The goal of this code pattern is to demonstrate how data scientists can leverage IBM's Watson Studio Local to automate the:
-
Periodic extraction of features (used to train the machine learning model) from distributed datasets.
-
Batch scoring of the extracted features on the deployed model.
To illustrate this, an example data science workflow which classifies 3 different wine categories from the chemical properties of those wines is used in this code pattern.
-
For feature extraction, Principal component analysis (PCA) is applied on the wine classification dataset and two principal components are extracted.
-
For the classification model, Logistic regression (a popular machine learning model) is applied on the extracted components to predict the wine categories.
What is PCA? Principal component analysis (PCA) is a popular dimensionality reduction technique which is used to reduce N number of numerical variables into few principal components that are used as features in the machine learning model. These principal components capture a major percentage of the combined variance effect of all the variables.
What is IBM Watson Studio Local? Watson Studio Local is an on premises solution for data scientists and data engineers. It offers a suite of data science tools that integrate with RStudio, Spark, Jupyter, and Zeppelin notebook technologies.
What is the IBM Watson Machine Learning? Watson Machine Learning is a Watson Studio Local tool that provides users the ability to create and train machine learning models. Users can also deploy their models to make them available to a wider audience.
This repo contains two Jupyter notebooks illustrating how to extract features and build a model on the wine classification data set. The data contains a list of wines with their associated chemical features and assigned wine classification. There are three scripts in the repo to automate the feature extraction, score the extracted features and combine the two steps as one wrapper respectively.
-
The first notebook uses feature engineering techniques such as PCA and standard scaling to extract the features for the model development from a wine dataset.
-
The second notebook trains, builds and saves a model that can be scored. The model can then be deployed and accessed remotely.
-
The first script is simply a replica of the first notebook as the .py script which can be scheduled to extract the features periodically and save them with version numbers.
-
The second script is used to score the set of extracted features on the deployed model and save the results with versioning.
-
The third script is simply a wrapper script that runs the above two scripts one after the other and used to automate the feature extraction and model scoring in one run.
Using the Watson Machine Learning feature in Watson Studio, all three scripts are deployed as a service to automate feature extraction and scoring in production.
When you have completed this code pattern, you will understand how to:
- Use Watson Studio Local and to extract features using PCA and other techniques.
- Build, Train, and Save a model from the extracted features using Watson Studio Local.
- Use the Watson Machine Learning feature to deploy and access your model in batch and API mode
- Automate the feature extraction and model scoring using the scripts that are deployed as a service in batch and API mode.

- The wine classification data set is loaded into Watson Studio Local as an asset.
- The user interacts with Watson Studio Local to access assets such as Jupyter notebooks, python scripts, and data sets.
- The Jupyter notebooks use Spark DataFrame operations to clean the dataset and use Spark MLlib to train a PCA classification model.
- The model and accompanying scripts are deployed and run from Watson Machine Learning.
- IBM Watson Studio Local: An out-of-the-box on premises solution for data scientists and data engineers. It offers a suite of data science tools that integrate with RStudio, Spark, Jupyter, and Zeppelin notebook technologies.
- Apache Spark: An open-source, fast and general-purpose cluster computing system.
- Jupyter Notebooks: An open-source web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text.
- Artificial Intelligence: Artificial intelligence can be applied to disparate solution spaces to deliver disruptive technologies.
- Python: Python is a programming language that lets you work more quickly and integrate your systems more effectively.
Watson Studio Local provides a suite of data science tools, such as Spark and Jupyter notebooks, that are needed to complete this code pattern. Read the Installation Guide to install and configure your Watson Studio Local instance.
Follow these steps to setup the proper environment to run our notebooks locally.
- Clone the repo
- Create project in IBM Watson Studio Local
- Create project assets
- Run the notebooks to create our model
- Commit changes to Watson Studio Local Master Repository
- Create release project in IBM Watson Machine Learning
- Deploy our model as a web service
- Deploy our scripts as a job
- Bring deployments on-line
- Gather API endpoints data for use in scripts
- Modify scripts in Watson Studio Local
- Run scripts locally to test
- Manage your model with IBM Watson Machine Learning
git clone https://github.com/IBM/model-mgmt-on-watson-studio-local.git
In Watson Studio Local, we use projects as a container for all of our related assets. To create a project:
- From the Watson Studio Local home page, select the
Add Projectbutton.

- Enter your project name and press the
Createbutton.

Once created, you can view all of the project assets by selecting the Assets tab from the project's home page.

