


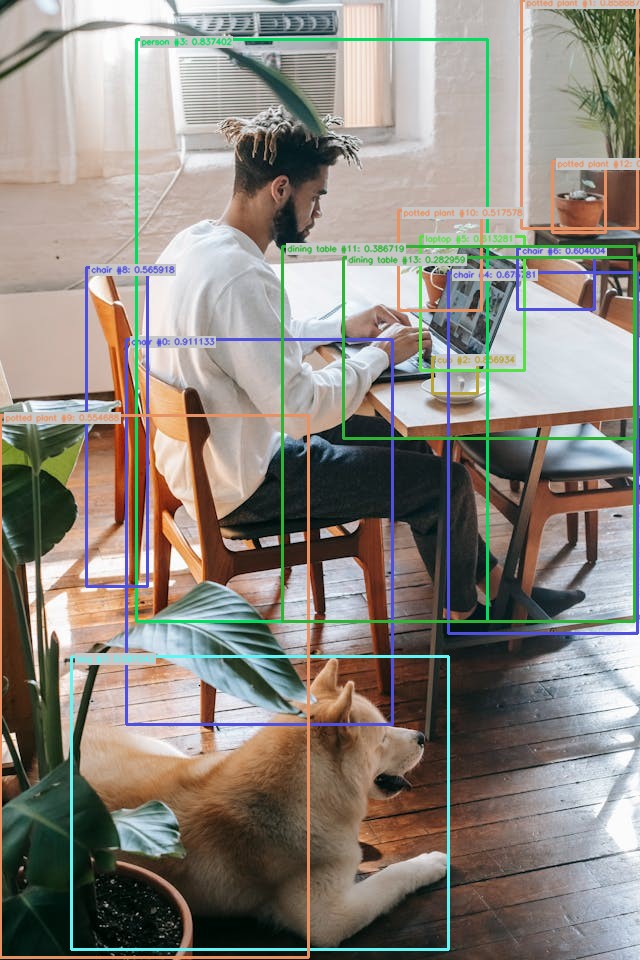
Train YOLOv10 object detection models.
We strongly recommend using a virtual environment. If you're not sure where to start, we offer a tutorial here.
pip install ikomiafrom ikomia.dataprocess.workflow import Workflow
# Init your workflow
wf = Workflow()
# Add dataset loader
coco = wf.add_task(name="dataset_coco")
coco.set_parameters({
"json_file": "path/to/json/annotation/file",
"image_folder": "path/to/image/folder",
"task": "detection",
})
# Add training algorithm
train = wf.add_task(name="train_yolo_v10", auto_connect=True)
# Launch your training on your data
wf.run()Ikomia Studio offers a friendly UI with the same features as the API.
- If you haven't started using Ikomia Studio yet, download and install it from this page.
- For additional guidance on getting started with Ikomia Studio, check out this blog post.
- model_name (str) - default 'yolov10m': Name of the YOLOv10 pre-trained model. Other model available:
- yolov10n
- yolov10s
- yolov10b
- yolov10l
- yolov10x
- batch_size (int) - default '8': Number of samples processed before the model is updated.
- epochs (int) - default '100': Number of complete passes through the training dataset.
- dataset_split_ratio (float) – default '0.9': Divide the dataset into train and evaluation sets ]0, 1[.
- input_size (int) - default '640': Size of the input image.
- weight_decay (float) - default '0.0005': Amount of weight decay, regularization method.
- momentum (float) - default '0.937': Optimization technique that accelerates convergence.
- workers (int) - default '0': Number of worker threads for data loading (per RANK if DDP).
- optimizer (str) - default '0.937': Optimizer to use, choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto]
- lr0 (float) - default '0.01': Initial learning rate (i.e. SGD=1E-2, Adam=1E-3)
- lr1 (float) - default '0.01': Final learning rate (lr0 * lrf)
- output_folder (str, optional): path to where the model will be saved.
- config_file (str, optional): path to the training config file .yaml.
Parameters should be in strings format when added to the dictionary.
from ikomia.dataprocess.workflow import Workflow
# Init your workflow
wf = Workflow()
# Add dataset loader
coco = wf.add_task(name="dataset_coco")
coco.set_parameters({
"json_file": "path/to/json/annotation/file",
"image_folder": "path/to/image/folder",
"task": "detection",
})
# Add training algorithm
train = wf.add_task(name="train_yolo_v10", auto_connect=True)
train.set_parameters({
"model_name": "yolov10m",
"epochs": "50",
"batch_size": "4",
"input_size": "640",
"dataset_split_ratio": "0.9",
"weight_decay": "0.0005",
"momentum": "0.937",
"workers": "0",
"optimizer": "auto",
"lr0": "0.01",
"lr1": "0.01"
})
# Launch your training on your data
wf.run()