Обратите внимание, пока материал находится в статусе черновика. Чем дальше вы продвинетесь вглубь текста, тем больше неувязок, косноязычия и ошибок вы там увидите, а где-то примерно в районе середины статьи окончательно попадёте в область разрозненных заметок, невнятных почеркушек и псоголовых воинов, воюющих с драконами. Пожалуйста, не судите строго, материал хоть и не быстро, но упорно корректируется, медленно дрейфуя в сторону большей читаемости.
.jpg)
Добрый день! Меня зовут Михаил Емельянов, по профессии я программист программ, а эту небольшую памятку по базовым возможностям языка Python меня сподвиг написать довольно существенный, на мой взгляд, разрыв между декларируемыми объемами всевозможных курсов программирования и требованиями реальных, даже достаточно скромнооплачиваеых вакансий.
Пользуясь аналогиями из игрового мира, можно сказать, что начинающий программист зачастую стоит на берегу озера кипящей лавы, в центре которого находится остров со столь вожделенными вакансиями, а промежуточные островки, по которым надо перепрыгивать, постепенно наращивая свои навыки в последовательных мини-квестах, либо отсутствуют, либо расположены несистемно и хаотично, либо достаточно ровная их последовательность обрывается, так и не успев помочь отойти сколько-нибудь далеко от берега. Давайте попробуем построить дорожку островков-подсказок, ряд которых, хоть и не без усилий, позволит-таки нам достичь цели.
Небольшое отступление про формат Jupiter Notebooks, на случай, если раньше вам не приходилось иметь с ним дела. Jupiter позволяет перемешивать текстовые заметки, исходные коды и результаты вывода программ.
Здесь вы видите текст, который выглядит как обычная статья, но это только потому, что исходный Jupiter Notebook был при помощи nbconvert преобразован в Markdown. На самом деле все примеры кода интерактивны, вы можете их менять, дополнять и вообще крутить как угодно, разбираясь в тонкостях Python; поэтому многие используемые методы не «разжеваны» (да такой задачи и не ставилось), Jupiter сам по себе лучший самоучитель. Исходные тексты лежат на github/amaargiru/pycore.
Для работы с Jupiter вы можете воспользоваться VS Code, JetBrains IntelliJ или каким-нибудь онлайн-инструментом, самым известным из которых являятся Google Colab.
В этой статье 100 % есть ошибки и неточности самых разных калибров, так что, если что-то углядите, не стесняйтесь выражаться в личку, в комментариях, на почту war4one@gmail.com, а если чувствуете в себе Силу — смело форкайте репу и пишите туда всё, что считаете нужным, все исправления и дополнения бурно приветствуются.
Погружаясь в Python, не забывайте про прекрасную официальную документацию docs.python.org. Изучив её, хотя бы по диагонали, и постепенно углубляясь в нужные разделы, вы сможете убедиться, что многие «хаки», «открытия» и прочие неочевидные вещи уже давно разжеваны, описаны и имеют подробные примеры применения.
Также я бы рекомендовал для изучения базового синтаксиса Python на полную катушку использовать leetcode.com. Если отфильтровать задачи по уровню «Easy», а потом добавить дополнительную сортировку по столбцу «Acceptance», то перед вами предстанет не волчий оскал соревновательной платформы, а ванильный букварь с плавно нарастающим уровнем задачек.
Что ж, пожалуй, довольно запрягать. Погнали!
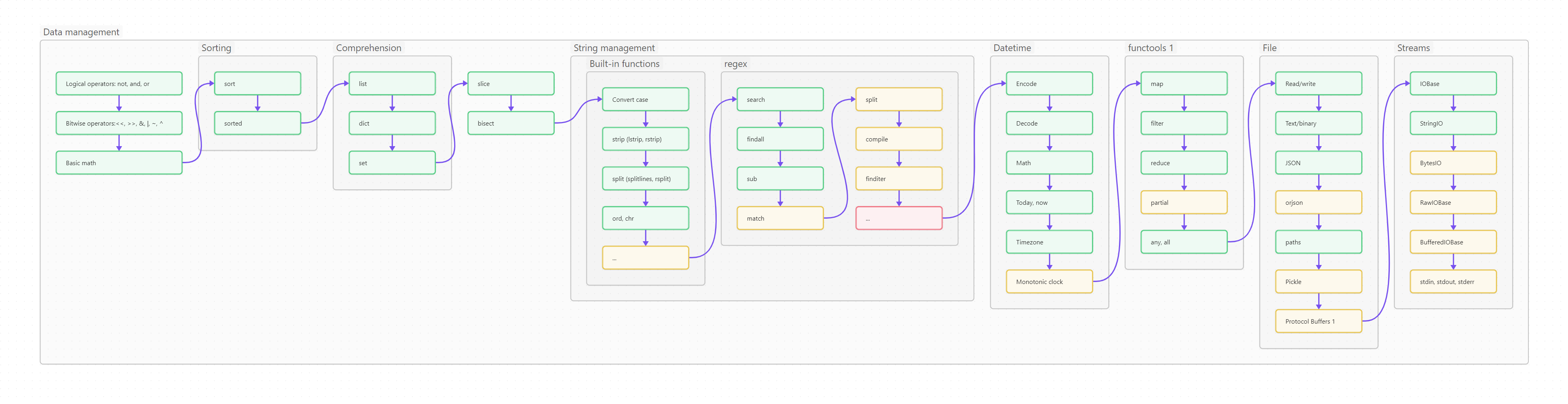
Ниже вы видите оглавление, сделанное для лучшего усвоения не плоским, а в виде диаграммы-путеводителя. Сама диаграмма, кстати, сделана на базе Mermaid и вынесена в отдельный проект на GitHub, так что вы легко можете менять картинку, просто корректируя текстовый файл.
Пользоваться путеводителем очень просто. Как в обычном тексте, идите слева направо и сверху вниз. Если вы только начинаете изучать Python, то идите по зеленым пунктам путеводителя. Если накопленный опыт, любопытство или необходимость толкают вас глубже, начните изучать разделы, помеченные серым. Оранжевым помечены темы, требующие углубленного изучения, ими лучше заняться (хотя бы и не копая, для начала, особенно глубоко) в третий проход. Даже если вы не собираетесь плотно использовать на практике какие-то из оранжевых тем, рассмотрите их хотя бы поверхностно, чтобы чётко понимать, что это, для чего необходимо, плюсы и минусы; держать, так сказать, в «горячем резерве».

«На востоке расположен Рай; место это преобильное и известно своими наслаждениями, но для людей недоступно. Место это ограждено огненной стеной до самого неба.»
Эбсторфская карта.
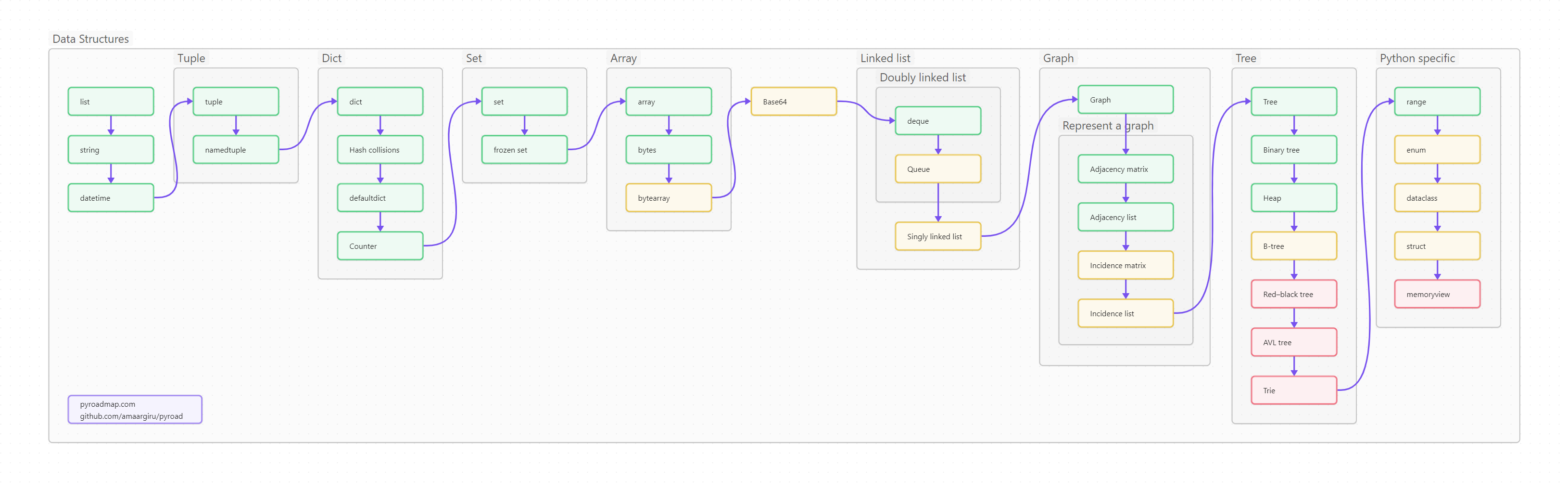
Как известно, программирование = структуры данных + алгоритмы (у Никлауса Вирта даже книжка такая есть). Начнем с данных, а потом плавненько перейдем к методам их обработки.
Список — самая универсальная и популярная структура данных в Python. Если вы пока точно не определились, какая структура понадобится в вашем проекте, просто возьмите список, с него достаточно просто мигрировать на что-нибудь более специализированное.
Список представляет собой упорядоченную изменяемую коллекцию объектов произвольных типов. Внутреннее строение списка - массив (точнее, vector) указателей, т. е. список является динамическим массивом.
a = [] # Создаем пустой список
a: list[int] = [10, 20]
b: list[int] = [30, 40]
a.append(50) # Добавляем значение в конец списка
b.insert(2, 60) # Вставляем значение по определенному индексу
print(a, b)
a += b
print(f"Add: {a}")
a.reverse()
b = list(reversed(a)) # reversed() возвращает итератор, а не список
print(f"Reverse: {a}, {b}")
b = sorted(a) # Возвращает новый отсортированный список
a.sort() # Модифицирует исходный список и не возвращает ничего
print(f"Sort: {a}, {b}")
s: str = "A whole string"
list_of_chars: list = list(s)
print(list_of_chars)
list_of_words: list = s.split()
print(list_of_words)
i: int = list_of_chars.index("w") # Возвращает индекс первого вхождения искомого элемента или вызывает исключение ValueError
print(i)
list_of_chars.remove("w") # Удаляет первое вхождение искомого элемента или вызывает исключение ValueError
e = list_of_chars.pop(9) # Удаляет и возвращает значение, расположенное по индексу. pop() (без аргумента) удалит и вернет последний элемент списка
print(list_of_chars, e)
a.clear() # Очистка списка[10, 20, 50] [30, 40, 60]
Add: [10, 20, 50, 30, 40, 60]
Reverse: [60, 40, 30, 50, 20, 10], [10, 20, 50, 30, 40, 60]
Sort: [10, 20, 30, 40, 50, 60], [10, 20, 30, 40, 50, 60]
['A', ' ', 'w', 'h', 'o', 'l', 'e', ' ', 's', 't', 'r', 'i', 'n', 'g']
['A', 'whole', 'string']
2
['A', ' ', 'h', 'o', 'l', 'e', ' ', 's', 't', 'i', 'n', 'g'] r
Кортеж — тоже список, только неизменяемый (immutable) и хэшируемый (hashable). Кортеж, содержащий те же данные, что и список, занимает меньше места:
a = [2, 3, "Boson", "Higgs", 1.56e-22]
b = (2, 3, "Boson", "Higgs", 1.56e-22)
print(f"List: {a.__sizeof__()} bytes")
print(f"Tuple: {b.__sizeof__()} bytes")List: 104 bytes
Tuple: 64 bytes
В соответствии с названием, имеет именованные поля. Удобно!
from collections import namedtuple
rectangle = namedtuple('rectangle', 'length width')
r = rectangle(length = 1, width = 2)
print(r)
print(r.length)
print(r.width)
print(r._fields)rectangle(length=1, width=2)
1
2
('length', 'width')
Словарь — вторая по частоте использования структура данных в Python. dict - реализация хеш-таблицы, поэтому в качестве ключа нельзя брать нехешируемый объект, например, список (тут-то нам и может пригодиться кортеж). Ключом словаря может быть любой неизменяемый объект: число, строка, datetime и даже функция. Такие объекты имеют метод __hash__(), который однозначно сопоставляет объект с некоторым числом. По этому числу словарь ищет значение для ключа.
Списки, словари и множества (которые мы рассмотрим чуть ниже) изменяемы и не имеют метода хеширования, при попытке подставить их в словарь возникнет ошибка.
d = {} # Создаем пустой словарь
d: dict[str, str] = {"Italy": "Pizza", "US": "Hot-Dog", "China": "Dim Sum"} # Непосредственное создание словаря
k = ["Italy", "US", "China"]
v = ["Pizza", "Hot-Dog", "Dim Sum"]
d = dict(zip(k, v)) # Создание словаря из двух коллекций при помощи zip
k = d.keys() # Коллекция ключей. Отражает изменения в основном словаре
v = d.values() # Коллекция значений. Тоже отражает изменения в основном словаре
k_v = d.items() # Кортежи ключ-значение, которые тоже отражают изменения в основном словаре
print(d)
print(k)
print(v)
print(k_v)
print(f"Mapping: {k.mapping['Italy']}")
d.update({"China": "Dumplings"}) # Добавление значение. При совпадении ключа старое значение будет перезаписано
print(f"Replace item: {d}")
c = d["China"] # Читаем значение
print(f"Read item: {c}")
try:
v = d.pop("Spain") # Удаляет значение или вызывает исключение KeyError
except KeyError:
print("Dictionary key doesn't exist")
# Примеры dict comprehension (более подробно comprehension будет рассмотрено ниже)
b = {k: v for k, v in d.items() if "a" in k} # Вернет новый словарь, отфильтрованный по значению ключа
print(b)
c = {k: v for k, v in d.items() if len(v) >= 7} # Вернет новый словарь, отфильтрованный по длине значений
print(c)
d.clear() # Очистка словаря{'Italy': 'Pizza', 'US': 'Hot-Dog', 'China': 'Dim Sum'}
dict_keys(['Italy', 'US', 'China'])
dict_values(['Pizza', 'Hot-Dog', 'Dim Sum'])
dict_items([('Italy', 'Pizza'), ('US', 'Hot-Dog'), ('China', 'Dim Sum')])
Mapping: Pizza
Replace item: {'Italy': 'Pizza', 'US': 'Hot-Dog', 'China': 'Dumplings'}
Read item: Dumplings
Dictionary key doesn't exist
{'Italy': 'Pizza', 'China': 'Dumplings'}
{'US': 'Hot-Dog', 'China': 'Dumplings'}
Любая хеш-таблица, в том числе и питоновский словарь, должна уметь решать проблему вычисления хеша. Для этого используются техники open addressing или chaining. Python использует open addressing.
Новый словарь инициализируется с 8 пустыми слотами.
Интерпретатор сначала пытается добавить новую запись по адресу, зависящему от хеша ключа.
addr = hash(key) & mask,где
mask = PyDictMINSIZE - 1Если этот адрес занят, то интерпретатор проверяет (при помощи ==) хеш и ключ. Если оба совпадают, то, значит, запись уже существует. Тогда начинается зондирование свободных слотов, которое идет в псевдослучайном порядке (порядок зависит от значения ключа). Новая запись будет добавлена по первому свободному адресу.
Чтение из словаря происходит аналогично, интерпретатор начинает поиск с позиции addr и идет по тому же псевдослучайному пути, пока не прочитает нужную запись.
Если попытаться прочитать из обычного словаря значение ключа, которого там нет, то будет выброшено исключение KeyError (исключения будут рассмотрены ниже). Defaultdict позволяет не писать обработчик исключений, а просто воспринимает чтение несуществующего ключа как команду записать в этот ключ и вернуть значение по умолчанию; например, defaultdict(int) вернет 0.
from collections import defaultdict
dd = defaultdict(int)
print(dd[10]) # Печать int, будет выведен ноль, значение по умолчанию
dd = {} # "Обычный" пустой словарь
# print(dd[10]) # вызовет исключение KeyError0
Счетчик подсчитывает передаваемые ему объекты. Иногда очень удобно просто бухнуть в счетчик какой-нибудь список и сразу получить структуру данных с подсчитанными элементами.
from collections import Counter
shirts_colors = ["red", "white", "blue", "white", "white", "black", "black"]
c = Counter(shirts_colors)
print(c)
c["blue"] += 1
print(f"After shopping: {c}")Counter({'white': 3, 'black': 2, 'red': 1, 'blue': 1})
After shopping: Counter({'white': 3, 'blue': 2, 'black': 2, 'red': 1})
Объяснение работы Counter() при помощи defaultdict():
from collections import defaultdict
shirts_colors = ["red", "white", "blue", "white", "white", "black", "black"]
d = defaultdict(int)
for shirt in shirts_colors:
d[shirt] += 1
print(d)defaultdict(<class 'int'>, {'red': 1, 'white': 3, 'blue': 1, 'black': 2})
Третья по распространенности питоновская структура данных. Когда-то, когда Python был молод, множества представляли собой несколько редуцированные словари, но со временем их судьбы (и реализации) стали расходиться. Однако, множество всё-таки является хеш-таблицей с соответствующим быстродействием на разных типах операций.
big_cities: set["str"] = {"New-York", "Los Angeles", "Ottawa"}
american_cities: set["str"] = {"Chicago", "New-York", "Los Angeles"}
big_cities |= {"Sydney"} # Добавить значение (или add())
american_cities |= {"Salt Lake City", "Seattle"} # Сложить множества (или update())
print(big_cities, american_cities)
union_cities: set["str"] = big_cities | american_cities # Или union()
intersected_cities: set["str"] = big_cities & american_cities # Или intersection()
dif_cities: set["str"] = big_cities - american_cities # Или difference()
symdif_cities: set["str"] = big_cities ^ american_cities # Или symmetric_difference()
issub: bool = big_cities <= union_cities # Или issubset()
issuper: bool = american_cities >= dif_cities # Или issuperset()
print(union_cities)
print(intersected_cities)
print(dif_cities)
print(symdif_cities)
print(issub, issuper)
big_cities.add("London")
big_cities.remove("Ottawa") # Удаляет значение, если оно имеется или выбрасывает KeyError
big_cities.discard("Los Angeles") # Удаляет значение без выбрасывания KeyError
big_cities.pop() # Возвращает и удаляет случайное значение (порядок в set неопределен) или выбрасывает KeyError
big_cities.clear() # Очищает множество{'New-York', 'Los Angeles', 'Sydney', 'Ottawa'} {'New-York', 'Seattle', 'Chicago', 'Los Angeles', 'Salt Lake City'}
{'Ottawa', 'Salt Lake City', 'Chicago', 'New-York', 'Seattle', 'Sydney', 'Los Angeles'}
{'New-York', 'Los Angeles'}
{'Ottawa', 'Sydney'}
{'Seattle', 'Ottawa', 'Chicago', 'Salt Lake City', 'Sydney'}
True False
Frozen set — то же множество, только иммутабельное и хешируемое. Напоминает разницу между списком и кортежем, не правда ли?
a = frozenset({"New-York", "Los Angeles", "Ottawa"})Я перешел на Python с языков, более приближенных к «железу» (C, C#, даже на ассемблере когда-то писал за деньги :) и сначала немного удивлялся, что обычный массив, в котором всё так удобно лежит на своих местах, используется относительно редко. Массив в Python не является структурой данных, выбираемой по умолчанию и используется только в случаях, когда решающую роль начинают играть размер структуры и скорость её обработки. Но, с другой стороны, если вы смотрите в сторону NumPy и Pandas (немного затронуты ниже), то массивы — ваше всё.