For our project, we need to add our notebooks and scripts. To add our notebooks:
-
Select
Notebooksin the projectAssetslist, then press theAdd Notebookbutton. -
Enter a unique notebook name and use the
From URLoption to load the notebook from the github repo. -
Select
Environmentthat runs underPython v3.1or greater.
NOTE: To make it easier to follow along with the remaining instructions, it is recommended that you set
Nameto match the name of the notebook in the uploaded file.

- Enter this URL:
https://raw.githubusercontent.com/IBM/model-mgmt-on-watson-studio-local/master/notebooks/pca-features.ipynb
- Repeat this step to add the second notebook, using the following URL:
https://raw.githubusercontent.com/IBM/model-mgmt-on-watson-studio-local/master/notebooks/pca-modeling.ipynb
To add our scripts:
- Select
Scriptsin the projectAssetslist, then press theAdd Scriptbutton.

- Click on the
From Filetab and then use theDrag and Dropoption to load the script file from your local repo. The script name will be pre-populated with the name of the uploaded file. Select Python version 3.

- Add the following scripts:
scripts/feature_engineering.py
scripts/extract_and_score.py
scripts/model_scoring.py
To add our data set:
- Select
Data setsin the projectAssetslist, then press theAdd Data Setbutton.

From the Local File tab, click the Select from your local file system button to select the file /data/Wine.csv from your local repo.
To view our notebooks, select Notebooks in the project Assets list.

First, some background on how executing a notebooks:
When a notebook is executed, what is actually happening is that each code cell in the notebook is executed, in order, from top to bottom.
Each code cell is selectable and is preceded by a tag in the left margin. The tag format is
In [x]:. Depending on the state of the notebook, thexcan be:
- A blank, this indicates that the cell has never been executed.
- A number, this number represents the relative order this code step was executed.
- A
*, which indicates that the cell is currently executing.There are several ways to execute the code cells in your notebook:
- One cell at a time.
- Select the cell, and then press the
Playbutton in the toolbar.- Batch mode, in sequential order.
- From the
Cellmenu bar, there are several options available. For example, you canRun Allcells in your notebook, or you canRun All Below, that will start executing from the first cell under the currently selected cell, and then continue executing all cells that follow.- At a scheduled time.
- Press the
Schedulebutton located in the top right section of your notebook panel. Here you can schedule your notebook to be executed once at some future time, or repeatedly at your specified interval.
To run a notebook, simply click on the notebook name from the Notebooks list.
-
Run the
pca-featuresnotebook first. It reads in and transforms the wine data set. It also creates data files that will be required by the next notebook. Thesecsvdata files can be viewed by selectingData setsfrom the projectAssetslist. -
Run the
pca-modelingnotebook, which generates and saves our data model.
Once the model is created, you can view it by selecting Models in the project Asset list. Note that it is given a default version number.

Note: After executing the notebooks, you may be wondering why we just didn't combine all of the code into just a single notebook. The reason is simply to seperate out the the data processing steps from the model creation steps. This allows us to process any new data in the future without effecting our current model. In fact, this is exactly what should be done with any new data - score it against the current model first to determine if the results are still acceptable. If not, we can then run the second notebook to generate a new model.
As you will see later, running the first notebook will be done by running a script in our project (
scripts/feature_engineering.py). This script was initially created by loading thepca-featuresnotebook into Jupyter, then exporting the notebook cells into apythonscript (use the menu optionsFile->Download as->Python (.py)). We only had to modify the script slightly to include some code to handling data versioning.
After making changes to your project, you will be occasionally reminded to commit and push your changes to the Watson Studio Local Master Repoisory.

Now that we have added our notebooks and scripts, and generated our model, let's go ahead and do that. Commit and push all of our new assets, and set the version tag to v1.0.

IBM Watson Machine Learning provides the mechanism to deploy our model as a web service. It manages Project Releases, which we will now create.
- Launch the IBM Watson Machine Learning tool by selecting it from the main drop-down menu on the Watson Studio Local home page.

- From the
Project releasespage, press theAdd Project Releasebutton.

- Select our previously committed project from the
Source projectdrop-down list, and select the version tag you assigned to the project. Give the release aNameand aRoute(which can be any random string), and the pressCreate.

- If you click on the
Assetstab, you will see all of the assets associated with the project.

- Select the model from the list of
Assetsassociated with our project. From the model details panel, press theweb servicebutton.

- On the model deployment screen, provide a unique name, reserve some CPUs and memory, then press
Create.

- From the details panel for the
extract_and_score.pyscript, press thejobbutton.

