此工作完全基于Denny的教程,本人愚昧,详细记录,以备后用,或微助游客(代码中加入自己的详细注释).
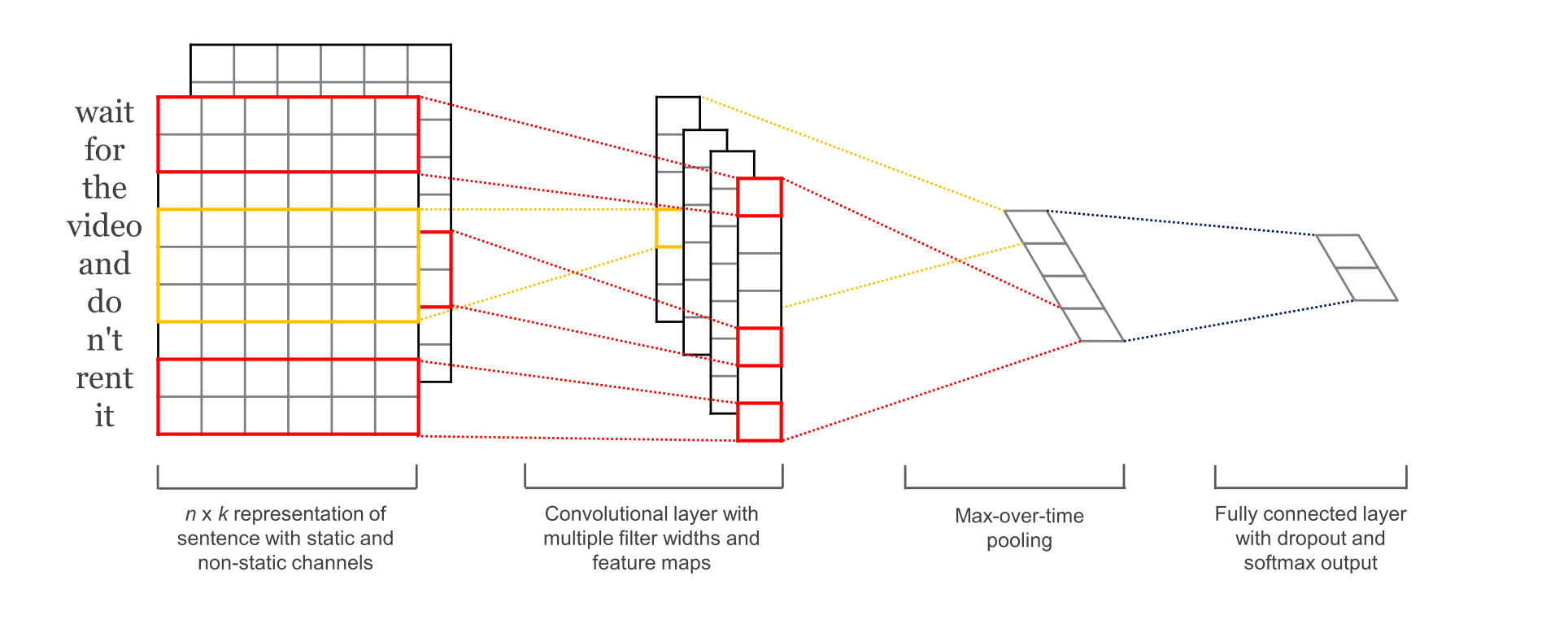
本文主要内容:工作的详细步骤说明以及TensorFlow的相关知识说明.下面是要实现的模型:
我们使用影评的数据集
用data_helper脚本来清洗数据,加载句子和标签,还有生成随机的batch.
