This code pattern demonstrates how images, specifically document images like id cards, application forms, cheque leaf, can be classified using Convolutional Neural Network (CNN). Even though there are code patterns for image classification, none of them showcase how to use CNN to classify images using Keras libraries.
Many organisations process application forms, such as loan applications, from it's customers. Along with the application forms, customers provide supporting documents needed for processing applications. Some of these supporting documents could be identity proof document, address proof document. Generally application forms, along with supporting documents, are scanned and captured into the organisation's systems for further processing of applications. When the system is fed with a set of all these scanned documents, it needs to identify the form document so that it can process it further. This code pattern shows how to classify images and identify application form document among them.
What is CNN and why CNN?
A CNN is a supervised learning technique which needs both input data and target output data to be supplied. These are classified by using their labels in order to provide a learned model for future data analysis.
Typically a CNN has three main constituents - a Convolutional Layer, a Pooling Layer and a Fully connected Dense Network. The Convolutional layer takes the input image and applies m number of nxn filters to receive a feature map. The feature map is next fed into the max pool layer which is essentially used for dimensionality reduction, it picks only the best features from the feature map. Finally, all the features are flattened and sent as input to the fully connected dense neural network which learns the weights using backpropagation and provides the classification output.
The motivation behind the CNN is that it is based on the way the visual cortex functions, where one object in the scene is in focus while the rest is blurred, similarly the CNN takes one section/window of the input image at a time for classification. Each time the CNN will produce a feature map for each section, in the convolutional layer. In the Pooling layer it removes the excess features and takes only the most important features for that section, thereby performing feature extraction. Hence, with the use of CNNs we don't have to perform an additional feature extraction technique.
CNNs require lesser pre-processing as compared to other similar classification algorithms. While traditional MLP(Multi Layer Perceptron) algorithms have significant accuracy for image recognition, they suffer from the curse of dimensionality due to the nodes being fully connected, and hence cannot be scaled to high resolution images. CNNs overcome these challenges posed by MLP by exploiting the spatial correlation of an image. This is done by enforcing a pattern of local connectivity between adjacent neuron layers. Hence, CNNs prove to be superior at Image classification, Video Analysis, Natural Language Processing and wide range of other applications as compared to other techniques.
This code pattern covers the following aspects:
- Dataset preparation for training and testing
- Running notebook for image classification
In this code pattern, we have considered applications for Purchase Agreement and Rental Agreement. Typical documents that are submitted for these applications are PAN (Permanent Account Number) card, Driving License, Cheque leaf, Passport and the application form itself. This code pattern identifies the application form document from all the other types of documents.
We will use Python, Jupyter notebook, CNN in Keras libraries and IBM Cloud Object Storage


- User uploads test images to IBM Cloud Storage.
- User adds Cloud Object Storage credentials, in Jupyter notebook, for the test images uploaded. User runs the notebook.
- Notebook pulls images from Cloud Object Storage and classifies the images using trained machine learning model.
-
IBM Watson Studio: Analyze data using RStudio, Jupyter, and Python in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
-
IBM Cloud Object Storage: An IBM Cloud service that provides an unstructured cloud data store to build and deliver cost effective apps and services with high reliability and fast speed to market.
- Jupyter Notebooks: An open-source web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text.
- Artificial Intelligence: Intelligence demonstrated by machines, in contrast to the natural intelligence displayed by humans.
- Machine Learning: Uses statistical techniques to give computer systems the ability to "learn" with data
- Python: An interpreted high-level programming language for general-purpose programming
Follow these steps to setup and run this code pattern. The steps are described in detail below.
- Sign up for IBM Watson Studio
- Building Machine Learning Model
- Testing image classification machine learning model
- Analyze the Results
If you have not already signed up for Watson Studio then you can sign up here. By signing up for IBM Watson Studio, two services will be created - Spark and ObjectStore in your IBM Cloud account.
Training a machine learning model requires a large number of documents and variety in them. While we have trained and tested the methodology followed in this code pattern, which has given good accuracy (>85%) with a large dataset, we cannot provide those images since they are not publicly available images. For the sake of executing this code pattern and understanding the methodology we have provided our personal documents and masked personal information on those documents. Please note that multiple copies, with resolution and color changes, of same kind of documents are provided. It is recommended that the user create their own set of images and use them in this code pattern so that they can appreciate the real value of this code pattern. To create your own dataset, follow the following naming structure for each type of image -

