Login/Sign Up for IBM Cloud: https://ibm.biz/YourPathToDeepLearning
Hands-On Guide: https://ibm.biz/rnn-tensorflow-NNLab
Slides: https://ibmdevelopermea.github.io/YPDL-Recurrent-Neural-Networks-using-TensorFlow-Keras/#/
Workshop Replay: https://www.crowdcast.io/e/ypdl-3
Survey - https://ibm.biz/YPDL-Survey
Language Modeling is the task of assigning probabilities to sequences of words. Given a context of one or a sequence of words in the language that the language model was trained on, the model should provide the next most probable words or sequence of words that follows from the given sequence of words in the sentence. Language Modeling is one of the most important tasks in Natural Language Processing.
Recurrent neural networks (RNN) are a class of neural networks that is powerful for modeling sequence data such as time series or natural language. Basically an RNN uses a for loop and performs multiple iterations over the timesteps of a sequence while maintaining an internal state that encodes information about the timesteps it has seen so far. RNNs can easily be constructed using the Keras RNN API available within TensorFlow - an end-to-end open source machine learning platform that makes it easier to build and deploy machine learning models.
IBM's Watson® Studio is a data science platform that provides all the tools necessary to develop a data-centric solution on the cloud. It makes use of Apache Spark clusters to provide the computational power needed to develop complex machine learning models. You can choose to create assets in Python, Scala, and R, and leverage open source frameworks (such as TensorFlow) that are already installed on Watson® Studio.
In this tutorial, you will perform Language Modeling on the Penn Treebank dataset by creating a Recurrent Neural Network (RNN) using the Long Short-Term Memory unit and deploying it on IBM Watson® Studio on IBM Cloud® Pak for Data as a Service.
The goal of this tutorial is to import a Jupyter notebook written in Python into IBM Watson® Studio on IBM Cloud® Pak for Data as a Service and run through it. The notebook creates a Recurrent Neural Network model based on the Long Short-Term Memory unit to train and benchmark on the Penn Treebank dataset. By the end of this notebook, you should be able to understand how TensorFlow builds and executes a RNN model for Language Modeling. You'll learn how to:
- Run a Jupyter Notebook using IBM Watson® Studio on IBM Cloud® Pak for Data as a Service.
- Build a Recurrent Neural Network model using the Long Short-Term Memory unit for Language Modeling.
- Train the model and evaluate the model by performing validation and testing.
The following prerequisites are required to follow the tutorial:

This tutorial will take approximately four hours to complete. The bulk of this time will be spent training/evaluating the LSTM model. You can refer the reducing the notebook execution time section for methods to reduce the time required for execution.
- Set up IBM Cloud Pak for Data as a Service
- Create a new project and import the notebook
- Read through the notebook
- Run the notebook
-
Open a browser, and log in to IBM Cloud with your IBM Cloud credentials.
-
Type
Watson Studioin the search bar at the top. If you already have an instance of Watson Studio, it should be visible. If so, click it. If not, click Watson Studio under Catalog Results to create a new service instance.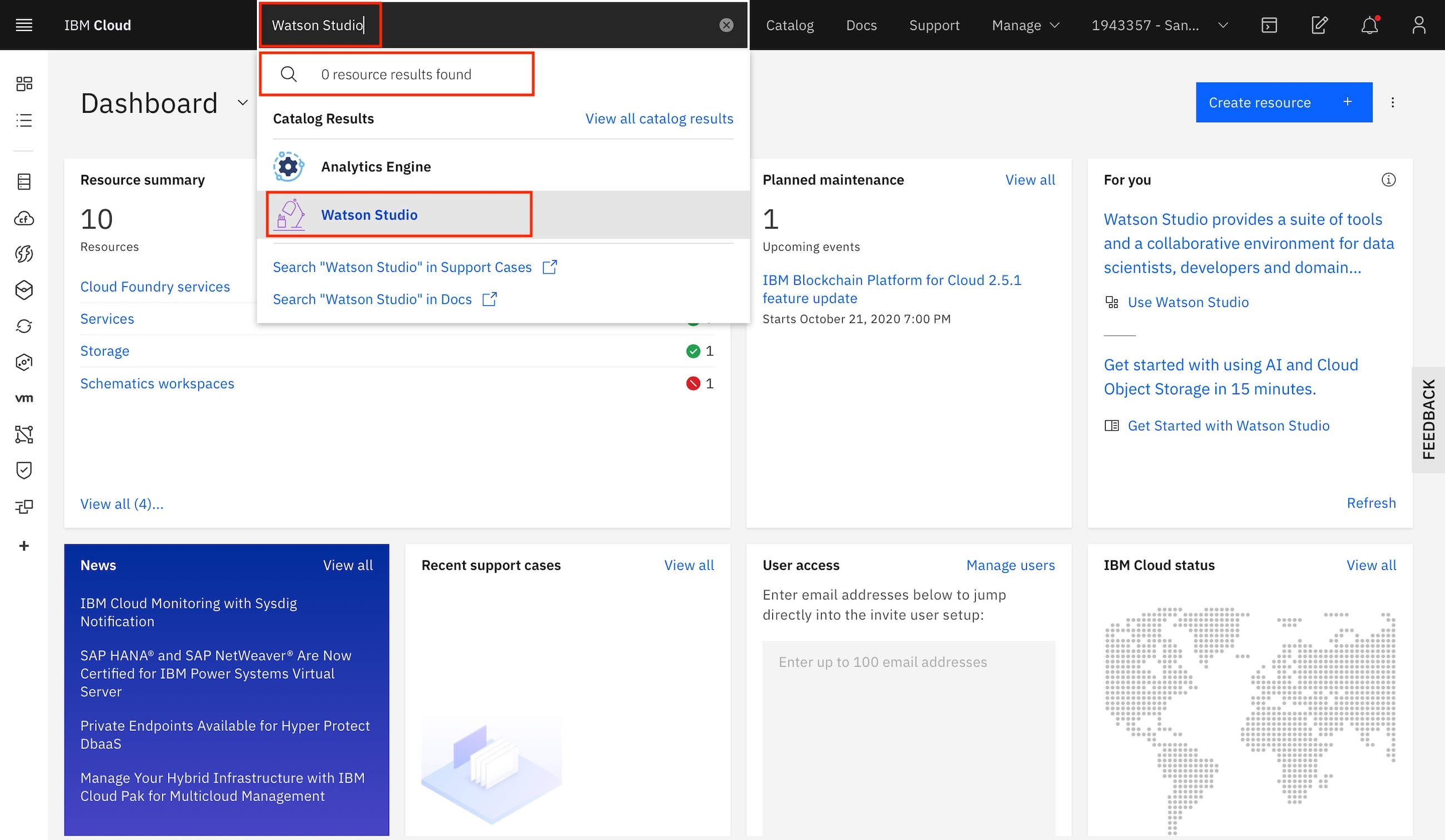
-
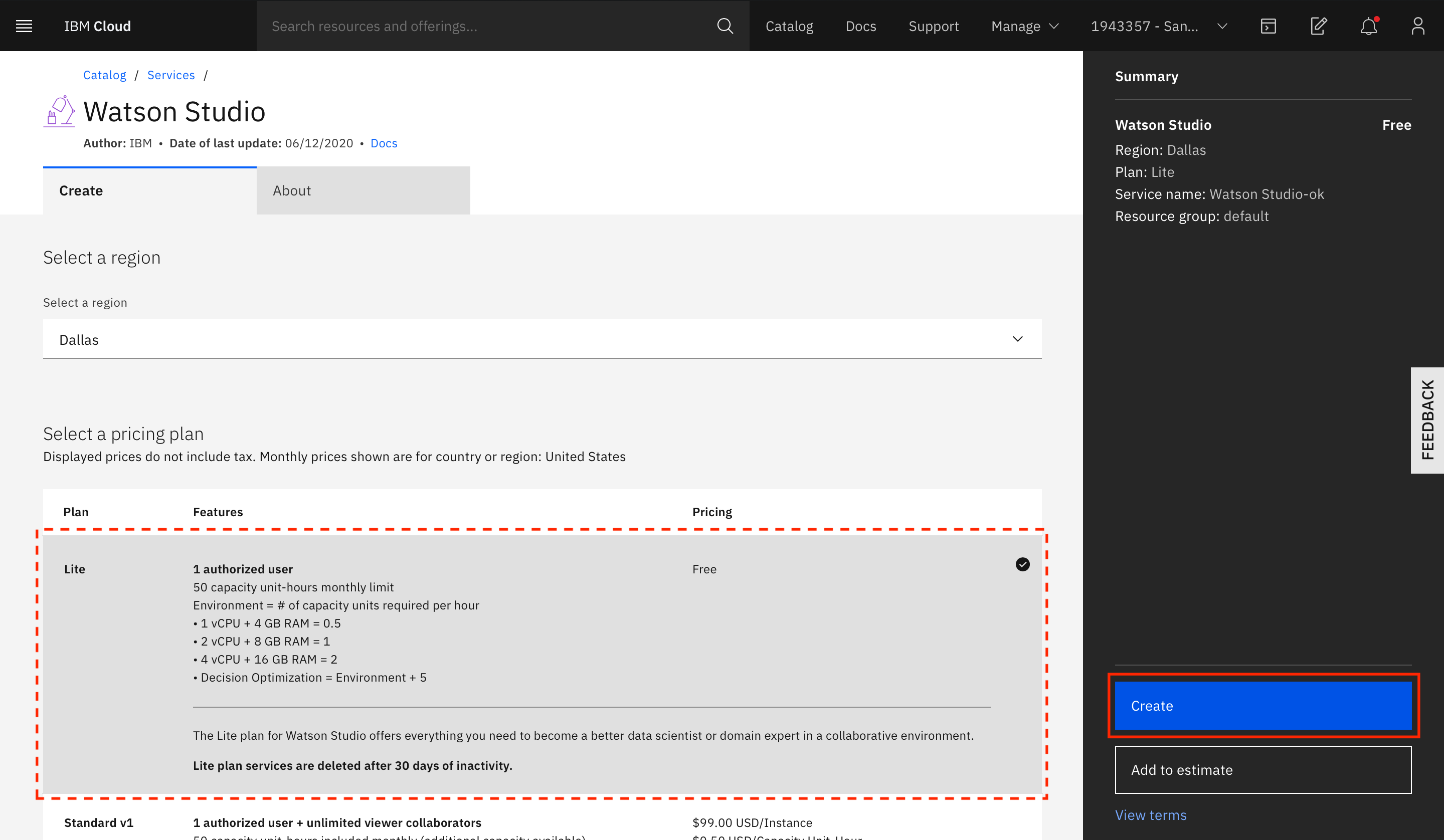
Select the type of plan to create if you are creating a new service instance. A Lite (free) plan should suffice for this tutorial). Click Create.