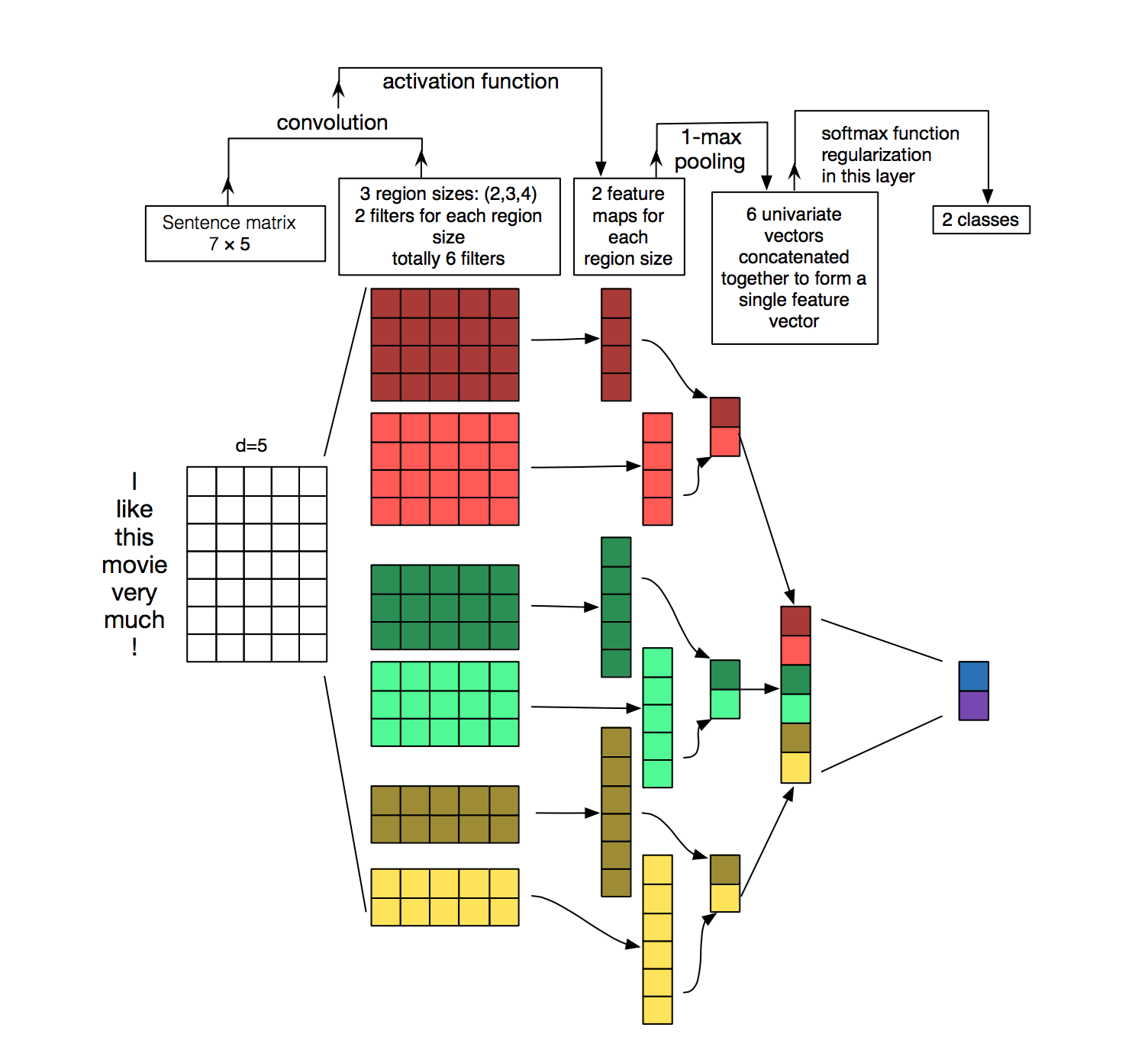
再放一张图帮助理解:
1.我们来自定义一个类TextCNN来承载网络的各种参数和配置,并在__init__()函数中初始化来生成Graph.
定义网络的输入:input_x,input_y,dropout_keep_prob,在训练和测试的时候需要feed这些placeholder.
TensorFlow也提供这样的机制:先创建特定数据类型的占位符(placeholder),之后再进行数据的填充. 但是placeholder节点被声明的时候是未被初始化的,也不包含数据,所以在train过程时,需要为这些placeholder节点提供数据,所以在train或test时候通过feed_dict供给数据.
2.定义 EMBEDDING LAYER, output:[None, sequence_length, embedding_size, 1]
这也是网络的第一层,词向量层.是为了把高维的词汇表中词的索引转化成低维的向量表征(vector representation).
如结构图所示,输入层是句子中的词语对应的word vector依次(从上到下)排列的矩阵,假设句子有 n 个词,vector的维数为 k ,那么这个矩阵就是 n×k 的。
TensorFlow的conv2d()函数的输入所需是:tensor of shape [batch, in_height, in_width, in_channels] ,4-D. tf.random_uniform(shape, minval,maxval),输出一个随机值(范围是[minval, maxval))来填充的的指定shape的tensor. tf.nn.embedding_lookup(self.W,input_x),这一步之后产生一个3-D的tensor:[None, sequence_length, embedding_size], 然后用tf.expand_dims()函数把3-DK扩展成4-D:[None, sequence_length, embedding_size, 1],对应与con2d()所以的tensor.
3.定义卷积和池化层, outut:[batch_size, 1, 1, num_filters]
模型使用不同size的卷积核(filter),对于不同的filter要分别处理,他们生成tensor的shape是不一样,最后需要把所有结果合并起来,装在pooled_outputs[]中. 首先定义W:filter matrix 和b:bias matrix,
W: a filter tensor of shape[filter_height,filter_width,in_channels,out_channels],[词个数,embedding_size,输入通道,输出通道] b: a bias tensor of shape [out_channels],他跟卷积层的输出通道数对应.
把第一层得到的词向量和W放入卷积函数con2v(),这里执行narrow convolution,每一次卷积之后得到的tensor的shape是:[1,sequence_length-filter_size+1,embedding_size,1],然后对卷积的输出做一次非线性的激活函数,得到的tensor的shape是:[1,sequence_length-filter_size+1,1,1].