- On the script deploy screen, provide a job name, set the type to
Script run, addv1as a command line argument, then pressCreate.

Repeat these steps for the remaining 2 scripts.
If you select the Deployments tab from the project page, you will notice that all of the deployments are listed as disabled.

To bring the deployments on-line, press the Launch button icon, which is the left-most icon listed at the top of the page. Once you complete the action, you should see the following.

Note: you may have to manually
Enablethe model deployment by using the menu options listed on the right side of the model row in the deployments table.
Some of our scripts will need access to our deployed model and, in some cases, to the other deployed scripts.
Here is a quick overview of what our scripts do and require:
-
feature_engineering.py - this script performs the same function as our
pca-featuresnotebook. It reads in data from the wine dataset, then applies machine learning techniques to transform the data. The output will be two data files -featuresandtarget. Note that theese data files will have a version tag appended to them so that their contents are not over-written every time that this script is run. This script does not require access to our model or other scripts. -
model_scoring.py - this script is a batch processor. It reads the
featuresdata file and scores each feature, one at a time, by running them through our model. The output will be ascoring_outputdata file. Note that the data file will have a version tag appended to it so that its contents are not over-written every time that this script is run. This script requires access to our deployed model. -
extract_and_score.py - this script was created for convenience, and can be used instead of running the previous scripts separately. It invokes the
feature_engineeringscript first, then when complete, it invokes themodel_scoringscript. This script requires access to the other deployed scripts.
To access the deployed model or scripts, we need to gather the associated API endpoints and an authorization token. All of these values are available from the deployment pages for each of the objects. The endpoints will take on the following format:
- model endpoints will end in
/score. - script endpoints will end in either
/trigger,/status, or/cancel(which corresponds to the actions:start,status, andstop).
To get the endpoint for our deployed model, click on the model from the Assets tab of the project page.

The endpoint is listed at the top of the page. Both the Endpoint and the Deployment Token can be saved to the clipboard by clicking on their respective  icons.
icons.
Repeat this step to retrieve the endpoints for both the feature_engineering and model_scoring scripts.
Note: You will only need to get one copy of the
Deployment Token. It will be the same for all deployments within this project.
Once we have gathered our deployment endpoints and deployment token, we need to go back to Watson Studio Local mode so that we can modify and test our scripts.

Go to the Assets list for the project, and select Scripts. Click on a script file to open it up in edit mode.
The scripts we will be modifying are those that reference deployment objects. These are:
scripts/model_scoring.py
scripts/extract_and_score.py
- For the
model_scoringscript, substitute in the token and endpoint values, then save the new version of the script.

-
For the
extract_and_scorescript, substitute in the token and endpoint values. The endpoint values are for thefeature_engineeringandmodel_scoringdeployment scripts.Important: The endpoints will end with the string
/trigger. Delete that portion of the URL as the script will append either/triggeror/statusto the endpoints, as needed. -
Finish by saving the new version of the script by clicking on the
Saveicon located at the top right side of the page.