-
Click Get Started on the landing page for the service instance.
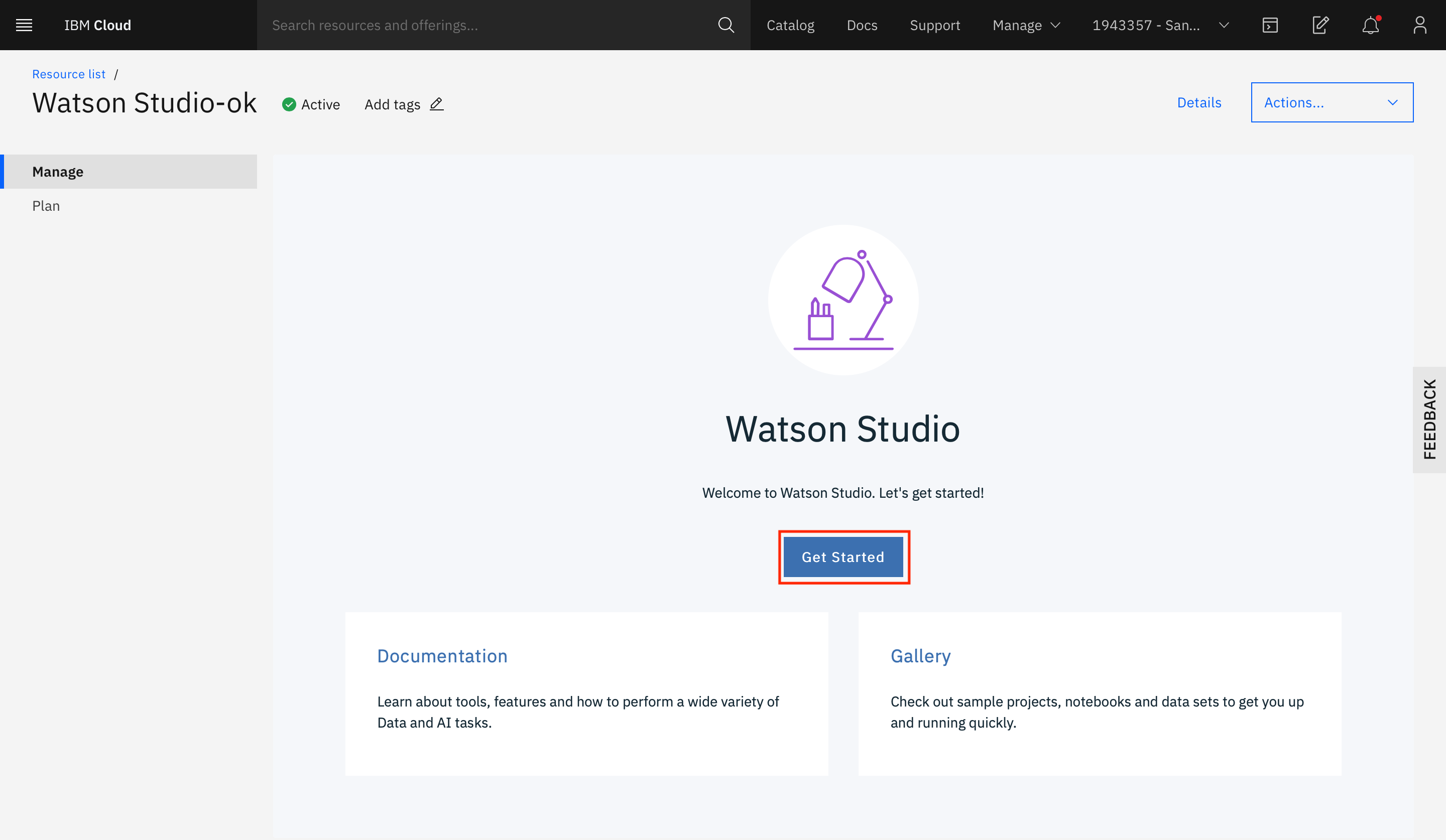
This should take you to the landing page for IBM Cloud Pak for Data as a Service.
-
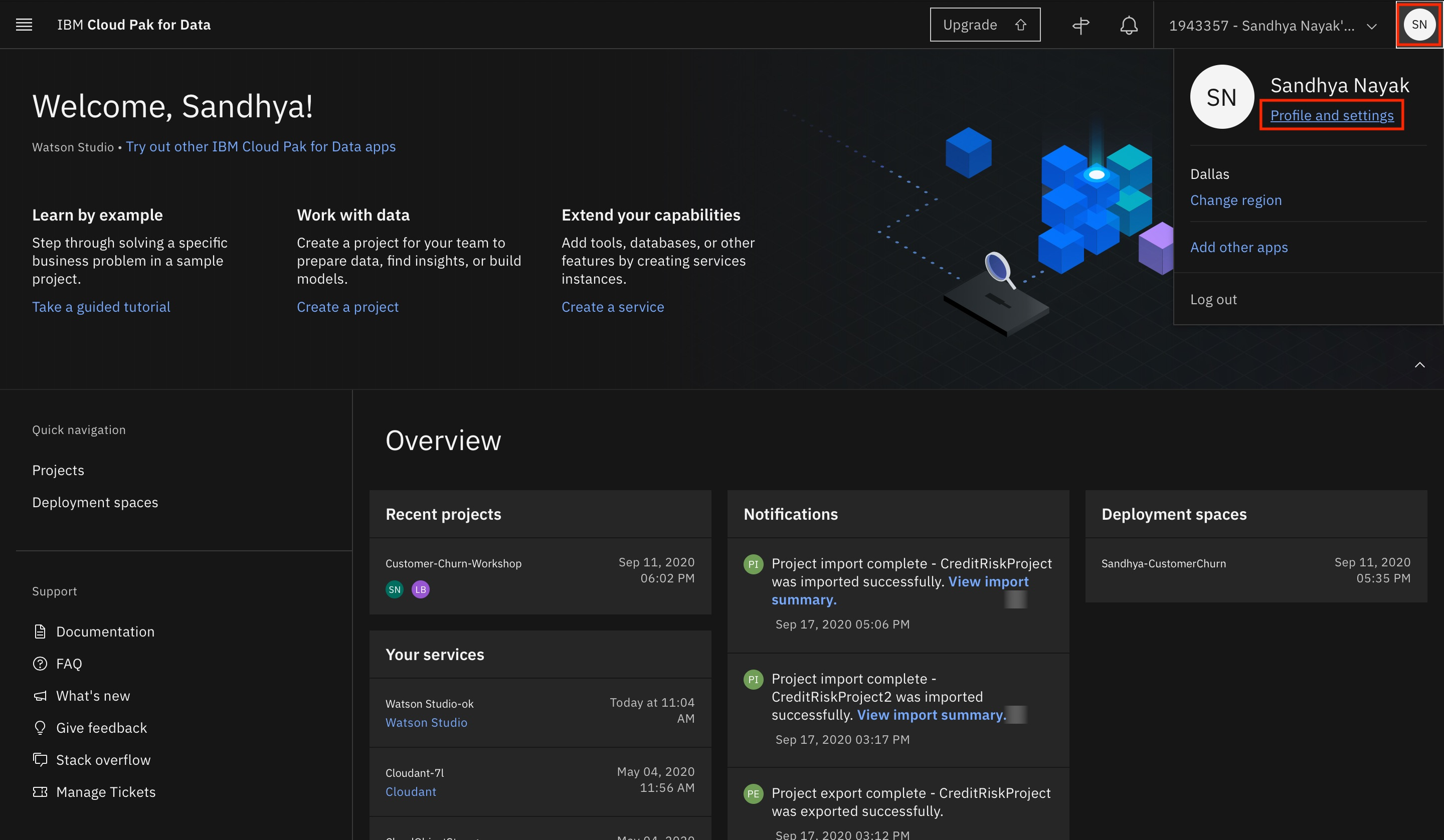
Click your avatar in the upper-right corner, then click Profile and settings under your name.