You can use the dataset provided in this code pattern or create your own dataset. To use the dataset provided in this code pattern, download the Data.zip file from Data folder of this repository
Create a folder named Data. Then create three sub-folders named Train_Data, Test_Data, Val_Data which are used for training, testing and validation respectively. Since we have used Cheque, Form Documents, Driving License, Pancard and Passport create folders to indicate the types of documents Cheque,Documents,Driving_License,Pancard,Passport which will be the classes that machine learning model learns and classifies images.
Compress the Data folder so it can be uploaded to Object Storage.
If you are using a mac machine then compression creates some additional files which should be deleted. On command prompt, go to the compressed file location and run the following commands:
* zip -d Data.zip \__MACOSX/\\*
* zip -d Data.zip \\\*/.DS_Store
Create an Object Storage instance, if you do not have an instance created earlier.
A notebook in Watson Studio is a web-based environment for interactive computing. You can run small pieces of code that process your data, and you can immediately view the results of your computation.
Login to IBM Cloud Dashboard. Click on the Watson Studio instance that was created earlier. Click Get Started button at the bottom of the page.
- If a project is not created earlier then click
New Project. Provide any Name. Object Storage instance should already be selected by default. Verify it is the instance that you want to use. If not select the instance you want from drop down list - Click on
Assetstab. Navigate toNotebookssection below. ClickCreate Notebook - Select the
From URLtab. - Enter a name for the notebook.
- Optionally, enter a description for the notebook.
- Enter this Notebook URL: https://github.com/IBM/image-classification-using-cnn-and-keras/blob/master/notebooks/Image%20Classification%20of%20Documents.ipynb
- Under Runtime select Default Python with 4 CPU and 16GB RAM
- Click the
Createbutton.

- Add
Data.zipfile, created/downloaded in this section, to Object Storage. In Watson Studio, go to your project default page, useFind and Add Data(look for the 10/01 icon) and itsFilestab - Click browse and upload
Data.zipfile

If you use your own dataset, you will need to update the variables/folder names that refer to the data files in the Jupyter Notebook.
To open the notebook, click on the edit icon to start editing the notebook on your project.
In the notebook, update the global variables in the cell following
2.2 Global Variables section.
In the notebook, update the global variables in the cell following 2.2 Global Variables section.
Enter the desired batch_sizes for your training, validation and testing datasets