Массив хранит переменные определенного типа, поэтому, в отличие от списка, не требует создания нового объекта для каждой новой переменной и выигрывает у списка в размерах и скорости доступа. Можно сказать, что это тонкая обёртка над Си-массивами.
Следует различать array («просто» массив), bytes (иммутабельный массив, содержащий только байты, наследие str из Python 2) и bytearray (мутабельный байтовый массив).
from array import array
a1 = array("l", [1, 2, 3, -4])
a2 = array("b", b"1234567890")
b = bytes(a2)
print(a1)
print(a2[0])
print(b)
print(a1.index(-4)) # Возвращает индекс элементы или выбрасывает ValueErrorarray('l', [1, 2, 3, -4])
49
b'1234567890'
3
### Encode
b1 = bytes([1, 2, 3, 4]) # Целые числа должны быть в диапазоне от 0 to 255
b2 = "The String".encode('utf-8')
b3 = (-1024).to_bytes(4, byteorder='big', signed=True) # byteorder = "big"/"little"/"sys.byteorder", signed = False/True
b4 = bytes.fromhex('FEADCA') # Для большей читаемости hex-значения могут быть разделены пробелами
b5 = bytes(range(10,30,2))
print(b1, b2, b3, b4, b5)
### Decode
c: list = list(b"\xfc\x00\x00\x00\x00\x01")
s: str = b'The String'.decode("utf-8")
b: int = int.from_bytes(b"\xfc\x00", byteorder='big', signed=False) # byteorder = "big"/"little"/"sys.byteorder", signed = False/True
s2: str = b"\xfc\x00\x00\x00\x00\x01".hex(" ")
print(c, s, b, s2)
with open("1.bin", "wb") as file: # Байтовая запись в файл
file.write(b1)
with open("1.bin", "rb") as file: # Чтение из файла
b6 = file.read()
print(b6)b'\x01\x02\x03\x04' b'The String' b'\xff\xff\xfc\x00' b'\xfe\xad\xca' b'\n\x0c\x0e\x10\x12\x14\x16\x18\x1a\x1c'
[252, 0, 0, 0, 0, 1] The String 64512 fc 00 00 00 00 01
b'\x01\x02\x03\x04'
Односвязный список представляет набор связанных узлов, каждый из которых хранит собственные данные и ссылку на следующий узел. В практике применим редко, но его любят использовать интервьюеры на собеседованиях, чтобы кандидат мог блеснуть своими алгоритмическими знаниями. В Python встроенной реализации не имеет, можно или использовать deque (в основе которого лежит двусвязный список), или написать свою реализацию.
Ссылки в каждом узле указывают на предыдущий и на последующий узел в списке. Можно или использовать deque, или написать свою реализацию.
from collections import deque
d = deque([1, 2, 3, 4], maxlen=1000)
d.append(5) # Add element to the right side of the deque
d.appendleft(0) # Add element to the left side of the deque by appending elements from iterable
d.extend([6, 7]) # Extend the right side of the deque
d.extendleft([-1, -2]) # Extend the left side of the deque
print(d)
a = d.pop() # Remove and return an element from the right side of the deque. Can raise an IndexError
b = d.popleft() # Remove and return an element from the left side of the deque. Can raise an IndexError
print(a, b)
print(d)deque([-2, -1, 0, 1, 2, 3, 4, 5, 6, 7], maxlen=1000)
7 -2
deque([-1, 0, 1, 2, 3, 4, 5, 6], maxlen=1000)
Queue реализует FIFO со множественными поставщиками данных и множественными потребителями. Может быть особенно полезен при многопоточности, позволяя корректно обмениваться информацией между потоками. Также существуют LifoQueue для реализации LIFO и PriorityQueue для реализации очереди с приоритетом.
from queue import Queue
q = Queue(maxsize=1000)
q.put("eat", block=True, timeout=10)
q.put("sleep") # По умолчанию block=True, timeout=None
q.put("code")
q.put_nowait("repeat") # Эквивалент put("repeat", block=False). Если свободный слот не будет предоставлен немедленно, будет вызвано исключение queue.Full
print(q.queue)
a = q.get(block=True, timeout=10) # Удалить и возвратить элемент из FIFO
b = q.get() # По умолчанию block=True, timeout=None
c = q.get_nowait() # Эквивалент get(False)
print(a, b, c, q.queue)deque(['eat', 'sleep', 'code', 'repeat'])
eat sleep code deque(['repeat'])
Иерархическая структура данных, в которой каждый узел имеет не более двух потомков. Встроенной реализации не имеет, нужно писать свою. Как правило, используются деревья с дополнительными свойствами, рассмотренные ниже.
Бинарное дерево, удовлетворяющее свойство кучи: если B является узлом-потомком узла A, то ключ(A) ≥ ключ(B). Куча является максимально эффективной реализацией абстрактного типа данных, который называется очередью с приоритетом и поддерживающего две обязательные операции — добавить элемент и извлечь минимум (или максимум, в зависимости от реализации).
В Python min-куча (наименьшее значение всегда лежит в корне) реализована на базе списка при помощи встроенного модуля heapq. Если вам нужна max-куча, с максимальным значением в корне, можете воспользоваться советами со Stackoverflow.
import heapq
h = [211, 1, 43, 79, 12, 5, -10, 0]
heapq.heapify(h) # Превращаем список в кучу
print(h)
heapq.heappush(h, 2) # Добавляем элемент
print(h)
m = heapq.heappop(h) # Извлекаем минимальный элемент
print(h, m)[-10, 0, 5, 1, 12, 211, 43, 79]
[-10, 0, 5, 1, 12, 211, 43, 79, 2]
[0, 1, 5, 2, 12, 211, 43, 79] -10
Пробежимся коротенько по остальным структурам данных, которые в Python не имеют встроенной реализации, но, тем не менее, могут весьма пригодиться в реальном проекте.
Сбалансированное дерево, оптимизированное для доступа к относительно медленным элементам памяти (например, дисковым структурам или индексам баз данных); как ветви, так и листья представляют собой списки (для того, чтобы можно было считать такой список в один проход для дальнейшего быстрого разбора в ОЗУ). Нужно писать свою реализацию. Либо — воспользоваться встроенной в Python поддержкой базы данных sqlite3, эта БД как раз реализована на би-дереве.
Самобалансирующееся двоичное дерево поиска, позволяющее быстро выполнять основные операции: добавление, удаление и поиск узла. Сбалансированность достигается за счёт введения дополнительного признака узла дерева — «цвета». Этот атрибут может принимать одно из двух возможных значений — «чёрный» или «красный». Листовые узлы КЧ деревьев не содержат данных, поэтому не требуют выделения памяти — достаточно просто записать в узле-предке нулевой указатель на потомка. Нужно писать свою реализацию.
Возможно, вы читали о том, что при собеседовании в FAANG претендентов «заставляют крутить красно-черное дерево на доске». Это «кружение» и есть балансировка, после операции вставки или удаления элемента дерево нужно отбалансировать, с примерным объемом кода вы можете ознакомиться здесь или здесь.
В АВЛ-деревьях операции вставки и удаления работают медленнее, чем в красно-черных деревьях (при том же количестве листьев красно-чёрное дерево может быть выше АВЛ-дерева, но не более чем в 1,388 раза). Поиск же в АВЛ-дереве выполняется быстрее (максимальная разница в скорости поиска составляет 39 %). Нужно писать свою реализацию.
Структура данных, позволяющая хранить ассоциативный массив, ключами которого являются строки. Нужно писать свою реализацию.
В квадратных скобках показан худший случай.
| Структура | Реализация | Применение | Индексация | Поиск | Вставка | Удаление | Память |
|---|---|---|---|---|---|---|---|
| Динамический массив | list | 1 | n | n | n | n | |
| Хэш таблица | dict, set | 1 [n] |
1 [n] |
1 [n] |
n | ||
| Массив | array, bytes, bytearray | Для хранения однотипных данных | 1 | n | n | n | n |
| Односвязный список | - (~deque) | n | n | 1 | 1 | n | |
| Двусвязный список | deque | FIFO, LIFO | n | n | 1 | 1 | n |
| Бинарное дерево | - | logn [n] |
logn [n] |
logn [n] |
logn [n] |
n | |
| Куча | heapq | Очередь с приоритетом | 1 (find min) |
logn | logn (del min) |
n | |
| B-tree (Би-дерево) | ~sqlite | Для памяти с медленным доступом | logn | logn | logn | logn | n |
| КЧ дерево | - | logn | logn | logn | logn | n | |
| АВЛ дерево | - | logn | logn | logn | logn | n | |
| Префиксное дерево | - | T9, алгоритм Ахо–Корасик, алгоритм LZW |
key | key | key |
Удобные конструкции для определения заранее известных перечислений.
from enum import Enum, auto
import random
class Currency(Enum):
euro = 1
us_dollar = 2
yuan = auto()
local_currency = Currency.us_dollar
print(local_currency)
local_currency = Currency["us_dollar"] # Может вызвать исключение KeyError
print(local_currency)
local_currency = Currency(2) # Может вызвать исключение ValueError
print(local_currency)
print(local_currency.name)
print(local_currency.value)
list_of_members = list(Currency)
member_names = [e.name for e in Currency]
member_values = [e.value for e in Currency]
random_member = random.choice(list(Currency))
print(list_of_members, "\n",
member_names, "\n",
member_values, "\n",
random_member)Currency.us_dollar
Currency.us_dollar
Currency.us_dollar
us_dollar
2
[<Currency.euro: 1>, <Currency.us_dollar: 2>, <Currency.yuan: 3>]
['euro', 'us_dollar', 'yuan']
[1, 2, 3]
Currency.euro
range() возвращает иммутабельную последовательность чисел, которая часто используется как задатчик диапазона для цикла for.
r1: range = range(11) # Возвращает последовательность чисел от 0 до 10
r2: range = range(5, 21) # Возвращает последовательность чисел от 5 до 20
r3: range = range(20, 9, -2) # Возвращает последовательность чисел от 20 до 10 с шагом 2
print("To exclusive: ", end="")
for i in r1:
print(f"{i} ", end="")
print("\nFrom inclusive to exclusive: ", end="")
for i in r2:
print(f"{i} ", end="")
print("\nFrom inclusive to exclusive with step: ", end="")
for i in r3:
print(f"{i} ", end="")
print(f"\nFrom = {r3.start}")
print(f"To = {r3.stop}")To exclusive: 0 1 2 3 4 5 6 7 8 9 10
From inclusive to exclusive: 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
From inclusive to exclusive with step: 20 18 16 14 12 10
From = 20
To = 9
Декоратор, автоматически создающий методы init(), repr() и eq(). Нужен для создания классов, главной задачей которых является хранение данных. Аннотации типов обязательны. Существует более продвинутая альтернатива под названием attrs.
from dataclasses import dataclass
from decimal import *
from datetime import datetime
@dataclass
class Transaction:
value: Decimal
issuer: str = "Default Bank"
dt: datetime = datetime.now()
t1 = Transaction(value=1000_000, issuer="Deutsche Bank", dt = datetime(2022, 1, 1, 12))
t2 = Transaction(1000)
print(t1)
print(t2)Transaction(value=1000000, issuer='Deutsche Bank', dt=datetime.datetime(2022, 1, 1, 12, 0))
Transaction(value=1000, issuer='Default Bank', dt=datetime.datetime(2022, 9, 6, 17, 50, 36, 162897))
Dataclass может быть сделан иммутабельным с директивой frozen=True.
from dataclasses import dataclass
@dataclass(frozen=True)
class User:
name: str
account: intЗапаковка (и распаковка, разумеется) данных в байтовые последовательности с предопределенными размерами каждого элемента данных, их порядка в структуре, а также порядка байт для многобайтовых типов данных. Позволяет превращать Python-овский int в, например, short int или long int (подробности про систему типов языка Си).
При работе со структурами вам нужно будет знать, что такое little-endian и big-endian, а также не забывать, что размер типа данных в Си бывает разным.
from struct import pack, unpack, iter_unpack
b = pack(">hhll", 1, 2, 3, 4)
print(b)
t = unpack(">hhll", b)
print(t)
i = pack("ii", 1, 2) * 5
print(i)
print(list(iter_unpack('ii', i)))b'\x00\x01\x00\x02\x00\x00\x00\x03\x00\x00\x00\x04'
(1, 2, 3, 4)
b'\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00'
[(1, 2), (1, 2), (1, 2), (1, 2), (1, 2)]
Строки в Python 3 — иммутабельные последовательности, использующие кодировку Unicode.
se: str = "" # Пустая строка
si: str = str(12345) # Создает строку из числа
sj: str = " ".join(["Follow", "the", "white", "rabbit"]) # Собирает строку из кусочков, используя указанный сепаратор
print(f"Joined string: {sj}")
is_contains: bool = "rabbit" in sj # Проверка наличия подстроки
is_startswith = sj.startswith("Foll")
is_endswith = sj.endswith("bbit")
print(f"is_contains = {is_contains}, is_startswith = {is_startswith}, is_endswith = {is_endswith}")
sr: str = sj.replace("rabbit", "sheep") # Замена подстроки. Можно указать количество замен: sr: str = sj.replace("rabbit", "sheep", times)
print(f"After replace: {sr}")
i1 = sr.find("rabbit") # Возвращает стартовый индекс первого вхождения или -1. Есть еще rfind(), начинающий искать с конца строки
i2 = sr.index("sheep") # Возвращает стартовый индекс первого вхождения или выкидывает ValueError. Есть еще rindex(), начинающий искать с конца строки
print(f"Start index of 'rabbit' is {i1}, start index of 'sheep' is {i2}")
d = str.maketrans({"a" : "x", "b" : "y", "c" : "z"})
st = "abc".translate(d)
print(f"Translate string: {st}")
sr = sj[::-1] # Реверс через slice с отрицательным шагом
print(f"Reverse string: {sr}")Joined string: Follow the white rabbit
is_contains = True, is_startswith = True, is_endswith = True
After replace: Follow the white sheep
Start index of 'rabbit' is -1, start index of 'sheep' is 17
Translate string: xyz
Reverse string: tibbar etihw eht wolloF
Для работы с датами и временем в datetime есть типы date, time, datetime и timedelta. Все они хешируемы и иммутабельны.
from datetime import date, time, datetime, timedelta
d: date = date(year=1964, month=9, day=2)
t: time = time(hour=12, minute=30, second=0, microsecond=0, tzinfo=None, fold=0)
dt: datetime = datetime(year=1964, month=9, day=2, hour=10, minute=30, second=0)
td: timedelta = timedelta(weeks=1, days=1, hours=12, minutes=13, seconds=14)
print (f"{d}\n {t}\n {dt}\n {td}")1964-09-02
12:30:00
1964-09-02 10:30:00
8 days, 12:13:14
Получение текущей даты или даты/времени.
from datetime import date, datetime
import pytz
import time
d: date = date.today()
dt1: datetime = datetime.today()
dt2: datetime = datetime.utcnow()
dt3: datetime = datetime.now(pytz.timezone('US/Pacific'))
t1 = time.time() # Эпоха Unix
t2 = time.ctime()
print (f"{d}\n {dt1}\n {dt2}\n {dt3}\n {t1}\n {t2}")2022-09-27
2022-09-27 09:47:02.430474
2022-09-27 04:47:02.430474
2022-09-26 21:47:02.430474-07:00
1664254022.4304743
Tue Sep 27 09:47:02 2022
Часовые пояса.
from datetime import date, time, datetime, timedelta, tzinfo
from dateutil.tz import UTC, tzlocal, gettz, datetime_exists, resolve_imaginary
tz1: tzinfo = UTC # Часовой пояс UTC
tz2: tzinfo = tzlocal() # Местный часовой пояс
tz3: tzinfo = gettz() # Местный часовой пояс
tz4: tzinfo = gettz("America/Chicago") # Или, например, "Asia/Kolkata". Полный список: en.wikipedia.org/wiki/List_of_tz_database_time_zones
local_dt = datetime.today()
utc_dt = local_dt.astimezone(UTC) # Конвертация местного часового пояса в часовой пояс UTC
print (f"{tz1}\n {tz2}\n {tz3}\n {tz4}\n {local_dt}\n {utc_dt}")tzutc()
tzlocal()
tzlocal()
tzfile('US/Central')
2022-09-27 09:19:35.399362
2022-09-27 04:19:35.399362+00:00
Позволю себе крошечную ремарку, которая была бы несколько неуместна ни в начале статьи (когда вы только взвешивали её полезность) ни, тем более, в конце (чтобы не портить послевкусия). Раз уж вы, прочитав довольно значительный кусок этого материала, невольно верифицировали себя как представитель программной индустрии, причём, как специалиста, непосредственно работающего с кодом, то, следовательно, есть некоторая ненулевая вероятность того, что вы ищете нового сотрудника. Дело в том, что я, автор этой статьи, ищу новую работу, и если вам нужен middle backend Python-программист, то, возможно, вас заинтересует моя кандидатура.