-
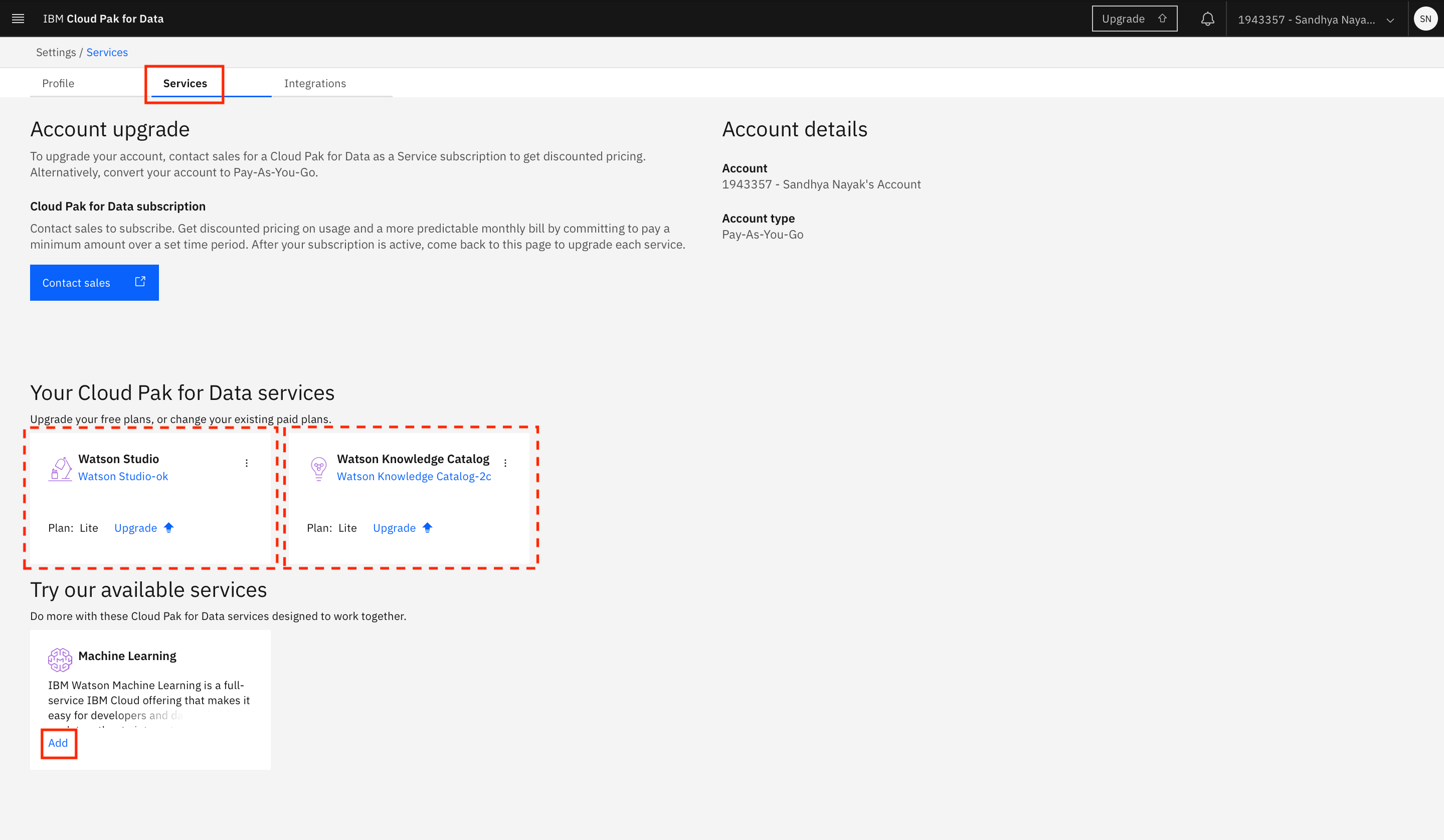
Switch to the Services tab. You should see the Watson Studio service instance listed under Your Cloud Pak for Data services.
You can also associate other services such as Watson Knowledge Catalog and Watson Machine Learning with your IBM Cloud Pak for Data as a Service account. These are listed under Try our available services.
In the example shown here, a Watson Knowledge Catalog service instance already exists in the IBM Cloud account, so it's automatically associated with the IBM Cloud Pak for Data as a Service account. To add any other service (Watson Machine Learning in this example), click Add within the tile for the service under Try our available services.
-
Select the type of plan to create (a Lite plan should suffice), and click Create.
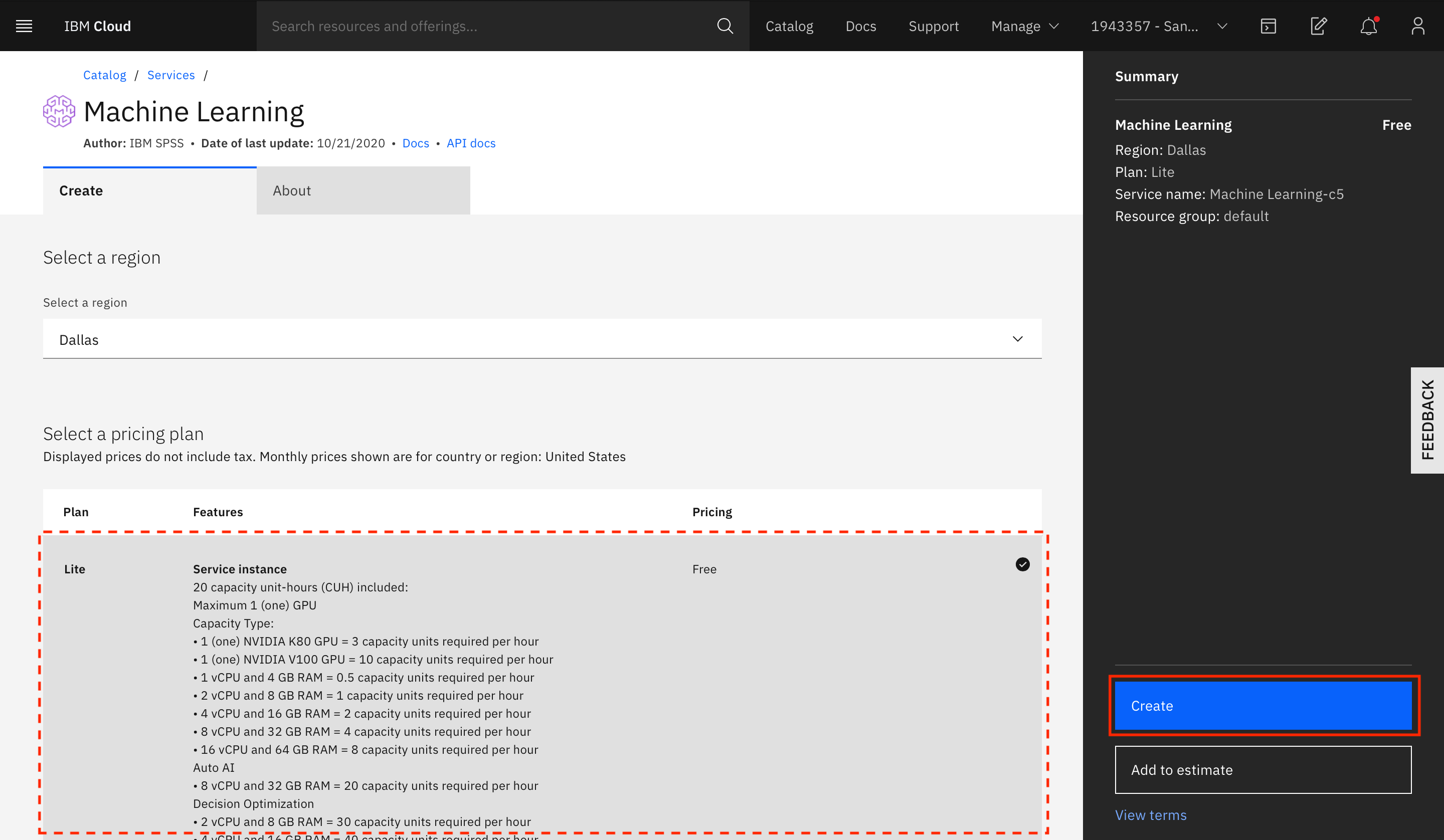







After the service instance is created, you are returned to the IBM Cloud Pak for Data as a Service instance. You should see that the service is now associated with your IBM Cloud Pak for Data as a Service account.

