The following project provides a neural network architecture for part-of-speech tagging and lemmatizing sentences, achieving state-of-the-art (as of 2018) results for morphologically-rich languages, e.g., Czech, German, and Arabic (Kondratyuk et al., 2018).
There are two main ideas:
- Since part-of-speech tagging and lemmatization are related tasks, sharing the initial layers of the network is mutually beneficial. This results in higher accuracy and requires less training time.
- The lemmatizer can further improve its accuracy by looking at the tagger's predictions, i.e., taking the output of the tagger as an additional lemmatizer input.
The model consists of 3 parts:
- The shared encoder generates character-level and word-level embeddings and processes them through a bidirectional RNN (BRNN).
- The tagger decoder generates part-of-speech tags with a softmax classifier by using the output of the shared encoder.
- The lemmatizer decoder generates lemmas character-by-character with an RNN by using the outputs of the shared encoder and also the output of the tagger.
The image below provides a detailed overview of the architecture and design of the system.
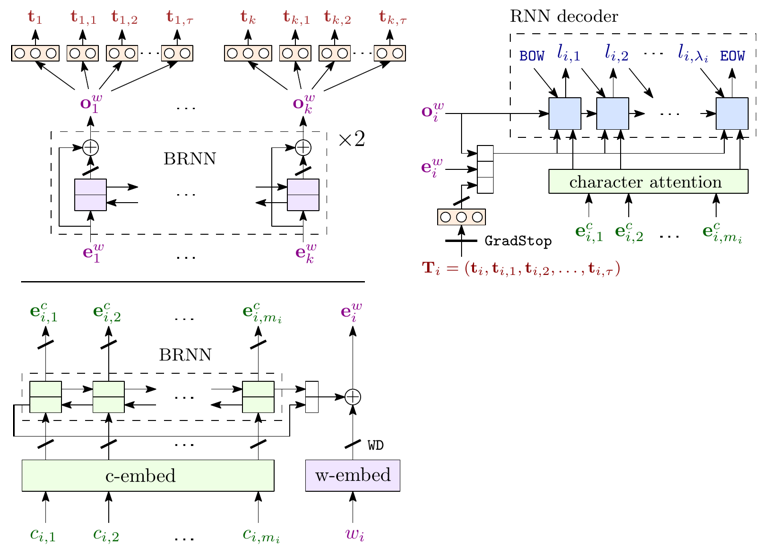
- Bottom - Word-level encoder, with word input
w, character inputsc, character statese^c, and combined word embeddinge^w. Thick slanted lines denote training dropout. - Top Left - Sentence-level encoder and tag classifier, with word-level inputs
e^w. Two BRNN layers with residual connections act on the embedded words of a sentence, producing intermediate sentence contextso^wand tag classificationt. - Top Right - Lemma decoder, consisting of a seq2seq decoder with attention on character encodings
e^c, and with additional inputs of processed tagger featurest, embeddingse^wand sentence-level contextso^w, producing lemma charactersl.
For technical details, see the paper, "LemmaTag: Jointly Tagging and Lemmatizing for Morphologically-Rich Languages with BRNNs".
Not all languages are alike when part-of-speech tagging. For instance, the Czech language has over 1500 different types of tags, while English has about 50. This discrepancy is due to Czech being a morphologically-rich language, which alters the endings of its words to indicate information like case, number, and gender. English, on the other hand, relies heavily on the positioning of a word relative to other words to convey this information.
The image below shows how Czech tags are split up into several subcategories that delineate a word's morphology, along with the number of unique values in each subcategory.

LemmaTag takes advantage of this by also predicting each tag subcategory and feeding this information to the lemmatizer (if the subcategories exist for the language). This modification improves both tagging and lemmatizing accuracies.
The code uses Python 3.5+ running TensorFlow (tested working with TF 1.12).
- Clone the repository.
git clone https://github.com/Hyperparticle/LemmaTag.git
cd ./LemmaTag- Install the python packages in
requirements.txtif you don't have them already.
pip install -r ./requirements.txtTo start training on a sample dataset with default parameters, run
python lemmatag.pyThis will save the model periodically and output the training/validation accuracy. See the Visualize Results section on how to view the training graphs.
For a list of all supported arguments, run
python lemmatag.py --helpA wide range of datasets supporting many languages can be downloaded from Universal Dependencies. Each dataset repo should contain train, dev, and test files in conllu tab-separated format.
The train, dev, and test files must be converted to conllu or LemmaTag format. The LemmaTag format has 3 tab-separated columns: the word form, its lemma, and its part-of-speech tag. Sentences are split by empty lines. See data/sample-cs-cltt-ud-test.txt for an example of a small Czech dataset.
To read the dataset as conllu files, use the --conllu flag and specify the dataset files with --train, --dev, and --test:
python lemmatag.py --conllu --train TRAIN_FILE --dev DEV_FILE --test TEST_FILEwhere INPUT_FILE and OUTPUT_FILE are the names of the input and output dataset files. Alternatively, one can convert the files beforehand:
python util/conllu_to_lemmatag.py < INPUT_FILE > OUTPUT_FILEThe training metrics can be viewed with TensorBoard in the logs directory:
tensorboard --logdir logsThen navigate to localhost:6006.
Please cite this project (PDF) as
Daniel Kondratyuk, Tomáš Gavenčiak, Milan Straka, and Jan Hajič. 2018. "LemmaTag: Jointly Tagging and Lemmatizing for Morphologically Rich Languages with BRNNs". In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
@InProceedings{D18-1532,
author = "Kondratyuk, Daniel
and Gaven{\v{c}}iak, Tom{\'a}{\v{s}}
and Straka, Milan
and Haji{\v{c}}, Jan",
title = "LemmaTag: Jointly Tagging and Lemmatizing for Morphologically Rich Languages with BRNNs",
booktitle = "Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing",
year = "2018",
publisher = "Association for Computational Linguistics",
pages = "4921--4928",
location = "Brussels, Belgium",
url = "http://aclweb.org/anthology/D18-1532"
}