if you follow the step carefully, you will see the data in the database and can use trino to query or use it

-
Trick: To debug in this step, you dont need to write the query with multiple column and the large data parquet file, just try with small table with few column and small size parquet file first. And if this step wrong, you can try to check the configure of component - MINIO, Detal lake, Postgress. If you can import data and query the data by DBeaver, so all configure is write and you just only need to check the structure of parquet file and data import
The main idea of this step is you use the streaming tool to create many data you want. There are some tool you can use in local for POC which are RabbitMQ, Kafka... and in this Project i used Kafka Flink and send data to PostgreSQL to use. The main idea to develop in this step is you should define the kafka-producer service and use it to send data continuously to PostgresSQL. In Kafka Producer, you can define the message format, the data you want to binding the message and the topic you want to share the message. You can reference this guide to develop: https://docs.confluent.io/cloud/current/connectors/cc-postgresql-sink.html#step-6-check-the-results-in-postgresql
- First you can start the docker compose file (You can skip this step when you run it success in step 1)
- Then, you can access to https://localhost:9021 (9021 is the port of control center kafka)
- Click on the topic tab - for example you can follow like image below

- If you can see the messege - for example like this - you develop kafka producer corectly

- Next you need to define the config where you want to get data from kafka and send to it, in our project i use postgre and define the config of postgres That is all you need to define and use kafka in this step, one things i want to note in here is i split the data in two part. One i storage the offline data (base data) and one i use to storage the online data ( in real world that maybe created when the end user active with your system and in this project i use kafka to POC it). You can send the data from kafka to the base data directly and use some CDC tool like Debezium to capture the change of data and update it later if you want. Or in this project, i just split it in two part and you can do what ever you want to do the online data first and then copy or send it to base data.
- The last thing i want to note you in here is, you can create multiple kafka-producer service to send many message or try to deploy the Docker Swarm mode (you can follow this guide https://docs.docker.com/engine/swarm/stack-deploy/) to run many node kafka-producer
Apache Airflow™ is an open-source platform for developing, scheduling, and monitoring batch-oriented workflows. Airflow’s extensible Python framework enables you to build workflows connecting with virtually any technology. A web interface helps manage the state of your workflows. Airflow is deployable in many ways, varying from a single process on your laptop to a distributed setup to support even the biggest workflows. Airflow have many Operator and you can choose one of them to do what you want to do. It have PostgresOperator and you can use it to create the job when working with Postgre database. It have DockerOperator and you can create a job build app by Docker. In this project, i use GreatExpectationsOperator to create a job validation data in PostgreSQL.
- First, you need to run all service that is need for Airflow service by using airflow. Open the terminal Change directory to schedule-job folder in repository (cd schedule_job) and run the airflow service by command
docker-compose -f airflow-docker-compose.yaml.- Second, when all service success and healthy, open your browser and access to http://locahost:8080. If lucky you can see the airflow-webserver service like that
 . And you can handler all error when develop by see the log - for example -
. And you can handler all error when develop by see the log - for example - 
- Now the question is, how can we define all the job or task in airflow. I will give you one simple example in here you can see in this image below
 As you can see in this example, i define 3 task and using PostgreOperator to work with Postgre database. i create job create table and then i create the job validate data and finally when data validation task execute success i drop the table i created in first job. One thing you need to note in the validation job is, when you working GreatExpectationsOperator in airflow, you need to define one config json file of great expectation to validate data - for example - like this
As you can see in this example, i define 3 task and using PostgreOperator to work with Postgre database. i create job create table and then i create the job validate data and finally when data validation task execute success i drop the table i created in first job. One thing you need to note in the validation job is, when you working GreatExpectationsOperator in airflow, you need to define one config json file of great expectation to validate data - for example - like this

- That is all the example i want to give for you and you can follow this guide https://docs.astronomer.io/learn/airflow-great-expectations
Back to our project, i just use GreatExpectationsOperator in airflow to validate all data i send from Kafka to Postgre so i just define one job in schedule_job/dags/gx.py
Notice that, when we combine PostgreOperator with Airflow, you might be meet one error about connection with Postgre, so we need to config the Airflow with Postgre by access the Connections in the tab Admins like image below
 and add the config to connect to Postgre like image below
and add the config to connect to Postgre like image below
 in there, Host 172.17.0.1 is the Docker Host IP, Port 5433 is the port of Postgress
in there, Host 172.17.0.1 is the Docker Host IP, Port 5433 is the port of Postgress