-
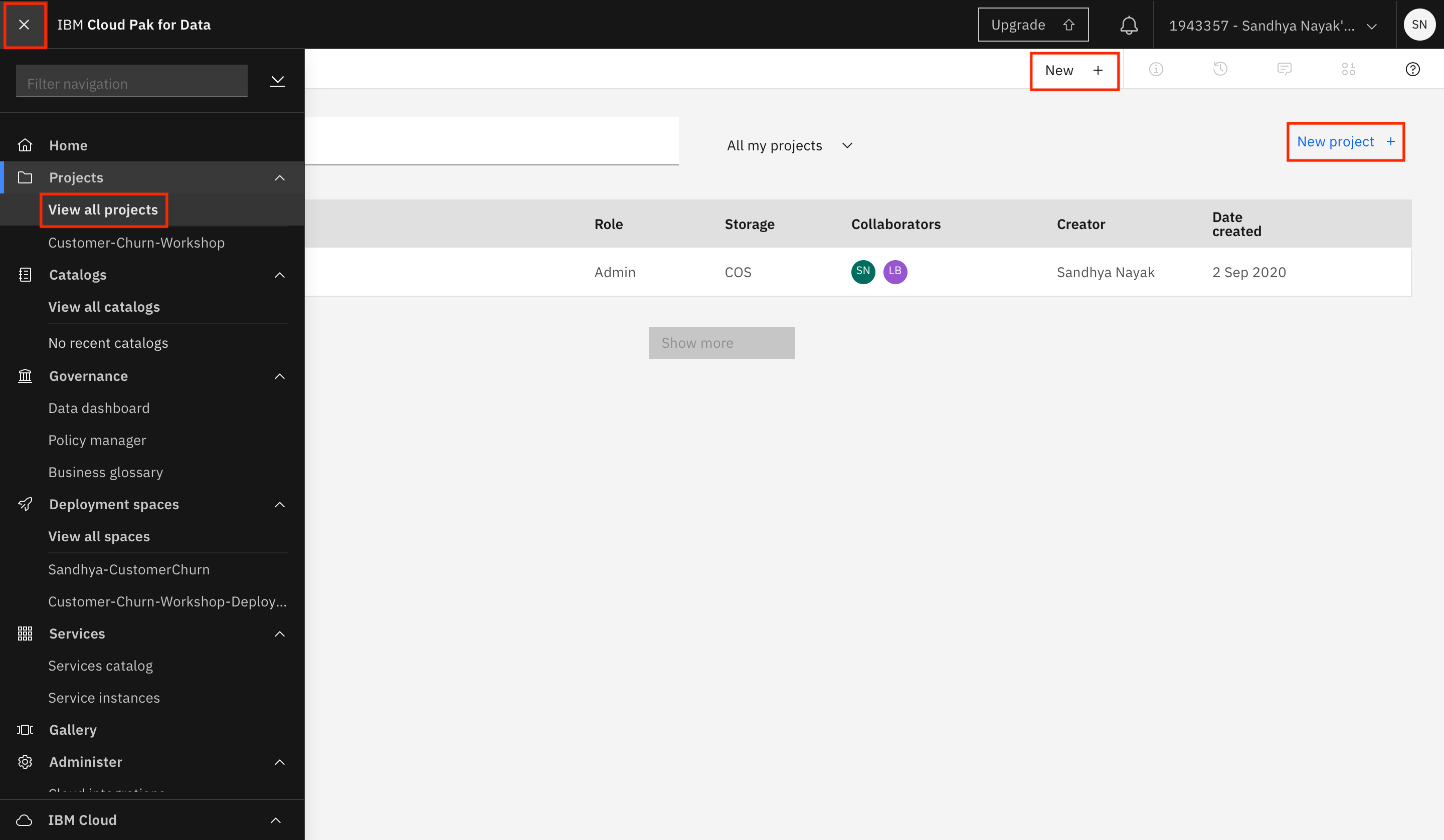
Navigate to the hamburger menu (☰) on the left, and choose View all projects. After the screen loads, click New + or New project + to create a new project.
-
Select Create an empty project.
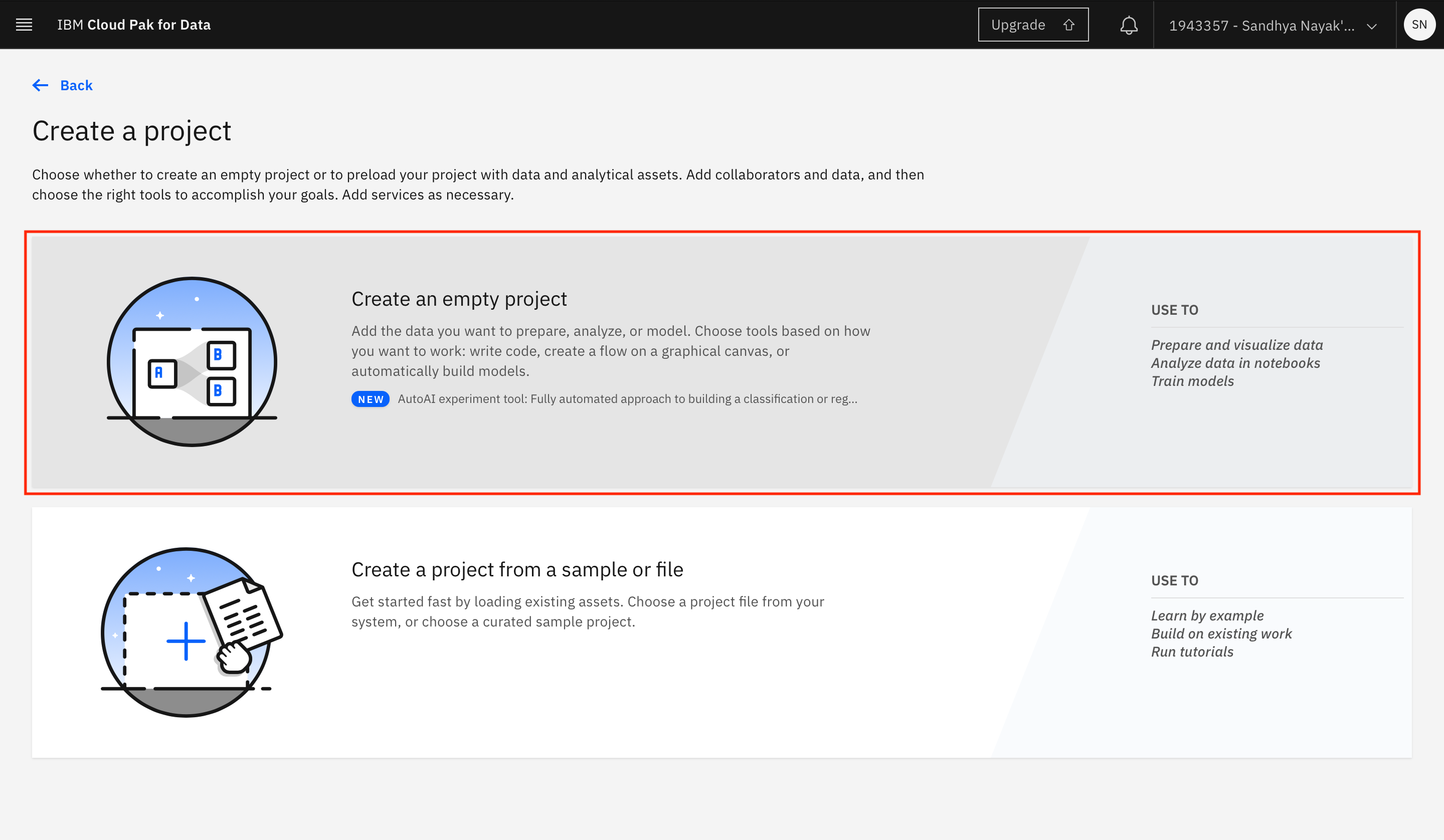
-
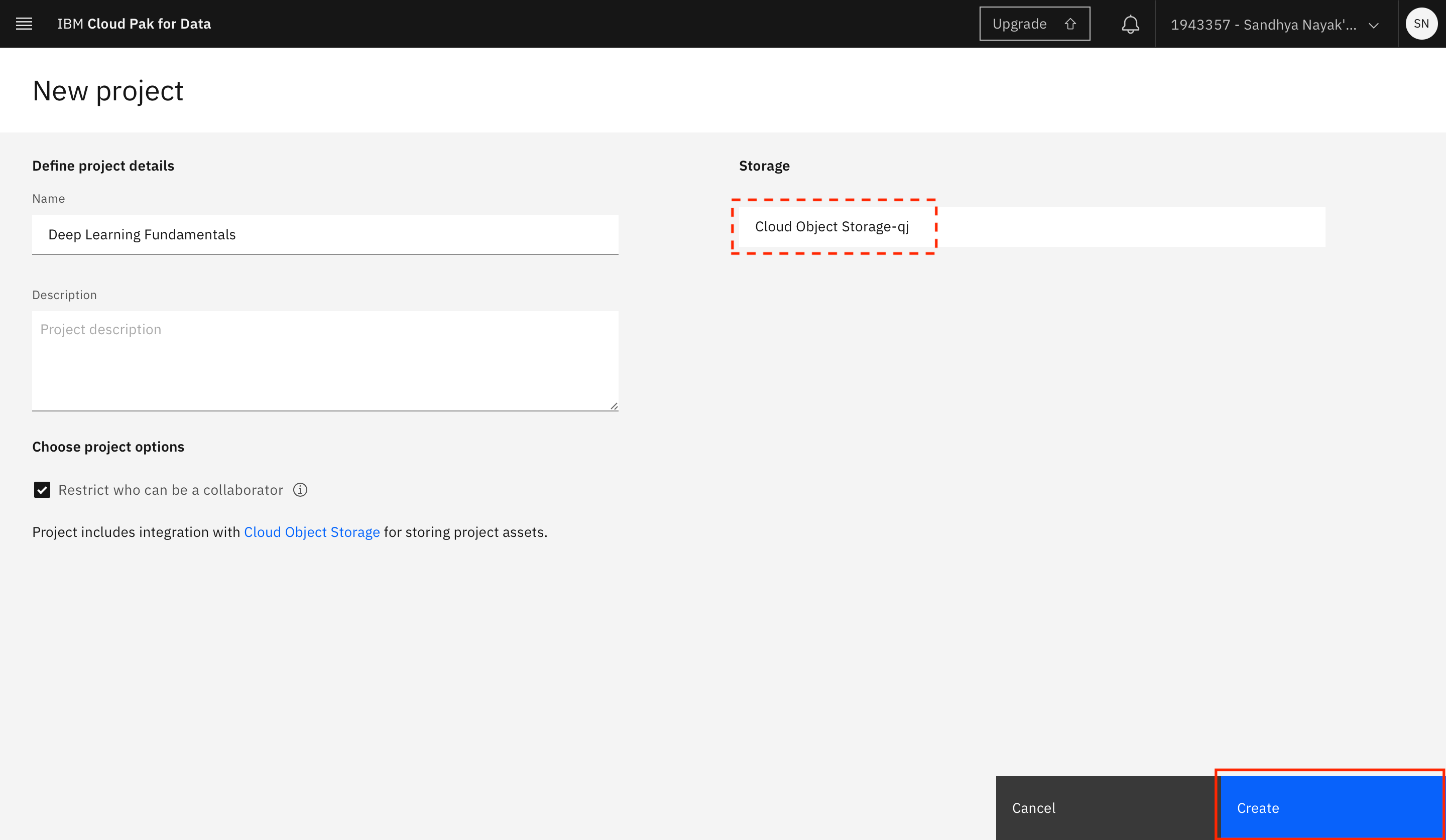