To avoid having to go back and forth between Watson Studio Local and Watson Machine Learning (which includes re-deploying and creating new release versions), make sure the scripts run locally in Watson Studio Local first.
Scripts can be run from either the detail panel for the script, or from the script editor.
-
Run as a job from the script detail panel:
- From the project page, click on
Scriptsin theAssetslist.
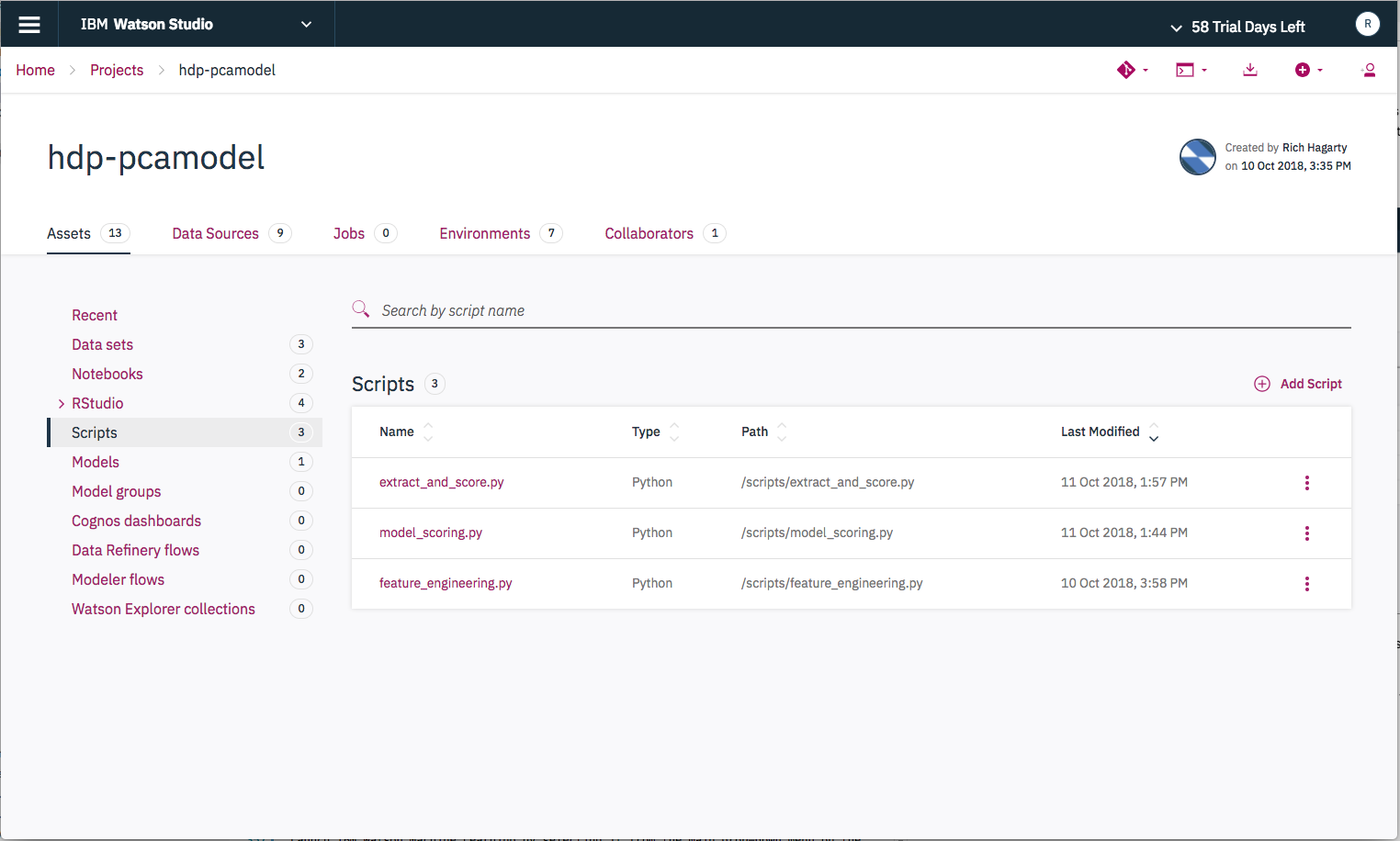
Start with the script
feature_engineering. Use the menu bar on the right side of the script row toCreate Joband run the script.In the
Create Jobrun panel, provide a unique name and make sure you use the following options:- Type:
Script Run - Worker:
Python 3 - Source asset:
/scripts/feature_engineering.py - Command line arguments:
v1 - Scheduled to run:
On demand
After you press the
Createbutton, you will see the run panel.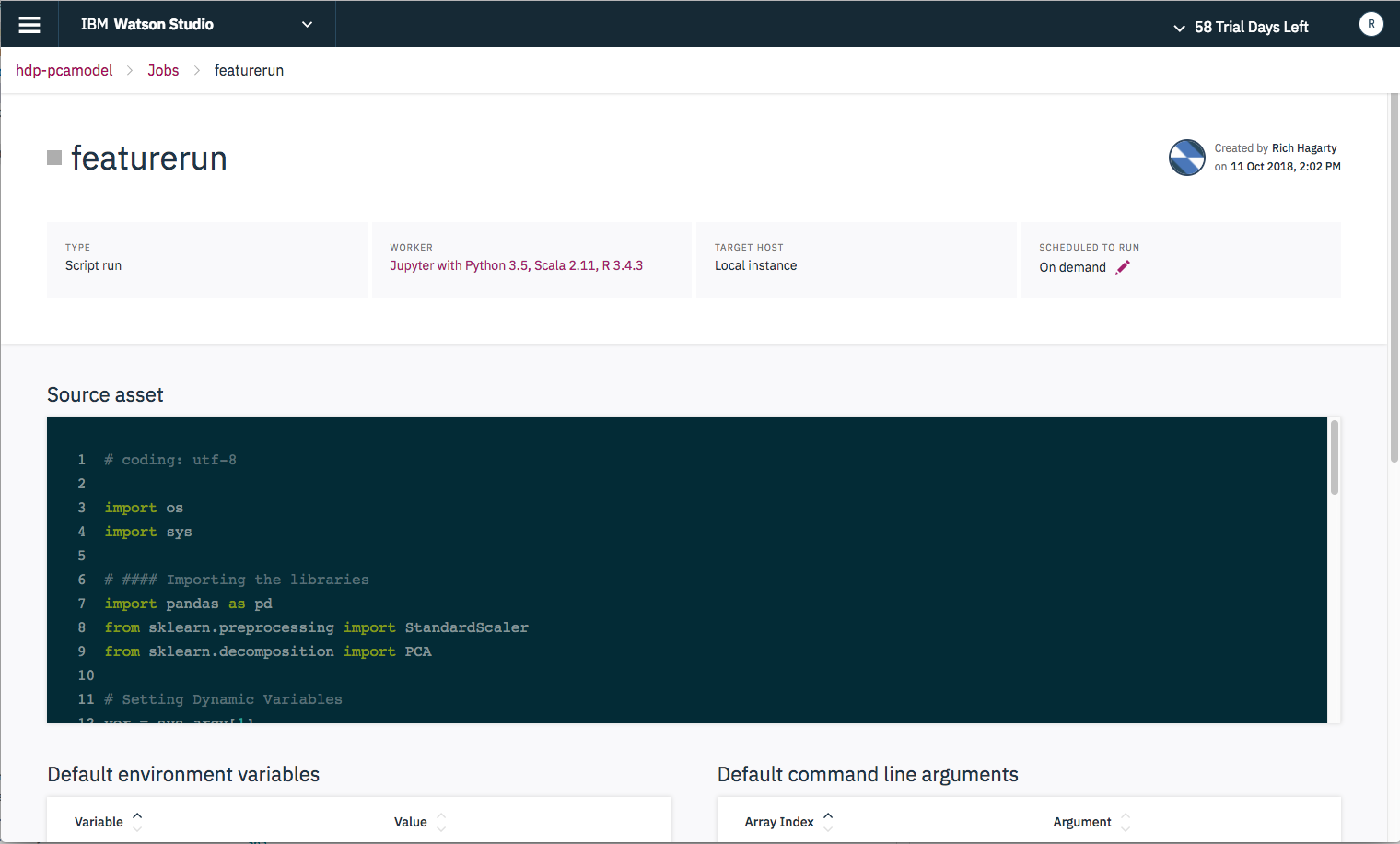
If you scroll down a bit, you will see a
Run Nowbutton. Click it to start the script. Again, you will be presented with a dialog that requires you give it a run name. The rest of the values will be defaulted to values you already set, so they do not need to be modified. Click theRunbutton to run the script.You will be transferred back to the run panel where you can see the status (listed under
Duration) and a tail of the log file. Once completed successfully, you should see 2 new files listed underData setsin theAssetslist.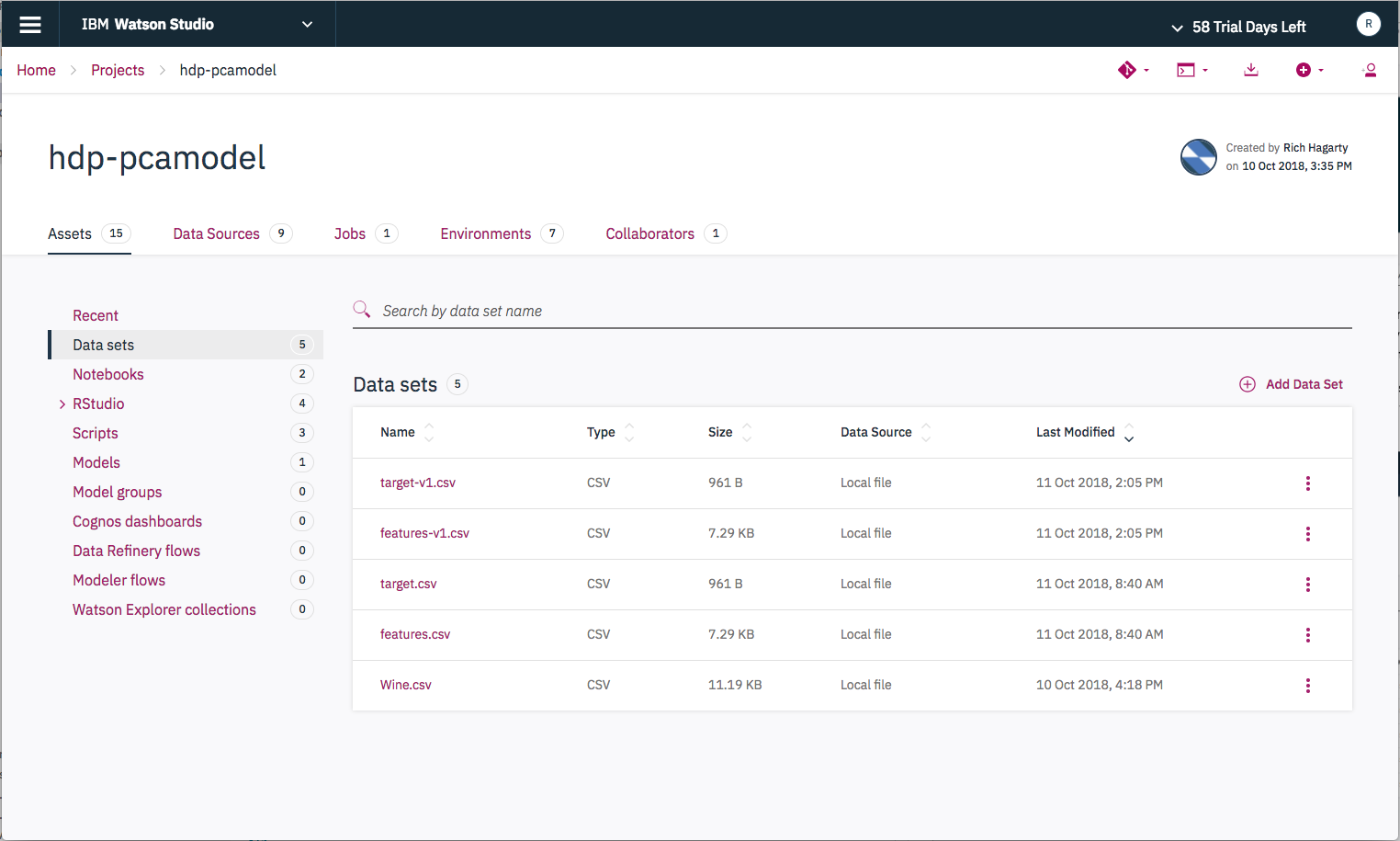
NOTE: The created data files (