interested_folder='Documents' is used to specify which class is to be treated as application forms class, so that it points out images that belong to this class.
Add the Object Storage credentials to the notebook
Select the cell below 2.1 Add your service credentials for Object Storage section in the notebook to update the credentials for Object Store.
- Delete the contents of the cell
- Use
Find and Add Data(look for the 10/01 icon) and its Files tab. You should see the file names uploaded earlier. Make sure your active cell is the empty one below 2.2 Add... - Under Files, click the dropdown for
Insert to codeforData.zip - Click
Insert StreamingBody object.
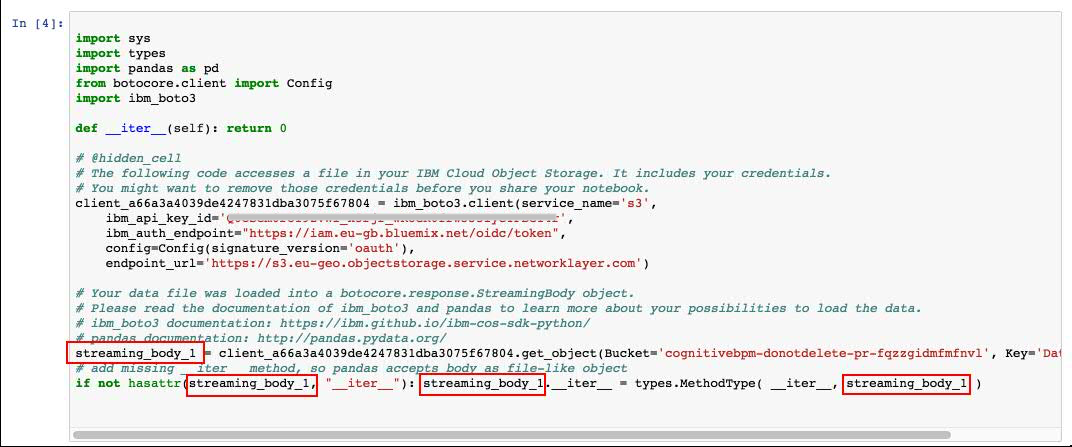
- Make sure the credentials are saved as streaming_body_1. If not edit and replace the numbers to 1. There should be four such occurrences in the cell as shown in the below image


Run the notebook until section 4.3 Train the Model by clicking on the run button in Jupyter notebook menubar
Depending on the dataset, the training of the model takes about one hour. When all the cells, until section 4.3 Train the Model in the notebook have run without any errors, we have our machine learning model trained.
Once the model is trained, it is ready to classify images. Place all images that need to be classified have to be in a folder. Compress the folder. It's named as testdoc-external.zip in this code pattern. You can supply your own set of images for classification or use the one provided in this code pattern. If you are using your own dataset, then update the zip file name occurrence in the notebook.
If you are using a mac machine then compression creates some additional files which should be deleted. On command prompt, go to the compressed file location and run the following commands. Replace file name if you are using a different file name.
* zip -d test_doc-external.zip \__MACOSX/\\*
* zip -d test_doc-external.zip \\\*/.DS_Store
Select the cell in Section 4.4
- Delete the contents of the cell
- Use
Find and Add Data(look for the 10/01 icon) and its Files tab. You should see the file names uploaded earlier. Make sure your active cell is the empty one below 2.2 Add... - Under Files, click the dropdown for
Insert to codefortest_doc-external.zip - Click
Insert StreamingBody object. - Make sure the credentials are saved as streaming_body_2. If not edit and replace the numbers to 2. There should be four such occurrences in the cell as shown in below image


The trained model classifies test images. It will point out to the test image that was of the type Document (application form document)

This notebook was able to identify the form document from a set of application documents.
This pattern aims to automate the identification of images belonging to different types or classes
- We considered a set of images for application form documents. Images belonged to different classes such as passport, driving license, cheque leaf, application form and pancard.
- We created a image classification machine learning model using the dataset created.
- We provided a set of images, belonging to all classes, to be classified.
- For each of the images the notebook ran predictions and probability of each of them belonging to different classes were listed.

- Of all the images provided the notebook pointed out the application form image, of
Documentsclass.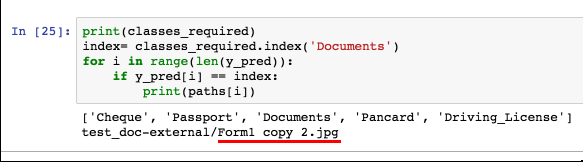


- Artificial Intelligence Code Patterns: Enjoyed this Code Pattern? Check out our other AI Code Patterns.
- AI and Data Code Pattern Playlist: Bookmark our playlist with all of our Code Pattern videos
- With Watson: Want to take your Watson app to the next level? Looking to utilize Watson Brand assets? Join the With Watson program to leverage exclusive brand, marketing, and tech resources to amplify and accelerate your Watson embedded commercial solution.
This code pattern is licensed under the Apache Software License, Version 2. Separate third party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 (DCO) and the Apache Software License, Version 2.