Provide a name for the project. You must associate an IBM Cloud Object Storage instance with your project. If you already have an IBM Cloud Object Storage service instance in your IBM Cloud account, it should automatically be populated here. Otherwise, click Add.
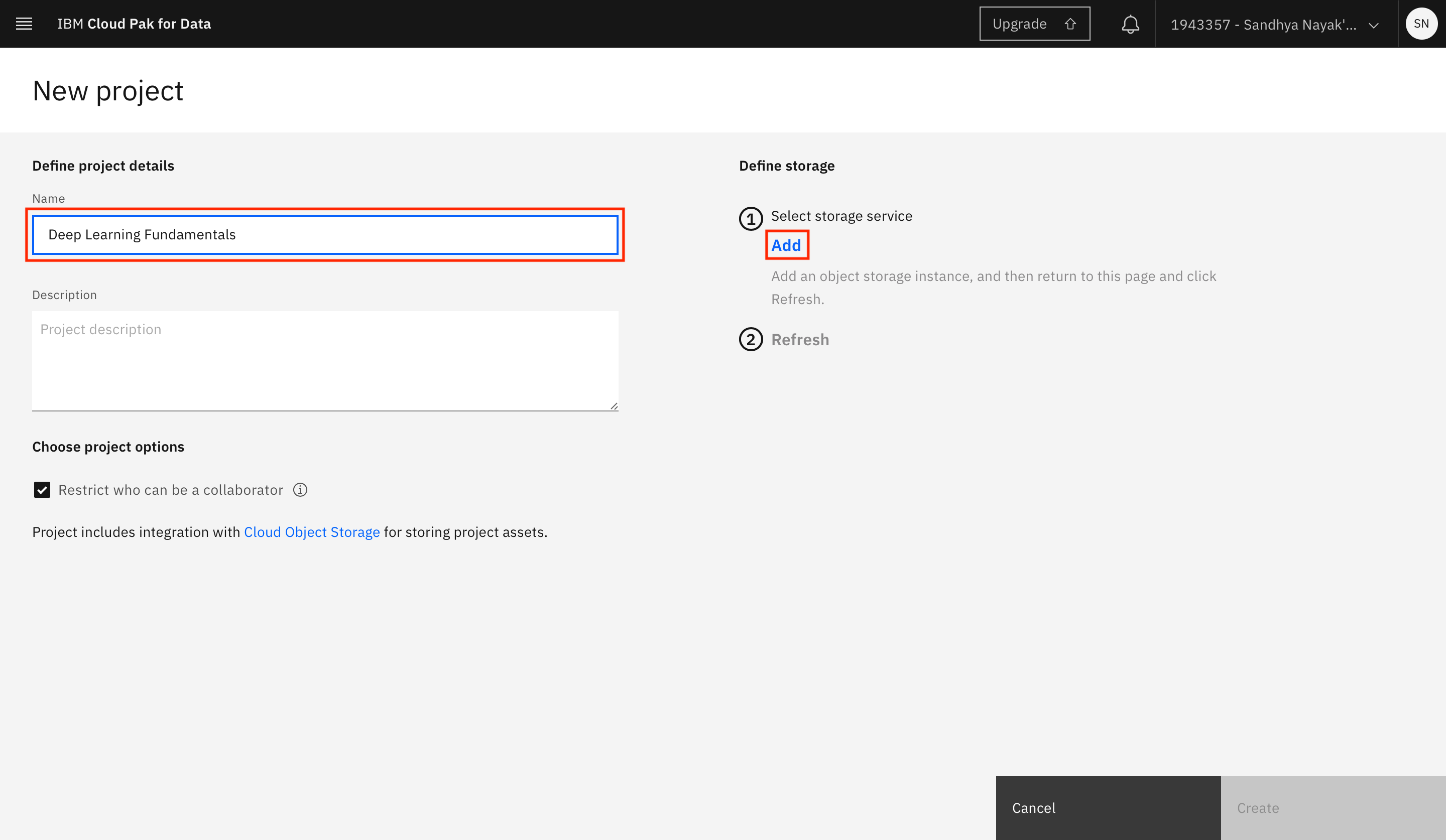
-
Select the type of plan to create (a Lite plan should suffice for this tutorial), and click Create.