targetandfeatures) will have a version tag appended to their name. This matches the command line argument we passed into the script. - From the project page, click on
-
Run interactively from the script editor
- from the project page, click on
Scriptsin theAssetslist, then click on thefeature_engineeringscript in the list. This will bring up the script editor.
Click the
Run configurationbutton in the tool bar and then addv1as a command line argument.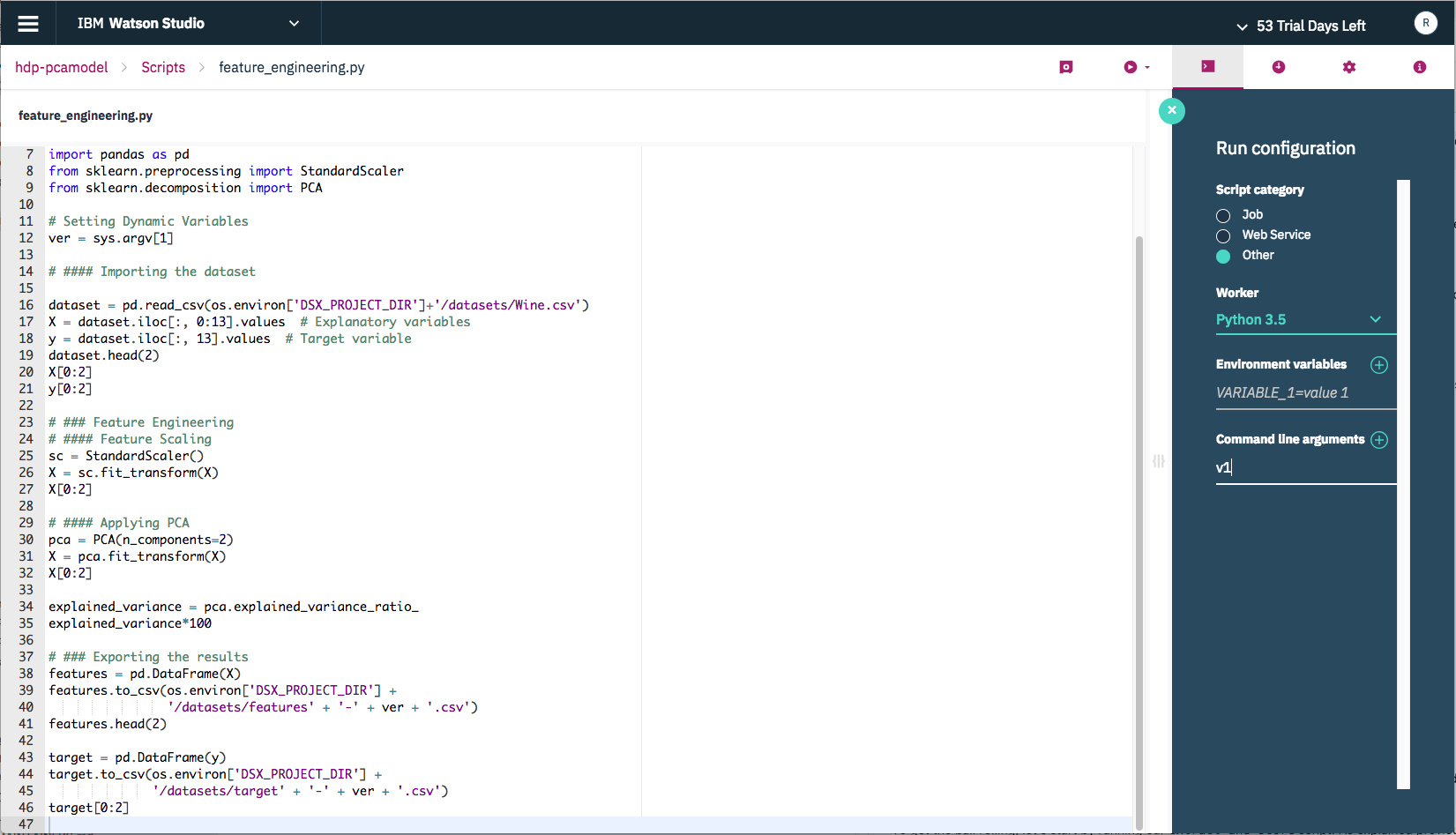
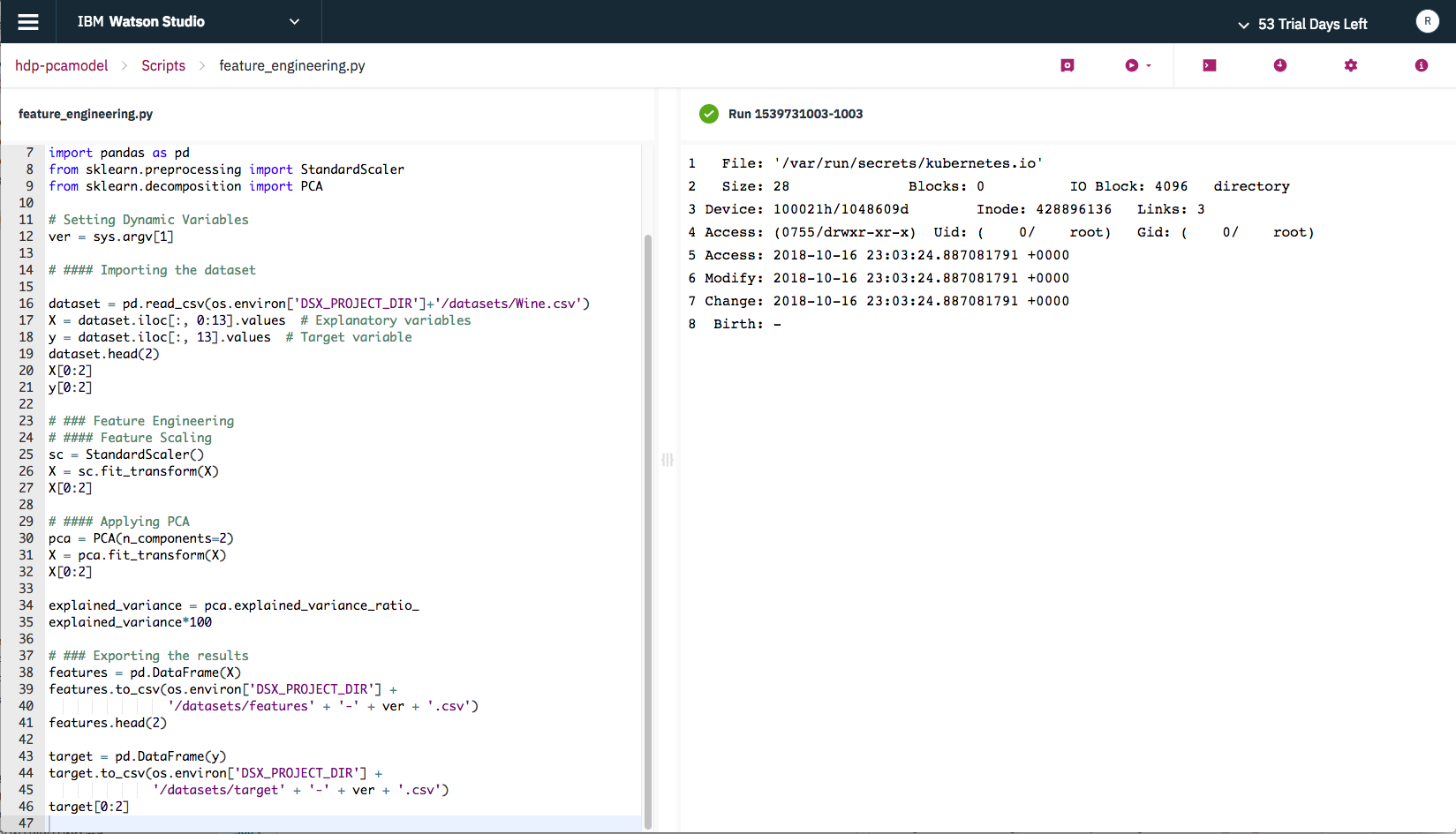
Drag the sizing icon located on the right side of the panel to open up the console log. Then start the script by clicking on the
Run->Run as jobbutton in the tool bar.The script will begin executing and displaying output to the console log.
- from the project page, click on