Большую часть своей осмысленной жизни я разрабатывал встроенные устройства на базе микроконтроллеров, 50/50 занимаясь схемотехникой и программированием. Моей последней «железячной» разработкой стал двадцатипятигигабитный маршрутизатор на базе шестнадцатиядерного процессора (звучит как заклинание из «Гарри Поттера» :), что по сложности примерно соответствует материнской плате персонального компьютера, после чего я перешел в чистые программисты. До этого в основном работал с ассемблером, C и C#, а на базе своих заметок по вновь изучаемому Python я и написал эту статью. На мой взгляд, достаточно логично сразу озвучить потенциальному работодателю свой примерный профессиональный уровень; завалить собеседование я не боюсь (всё равно профит, пообщаюсь с умными людьми), а вот понимания своего несоответствия занимаемой должности, выявленного в течении испытательного срока, хотелось бы избежать.
Собственно, вот всё, что я хотел бы вам сообщить: моё резюме, Github, емейл war4one@gmail.com и телефон 8 917 809-89-81 (лучше пишите в Telegram или WhatsApp).
А теперь давайте вернёмся в основное русло нашего повествования.
«Огненный поток, поднимающийся подобно пламени от земли до неба, опоясывал пространство величиною с маленький остров.»
История о докторе Иоганне Фаусте, знаменитом чародее и чернокнижнике.
Самый простой метод обработки данных, просто возвращает ту часть данных, местоположение которой (индексы) удовлетворяет определенным условиям.
a:str = "Pack my box with five dozen liquor jugs"
start, stop = 8, 21
b:str = a[start:stop] # Значения от start до stop-1
c:str = a[start:] # Значения от start до конца структуры
d:str = a[:stop] # Значения от начала до stop-1
e:str = a[:] # Полная копия структуры
print(b, "\n",
c, "\n",
d, "\n",
e, "\n")box with five
box with five dozen liquor jugs
Pack my box with five
Pack my box with five dozen liquor jugs
Значения start и stop могут быть отрицательными, это будет означать, что отсчет ведется от конца структуры. Можно также использовать значение step, чтобы на выход среза попали не все подряд данные из входной структуры.
a:str = "Step on no pets"
b:str = a[-4:] # «Хвостик»
c:str = a[::-1] # Реверс входной строки
d:str = a[4::-1] # Первые четыре значения, реверсированы
e:str = a[::2] # Каждый второй символ
print(b, "\n",
c, "\n",
d, "\n",
e, "\n")pets
step on no petS
petS
Se nn es
В сортировке всё самое интересное спрятано под капотом (мы ненадолго вернемся к этой теме чуть ниже, в разделе «Алгоритмы»), пока рассмотрим только Python-специфичный синтаксис.
Надо различать методы sort() и sorted(), первый сортирует данные in-place, второй порождает новую структуру.
a: list = [5, 2, 3, 1, 4]
b: list = sorted(a)
print(a, b)
a.sort()
print(a)[5, 2, 3, 1, 4] [1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
И sort(), и sorted() имеют параметр key для указания функции, которая будет вызываться на каждом элементе. Если вам больше по нраву сортировка при помощи функции, принимающей два аргумента (или вы привыкли к cmp в Python 2), присмотритесь к functools.cmp_to_key().
# Регистрозависимое сравнение строк
dinos: str = "Dinosaurs were Big and small"
a = sorted(dinos.split())
print(a)
# Регистронезависимое сравнение строк
dinos: str = "Dinosaurs were Big and small"
b = sorted(dinos.split(), key=str.lower)
print(b)['Big', 'Dinosaurs', 'and', 'small', 'were']
['and', 'Big', 'Dinosaurs', 'small', 'were']
Сложносочиненные структуры данных можно сортировать по key=lambda el: el[1] или даже, например по key=lambda el: (el[1], el[0]).
Comprehension, которое переводится то как списковое включение, то как абстракция списков (Википедия), то вообще никак не переводится — способ компактного описания операций обработки списков (а применительно к Python — еще и словарей, и множеств).
Проще говоря, если вам нужно получить из списка другой список, включающий только те значения, которые удовлетворяют какому-то определенному условию, или вычисляемые из первого списка по каким-то определенным правилам, то comprehension — претендент на решение этой задачи № 1.
# Примеры Comprehension
a = [i+1 for i in range(10)] # list
b = {i for i in range(10) if i > 5} # set
c = (2*i+5 for i in range(10)) # iter
d = {i: i**2 for i in range(10)} # dict
print(a,"\n", b, "\n", list(c), "\n", d)[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
{8, 9, 6, 7}
[5, 7, 9, 11, 13, 15, 17, 19, 21, 23]
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
Тут главное не перегнуть палку. Если запись comprehension становится слишком сложной и нечитаемой, возможно, стоит развернуть логику в «нормальный» цикл или в другой более удобочитаемый алгоритм. Comprehension соблазняет записывать «однострочникоми» достаточно сложные выражения, но не забывайте, что программист примерно 90 % времени читает код, и только 10 % пишет, так что если выражение будет плохочитаемым, вы усложните жизнь и себе, и свои коллегам.
Есть более-менее удачные «однострочники», есть быстрые, но плохочитаемые, написанные из спортивного интереса (это ссылки на решенные мной задачки на leetcode), желательно использовать comprehension в меру; лучше написать понятный развернутый алгоритм, чем непонятный, но обложенный пояснениями (если нет особых требований к производительности, само собой).
Еще немного про list comprehension:
# new_list = [expression for member in iterable (if conditional)]
fruits: list = ["Lemon", "Apple", "Banana", "Kiwi", "Watermelon", "Pear"]
e_fruits = [fruit for fruit in fruits if "e" in fruit]
# ☝ условие
print(e_fruits)
upper_fruits = [fruit.upper() for fruit in fruits]
# ☝ выражение
print(upper_fruits)
# Пример разбиения списка на фрагменты одинаковой длины
chunk_len = 2
chunk_fruits = [fruits[i:i + chunk_len] for i in range(0, len(fruits), chunk_len)]
print(chunk_fruits)['Lemon', 'Apple', 'Watermelon', 'Pear']
['LEMON', 'APPLE', 'BANANA', 'KIWI', 'WATERMELON', 'PEAR']
[['Lemon', 'Apple'], ['Banana', 'Kiwi'], ['Watermelon', 'Pear']]
Dict comprehension:
# new_dict = {expression for member in iterable (if conditional)}
d: dict = {"Italy": "Pizza", "US": "Hot-Dog", "China": "Dim Sum", "South Korea": "Kimchi"}
print(d)
a: dict = {k: v for k, v in d.items() if "i" in v} # Вернет новый словарь, отфильтрованный по значению
print(a)
b: dict = {k: v for k, v in d.items() if "i" in k} # Вернет новый словарь, отфильтрованный по ключу
print(b)
c: dict = {k: v for k, v in d.items() if len(v) >= 7} # Вернет новый словарь, отфильтрованный по длине значений
print(c){'Italy': 'Pizza', 'US': 'Hot-Dog', 'China': 'Dim Sum', 'South Korea': 'Kimchi'}
{'Italy': 'Pizza', 'China': 'Dim Sum', 'South Korea': 'Kimchi'}
{'China': 'Dim Sum'}
{'US': 'Hot-Dog', 'China': 'Dim Sum'}
Попробуйте самостоятельно поиграться с set comprehension. Не забывайте, что set «переваривает» только уникальные значения, поэтому в результате вы можете получить не совсем то, на что рассчитывали.
Попробуйте также освоить nested (вложенный) comprehension, используя конструкции вида [[func(y) for y in x] for x in n]. Для примера создайте двумерный массив, содержащий случайные значения, среднее значение которых плавно нарастает ближе к правому нижнему углу (если не получится, готовый пример есть чуть ниже, в коде, иллюстрирующем применение matplotlib).
s: str = "camelCase string"
print(s.lower())
print(s.upper())
print(s.capitalize())
print(s.title())camelcase string
CAMELCASE STRING
Camelcase string
Camelcase String
s: str = " ~~##A big blahblahblah##~~ "
s = s.strip() # Strips all whitespace characters from both ends
print(s)
s = s.strip("~#") # Strips all passed characters from both ends
print(s)
s = s.lstrip(" A") # Strips all passed characters from left end
print(s)
s = s.rstrip("habl") # Strips all passed characters from right end
print(s)~~##A big blahblahblah##~~
A big blahblahblah
big blahblahblah
big
s1: str = "Follow the white rabbit, Neo"
c1 = s1.split() # Splits on one or more whitespace characters
print(c1)
c2 = s1.split(sep=", ", maxsplit=1) # Splits on "sep" str at most "maxsplit" times
print(c2)
s2: str = "Beware the Jabberwock, my son!\n The jaws that bite, the claws that catch!"
c3 = s2.splitlines(keepends=False) # On [\n\r\f\v\x1c-\x1e\x85\u2028\u2029] and \r\n.
print(c3)
# split() vs rsplit()
c4 = s2.split(maxsplit=2)
c5 = s2.rsplit(maxsplit=2)
print(c4, c5)['Follow', 'the', 'white', 'rabbit,', 'Neo']
['Follow the white rabbit', 'Neo']
['Beware the Jabberwock, my son!', ' The jaws that bite, the claws that catch!']
['Beware', 'the', 'Jabberwock, my son!\n The jaws that bite, the claws that catch!'] ['Beware the Jabberwock, my son!\n The jaws that bite, the claws', 'that', 'catch!']
s1: str = "abcABC!"
for ch in s1:
print(f"{ch} -> {ord(ch)}") # Returns an integer representing the Unicode character
nums = [72, 101, 108, 108, 111, 33]
for num in nums:
print(f"{num} -> {chr(num)}")a -> 97
b -> 98
c -> 99
A -> 65
B -> 66
C -> 67
! -> 33
72 -> H
101 -> e
108 -> l
108 -> l
111 -> o
33 -> !
Регулярные выражения — отдельная область знаний, и весьма-весьма непростая область. Тут, пожалуй, самое время для бородатой шутки про то, что «если вы решили свою проблему при помощи регулярных выражений — теперь у вас две проблемы».
Регулярки похожи на вхождение в воду на пляже острова Гуам в сторону Марианской впадины — даже когда вы думаете, что погрузились реально глубоко, то, скорее всего, вы просто не видите впередилежащей бездны. Но — знать регулярные выражения, хотя бы на начальном уровне, необходимо для решения целого класса задач, а то, что вёрткие регулярки периодически поворачиваются к вам своими, кхм... новыми гранями, придется простить, переварить и принять.
Вот здесь есть грамотное и методически выдержанное введение в тему, пока же посмотрим на основные возможности регулярных выражений.
import re
s1: str = "123 abc ABC 456"
m1 = re.search("[aA]", s1) # Ищет первое вхождение паттерна, при неудаче возвращает None
print(m1, m1.group(0))
m2 = re.fullmatch("[aA]", s1) # Проверка, подходит ли строка под шаблон
print(m2)
c1: list = re.findall("[aA]", s1) # Найти в строке все непересекающиеся шаблоны
print(c1)
def replacer(s):
return chr(ord(s[0]) + 1) # Следующий символ из алфавита
s2 = re.sub("\w", replacer, s1) # Вы можете использовать функцию вместо шаблона
print(s2)
c2 = re.split("\d", s1)
print(c2)
iter = re.finditer("\D", s1) # Итератор по непересекающимся шаблонам
for ch in iter:
print(ch.group(0), end= "")<re.Match object; span=(4, 5), match='a'> a
None
['a', 'A']
234 bcd BCD 567
['', '', '', ' abc ABC ', '', '', '']
abc ABC
import re
m3 = re.match(r"(\w+) (\w+)", "John Connor, leader of the Resistance")
s3: str = m3.group(0) # Возвращает полное совпадение
s4: str = m3.group(1) # Возвращает часть в первых скобках
t1: tuple = m3.groups()
start: int = m3.start() # Возвращает начальный индекс совпадения
end: int = m3.end() # Возвращает конечный индекс совпадения
t2: tuple[int, int] = m3.span() # Кортеж (start, end)
print (f"{s3}\n {s4}\n {t1}\n {start}\n {end}\n {t2}\n")John Connor
John
('John', 'Connor')
0
11
(0, 11)
Python использует Unix Epoch: "1970-01-01 00:00 UTC"
from datetime import datetime
from dateutil.tz import tzlocal
dt1: datetime = datetime.fromisoformat("2021-10-04 00:05:23.555+00:00") # Может вызвать ValueError
dt2: datetime = datetime.strptime("21/10/04 17:30", "%d/%m/%y %H:%M") # Подробнее про форматы - https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes
dt3: datetime = datetime.fromordinal(100_000) # 100000-й день от 1.1.0001
dt4: datetime = datetime.fromtimestamp(20_000_000.01) # Время в секундах с начала Unix Epoch
tz = tzlocal()
dt5: datetime = datetime.fromtimestamp(20_000_000.01, tz) # С учетом часового пояса
print (f"{dt1}\n {dt2}\n {dt3}\n {dt4}\n {dt5}")2021-10-04 00:05:23.555000+00:00
2004-10-21 17:30:00
0274-10-16 00:00:00
1970-08-20 16:33:20.010000
1970-08-20 16:33:20.010000+05:00
from datetime import datetime
dt1: datetime = datetime.today()
s1: str = dt1.isoformat()
s2: str = dt1.strftime("%d/%m/%y %H:%M") # https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes
i: int = dt1.toordinal()
a: float = dt1.timestamp() # Секунды с начала Unix Epoch
print (f"{dt1}\n {s1}\n {s2}\n {i}\n {a}")2022-09-06 17:50:38.041159
2022-09-06T17:50:38.041159
06/09/22 17:50
738404
1662468638.041159
from datetime import date, time, datetime, timedelta
from dateutil.tz import UTC, tzlocal, gettz, datetime_exists, resolve_imaginary
d: date = date.today()
dt1: datetime = datetime.today()
dt2: datetime = datetime(year=1981, month=12, day=2)
td1: timedelta = timedelta(days=5)
td2: timedelta = timedelta(days=1)
d = d + td1 # date = date ± timedelta
dt3 = dt1 - td1 # datetime = datetime ± timedelta
td3 = dt1 - dt2 # timedelta = datetime - datetime
td4 = 10 * td1 # timedelta = const * timedelta
c: float = td1/td2 # timedelta/timedelta
print (f"{d}\n {dt3}\n {td3}\n {td4}\n {c}")2022-09-11
2022-09-01 17:50:38.132916
14888 days, 17:50:38.132916
50 days, 0:00:00
5.0
Бинарный поиск существенно быстрее, чем обычный (см. раздел «Алгоритмы»), но требует предварительной сортировки коллекции, по которой осуществляется поиск.
import bisect
a: list[int] = [12, 6, 8, 19, 1, 33]
a.sort()
print(f"Sorted: {a}")
print(bisect.bisect(a, 20)) # Найти индекс для потенциальной вставки
bisect.insort(a, 15) # Вставка значения в отсортированную последовательность
print(a)
# Бинарный поиск
def binary_search(a, x, lo=0, hi=None):
if hi is None:
hi = len(a)
pos = bisect.bisect_left(a, x, lo, hi)
return pos if pos != hi and a[pos] == x else -1
print(binary_search(a, 15))Sorted: [1, 6, 8, 12, 19, 33]
5
[1, 6, 8, 12, 15, 19, 33]
4
На случай, если начиная с этого момента и до конца текущего жизненного цикла вы собираетесь к месту и не месту использовать приёмы функционального программирования, чтобы сделать свой код «воистину крутым», просто процитирую вам Джоэля Граса, автора книги «Data Science: Наука о данных с нуля»: «В первом издании этой книги были представлены функции partial, map, reduce и filter языка Python. На своем пути к просветлению я понял, что этих функций лучше избегать, и их использование в книге было заменено включениями в список, циклами и другими, более Python'овскими конструкциями». Такие дела...
import functools
# Преобразует все входящие значения при помощи указанной функции
iter1 = map(lambda x: x + 1, range(10))
print(list(iter1))
# Передает в выходной итератор только значения, удовлетворяющие условию
iter2 = filter(lambda x: x > 5, range(10))
print(list(iter2))
# Применяет указанную функцию ко всей последовательности входных данных, сводя их к единственному значению
a = functools.reduce(lambda out, x: out + x, range(10))
print(a)[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[6, 7, 8, 9]
45
import functools
def sum(a,b):
return a + b
add_const = functools.partial(sum, 10)
print(add_const(5))15
Если вам не сразу станет понятно, как работает функция partial (и зачем она нужна), не расстраивайтесь, вы не одиноки :). Вот, пожалуйста, тема на Stackoverflow: «I am not able to get my head on how the partial works». Там, кстати, есть совет, как partial могут быть полезны при организации pipe с включением функций, имеющих разное количество аргументов.
any() вернет True, если хотя бы один элемент итерируемой коллекции истинен, all() вернет True только в случае истинности всех элементов коллекции.
animals = ["Squirrel", "Beaver", "Fox"]
sentence = "Bison likes squirrels and beavers"
any_animal: bool = any(animal.lower() in sentence.lower() for animal in animals)
print(any_animal)
all_animal: bool = all(animal.lower() in sentence.lower() for animal in animals)
print(all_animal)True
False
Файловые операции стоят немного особняком от остальных методов обработки данных, так как подразумевают взаимодействие с неким постоянным энергонезависимым хранилищем данных. Так что если вам нужно сохранить данные на завтра, или, наоборот, нужно прочитать данные, которые вам предоставили неделю назад, то вам, очевидно, нужно будет работать с файлами. В файлах же осядет информация, которую мы передаем базам данных, но эту тему мы рассмотри ниже.
f = open("f.txt", mode='r', encoding="utf-8", newline=None)
print(f.read())Hello from file!