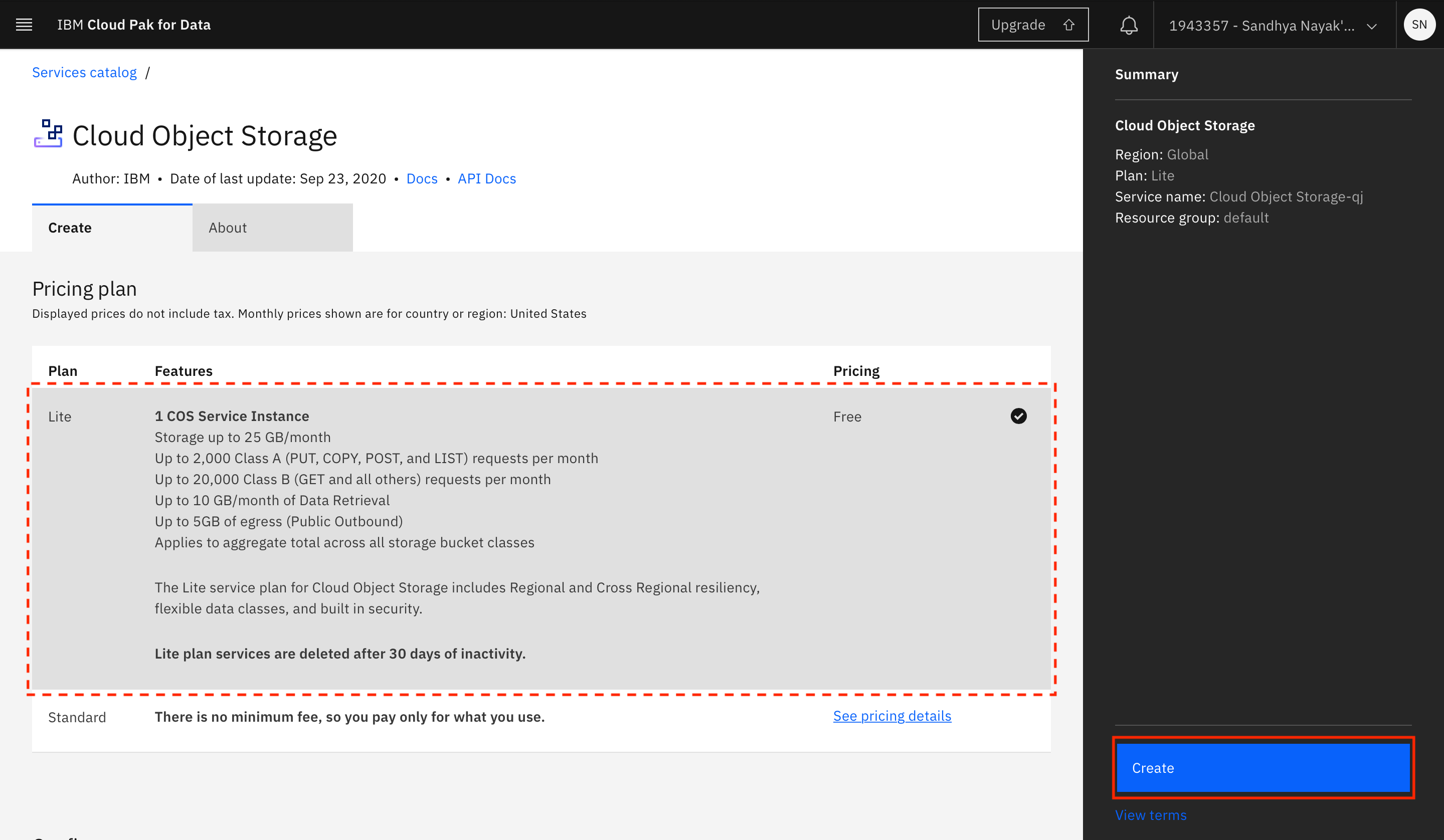
-
Click Refresh on the project creation page.
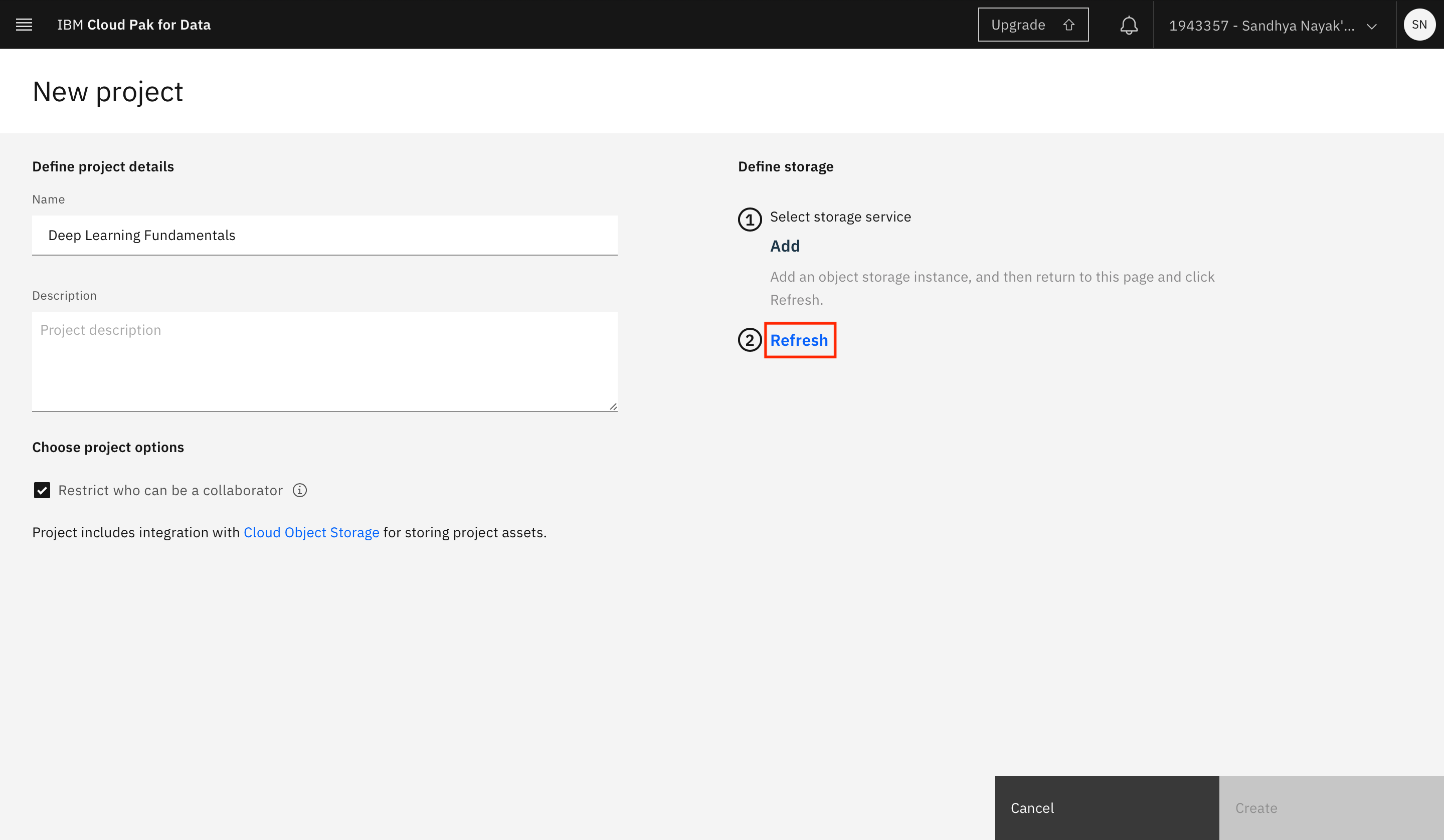
-
Click Create after you see the IBM Cloud Object Storage instance you created displayed under Storage.