Using either method, repeat this process to run the model_scoring script, and then the extract_and_score script.
NOTE: The
extract_and_scorescript will fail when it attempts to check the status of themodel_scoringscript. Remember, it invokes the other scripts by calling their endpoints which are deployed in Watson Machine Learning. The problem is that those deployed scripts do not have the updated endpoint information yet, and won't until we push our changes back up to the Watson Machine Learning release model (which we will do next).
Once you have verified the scripts, commit and push the changes to the Watson Studio Master Repository, as described above in Step #5. Make sure you bump the version number.
Launch IBM Watson Machine Learning by selecting it from the main drop-down menu on the Watson Studio Local home page.
First we need to update our release project to grab all of the latest versions of our scripts.
-
From the Watson Machine Learning home page, click on our project tile.
-
From the row of icons listed in the page banner, click on the
Updateicon. -
From the update screen, use the
Source projectdrop-down menu to select our Watson Studio Local project. Then select the version tag associated with our latest commit.
Now that all of our assets are updated, we can actually manage our model by tracking its use and performance.
To get the ball rolling, let's start by running our extract_and_score script. As explained previously, this will read in the current wine csv file and transform it, then score each wine against our model.
- From the
Assetpage, select theextract_and_scorescript. From the detail page, click on the script name to bring up the script launch page. Then click on theAPItab.