На всякий случай, если вы испытываете программистский зуд даже небольшой степени выраженности, напоминаю — эта статья в оригинале написана в Jupiter Notebook, все примеры кода интерактивны, не надо на них смотреть, их надо видоизменять, корректировать, дорабатывать.
Особенно это важно, если вам в приведенных сниппетах что-то непонятно. Обязательно запустите этот код в IDE, погоняйте пошаговый отладчик; только когда концы свяжутся, только когда вы поймете, как функционирует этот кусочек кода, только тогда промелькнёт маленькая искорка и ваша квалификация как программиста немного подрастёт.
Исходный код скачивается отсюда, VS Code лежит здесь.
Режимы (mode):
"r" — чтение (поведение по умолчанию)
"w" — запись (информация, ранее присутствующая в файле, будет стёрта)
"x" — эксклюзивное создание и запись; если файл уже существует, будет выброшено исключение FileExistsError
"a" — открытие с последующим добавлением в конец файла
"w+" — чтение и запись
"r+" — чтение и запись с начала файла
"a+" — чтение и запись с конца файла
"t" — текстовый режим ("rt", "wt" и т. д.; поведение по умолчанию)
"b" — двоичный режим ("rb", "wb", "xb" и т. д.)
encoding=None — будет использована кодировка по умолчанию (зависит от системы). Если нет специальных требований, просто используйте везде encoding="utf-8".
newline=None — при чтении системные символы конца строки будут конвертированы в "\n"; при записи, наоборот, "\n" будут конвертированы в системные символы конца строки.
Возможные исключения при работе с файлами:
FileNotFoundError при чтении в режиме "r" или "r+".
FileExistsError при записи в режиме "x".
IsADirectoryError, PermissionError — в любом режиме.
Открывает файл и возвращает файловый объект.
Для работы с файлами лучше использовать менеджеры контекста (рассмотрены ниже), т. е. конструкции вида "with open...". Даже если что-то пойдет не так, как задумано (например, вы не обработаете исключение во время работы с файлом), менеджер контекста «зачистит хвосты», и ваша оплошность не отразится, например, на файловой системе.
with open("f.txt", encoding="utf-8") as f:
chars = f.read(5) # Reads chars/bytes or until EOF
print(chars)
f.seek(0) # Moves to the start of the file. Also seek(offset) and seek(±offset, anchor), where anchor is 0 for start, 1 for current position and 2 for end
lines: list[str] = f.readlines() # Also readline()
print(lines)Hello
['Hello from file!']
with open("f.txt", "w", encoding="utf-8") as f:
f.write("Hello from file!") # Или f.writelines(<collection>)Человекочитаемый формат для хранения и передачи данных.
import json
d: dict = {1: "Lemon", 2: "Apple", 3: "Banana!"}
object_as_string: str = json.dumps(d, indent=2)
print(object_as_string)
restored_object = json.loads(object_as_string)
# Write object to JSON file
with open("1.json", 'w', encoding='utf-8') as file:
json.dump(d, file, indent=2)
# Read object from JSON file
with open("1.json", encoding='utf-8') as file:
restored_from_file = json.load(file)
print(restored_from_file){
"1": "Lemon",
"2": "Apple",
"3": "Banana!"
}
{'1': 'Lemon', '2': 'Apple', '3': 'Banana!'}
Бинарный формат для хранения и передачи данных.
import pickle
d: dict = {1: "Lemon", 2: "Apple", 3: "Banana!"}
# Запись объекта в бинарный файл
with open("1.bin", "wb") as file:
pickle.dump(d, file)
# Чтение объекта из файла
with open("1.bin", "rb") as file:
restored_from_file = pickle.load(file)
print(restored_from_file){1: 'Lemon', 2: 'Apple', 3: 'Banana!'}
Если вы хотите передавать и хранить данные, используя универсальную структуру, одинаково хорошо понимаемую всеми языками программирования (как JSON) и занимающую мало места (как Pickle), то можно посмотреть в сторону Protocol Buffers (Wikipedia, примеры для Python). Есть еще альтернативы, например, FlatBuffers, Apache Avro или Thrift.
При работе с файлами не обойтись без манипулирования файловыми путями.
from os import getcwd, path, listdir
from pathlib import Path
s1: str = getcwd() # Возвращает текущую рабочую директорию
print(s1)
s2: str = path.abspath("f.txt") # Возвращает полный путь
print(s2)
s3: str = path.basename(s2) # Возвращает имя файла
s4: str = path.dirname(s2) # Возвращает путь без файла
t1: tuple = path.splitext(s2) # Возвращает кортеж из пути и имени файла
print(s3, s4, t1)
p = Path(s2)
st = p.stat()
print(st)
b1: bool = p.exists()
b2: bool = p.is_file()
b3: bool = p.is_dir()
print(b1, b2, b3)
c: list = listdir(path=s1) # Возвращает список имен файлов, находящихся по указанному пути
print(c)
s5: str = p.stem # Возвращает имя файла без расширения
s6: str = p.suffix # Возвращает расширение файла
t2: tuple = p.parts # Возвращает все элементы пути как отдельные строки
print(s5, s6, t2)c:\Works\amaargiru\pycore
c:\Works\amaargiru\pycore\f.txt
f.txt c:\Works\amaargiru\pycore ('c:\\Works\\amaargiru\\pycore\\f', '.txt')
os.stat_result(st_mode=33206, st_ino=2251799814917120, st_dev=3628794147, st_nlink=1, st_uid=0, st_gid=0, st_size=16, st_atime=1662468638, st_mtime=1662468638, st_ctime=1661089564)
True True False
['.git', '.gitignore', '.pytest_cache', '01_python.ipynb', '01_python.md', '02_postgre.md', '03_architecture.md', '04_algorithms.ipynb', '04_algorithms.md', '05_admin_devops.md', '06_pytest_mock.ipynb', '06_pytest_mock.md', '07_fastapi.md', '08_flask.md', '1.bin', '1.json', 'compose_readme.bat', 'coupling_vs_cohesion.svg', 'f.txt', 'gitflow.svg', 'graph_for_dfs.jpg', 'pycallgraph3.png', 'readme.md']
f .txt ('c:\\', 'Works', 'amaargiru', 'pycore', 'f.txt')
a: list[int] = [1, 2, 3, 4, 5, 2, 2]
s = sum(a)
print(s)
c = a.count(2) # Вернет количество вхождений
print(c)
mn = min(a)
print(mn)
mx = max(a)
print(mx)19
3
1
5
Присмотритесь к встроенным функциям, там есть еще кое-что, касающееся элементарной математики.
from math import pi
a: float = pi ** 2 # Or pow(pi, 2)
print(f"Power: {a}")
b: float = round(pi, 2)
print(f"Round: {b}")
c: int = round(256, -2)
print(f"Int round: {c}")
d: float = abs(-pi)
print(f"Abs: {d}")
e: float = abs(10+10j) # Or e: float = abs(complex(real=10, imag=10))
print(f"Complex abs: {e}")Power: 9.869604401089358
Round: 3.14
Int round: 300
Abs: 3.141592653589793
Complex abs: 14.142135623730951
a: int = 0b01010101
b: int = 0b10101010
print(f"And: 0b{a&b:08b}")
print(f"Or: 0b{a|b:08b}")
print(f"Xor: 0b{a^b:08b}")
print(f"Left shift: 0b{a << 4:08b}")
print(f"Right shift: 0b{b >> 4:08b}")
print(f"Not: 0b{~a:08b}")And: 0b00000000
Or: 0b11111111
Xor: 0b11111111
Left shift: 0b10101010000
Right shift: 0b00001010
Not: 0b-1010110
a: int = 4242
print(f"{a} in binary format: 0b{a:b}")
c = a.bit_count() # Returns the number of ones in the binary representation of the absolute value of the integer
print(f"Bit count: {c}")4242 in binary format: 0b1000010010010
Bit count: 4
from fractions import Fraction
f = Fraction("0.2").as_integer_ratio()
print(f)(1, 5)
import math
p1 = (0.22, 1, 12)
p2 = (-0.12, 3, 7)
print(math.dist(p1, p2))5.39588732276722
Мини-язык для манипулирования массивами. На удачных сценариях работает в сотни раз быстрее встроенных функций. Еще более быстрая альтернатива работает на GPU, называется CuPy и опять-таки обещает стократный прирост производительности, только уже по сравнению с NumPy. Так что если вам нужен какой-нибудь быстрый FFT или еще какой числогрыз, то вы знаете, что делать. Если вы дружите с английским, то изучайте официальный мануал, если нет — на «Хабре» есть перевод (как всегда, читайте комментарии, там немало полезного).
Небольшое отступление.
Во-первых, тут мы переходим границу между встроенной функциональность языка и внешними библиотеками. Надо понимать, что успех Python во многом основан именно на богатстве его экосистемы (хотя, впрочем, тоже самое можно сказать и про JavaScript, и про C#); сам язык предоставляет богатую, но всё же ограниченную функциональность, в то время как функционал внешних библиотек практически безграничен, это как бесконечно разнообразные кубики Лего. Соответственно, очень часто для решения задачи не нужно реализовывать алгоритм с нуля, на чистом Python'е, достаточно подобрать нужную библиотеку.
Во-вторых, популярность разных библиотек Python (в том числе и конкурирующих) сильно разнится. Например, NumPy — очень популярная библиотека, но в мире существуют буквально миллионы Python-разработчиков, которые никогда не работали с NumPy, просто в силу своего круга функциональных обязанностей.
Для начинающего разработчика это представляет собой довольно нешуточную проблему — как конкретно двигаться вперед, какие библиотеки изучать, ведь знания чистого Python, как правило, недостаточно для формирования актуального резюме.
Дам вам небольшой совет. Ежегодно компания JetBrains (делающая среди прочего очень классную IDE PyCharm) проводит всемирный опрос Python-разработчиков, а потом выкладывает полученные результаты в виде так называемого Python Developers Survey Results. Например, если вы почитаете результаты последнего исследования, то найдете там довольно чёткие ориентиры: например, в разделе «Data science frameworks and libraries» в топе находятся NumPy, Pandas (рассмотрен ниже) и Matplotlib, в тестировании с большим отрывом лидирует pytest (смотри ниже), в других областях вперед вырываются Flask (Django на втором месте с крошечным отрывом), SQLAlchemy (vs Django ORM) и PostgreSQL (vs SQLite), про них мы тоже еще поговорим. Так что в целом, общее направление развития определить можно.
Однако, вернемся к NumPy. Не забывайте, что в основе NumPy лежат массивы, а все данные в массиве должны быть одинакового типа (просто на случай, если вы уже познали пр-р-рел-л-лесть списков Python). Создание массивов:
import numpy as np
a1 = np.array([1, 2, 3, 4, 5], float) # Получение массива из списка
print(a1[0:2])
a2 = np.zeros(5) # Массив, заполненный нулями
print(a2)
a3 = np.arange(0, 6, 1) # Использование диапазона, np.arange(from_inclusive, to_exclusive, step_size)
print(a3)
a4 = np.random.randint(6, size=10) # Создание массива, содержащего случайные значения, np.random.randint(low_inclusive, high_exclusive=None, size=None, dtype=int)
print(a4)
a5 = np.random.randint(6, size=(2, 5)) # Создание многомерного массива, содержащего случайные значения
print(a5)
print(a5.shape) # Число строк и столбцов в массиве
print(a5.dtype) # Тип переменных
print(1 in a5) # Проверка наличия элемента[1. 2.]
[0. 0. 0. 0. 0.]
[0 1 2 3 4 5]
[2 2 4 0 0 0 0 4 0 5]
[[1 0 3 5 0]
[3 1 4 2 2]]
(2, 5)
int32
True
Базовые математические операции (полный список):
import numpy as np
a1 = np.array([1, 2, 3, 4, 5])
a2 = np.array([6, 7, 8, 9, 10])
a3 = a1 + 1
print(a3)
a4 = a1 + a2
print(a4)
a5 = a1 ** 3
print(a5)
a6 = a1 ** a2
print(a6)[2 3 4 5 6]
[ 7 9 11 13 15]
[ 1 8 27 64 125]
[ 1 128 6561 262144 9765625]
Вообще, можно сказать, что быстрые математические операции над многомерными массивами — это главная «фишка» NumPy. Вы просто говорите: возьми такие-то массивы и проделай над ними такую-то операция. Далее все эти данные «проваливаются» в высокоскоростное ядро NumPy, где к ним уже можно применить всю мощь вашего процессора, которая раньше была вам недоступна (ну, или доступна не полностью) из-за Python-интерпретатора. Так что, если вы пытаетесь в цикле итерировать массив NumPy, по факту передавая данные на нижний уровень небольшими порциями (например, объектами row), то имейте ввиду, что тем самым используете возможности NumPy недостаточно эффективно; попробуйте решить задачу без итерирования.
Sum, Min, Max
import numpy as np
a1 = np.random.randint(6, size=(2, 10)) # NumPy поддерживает несколько десятков видов распределений, например, Пуассона и Стьюдента
print(a1)
s = np.sum(a1) # Сумма всех элементов
print(s)
mn = a1.min(axis=0) # Наименьшие числа в каждом столбце
print(mn)
mx = a1.max(axis=1) # Наибольшие числа в каждой строке
print(mx)
amin = a1.argmin(axis=0) # Индексы минимальных элементов в каждом столбце
print(amin)
amax = a1.argmax(axis=1) # Индексы максимальных элементов в каждой строке
print(amax)
uniq = np.unique(a1) # Извлечение уникальных элементов
print(uniq)[[3 0 4 1 0 5 4 0 1 3]
[0 3 4 0 0 1 4 0 5 4]]
42
[0 0 4 0 0 1 4 0 1 3]
[5 5]
[1 0 0 1 0 1 0 0 0 0]
[5 8]
[0 1 3 4 5]
В качестве домашнего задания попробуйте самостоятельно применить prod(), mean(), var(), std(), median(), cov() и corrcoef().
Форматирование массивов:
import numpy as np
a = np.random.randint(6, size=(3, 5))
print(a)
a1 = a.reshape((5, 3)) # Форматирование. Если есть возможность, создается новый view на те же самые данные
print(a1)
a.shape = (5, 3) # Форматирование in-place
print(a)
print(a.shape)
a = a[:, :, np.newaxis] # Увеличение размерности массива с 2 до 3
print(a)
print(a.shape)
a = a.flatten() # Конвертация в одномерный массив
print(a)
print(a.shape)[[5 5 5 1 1]
[0 2 0 5 5]
[0 2 5 4 5]]
[[5 5 5]
[1 1 0]
[2 0 5]
[5 0 2]
[5 4 5]]
[[5 5 5]
[1 1 0]
[2 0 5]
[5 0 2]
[5 4 5]]
(5, 3)
[[[5]
[5]
[5]]
[[1]
[1]
[0]]
[[2]
[0]
[5]]
[[5]
[0]
[2]]
[[5]
[4]
[5]]]
(5, 3, 1)
[5 5 5 1 1 0 2 0 5 5 0 2 5 4 5]
(15,)
Копирование массивов:
import numpy as np
import copy
a = np.random.randint(10, size=(4, 4))
print(a)
# Неглубокая (shallow) копия
a1 = np.copy(a)
# Глубокая (deep) копия
a2 = copy.deepcopy(a)
# Копирование ссылки
a3 = a
a[0, 0] = 10
print(a[0, 0] == a1[0, 0])
print(a[0, 0] == a2[0, 0])
print(a[0, 0] == a3[0, 0])[[5 3 1 4]
[0 8 7 0]
[1 7 4 7]
[5 3 5 2]]
False
False
True
NumPy очень мощный инструмент, не зря же он стоит на первом месте в списке «Data science frameworks and libraries» обзора, который мы упоминали чуть выше. Но углубляться в эту тему очень уж глубоко в рамках поверхностного обзора, пожалуй, не стоит; вряд ли прямо сейчас вам кровь из носу нужно освоить скалярное, тензорное и внешнее произведение матриц или познать (вспомнить?) специфику линейной алгебры. Думаю, даже если мы сейчас начнем описывать транспонирование или выбор оси, по которой будет произведена конкатенация массивов, то это уже будет, что называется, «не в коня корм».
К тому же, изучая тонкости употребления NumPy, начинает появляться соблазн упоминания SciPy, предоставляющего еще более широкий функционал, а после первого "import scipy" у нас начнется уже полное непотребство. Давайте пока пройдем мимо этой кроличьей норы, для первого знакомства она слишком глубока.
Единственное, что еще можно освоить в конце ознакомительного курса NumPy — взаимодействие с внешним миром. Изучите для начала load/save/savez (бинарники) и loadtxt/savetxt (человекочитаемый формат).
Библиотека обработки и анализа данных. Работа с данными строится поверх библиотеки NumPy.
В первом, грубом приближении pandas можно воспринимать как связку Excel + VisualBasic-скрипты, только более гибкую и удобную. Библиотека создает своеобразный мостик между профессиями Python-программиста, дата-сайентиста и аналитика, позволяя сосредоточиться в большей степени именно на очистке и анализе данных, на читабельности отчетов, а не на программировании. Pandas также поддерживает широкий спектр «красивостей» при выводе информации, позволяя, например, добавлять в выводимые данные градиентную подсветку (heatmap) или визуализировать отклонение от среднего (bar chart).