-
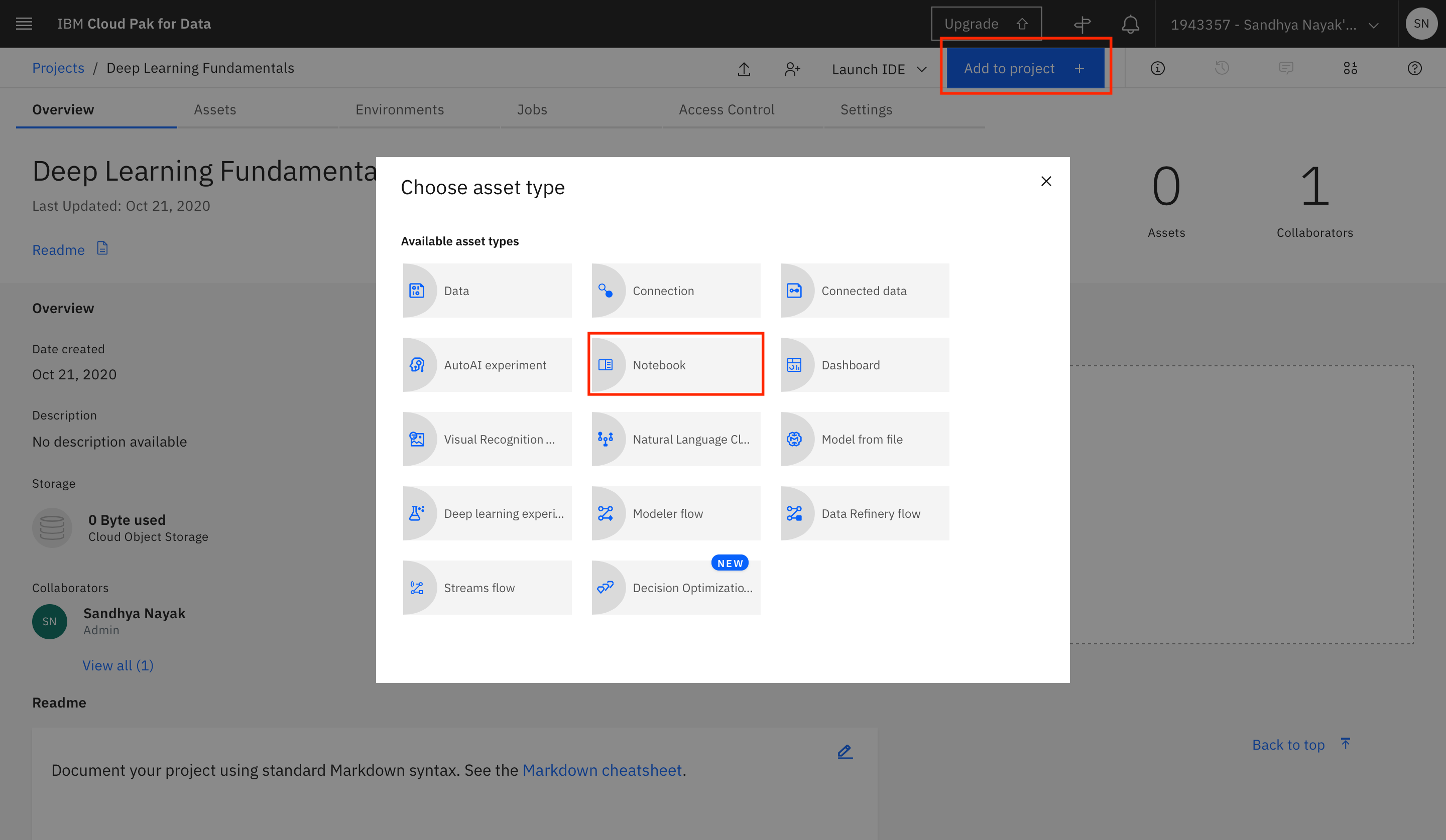
After the project is created, you can add the notebook to the project. Click Add to project +, and select Notebook.
-
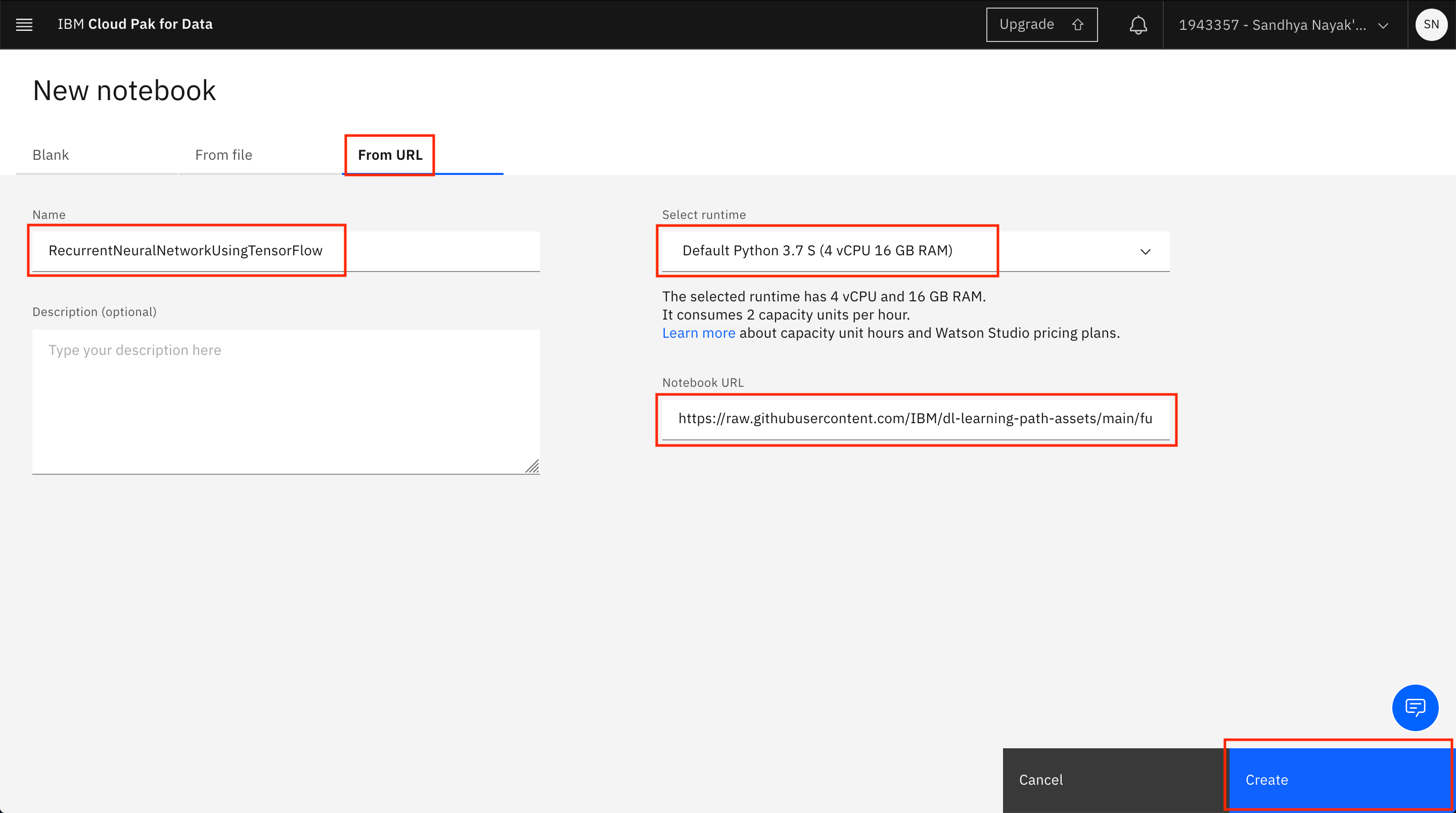
Switch to the From URL tab. Provide the name of the notebook as
RecurrentNeuralNetworkUsingTensorFlowand the Notebook URL ashttps://raw.githubusercontent.com/IBM/dl-learning-path-assets/main/fundamentals-of-deeplearning/notebooks/RecurrentNeuralNetworkUsingTensorFlow.ipynb. -
Under the Select runtime drop-down menu, select Default Python 3.7 S (4 vCPU 16 GB RAM). Click Create.
-
After the Jupyter Notebook is loaded and the kernel is ready, you can start executing the cells in the notebook.