-
Note that the
Command line argumentsvalue is set tov1. You can set this to anything you want, but it will be appended to the file names generated by this script. This is how to avoid overridding the data from previous runs of this script. -
To run the script, click on the
Overviewtab and scroll down to theRunssection of the page. Then click therun nowbutton. -
From the start dialog, enter a name, modify the command line argument if needed, then click the
Runbutton.

You can view the status of the job from the same panel. To see the associated log file, click the View logs menu option located on the right side of the job row.

From the main dashboard, you can also see that the script completed successfully, and also note that in the case of the extract-and-score script, three separate jobs were launched (the main script, and the two invoked scripts).

If the script completes succesfully, there should be a three versioned data files that should be added as Data sets assets in the project. The scoring_output-v1 file contains the final wine classification scores.

Here are links to each of the notebooks with example output:
- Data Analytics Code Patterns: Enjoyed this Code Pattern? Check out our other Data Analytics Code Patterns
- AI and Data Code Pattern Playlist: Bookmark our playlist with all of our Code Pattern videos
- Watson Studio: Master the art of data science with IBM's Watson Studio
- Spark on IBM Cloud: Need a Spark cluster? Create up to 30 Spark executors on IBM Cloud with our Spark service
This code pattern is licensed under the Apache Software License, Version 2. Separate third party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 (DCO) and the Apache Software License, Version 2.