Для того, чтобы как следует «распробовать» pandas, по-хорошему надо загрузить какой-нибудь развесистый набор данных, но мы, пожалуй, не будем погружаться в глубины глубин, просто поиграем небольшим самодельным датасетом.
import pandas as pd
s = pd.Series([0, 1, 4, 7, 8, 10, 12])
print(s)
print(s[2])0 0
1 1
2 4
3 7
4 8
5 10
6 12
dtype: int64
4
Series — базовая структура данных pandas. Вы можете воспринимать её как упорядоченный словарь или как строку Excel, смотря по тому, какая аналогия вам ближе.
import pandas as pd
s = pd.Series([0, 1, 4, 7, 8, 10, 12], index=["a", "b", "c", "d", "x", "y", "z"]) # Индексы Series можно задавать вручную
print(s)
print(s["x"])
print(s[["x", "y", "z"]]) # Выборка
print(s[s > 5]) # Фильтрация
print(s.max()) # Математика, примерно как в NumPy
print(s.sum())a 0
b 1
c 4
d 7
x 8
y 10
z 12
dtype: int64
8
x 8
y 10
z 12
dtype: int64
d 7
x 8
y 10
z 12
dtype: int64
12
42
При объединении нескольких Series получается DataFrame, вторая базовая структура данных pandas, которую в первом приближении можно рассматривать как лист Excel.
import pandas as pd
from pandas import DataFrame
s1 = pd.Series([0, 1, 4, 7, 8, 10, 12])
s2 = pd.Series([0, 100, 200, 300, 600, 900, 1200])
df = pd.DataFrame([s1, s2])
print(df)
print(df[1])
print(df[2][0])
print(df.iloc[0][2:4]) 0 1 2 3 4 5 6
0 0 1 4 7 8 10 12
1 0 100 200 300 600 900 1200
0 1
1 100
Name: 1, dtype: int64
4
2 4
3 7
Name: 0, dtype: int64
Давайте сделаем что-то более похожее на реальный анализ данных. При помощи формулы ИМТ выясним, кто из знаменитостей не следит за собой и обзавелся лишним весом:
from pandas import DataFrame
import matplotlib.pyplot as plt
def bmi(row):
return row["weight"] / row["height"] ** 2
if __name__ == '__main__':
celebs: dict = {"Britney Spears": {"height": 1.63, "weight": 57},
"Melanie Griffith": {"height": 1.73, "weight": 63},
"Kylie Minogue": {"height": 1.52, "weight": 46},
"Hulk Hogan": {"height": 1.98, "weight": 137}}
df = DataFrame(celebs) # Создаем DataFrame
df.loc["bmi"] = df.apply(lambda row: bmi(row), axis=0) # Добавлем новую строку с ИМТ
df = df.sort_values(by="bmi", ascending=True, axis=1) # Сортируем
print(df)
df.loc["bmi"].plot.bar() # Визуализация
plt.show() Kylie Minogue Melanie Griffith Britney Spears Hulk Hogan
height 1.520000 1.730000 1.630000 1.980000
weight 46.000000 63.000000 57.000000 137.000000
bmi 19.909972 21.049818 21.453574 34.945414

На самом деле Халк, конечно, не толстый, а профессиональный спортсмен, к которым формула ИМТ малоприменима, но крошка Кайли действительно вырывается вперед, даже с учетом своего небольшого роста.
Библиотеку визуализации matplotlib мы уже слегка задействовали в примере выше. Прямо здесь и прямо сейчас глубоко погружаться в разбор возможностей matplotlib/seaborn, наверное, смысла особого не имеет; все вы видели примеры иллюстраций в научной и бизнес-литературе и, разумеется, все эти графики и иллюстрации можно повторить при помощи рассматриваемых библиотек.
Давайте просто для затравки нарисуем пару симпатичных визуализаций, чтобы наглядно показать полезность качественного оформления результатов проделанной работы.
Тепловая карта (heatmap), наглядно показывающая достижения отдельных членов команды:
from random import randrange
import numpy as np
import matplotlib.pyplot as plt
import uuid
targets = ["authorities", "humans", "parrots", "cars", "motorcycles", "buildings", "warehouses"]
robots = ["Terminator #" + str(uuid.uuid4())[:5] for _ in range(7)]
harvest = np.array([[randrange(i * j) for i in range(10, 80, 10)] for j in range(1, 8)])
fig, ax = plt.subplots()
im = ax.imshow(harvest)
ax.set_xticks(np.arange(len(robots)), labels=robots)
ax.set_yticks(np.arange(len(targets)), labels=targets)
plt.setp(ax.get_xticklabels(), rotation=60, ha="right", rotation_mode="anchor")
for i in range(len(targets)):
for j in range(len(robots)):
text = ax.text(j, i, harvest[i, j], ha="center", va="center", color="w")
ax.set_title("Targets destroyed")
fig.tight_layout()
plt.rcParams['figure.figsize'] = [4, 4]
plt.rcParams['figure.dpi'] = 200
plt.show()
Аналогичная тепловая карта, визуализированная при помощи seaborn:
from random import randrange
import numpy as np
import matplotlib.pyplot as plt
import uuid
import seaborn as sns
sns.set_theme()
targets = ["authorities", "humans", "parrots", "cars", "motorcycles", "buildings", "warehouses"]
robots = ["Terminator #" + str(uuid.uuid4())[:5] for _ in range(7)]
harvest = np.array([[randrange(i * j) for i in range(10, 80, 10)] for j in range(1, 8)])
fig, ax = plt.subplots()
im = ax.imshow(harvest)
ax.set_title("Targets destroyed")
plt.rcParams['figure.figsize'] = [4, 4]
sns.heatmap(harvest, annot=True, fmt="d", linewidths=.5, ax=ax, xticklabels=robots, yticklabels=targets)
plt.setp(ax.get_xticklabels(), rotation=60, ha="right", rotation_mode="anchor")
plt.xticks(rotation=60)
plt.show()
А вот так будет выглядеть «Доска почёта» при отрисовке в 3D:
import uuid
from random import randrange
import matplotlib.cm as cm
import matplotlib.colors as colors
import matplotlib.pyplot as plt
import numpy as np
targets = ["authorities", "humans", "parrots", "cars", "motorcycles", "buildings", "warehouses"]
robots = ["Terminator #" + str(uuid.uuid4())[:5] for _ in range(7)]
harvest = np.array([[randrange(i * j) for i in range(10, 80, 10)] for j in range(1, 8)])
fig = plt.figure(figsize=(5, 5))
ax = fig.add_subplot(projection='3d')
ax.set_xticks(np.arange(len(robots)), labels=robots)
ax.set_yticks(np.arange(len(targets)), labels=targets)
plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor")
plt.setp(ax.get_yticklabels(), ha="left", rotation_mode="anchor")
ax.set_title("Our team")
xx, yy = np.meshgrid(range(len(targets)), range(len(robots)))
x1d, y1d = xx.ravel(), yy.ravel()
harvest1d = harvest.ravel()
# Setup color scheme
offset = harvest1d + np.abs(harvest1d.min())
fracs = offset.astype(float) / offset.max()
norm = colors.Normalize(fracs.min(), fracs.max())
colors = cm.jet(norm(fracs))
ax.bar3d(x1d, y1d, np.zeros_like(x1d + y1d), 0.7, 0.7, harvest1d, color=colors)
plt.show()
Углубиться достаточно глубоко в тему глубокого обучения в рамках нашего несколько поверхностного формата, конечно, не получится (каким-нибудь «Введением в Deep Learning» вполне можно нанести себе существенные травмы, если неудачно уронить со стола), так что скользнём буквально по верхушкам, рассмотрев основные понятия.
Глубинная нейронная сеть (deep neural network) — это, формально выражаясь, многослойная искусственная нейронная сеть, использующая алгоритмы машинного обучения для моделирования высокоуровневых абстракций с применением нелинейных преобразований. В ходу есть еще такие термины, как «поверхностное машинное обучение», «слабый ИИ», «сильный ИИ»; существует классификация понятий «глубокое обучение», «машинное обучение» и «искусственный интеллект» (вот, например, вариант от Microsoft, такую же структуру-матрёшку демонстрирует Франсуа Шолле в своей книге «Глубокое обучение на Python»), но сейчас, по крайней мере при неформальном общении, всё чаще ставится знак равенства между «машинным обучением» и «искусственным интеллектом»; причём в работе, как правило, используется «машинное обучение», а при подготовке презентаций — «искусственный интеллект» :) Дело, по всей видимости, в том, что глубокое обучение стало самой многообещающей и динамично развивающейся областью машинного обучения, а искусственным интеллектом уже давно именовали всю эту область знаний как популяризаторы науки, так и журналисты.
В общем, при первоначальном знакомстве с TensorFlow или PyTorch можете смело всем говорить, что занимаетесь AI, а если захотите углубиться — уж терминологией-то овладеете.
Что касается сути работы нейронных сетей, то здесь можно выделить следующие основные понятия:
Датасет — маркированные данные, используемые для обучения сети и для последующей проверки качества этого обучения. Вариант простого датасета — коллекция изображений одинакового размера с рукописными цифрами и буквами, где про каждое изображение точно известно, какай именно символ в нём содержится; такой датасет нужен для разработки систем распознавания рукописного текста (handwritten text recognition, HTR). Создание качественных датасетов — большая, тяжелая работа, поэтому сейчас идет активная работа по созданию моделей, способных работать с большими объёмами немаркированных данных. Как правило, датасет разбивается на две части — для обучения сети и для проверки качества проведенного обучения.
Искусственная нейронная сеть — программный или аппаратный аналог биологической нейронной сети; в самом простом варианте, в сети прямого распространения, это последовательно соединенные слои нейронов. Первые реализации нейронных сетей получили практическое воплощение еще в 60-х годах XX века, хотя существенный прогресс и практическое внедрение приходятся примерно на последние лет пятнадцать.
Архитектура искусственной нейронной сети — определяет общие принципы её построения, вот здесь есть хорошее введение в тему, наглядно показано, чем, например, GAN отличается от LSTM.
Обучение нейронной сети — если в двух словах, то это нахождение коэффициентов связи между нейронами. Применительно к машинному обучению заменяет процесс собственно программирования. Когда мы говорим о DALL-E 2, способном создавать изображения по текстовым описаниям или об AlphaGo, обыгрывающем профессиональных игроков в го — мы говорим в первую очередь об обученных нейронных сетях, создатели которых проявили бездну изобретательности, чтобы все коэффициенты связи были на своём месте. Дообучение — частичная корректировка коэффициентов связи между нейронами при модификации старого или добавлении нового функционала.
Зачем нужно машинное обучение? Сильный ИИ, который будет (скрестим пальцы) решать все наши проблемы в режиме реального времени, еще за горизонтом, а прямо сейчас нейронные сети решают задачи, которые не по зубам классическим алгоритмам. Можно ли при помощи «обычного» программирования решить, например, задачу распознавания отсканированного текста или перевода с одного языка на другой. Да, можно, и такие небезуспешные попытки неоднократно предпринимались. Но, учитывая прорыв в развитии математической базы машинного обучения, наметившийся в последние 10-15 лет, помноженный на гигантский прирост производительности даже обычных повседневных вычислительных устройств, вроде смартфонов, фактически и распознавание, и перевод сейчас реализуют только при помощи машинного обучения. Для некоторых же классов задач, таких, как распознавание изображений и видео с последующей классификацией объектов или беспилотная транспортировка, решения на базе классических алгоритмов никогда не заходили дальше вялотекущих концептов.
Мало-помалу машинное обучение делает нашу жизнь лучше. Со временем, надеюсь, каждый из нас сможет воспользоваться плодами работы искусственного интеллекта, хоть мы и величаем его «слабым». И речь идет не только о громких проектах, вроде автопилота «Теслы» (хотя и это крайне немаловажно), но в первую очередь о постоянном сканировании эксабайтных потоков информации, порождаемых современной цифровой цивилизацией — видео с уличных камер, сканов МРТ и КТ, телеметрии с фитнес-браслетов, отчетов об исследовании лекарственных средств и пищевых добавок. И если всё это пройдет перед, может быть, пока не очень умными, но зато неустанными глазами предварительно должным образом обученной нейронной сети, станет меньше неверных диагнозов, людей, умерших от инсультов или замерзших на улицах, лекарств с тяжелыми побочными эффектами.
«И не видели мы ни одной травы, которая не цвела бы, и ни одного дерева, которое не плодоносило бы. Камни же там — только драгоценные.»
Плавание святого Брендана.
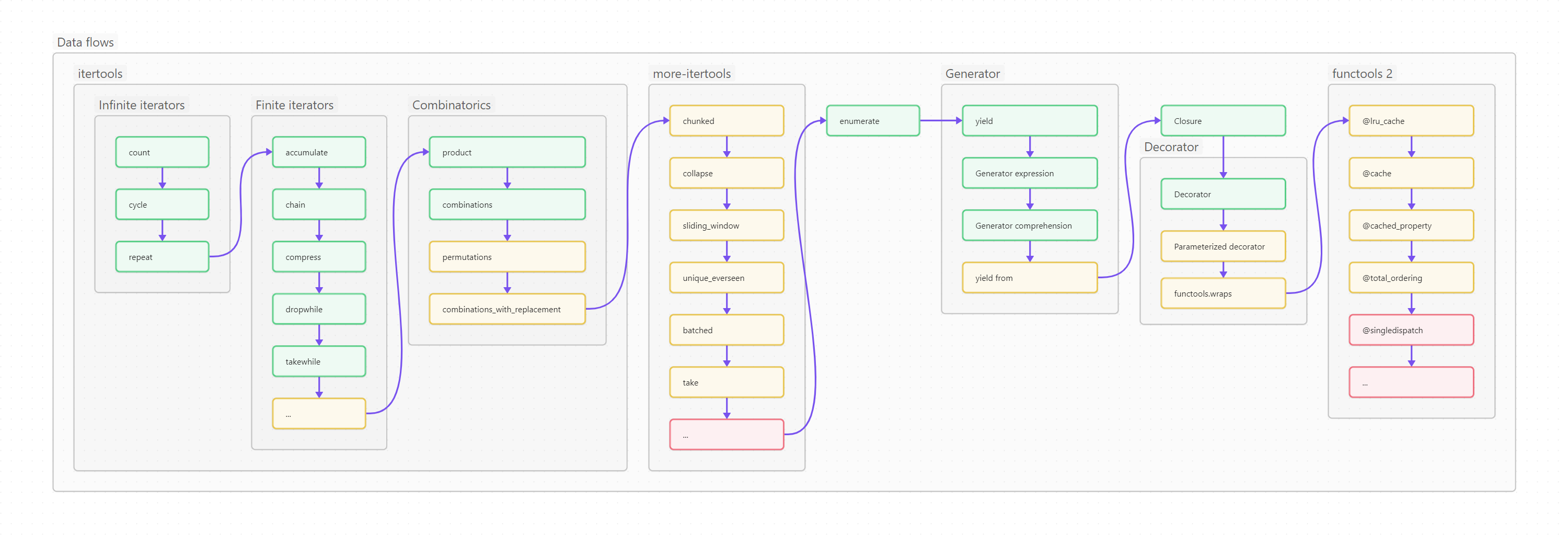
Методы модуля itertools возвращают итераторы.
Итератор — механизм поэлементного обхода данных, который использует метод next() для получения следующего значения последовательности. Подробнее создание итераторов будет рассмотрено ниже, в разделе «ООП / Утиная типизация». В «нормальные» данные итераторы перегоняются при помощи for, next или list().
Itertools содержит множество готовых итераторов, которые могут быть бесконечными (порождаются при помощи count, cycle или repeat), конечными (accumulate, chain, takewhile и другие) и комбинаторными (product, combinations, combinations_with_replacement, permutations). Лучше изучить их все, хотя бы поверхностно, потому что даже относительно редко употребляемый метод, например, какой-нибудь zip_longest(), иногда весьма и весьма пригождается, идеально ложась на поставленную задачу.
Пример работы с бесконечными итераторами:
from itertools import count, repeat, cycle
# Итератор, возвращающий равномерно распределенные значения
i1 = count(start=0, step=.1)
print(next(i1))
print(next(i1))
print(next(i1))
# Итератор, циклично и бесконечно возвращающий элементы итерируемого объекта
i2 = cycle([1, 2])
print(next(i2))
print(next(i2))
print(next(i2))
# Итератор, возвращающий один и тот же объект бесконечно, если не указано значение аргумента times
i3 = repeat("Wow!", times=3)
print(list(i3))0
0.1
0.2
1
2
1
['Wow!', 'Wow!', 'Wow!']