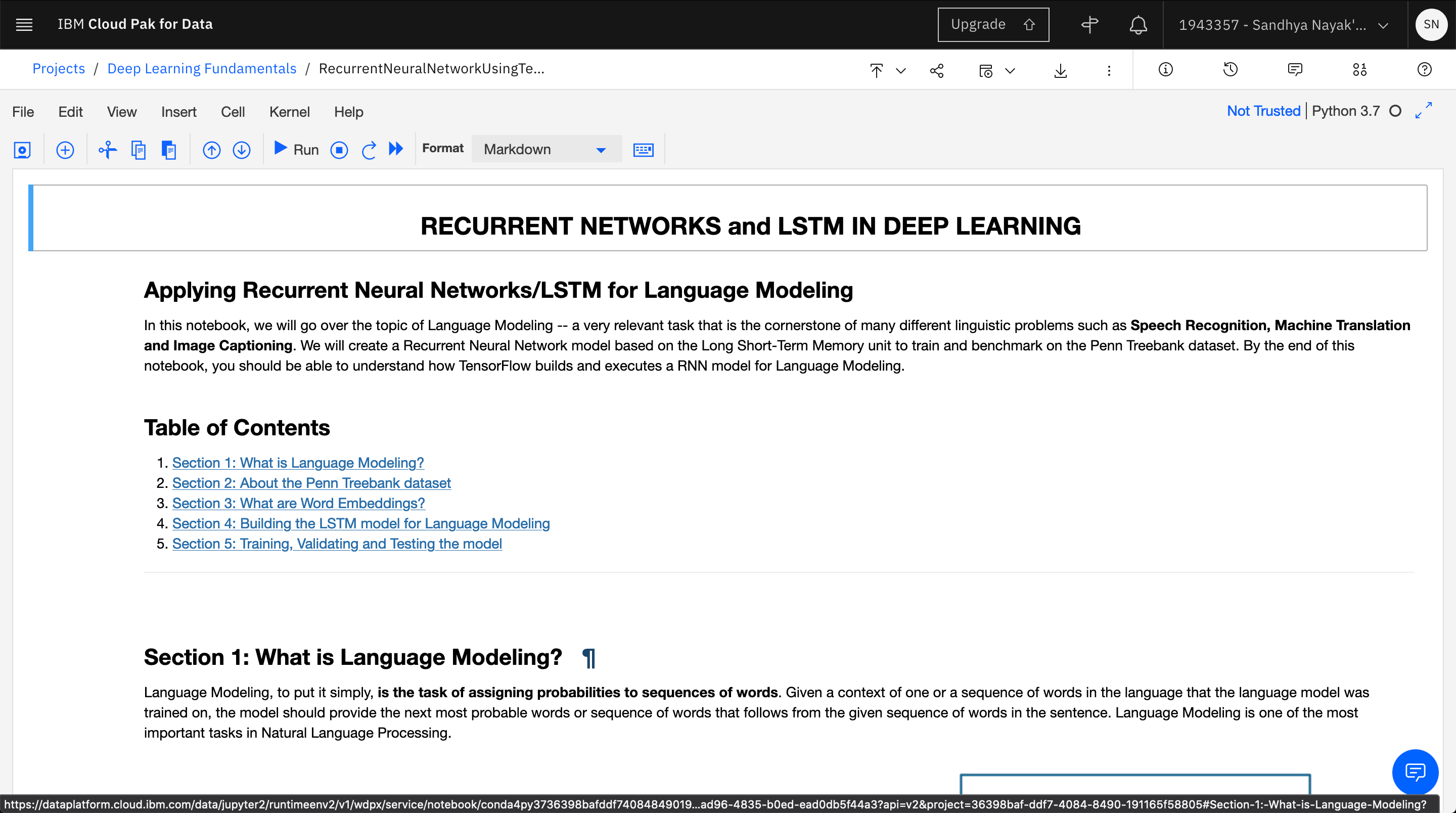









Important: Make sure that you stop the kernel of your notebooks when you are done to conserve memory resources.

Note: The Jupyter Notebook included in the project has been cleared of output. If you would like to see the notebook that has already been completed with output, refer to the example notebook.
Spend some time looking through the sections of the notebook to get an overview. A notebook is composed of text (markdown or heading) cells and code cells. The markdown cells provide comments on what the code is designed to do.
You run cells individually by highlighting each cell, then either clicking Run at the top of the notebook or using the keyboard shortcut to run the cell (**Shift + Enter **, but this can vary based on the platform). While the cell is running, an asterisk ([*]) shows up to the left of the cell. When that cell has finished running, a sequential number appears (for example, [17]).
Note: Some of the comments in the notebook are directions for you to modify specific sections of the code. Perform any changes as indicated before running the cell.
The notebook is divided into multiple sections.
- Section 1 gives an introduction to Language Modeling.
- Section 2 provides information about the Penn Treebank dataset which is being used to train and validate the model being built in this tutorial.
- Section 3 gives an introduction to Word Embeddings.
- Section 4 contains the code to build the LSTM model for Language Modeling.
- Section 5 contains the code to train, validate and test the model.
- Run the code cells in the notebook starting with the ones in section 4. The first few cells bring in the required modules such as tensorflow, numpy, reader and the dataset.
Note: The second code cell checks for the version of TensorFlow. The notebook only works with TensorFlow version 2.2.0-rc0, therefore, if an error is thrown here, you will need to ensure that you have installed TensorFlow version 2.2.0-rc0 in the first code cell.

Note: If you get the error in spite of installing TensorFlow version 2.2.0-rc0, your changes are not being picked up and you will need to restart the kernel by clicking on "Kernel"->"Restart and Clear Output". Wait until all the outputs disappear and then your changes should be picked up.

- The training, validation and testing of the model does not happen until the last code cell. Due to the number of epochs and the sheer size of the dataset, running this cell can take about 3 hours.

There are a number of ways in which you can reduce the time required for executing the notebook, i.e., the time needed to train and validate the model. While all of these methds will affect the performance of the model, some will cause a drastic change in performance.
- Fewer training epochs
The number of epochs set for training the model in the notebook is 15. You can reduce the number of epochs by changing the value of max_epochs.

A lower number of epochs may not bring down the model perplexity, resulting in poor performance of the model. On the other hand, an extremely higher number of epochs can cause overfitting, which will also result in poor model performance.
- Smaller dataset
Reducing the size of the dataset is another method to reduce the amount of time required for training. However, one should note that the this can negatively impact model performance. The model will be better trained when it is trained on a large amount of varied data.
- Use GPUs to increase processing power
You can make use of the GPU (Graphics Processing Unit) environments available within Watson Studio in order to accelerate model training. With GPU environments, you can reduce the training time needed for compute-intensive machine learning models you create in a notebook. With more compute power, you can run more training iterations while fine-tuning your machine learning models.
Note: GPU environments are only available with paid plans and not with the Lite (Free) Watson Studio plan. See the Watson Studio pricing plans
- Early stopping
You can also make use of EarlyStopping in order to improve training time. EarlyStopping stops training when a monitored metric has stopped improving. So, for example, you can specify that the training needs to stop if there is no improvement in perplexity for 3 consecutive epochs.
Refer the notebook used in the Demand forecasting using deep learning code pattern for an example of EarlyStopping.

In this tutorial, you learned about Language Modeling. You learned how to run a Jupyter Notebook using Watson Studio on IBM Cloud Pak for Data as a Service and how to create a Recurrent Neural Network model using TensorFlow based on the Long Short-Term Memory unit. Finally, you used this model to train and benchmark on the Penn Treebank dataset.
Login/Sign Up for IBM Cloud: https://ibm.biz/YourPathToDeepLearning
Hands-On Guide: https://ibm.biz/rnn-tensorflow-NNLab
Slides: https://ibmdevelopermea.github.io/YPDL-Recurrent-Neural-Networks-using-TensorFlow-Keras/#/
Workshop Replay: https://www.crowdcast.io/e/ypdl-3
Survey - https://ibm.biz/YPDL-Survey
-
YouTube - https://youtu.be/73gAq85IFCs
-
LinkedIn - https://www.linkedin.com/events/yourpathtodeeplearning6828696278394802176/
-
Twitter - https://twitter.com/mridulrb/status/1432342589986861056?s=20
-
Facebook - https://www.facebook.com/100003349938697/videos/893645731236407/
-
Periscope - https://www.periscope.tv/mridulrb/1RDGlPyzvpDGL
- 1st September - 6PM-8PM (GST)
- Personalized Recommendation Engines with TensorFlow
- https://www.crowdcast.io/e/ypdl-4