再对这个结果执行max_pool(value, ksize, strides, padding, data_format="NHWC", name=None),在这里设置ksize为[1, sequence_length - filter_size + 1, 1, 1],而input的value的shape为:[[1,sequence_length-filter_size+1,1,1]],且stride为[1,1,1,1].所以,在使用某一size的filter中执行max_pool()后,所得到的结果为: [batch_size, 1, 1, num_filters],结果是一维的,就是每个输出通道有一个值,所以第四维是num_filter,这第四维也就对应求得的feature.
当得到所有filter中执行max_pool后的输出tensor后 ,把他们都合并起来,最后得到的结果:[batch_size, num_filters_total].
为了后面的dropout做准备,还可以flatten这个结果,最后就成一个一维的数组,每个元素就是每个通道的最终输出值.[f1,f2,f3,,,,,]
4.dropout层
为了有效防止过拟合,在max_pool之后加一层dropout,这是一个全链接层.
5.Final (unnormalized) scores and predictions
使用上层得到的结果,通过矩阵运算(xw_plus_b),可以求得最终的score,并且根据最高score来预测它所属的类别predictions.在这一步,我们也可以使用 softmax 函数把原始得分(raw score)转化为标准化概率.
6.loss and accuracy
使用上面的score可以进一步定义网络的loss和accuracy,loss值用来衡量网络的错误,我们的目的是让这个值尽可能减小.在分类问题中常用的损失函数是 cross-entropy loss.用它来计算每个类的cross-entropy loss,给我们score和对应的lebel.然后计算loss的平均值来作为最终的loss值.
最后定义accuracy,是训练和测试时的一个非常有用的指标.
1.设定各种Parameters
使用tf.flags.DEFINE_integer(),tf.flags.DEFINE_boolean()等函数
2.准备数据
使用data_helpers脚本中的load_data_labels()函数,得到x_test:[[splited setence]],y:[[label]],求得x_test句子的最大长度:max_document_length=56,用VocabularyProcessor类来构建一个词汇表,shape:(10662,56),每个sentence对应一个list,一共10662个sentences,每个list是56维度(最长sentence,不够的用0 pad),list的填充的是句子中word所对应的index。之后,shuffle data,最后分数据,Tarin data(y_train)和Dev data(y_dev).
3.然后就可以进行训练了 但是先理解TensorFlow中session和Graph的概念: 在TensorFlow中,会话(session)是你执行图(graph)操作的环境,它包含了变量(Variable)和队列(queue)的状态,一个session只在一个graph中运营.当你创建Variable和Operation时不明确制定一个session,就会使用TensorFlow默认创建的session.当然,你也可以使用session.as_default()方法来改变默认的session.
一个Graph包含了各种Operation和tensor,你可以使用过个Graph,但是通常的项目中只使用一个Graph,你能在多个session中使用相同的Graph,但是不能在一个Graph中使用多个session.TensorFlow通常会有一个默认创建的Graph,当然你也可以手动创建一个,并且设定为默认图.明确的创建session和graph能让我们正确的释放各种资源,当它们不在需要时.
当实例化我们的TextCNN类后,我们定义的Variable和Operation都被放置到Graph和session中了.接下来使用Adam方法来最小化模型的loss,这里新创建一个Operation(train_op,它其实是执行apply_gradients()方法返回的一个Op),来执行模型参数的梯度更新.train_op每执行一次就对应训练过程的一步,TensorFlow自动判断哪一个变量(Variable)是可训练的然后计算他们的梯度.通过定义一个global_step变量,然后把它传给我们的优化器(optimizer),我们让TensorFLow来管理每一步的训练,每一次执行train_op,global_step会自动增加.
然后指定模型和summaries的存储路径.
TensorFLow中有一个summaries的概念,它让在我们train和wevaluation阶段跟踪和可视化各种参数.比如,你可以跟踪模型的loss和accuracy是怎么发展的.
checkpoint:他能保存模型的参数,并可以在之后恢复此模型.Checkpoints用来在稍后进行训练,或者提前结束训练来调训最佳参数.我们使用Saver类来定义checkpoint.
在真正训练之前要初始化Graph中所有的参数: sess.run(tf.initialize_all_variables())
下面定义一个函数(train_step)来执行一个训练阶段,首先你必须使用feed-dict{a:value,..}给所有传入网络的placeholder nodes来赋值.
先看一下run(fetches, feed_dict=None, options=None, run_metadata=None)这个函数,传入的参数fetches:一个graph元素或者一组graph元素(list). 返回是对应ftches的一个值或者一组值.用session.run()来执行训练操作(train_op),它返回我们想要得到的所有Ops的值.注意,train_op不返回值,它只更新网络的参数.最后,输出当前batch的loss和accuracy,并保存summaries.
我们还写了一个类似的函数(dev_step),在任意数据集上来评估loss和accuracy,比如验证集或者整个训练集.实际上,这个函数跟上面的函数做了相同的事情,只是它没有训练操作,也禁止了dropout.
最后的最后,我们要在循环中进行训练了!我们在数据集上进行批次迭代,在每批数据上,调用train_step来训练,并且偶尔评估和checkpoint(保存模型).
有理解错误的地方欢迎指出,或者兴趣相投的同学,欢迎联系我(himon980@gmail.com),互相交流,互相进步.