Применение некоторых конечных итераторов:
from itertools import accumulate, chain, compress, dropwhile, takewhile, pairwise
import operator
# Итератор, возвращающий накопленный результат выполнения указанной функции (по умолчанию — сложение)
i1 = accumulate([1, 2, 3, 4])
i2 = accumulate([1, 2, 3, 4], initial=10)
print(list(i1), list(i2))
i3 = accumulate([ -3, -2, -1, 1, 2, 3, 4], operator.mul)
print(list(i3))
# Можно использовать свою функцию
def myfunc(accumulated, current):
return accumulated + 2 * current
i4 = accumulate([1, 2, 3, 4], func=myfunc)
print(list(i4))
# Можно использовать лямбду (подробнее рассмотрены ниже)
i5 = accumulate([1, 2, 3, 4], lambda accumulated, current: accumulated + 2 * current)
print(list(i5))
# Итератор, возвращающий только те элементы входной последовательности,
# которые имеют соответствующий элемент, равный True или 1 в последовательности selectors
i6 = compress("ABCDEF", [1, 1, 1, 0, 0, 1])
print(list(i6))
# Итератор, отбрасывающий элементы входной последовательности, если результат выполнения функции равен True.
# Как только предикат становится False, то отбрасывание прекращается (предикат больше не применяется)
i7 = dropwhile(lambda x: x<5, [1, 4, 6, 4, 1, 1, 1, 0])
print(list(i7))
# takewhile, в отличие от dropwhile, наоборот, возвращает элементы входной последовательности,
# если результат выполнения функции равен True
i8 = takewhile(lambda x: x<5, [1, 4, 6, 0, 4, 1, 2, 1])
print(list(i8))
# Итератор, формирующий из нескольких входных последовательностей одну общую
i2 = chain(["A", "B", "C"],["D", "E", "F"],["G", "H", "I"])
print(list(i2))
# Кстати, такой же трюк можно провернуть при помощи обычной sum(), задав ей начальный параметр [] (т. е. пустой список)
a = sum([["A", "B", "C"],["D", "E", "F"],["G", "H", "I"]], [])
print(a)
# Возвращает элементы входной коллекции попарно
i6 = pairwise([1, 2, 3, 4, 5])
print(list(i6))[1, 3, 6, 10] [10, 11, 13, 16, 20]
[-3, 6, -6, -6, -12, -36, -144]
[1, 5, 11, 19]
[1, 5, 11, 19]
['A', 'B', 'C', 'F']
[6, 4, 1, 1, 1, 0]
[1, 4]
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I']
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I']
[(1, 2), (2, 3), (3, 4), (4, 5)]
Комбинаторика
from itertools import product, combinations, combinations_with_replacement, permutations
# Создает множество, содержащее все упорядоченные пары элементов из входных множеств
a = product("abc", "xyz")
print(list(a))
b = product([0, 1], repeat=3)
print(list(b))
# Возвращает подпоследовательности длины r из элементов входного итерируемого объекта, повторяющиеся элементы не допускаются
c = combinations("abc", r=2)
print(list(c))
# Выдает перестановки элементов итерируемого объекта
d = permutations("abc", r=2)
print(list(d))
# Возвращает подпоследовательности длины r из элементов входного итерируемого объекта, повторяющиеся элементы допустимы
e = combinations_with_replacement("abc", r=2)
print(list(e))[('a', 'x'), ('a', 'y'), ('a', 'z'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'x'), ('c', 'y'), ('c', 'z')]
[(0, 0, 0), (0, 0, 1), (0, 1, 0), (0, 1, 1), (1, 0, 0), (1, 0, 1), (1, 1, 0), (1, 1, 1)]
[('a', 'b'), ('a', 'c'), ('b', 'c')]
[('a', 'b'), ('a', 'c'), ('b', 'a'), ('b', 'c'), ('c', 'a'), ('c', 'b')]
[('a', 'a'), ('a', 'b'), ('a', 'c'), ('b', 'b'), ('b', 'c'), ('c', 'c')]
Иногда, при переборе объектов в цикле for, нужно получить не только сам объект, но и его порядковый номер. Разумеется, это можно сделать, создав дополнительную переменную, которая будет инкрементироваться на каждом шаге цикла. Однако, гораздо удобнее это делать с помощью итератора enumerate, введенным в PEP-279. Enumerate — синтаксический сахар («introduces ... to simplify a commonly used looping idiom») и позволяющего проще и нагляднее работать с объектами, поддерживающими итерацию. Метод __next__() enumerate возвращает кортеж, содержащий значение индекса и соответствующее этому индексу значение.
В документации работа enumerate упрощенно объясняется через генератор:
def enumerate(sequence, start=0):
n = start
for elem in sequence:
yield n, elem
n += 1На самом деле enumerate — не генератор, а итератор:
import collections
import types
e = enumerate("abcdef")
print(isinstance(e, enumerate))
print(isinstance(e, collections.Iterable))
print(isinstance(e, collections.Iterator))
print(isinstance(e, types.GeneratorType))True
True
True
False
Enumerate реализован не на Python, а на C, и в исходном коде, разумеется, нет ключевого слова yield.
Примеры использования enumerate:
values = ["a", "b", "c", "d"]
for count, value in enumerate(values):
print(count, value)
print("\n")
for count, value in enumerate(values, start=10 ):
print(count, value)0 a
1 b
2 c
3 d
10 a
11 b
12 c
13 d
Любая функция, содержащая ключевое слово yield, вернет генератор. Генератор не хранит в памяти все необходимые элементы, а просто содержит метод для вычисления очередного элемента; результат может создаваться на основе математического алгоритма или брать элементы из другого источника данных (коллекция, файл, сетевое подключение и т. д.), при необходимости модифицируя их.
Пройти генератор в цикле можно только один раз, на каждом шаге возможно вычислить только следующий элемент, но не предыдущий. Элемент генератора нельзя извлечь по индексу, будет выброшена ошибка, т. к. генератор не поддерживает метод __getitem__().
Бесконечный генератор:
def count(start, step):
current = start
while True:
yield current
current += step
c = count(100, 10)
print(next(c))
print(next(c))
print(next(c))100
110
120
Конечный генератор. Также, как и конечный итератор, конечный генератор можно превратить в список при помощи list():
def count(start, stop, step):
current = start
while current <= stop:
yield current
current += step
c = count(100, 200, 10)
print(next(c))
print(next(c))
print(next(c))
print(list(c))100
110
120
[130, 140, 150, 160, 170, 180, 190, 200]
Следует разделять итераторы и генераторы. Итератор — объект, который использует метод __next__() для получения следующего значения последовательности. Генератор — функция, которая позволяет отложено создавать результат при итерации.
Объявить генератор можно несколькими методами. Первый метод — объявить функцию с yield, как было показано выше.
Второй метод — использовать генераторное выражение (generator expression):
r = range(1, 11)
squares = (n**2 for n in r)
print(list(squares))[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
Можно объединить генераторы или делегировать часть функционала генератора другому генератору при помощи конструкции yield from:
def subg():
yield 'World'
def generator():
yield 'Hello'
yield from subg()
yield '!'
for i in generator():
print(i, end = ' ')Hello World !
До широкого распространения asyncio конструкция yield from использовалась для создания корутин на базе генераторов.
Что такое декораторы?
Декоратор в широком смысле – паттерн проектирования, когда один объект изменяет поведение другого. В Питоне декоратор, как правило, это функция A, которая принимает функцию B и возвращает функцию C. При этом функция C задействует в себе функцию B.
Задекорировать функцию значит заменить ее на результат работы декоратора.
Что может быть декоратором? К чему может быть применен декоратор?
Декоратором может быть любой вызываемый объект: функция, лямбда, класс, экземпляр класса. В последнем случае определите метод call.
Применять декоратор можно к любому объекту. Чаще всего к функциям, методам и классам. Декорирование встречается настолько часто, что под него выделен особый оператор @.
def auth_only(view): ...
@auth_only def dashboard(request): ... Если бы оператора декорирования не существовало, мы бы записали код выше так:
def auth_only(view): ...
def dashboard(request): ...
dashboard = auth_only(dashboard) Что будет, если декоратор не возвращает ничего?
Если в теле функции нет оператора return, вызов вернет None. Помним, результат декоратора замещает декорируемый объект. В нашем случае декоратор вернет None и функция, которую мы декорируем, тоже станет None. При попытке вызвать ее после декорирования получим ошибку NoneType is not callable.
В чем отличие @foobar от @foobar()?
Первое – обычное декорирование функцией foobar.
Второй случай – декорирование функцией, которую вернет вызов foobar. По-другому это называется параметрический декоратор или фабрика декораторов. См. следующий вопрос.
Что такое фабрика декораторов?
Это функция, которая возвращает декоратор. Такой декоратор редко помещают в отдельную переменную. Вместо этого декорируют результатом вызова фабрики декораторов.
Например, вам нужен декоратор для проверки прав. Логика проверки одинакова, но прав может быть много. Чтобы не плодить копипасту, напишем фабрику декораторов.
from functools import wraps
def has_perm(perm):
def decorator(view):
@wraps(view)
def wrapper(request):
if perm in request.user.permissions:
return view(request)
else:
return HTTPRedirect('/login')
return wrapper
return decorator
@has_perm('view_user')
def users(request):
...Зачем нужен @wraps? functools.wraps
wraps – декоратор из стандартной поставки Питона, модуль functools. Он назначает функции-врапперу те же поля name, module, doc, что и у исходной функции, которую вы декорируете. Это нужно для того, чтобы после декорирования функция-враппер не выглядела в стектрейсах как исходная функция.
Можно ли использовать несколько декораторов для одной функции?
Можно ли создать декоратор из класса?
!!!Написать параметризированный декоратор, который печатает время выполнения декорированной функции. Параметр декоратора — точность округления в миллисекундах
https://habr.com/ru/post/141411/
https://habr.com/ru/post/141501/
A decorator takes a function, adds some functionality and returns it. It can be any callable, but is usually implemented as a function that returns a closure.
@decorator_name def function_that_gets_passed_to_decorator(): ...
Decorator that prints function's name every time it gets called.
from functools import wraps
def debug(func):
@wraps(func)
def out(*args, **kwargs):
print(func.__name__)
return func(*args, **kwargs)
return out
@debug
def add(x, y):
return x + yWraps is a helper decorator that copies the metadata of the passed function (func) to the function it is wrapping (out).
Without it 'add.__name__' would return 'out'.
Decorator that caches function's return values. All function's arguments must be hashable.
from functools import lru_cache
@lru_cache(maxsize=None)
def fib(n):
return n if n < 2 else fib(n-2) + fib(n-1)Default size of the cache is 128 values. Passing 'maxsize=None' makes it unbounded. CPython interpreter limits recursion depth to 1000 by default. To increase it use 'sys.setrecursionlimit()'.
A decorator that accepts arguments and returns a normal decorator that accepts a function.
from functools import wraps
def debug(print_result=False):
def decorator(func):
@wraps(func)
def out(*args, **kwargs):
result = func(*args, **kwargs)
print(func.__name__, result if print_result else '')
return result
return out
return decorator
@debug(print_result=True)
def add(x, y):
return x + yUsing only '@debug' to decorate the add() function would not work here, because debug would then receive the add() function as a 'print_result' argument. Decorators can however manually check if the argument they received is a function and act accordingly.
В питоне есть оператор with. Размещенный внутри код выполняется с особенностью: до и после гарантированно срабатывают события входа в блок with и выхода из него. Объект, который определяет логику событий, называется контекстным менеджером.
На уровне класса события определены методами enter и exit. Первый срабатывает в тот момент, когда ход исполнения программы переходит внутрь with. Метод может вернуть значение. Оно будет доступно низлежащему внутри блока with коду.
exit срабатывает в момент выхода блока, в т.ч. и в случае исключения. В этом случае в метод будет передана тройка значений (exc_class, exc_instance, traceback).
Самый распространённый контекстный менеджер – класс, порожденный функцией open. Он гарантирует, что файл будет закрыт даже в том случае, если внутри блока возникнет ошибка.
Желательно выходить из контекстного менеджера как можно быстрее, чтобы освобождать контекст и ресурсы.
with open('file.txt') as f:
data = f.read()
process_data(data)В примере выше мы вышли из блока with сразу же после прочтения файла. Обработка данных происходит в основном блоке программы.
Контекстные менеджеры можно использовать для временной замены параметров, переменных окружения, транзакций БД.
Какие функции нужно переопределить в классе А, чтобы экземпляры этого класса могли реализовать протокол контекстного менеджера?
Напишем свой контекстный менеджер:
Enter() should lock the resources and optionally return an object. Exit() should release the resources. Any exception that happens inside the with block is passed to the exit() method. If it wishes to suppress the exception it must return a true value.
class MyOpen:
def __init__(self, filename):
self.filename = filename
def __enter__(self):
self.file = open(self.filename)
return self.file
def __exit__(self, exc_type, exception, traceback):
self.file.close()with open('test.txt', 'w') as file: ... file.write('Hello World!') with MyOpen('test.txt') as file: ... print(file.read()) Hello World!
«Место то несказанно прекрасно видом: всякое дерево благоцветно, и всякий плод зрел, и всевозможные явства изобилуют, всякое дуновение благовонно.»
Славянская книга Еноха.
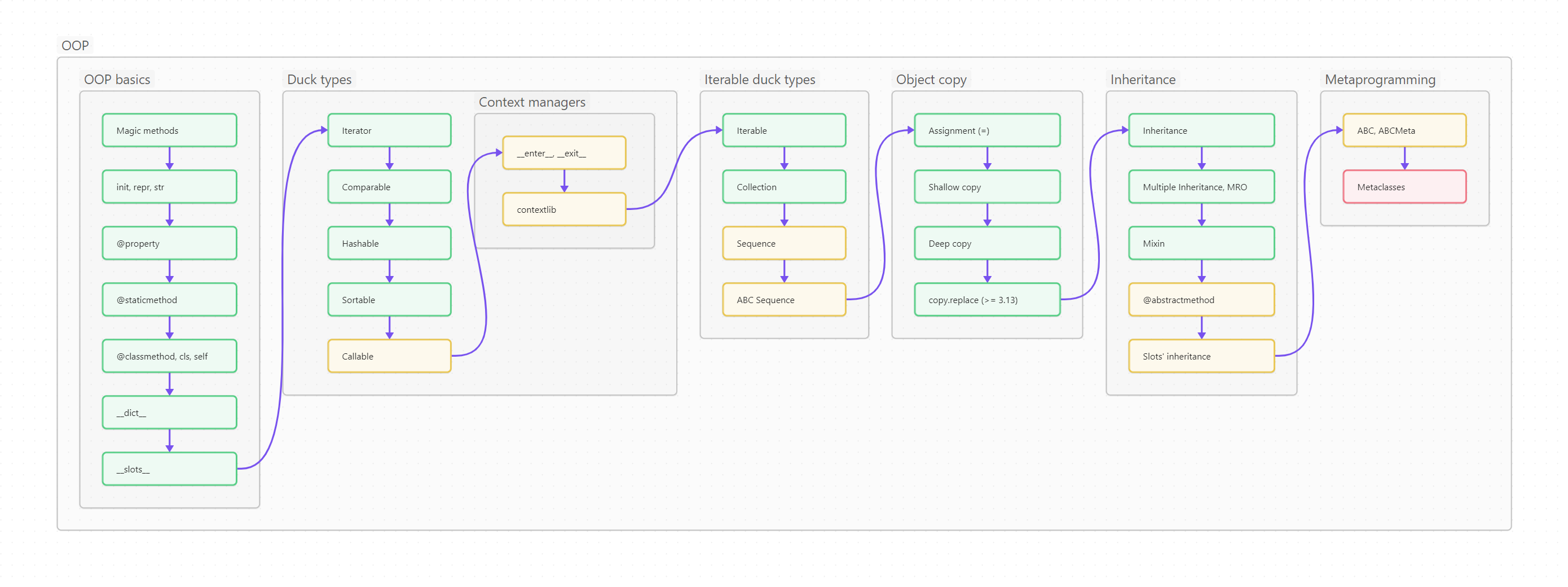
Что такое магические методы, для чего нужны?
Магическими метода называют методы, имена которых начинаются и заканчиваются двойным подчеркиванием. Магические они потому, что почти никогда не вызываются явно. Их вызывают встроенные функции или синтаксические конструкции. Например, функция len() вызывает метод len() переданного объекта. Метод add(self, other) вызывается автоматически при сложении оператором +.
Перечислим некоторые магические методы:
init: конструктор класса
add: сложение с другим объектом
eq: проверка на равенство с другим объектом
cmp: сравнение (больше, меньше, равно)
iter: при подстановке объекта в цикл
Как в классе сослаться на родительский класс?
Функция super принимает класс и экземпляр:
class NextClass(FirstClass):
def __init__(self, x):
super(NextClass, self).__init__()
self.x = xEverything is an object. Every object has a type. Type and class are synonymous.
= type() # Or: .class = isinstance(, ) # Or: issubclass(type(), )
type('a'), 'a'.class, str (<class 'str'>, <class 'str'>, <class 'str'>)
Some types do not have built-in names, so they must be imported:
from types import FunctionType, MethodType, LambdaType, GeneratorType, ModuleType
Each abstract base class specifies a set of virtual subclasses. These classes are then recognized by isinstance() and issubclass() as subclasses of the ABC, although they are really not. ABC can also manually decide whether or not a specific class is its virtual subclass, usually based on which methods the class has implemented. For instance, Iterable ABC looks for method iter() while Collection ABC looks for methods iter(), contains() and len().
class : def init(self, a): self.a = a def repr(self): class_name = self.class.name return f'{class_name}({self.a!r})' def str(self): return str(self.a)
@classmethod
def get_class_name(cls):
return cls.__name__
Return value of repr() should be unambiguous and of str() readable. If only repr() is defined, it will also be used for str().
print() f'{}' logging.warning() csv.writer().writerow([]) raise Exception()
print/str/repr([]) f'{!r}' Z = dataclasses.make_dataclass('Z', ['a']); print/str/repr(Z())
class : def init(self, a=None): self.a = a
class Person: def init(self, name, age): self.name = name self.age = age
class Employee(Person): def init(self, name, age, staff_num): super().init(name, age) self.staff_num = staff_num
class A: pass class B: pass class C(A, B): pass
MRO determines the order in which parent classes are traversed when searching for a method:
C.mro() [<class 'C'>, <class 'A'>, <class 'B'>, <class 'object'>]
Pythonic way of implementing getters and setters.
class Person: @property def name(self): return ' '.join(self._name)
@name.setter
def name(self, value):
self._name = value.split()
person = Person() person.name = '\t Guido van Rossum \n' person.name 'Guido van Rossum'
from dataclasses import make_dataclass = make_dataclass('<class_name>', <coll_of_attribute_names>) = make_dataclass('<class_name>', <coll_of_tuples>) = ('<attr_name>', [, <default_value>])
def func(<arg_name>: [= ]) -> : <var_name>: typing.List/Set/Iterable/Sequence/Optional[] <var_name>: typing.Dict/Tuple/Union[, ...]
A duck type is an implicit type that prescribes a set of special methods. Any object that has those methods defined is considered a member of that duck type.
If eq() method is not overridden, it returns 'id(self) == id(other)', which is the same as 'self is other'.
That means all objects compare not equal by default.
Only the left side object has eq() method called, unless it returns NotImplemented, in which case the right object is consulted.
Ne() automatically works on any object that has eq() defined.
class MyComparable: def init(self, a): self.a = a def eq(self, other): if isinstance(other, type(self)): return self.a == other.a return NotImplemented
Hashable object needs both hash() and eq() methods and its hash value should never change.
Hashable objects that compare equal must have the same hash value, meaning default hash() that returns 'id(self)' will not do.
That is why Python automatically makes classes unhashable if you only implement eq().
class MyHashable: def init(self, a): self._a = a @property def a(self): return self._a def eq(self, other): if isinstance(other, type(self)): return self.a == other.a return NotImplemented def hash(self): return hash(self.a)
With 'total_ordering' decorator, you only need to provide eq() and one of lt(), gt(), le() or ge() special methods and the rest will be automatically generated. Functions sorted() and min() only require lt() method, while max() only requires gt(). However, it is best to define them all so that confusion doesn't arise in other contexts. When two lists, strings or dataclasses are compared, their values get compared in order until a pair of unequal values is found. The comparison of this two values is then returned. The shorter sequence is considered smaller in case of all values being equal.
from functools import total_ordering
@total_ordering class MySortable: def init(self, a): self.a = a def eq(self, other): if isinstance(other, type(self)): return self.a == other.a return NotImplemented def lt(self, other): if isinstance(other, type(self)): return self.a < other.a return NotImplemented
Any object that has methods next() and iter() is an iterator. Next() should return next item or raise StopIteration. Iter() should return 'self'.
class Counter: def init(self): self.i = 0 def next(self): self.i += 1 return self.i def iter(self): return self
counter = Counter() next(counter), next(counter), next(counter) (1, 2, 3)
Sequence iterators returned by the iter() function, such as list_iterator and set_iterator. Objects returned by the itertools module, such as count, repeat and cycle. Generators returned by the generator functions and generator expressions. File objects returned by the open() function, etc.
All functions and classes have a call() method, hence are callable.
When this cheatsheet uses '<function>' as an argument, it actually means '<callable>'.
class Counter: def init(self): self.i = 0 def call(self): self.i += 1 return self.i
counter = Counter() counter(), counter(), counter() (1, 2, 3)
Only required method is iter(). It should return an iterator of object's items. Contains() automatically works on any object that has iter() defined.
class MyIterable:
def __init__(self, a):
self.a = a
def __iter__(self):
return iter(self.a)
def __contains__(self, el):
return el in self.aobj = MyIterable([1, 2, 3]) [el for el in obj] [1, 2, 3] 1 in obj True
Only required methods are iter() and len().
This cheatsheet actually means '<iterable>' when it uses '<collection>'.
I chose not to use the name 'iterable' because it sounds scarier and more vague than 'collection'. The only drawback of this decision is that a reader could think a certain function doesn't accept iterators when it does, since iterators are the only built-in objects that are iterable but are not collections.
class MyCollection: def init(self, a): self.a = a def iter(self): return iter(self.a) def contains(self, el): return el in self.a def len(self): return len(self.a)
Only required methods are len() and getitem(). Getitem() should return an item at the passed index or raise IndexError. Iter() and contains() automatically work on any object that has getitem() defined. Reversed() automatically works on any object that has len() and getitem() defined.
class MySequence: def init(self, a): self.a = a def iter(self): return iter(self.a) def contains(self, el): return el in self.a def len(self): return len(self.a) def getitem(self, i): return self.a[i] def reversed(self): return reversed(self.a)
It's a richer interface than the basic sequence.
Extending it generates iter(), contains(), reversed(), index() and count().
Unlike 'abc.Iterable' and 'abc.Collection', it is not a duck type. That is why 'issubclass(MySequence, abc.Sequence)' would return False even if MySequence had all the methods defined.
from collections import abc
class MyAbcSequence(abc.Sequence):
def __init__(self, a):
self.a = a
def __len__(self):
return len(self.a)
def __getitem__(self, i):
return self.a[i]+------------+------------+------------+------------+--------------+
| | Iterable | Collection | Sequence | abc.Sequence |
+------------+------------+------------+------------+--------------+
| iter() | REQ | REQ | Yes | Yes |
| contains() | Yes | Yes | Yes | Yes |
| len() | | REQ | REQ | REQ |
| getitem() | | | REQ | REQ |
| reversed() | | | Yes | Yes |
| index() | | | | Yes |
| count() | | | | Yes |
+------------+------------+------------+------------+--------------+
Other ABCs that generate missing methods are: MutableSequence, Set, MutableSet, Mapping and MutableMapping.
Names of their required methods are stored in '<abc>.__abstractmethods__'.
Glossary defines iterable as any object with iter() or getitem() and sequence as any object with len() and getitem(). It does not define collection. Passing ABC Iterable to isinstance() or issubclass() checks whether object/class has iter(), while ABC Collection checks for iter(), contains() and len().
Mechanism that restricts objects to attributes listed in 'slots' and significantly reduces their memory footprint.
class MyClassWithSlots: slots = ['a'] def init(self): self.a = 1
Классы хранят поля и их значения в секретном словаре dict. Поскольку словарь – изменяемая структура, вы можете на лету добавлять и удалять из класса поля. Параметр slots в классе жестко фиксирует набор полей класса. Слоты используются когда у класса может быть очень много полей, например, в некоторых ORM, либо когда критична производительность, потому что доступ к слоту срабатывает быстрее, чем поиск в словаре.
Слоты активно используются в библиотеках requests и falcon.
Недостатки: нельзя присвоить классу поле, которого нет в слотах. Не работают методы getattr и setattr.
В Python оператор присваивания (=) не копирует объекты. Вместо этого он создает связь между существующим объектом и именем целевой переменной. Чтобы создать копии объекта в Python, необходимо использовать модуль copy. Более того, существует два способа создания копий для данного объекта с помощью модуля copy.
Shallow Copy – это побитовая копия объекта. Созданный скопированный объект имеет точную копию значений в исходном объекте. Если одно из значений является ссылкой на другие объекты, копируются только адреса ссылок на них. Deep Copy – рекурсивно копирует все значения от исходного объекта к целевому, т. е. дублирует даже объекты, на которые ссылается исходный объект.
from copy import copy, deepcopy = copy() = deepcopy()
Что такое множественное наследование? Возможно ли множественное наследование? Что такое MRO?
Да, можно указать более одного родителя в классе потомка.
MRO – method resolution order, порядок разрешения методов. Алгоритм, по которому следует искать метод в случае, если у класса два и более родителей. Алгоритм линеаризует граф наследования. Коротко можно описать так: ищи слева направо. Поэтому чем левее стоит класс, тем больше у него приоритет при поиске метода.
Прокомментировать выражение object() == object()
Всегда ложь, поскольку по умолчанию объекты сравниваются по полю id (адрес в памяти), если только не переопределен метод eq.
Как удаляется объект?
Code that generates code.
Type is the root class. If only passed an object it returns its type (class). Otherwise it creates a new class.
<class> = type('<class_name>', <tuple_of_parents>, <dict_of_class_attributes>)
>>> Z = type('Z', (), {'a': 'abcde', 'b': 12345})
>>> z = Z()
Singleton через метаклассы
Какие задачи решали с помощью метаклассов?
A class that creates classes.
def my_meta_class(name, parents, attrs): attrs['a'] = 'abcde' return type(name, parents, attrs)
class MyMetaClass(type):
def __new__(cls, name, parents, attrs):
attrs['a'] = 'abcde'
return type.__new__(cls, name, parents, attrs)New() is a class method that gets called before init(). If it returns an instance of its class, then that instance gets passed to init() as a 'self' argument.
It receives the same arguments as init(), except for the first one that specifies the desired type of the returned instance (MyMetaClass in our case).
Like in our case, new() can also be called directly, usually from a new() method of a child class (def __new__(cls): return super().__new__(cls)).
The only difference between the examples above is that my_meta_class() returns a class of type type, while MyMetaClass() returns a class of type MyMetaClass.
Right before a class is created it checks if it has the 'metaclass' attribute defined. If not, it recursively checks if any of his parents has it defined and eventually comes to type().
class MyClass(metaclass=MyMetaClass): b = 12345
MyClass.a, MyClass.b ('abcde', 12345)
type(MyClass) == MyMetaClass # MyClass is an instance of MyMetaClass. type(MyMetaClass) == type # MyMetaClass is an instance of type.
text +-------------+-------------+ | Classes | Metaclasses | +-------------+-------------| | MyClass --> MyMetaClass | | | v | | object -----> type <+ | | | ^ +--+ | | str ----------+ | +-------------+-------------+
MyClass.base == object # MyClass is a subclass of object. MyMetaClass.base == type # MyMetaClass is a subclass of type.
text +-------------+-------------+ | Classes | Metaclasses | +-------------+-------------| | MyClass | MyMetaClass | | v | v | | object <----- type | | ^ | | | str | | +-------------+-------------+
https://proglib.io/p/metaclasses-in-python
https://habr.com/ru/post/145835/
«Эта стена тянется с юга на север, и в ней есть лишь один проход, скрываемый пылающим пламенем, так что ни один смертный не может туда проникнуть.»
Приключения сэра Джона Мандевиля.
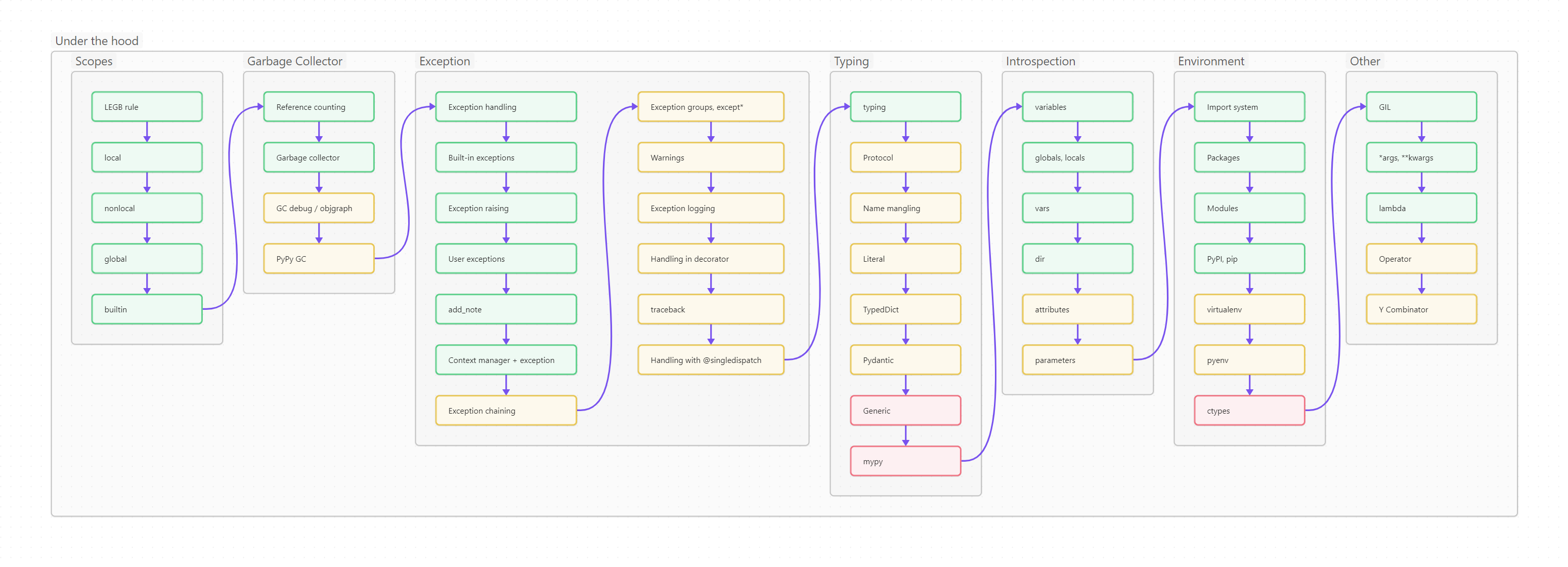
Стандартный интерпретатор Python (CPython) использует для сборки мусора два алгоритма: подсчет ссылок (reference counting, неотключаемый механизм) и garbage collector (стандартный модуль gc из Python, отключаемый). Алгоритм подсчета ссылок не умеет определять циклические ссылки.
Циклические ссылки могут находиться только в “контейнерных” объектах, т.е. в объектах, которые могут хранить другие объекты, например в списках, словарях, классах и кортежах. GC не следит за простыми и неизменяемыми типами, за исключением кортежей. Некоторые кортежи и словари также исключаются из списка слежки при выполнении определенных условий. Со всеми остальными объектами гарантированно справляется алгоритм подсчета ссылок.
В отличие от алгоритма подсчета ссылок, циклический GC не работает постоянно, а запускается периодически. GC разделяет все объекты на 3 поколения. Новые объекты попадают в первое поколение. Если новый объект выживает процесс сборки мусора, то он перемещается в следующее поколение. Чем выше поколение, тем реже оно сканируется. Так как новые объекты зачастую имеют очень маленький срок жизни (являются временными), то имеет смысл опрашивать их чаще, чем те, которые уже прошли через несколько этапов сборки мусора.
В каждом поколенн есть специальный счетчик и порог срабатывания, при достижении которого начинается процесс сборки мусора. Как только в Python создается какой-либо контейнерный объект, он проверяет эти пороги. Если условия срабатывают, то начинается процесс сборки мусора.
Стандартные пороги срабатывания для поколений установлены на 700, 10 и 10 соответственно, но всегда можно изменить их с помощью функций gc.get_threshold и gc.set_threshold.
Алгоритм поиска циклических ссылок: говоря кратко, GC проходит по всем объектам из выбранного поколения и временно удаляет все ссылки от каждого объекта. Все объекты, у которых после этого счетчик ссылок меньше двух, считаются недоступными и могут быть удалены.
Ручной отлов циклических ссылок возможен благодаря наличию у GC отладочному флагу DEBUG_SAVEALL, с которым все недоступные объекты будут добавлены в список gc.garbage:
gc.set_debug(gc.DEBUG_SAVEALL)Список gc.garbage, в свою очередь, можно визуализировать с помощью objgraph:

В других интерпретаторах Python имеются другие механизмы сборки мусора, например, в интерпретаторе PyPy отсутствует алгоритм постоянного подсчета ссылок. Из-за этого, например, содержимое файла может быть обновлено только после прохода GC, а не тогда, когда файл был закрыт в программе.
Global Interpreter Lock - собенность интерпретатора, когда одновременно может исполняться только один тред, остальные треды в это время простаивают.
GIL позволяет безопасно согласовывать изменения данных. Без этого, например, если один тред удалит все элемены из списка, а второй начнет итерацию по нему, произойдет ошибка. Аналогично, сборщик мусора может начать некорректно подсчитывать ссылки. Проблему можно решить, установив блокировки на все разделяемые структуры данных, но это привнесло бы дополнительные сложности: оверхед по коду, потерю производительности, возможные deadlocks. GIL позволяет осуществлять простую интеграцию C-библиотек, которые зачастую тоже не потокобезопасны, а также обеспечивает быструю работу однопоточных скриптов.
GIL работает так: на каждый тред выделяется некоторый квант времени. Он измеряется в машинных единицах “тиках” и по умолчанию равен 100. Как только на тред было потрачено 100 тиков, интерпретатор бросает этот тред и переключается на второй, тратит 100 тактов на него, затем третий, и так по кругу. Этот алгоритм гаранитрует, что всем тредам будет выделено ресурсов поровну.
Проблема в том, что из-за GIL далеко не все задачи могут быть решены в тредах. Напротив, их использование чаще всего снижает быстродействие программы. С использованием тредов требуется следить за доступом к общим ресурсам: словарям, файлам, соединением к БД.
Как обойти ограничения, накладываемые GIL?
Вариант 1 - использовать альтернативные интерпретаторы Python, например PyPy.
Вариант 2 - уход от многопоточности в сторону мультипроцессности, используя модуль multiprocessing. Последний вариант подробно разобран ниже.
Выражения *args и **kwargs объявляют в сигнатуре функции. Они означают, что внутри функции будут доступны переменные с именами args и kwargs (без звездочек). Можно использовать другие имена, но это считается дурным тоном.
args – это кортеж, который накапливает позиционные аргументы. kwargs – словарь позиционных аргументов, где ключ – имя параметра, значение – значение параметра.
Важно: если в функцию не передано никаких параметров, переменные будут соответственно равны пустому кортежу и пустому словарю, а не None.
(<positional_args>) # f(0, 0) (<keyword_args>) # f(x=0, y=0) (<positional_args>, <keyword_args>) # f(0, y=0)
def f(<nondefault_args>): # def f(x, y): def f(<default_args>): # def f(x=0, y=0): def f(<nondefault_args>, <default_args>): # def f(x, y=0):
A function has its default values evaluated when it's first encountered in the scope. Any changes to default values that are mutable will persist between invocations.
Splat expands a collection into positional arguments, while splatty-splat expands a dictionary into keyword arguments.
args = (1, 2) kwargs = {'x': 3, 'y': 4, 'z': 5} func(*args, **kwargs)
func(1, 2, x=3, y=4, z=5)
Splat combines zero or more positional arguments into a tuple, while splatty-splat combines zero or more keyword arguments into a dictionary.
def add(*a): return sum(a)
add(1, 2, 3) 6
def f(*, x, y, z): # f(x=1, y=2, z=3) def f(x, *, y, z): # f(x=1, y=2, z=3) | f(1, y=2, z=3) def f(x, y, *, z): # f(x=1, y=2, z=3) | f(1, y=2, z=3) | f(1, 2, z=3)
def f(*args): # f(1, 2, 3) def f(x, *args): # f(1, 2, 3) def f(*args, z): # f(1, 2, z=3)
def f(**kwargs): # f(x=1, y=2, z=3) def f(x, **kwargs): # f(x=1, y=2, z=3) | f(1, y=2, z=3) def f(*, x, **kwargs): # f(x=1, y=2, z=3)
def f(*args, **kwargs): # f(x=1, y=2, z=3) | f(1, y=2, z=3) | f(1, 2, z=3) | f(1, 2, 3) def f(x, *args, **kwargs): # f(x=1, y=2, z=3) | f(1, y=2, z=3) | f(1, 2, z=3) | f(1, 2, 3) def f(*args, y, **kwargs): # f(x=1, y=2, z=3) | f(1, y=2, z=3)
= [ [, ...]] = { [, ...]} = (*, [...]) = {** [, ...]}
head, *body, tail =
Как передаются значения аргументов в функцию или метод? Как передаются аргументы функций в Python (by value or reference)?
Это анонимные функции. Они не резервируют имени в пространстве имен. Лямбды часто передают в функции map, reduce, filter.
Лямбды в Питоне могут состоять только из одного выражения. Используя синтаксис скобок, можно оформить тело лямбды в несколько строк.
Допустимы ли следующие выражения?
nope = lambda: pass riser = lambda x: raise Exception(x) Нет, при загрузке модуля выскочит исключение SyntaxError. В теле лямбды может быть только выражение. pass и raise являются операторами.
= lambda: <return_value> = lambda <arg_1>, <arg_2>: <return_value>
<obj> = <exp_if_true> if <condition> else <exp_if_false>
>>> [a if a else 'zero' for a in (0, 1, 2, 3)]
['zero', 1, 2, 3]
Closure
We have/get a closure in Python when: A nested function references a value of its enclosing function and then the enclosing function returns the nested function.
def get_multiplier(a):
def out(b):
return a * b
return out>>> multiply_by_3 = get_multiplier(3)
>>> multiply_by_3(10)
30
If multiple nested functions within enclosing function reference the same value, that value gets shared.
To dynamically access function's first free variable use '<function>.__closure__[0].cell_contents'.
Простой пример:
a: float = 0
b: float = 0
try:
b: float = 1/a
except ZeroDivisionError as e:
print(f"Error: {e}")Error: division by zero
Более сложный пример. Code inside the else block will only be executed if try block had no exceptions. Code inside the finally block will always be executed (unless a signal is received).
import traceback
a: float = 0
b: float = 0
try:
b: float = 1/a
except ZeroDivisionError as e:
print(f"Error: {e}")
except ArithmeticError as e:
print(f"We have a bit more complicated problem: {e}")
except Exception as serious_problem: # Catch all exceptions
print(f"I don't really know what is going on: {traceback.print_exception(serious_problem)}")
else:
print("No errors!")
finally:
print("This part is always called")Error: division by zero
This part is always called
BaseException
+-- SystemExit # Raised by the sys.exit() function
+-- KeyboardInterrupt # Raised when the user press the interrupt key (ctrl-c)
+-- Exception # User-defined exceptions should be derived from this class
+-- ArithmeticError # Base class for arithmetic errors
| +-- ZeroDivisionError # Dividing by zero
+-- AttributeError # Attribute is missing
+-- EOFError # Raised by input() when it hits end-of-file condition
+-- LookupError # Raised when a look-up on a collection fails
| +-- IndexError # A sequence index is out of range
| +-- KeyError # A dictionary key or set element is missing
+-- NameError # An object is missing
+-- OSError # Errors such as “file not found”
| +-- FileNotFoundError # File or directory is requested but doesn't exist
+-- RuntimeError # Error that don't fall into other categories
| +-- RecursionError # Maximum recursion depth is exceeded
+-- StopIteration # Raised by next() when run on an empty iterator
+-- TypeError # An argument is of wrong type
+-- ValueError # When an argument is of right type but inappropriate value
+-- UnicodeError # Encoding/decoding strings to/from bytes fails
from decimal import *
def div(a: Decimal, b: Decimal) -> Decimal:
if b == 0:
raise ValueError("Second argument must be non-zero")
return a/b
try:
c: Decimal = div(1, 0)
except ValueError:
print("We have ValueError, as a planned!")
# raise # We can re-raise exceptionWe have ValueError, as a planned!
import sys
# sys.exit() # Exits with exit code 0 (success)
# sys.exit(777) # Exits with passed exit codeclass MyException(Exception):
pass
raise MyException("My car is broken")---------------------------------------------------------------------------
MyException Traceback (most recent call last)
c:\Works\amaargiru\pycore\01_python.ipynb Ячейка 103 in <cell line: 4>()
<a href='vscode-notebook-cell:/c%3A/Works/amaargiru/pycore/01_python.ipynb#Y204sZmlsZQ%3D%3D?line=0'>1</a> class MyException(Exception):
<a href='vscode-notebook-cell:/c%3A/Works/amaargiru/pycore/01_python.ipynb#Y204sZmlsZQ%3D%3D?line=1'>2</a> pass
----> <a href='vscode-notebook-cell:/c%3A/Works/amaargiru/pycore/01_python.ipynb#Y204sZmlsZQ%3D%3D?line=3'>4</a> raise MyException("My car is broken")
MyException: My car is broken
Exception Object
arguments = .args exc_type = .class filename = .traceback.tb_frame.f_code.co_filename func_name = .traceback.tb_frame.f_code.co_name line = linecache.getline(filename, .traceback.tb_lineno) error_msg = ''.join(traceback.format_exception(exc_type, , .traceback))
Пробовал flake8 + black, остановился на линтере, встроенном в Pycharm + mypy.
Python не использует спецификаторы доступа, такие как private, public, protected и т. д. Однако, в нем есть имитации поведения переменных путем использования одинарного или двойного подчеркивания в качестве префикса к именам переменных. По умолчанию переменные без подчеркивания являются общедоступными.
Поле класса с одним лидирующим подчеркиванием говорит о том, что параметр используется только внутри класса. При этом он доступен для обращения извне.
class Foo(object):
def __init__(self):
self._bar = 42
Foo()._bar
42Современные IDE вроде PyCharm подсвечивают обращение к полю с подчеркиванием, но ошибки в процессе исполнения не будет.
Поля с двойным подчеркиванием доступны внутри класса, но извне доступны только при обращении к полю вида ___ (name mangling). Значение скрытого поля вне класса получить можно, но это смотрится уродливо.
class Foo(object):
def __init__(self):
self.__bar = 42
Foo().__bar
AttributeError: 'Foo' object has no attribute '__bar'
Foo()._Foo__bar
42В целом, джентельменское соглашение пайтон-программистов подразумевает (простое именование для приватных переменных или использование одинарного подчеркивания для переменных, которые очень нежелательно вытаскивать за пределы класса) + использование методов для доступа к переменным
class Stack(object):
def __init__(self):
self._storage = []
def push(self, value):
self._storage.append(value)Inspecting code at runtime.
= dir() # Names of local variables (incl. functions). = vars() # Dict of local variables. Also locals(). = globals() # Dict of global variables.
= dir() # Names of object's attributes (incl. methods).
= vars() # Dict of writable attributes. Also .dict.
= hasattr(, '<attr_name>') # Checks if getattr() raises an AttributeError.
value = getattr(, '<attr_name>') # Raises AttributeError if attribute is missing.
setattr(, '<attr_name>', value) # Only works on objects with 'dict' attribute.
delattr(, '<attr_name>') # Same. Also del <object>.<attr_name>.
from inspect import signature = signature() # Function's Signature object. = .parameters # Dict of function's Parameter objects. = .name # Parameter's name. = .kind # Member of ParameterKind enum.
(использование dir(), dir, hasattr(), getattr())
Как получить список атрибутов объекта?
Функция dir возвращает список строк – полей объекта. Поле dict содержит словарь вида {поле -> значение}.
Module of functions that provide the functionality of operators.
import operator as op = op.add/sub/mul/truediv/floordiv/mod(, ) # +, -, *, /, //, % <int/set> = op.and_/or_/xor(<int/set>, <int/set>) # &, |, ^ = op.eq/ne/lt/le/gt/ge(, ) # ==, !=, <, <=, >, >= = op.itemgetter/attrgetter/methodcaller() # [index/key], .name, .name()
elementwise_sum = map(op.add, list_a, list_b) sorted_by_second = sorted(, key=op.itemgetter(1)) sorted_by_both = sorted(, key=op.itemgetter(1, 0)) product_of_elems = functools.reduce(op.mul, ) union_of_sets = functools.reduce(op.or_, <coll_of_sets>) first_element = op.methodcaller('pop', 0)()
Binary operators require objects to have and(), or(), xor() and invert() special methods, unlike logical operators that work on all types of objects.
Also: '<bool> = <bool> &|^ <bool>' and '<int> = <bool> &|^ <int>'.
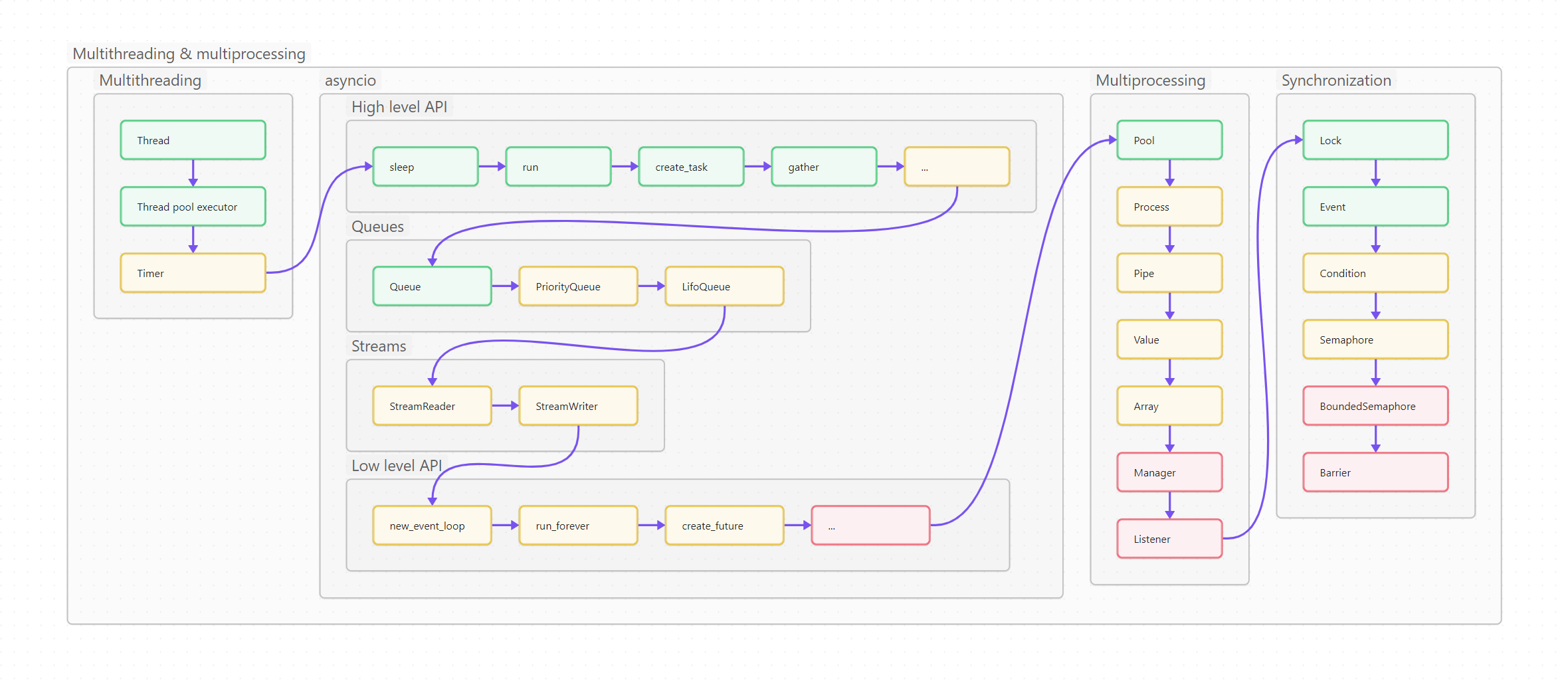
CPython interpreter can only run a single thread at a time. That is why using multiple threads won't result in a faster execution, unless at least one of the threads contains an I/O operation.
from threading import Thread, RLock, Semaphore, Event, Barrier
from concurrent.futures import ThreadPoolExecutor
<Thread> = Thread(target=<function>) # Use `args=<collection>` to set the arguments.
<Thread>.start() # Starts the thread.
<bool> = <Thread>.is_alive() # Checks if the thread has finished executing.
<Thread>.join() # Waits for the thread to finish.
Use 'kwargs=<dict>' to pass keyword arguments to the function.
Use 'daemon=True', or the program will not be able to exit while the thread is alive.**
<lock> = RLock() # Lock that can only be released by the owner.
<lock>.acquire() # Waits for the lock to be available.
<lock>.release() # Makes the lock available again.
with <lock>: # Enters the block by calling acquire(),
... # and exits it with release().
<Semaphore> = Semaphore(value=1) # Lock that can be acquired by 'value' threads.
<Event> = Event() # Method wait() blocks until set() is called.
<Barrier> = Barrier(n_times) # Wait() blocks until it's called n_times.
Object that manages thread execution. An object with the same interface called ProcessPoolExecutor provides true parallelism by running a separate interpreter in each process. All arguments must be pickable.
<Exec> = ThreadPoolExecutor(max_workers=None) # Or: `with ThreadPoolExecutor() as <name>: …`
<Exec>.shutdown(wait=True) # Blocks until all threads finish executing.
<iter> = <Exec>.map(<func>, <args_1>, ...) # A multithreaded and non-lazy map().
<Futr> = <Exec>.submit(<func>, <arg_1>, ...) # Starts a thread and returns its Future object.
<bool> = <Futr>.done() # Checks if the thread has finished executing.
<obj> = <Futr>.result() # Waits for thread to finish and returns result.
Многопоточность достигается модулем Threading. Это нативные Posix-треды, такие треды исполняются операционной системой, а не виртуальной машиной.
В чем отличие тредов от мультипроцессинга?
Главное отличие в разделении памяти. Процессы независимы друг от друга, имеют раздельные адресные пространства, идентификаторы, ресурсы. Треды исполняются в совместном адресном пространстве, имеют общий доступ к памяти, переменным, загруженным модулям.
Какие задачи хорошо параллелятся, какие плохо?
Те задачи, которые порождают долгий IO. Когда тред упирается в ожидание сокета или диска, интерпретатор бросает этот тред и стартует следующий. Это значит, не будет простоя из-за ожидания. Наоборот, если ходить в сеть в одном треде (в цикле), то каждый раз придется ждать ответа.
Однако, если затем в треде обрабатывает полученные данные, то выполнятся будет только он один. Это не только не даст прироста в скорости, но и замедлит программу из-за переключения на другие треды.
Короткий ответ: хорошо ложатся на треды задачи по работе с сетью. Например, выкачать сто урлов. Полученные данные обрабатывайте вне тредов.
Нужно посчитать 100 уравнений. Делать это в тредах или нет?
Нет, потому что в этой задаче нет ввода-вывода. Интерпретатор только будет тратить лишнее время на переключение тредов. Сложные математические задачи лучше выносить в отдельные процессы, либо использовать фреймворк для распределенных задач Celery, либо подключать как C-библиотеки.
Понимание что такое heap dump и thread dump.
понимание многопоточности, способов ей управлять и проблем, с этим связанных (синхронизации, локи, race condition и т.д.);
-
Многопоточность - вариант реализации вычислений, при котором для решения некоторой прикладной задачи запускаются и выполняются несколько независимых потоков вычислений, причём выполнение происходит одновременно или псевдоодновременно. В операционных системах, где термины "поток" и "процесс" различаются, под "потоком" понимают именно поток выполнения (ресурсами же владеет сущность, называемая "процессом"). Обычно применяется для распараллеливания вычислений на несколько вычислителей (процессоров и ядер процессора).
-
Многопроцессность - вариант реализации вычислений, когда для решения некоторой прикладной задачи запускается несколько независимых процессов. В системах, где под процессом понимается сущность, владеющая ресурсами (памятью, открытыми файлами, сетевыми подключениями), несколько процессов запускаются с целью повышения отказоустойчивости приложения а также с целью повышения безопасности. Т.к. ОС выполняет разделение памяти и прочих ресурсов именно между процессами (в то время как потоки работают в едином адресном пространстве), то а) внезапно упавший (читай - убитый ОС) процесс не уронит остальные; б) если в процессе начал выполняться чужеродный код (например, из-за RCE уязвимости), то он не получит доступ к содержимому памяти в других процессах. Многопроцессность сегодня можно увидеть в браузерах, когда отдельные вкладки выполняются в разных процессах, и упавшая вкладка (из-за js или из-за кривого плагина) тянет за собой не весь браузер, а только себя или еще пару вкладок.
https://realpython.com/async-io-python/
В JavaScript async / await сделаны жадными как Promise. При вызове async функции автоматически создается задача и отправляется в очередь на исполнение в event loop. await, в свою очередь, просто ждёт результат.
В питоне асинхронщину задизайнили иначе - лениво.
Вызов async функции возвращает объект - корутину, - которая ни чего не делает.
asyncio.run() создаёт event loop, запускает (корневую) корутину и блокирует поток до получения результата.
await запускает корутину изнутри другой корутины в текущем event loop и ждёт результат.
Для запуска корутины без ожидания (как это делает Promise) используется asyncio.create_task(coro). Либо asyncio.gather(*aws), если надо запустить сразу несколько. Нужно только следить, чтобы ссылка на возвращаемое значение сохранялась до конца вычисления, иначе его пожрет GC и все оборвется на самом интересном месте (промис бы отработал до конца не смотря ни на что).
В JS только один event loop, поэтому было вполне разумно закопать его внутрь promise / async / await как деталь реализации, упростив работу прикладному программисту. В питоне отзеркалили более ранний вариант корутин на генераторах, дали возможность использовать разные event loop и выставили все кишки наружу.
# Однопоточное приложение
import time
COUNT = 100_000_000
def countdown(n):
while n > 0:
n -= 1
start = time.time()
countdown(COUNT)
end = time.time()
print("Count time", end - start)Count time 3.81453800201416
# Многопоточное приложение, время выполнения будет больше, чем у однопоточного, т. к. добавятся временные затраты на переключение потоков
import time
from threading import Thread
COUNT = 100_000_000
def countdown(n):
while n > 0:
n -= 1
t1 = Thread(target=countdown, args=(COUNT//2,))
t2 = Thread(target=countdown, args=(COUNT//2,))
start = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
end = time.time()
print("Count time", end - start)Count time 3.8378489017486572
# Многопроцессорное приложение
import time
import multiprocessing as mp
COUNT = 100_000_000
def countdown(n):
while n > 0:
n -= 1
if __name__ == '__main__':
pool = mp.Pool()
start = time.time()
pool.apply_async(countdown, args=(COUNT // 2,))
pool.apply_async(countdown, args=(COUNT // 2,))
pool.close()
pool.join()
end = time.time()
print("Count time", end - start)Count time 2.0029137134552
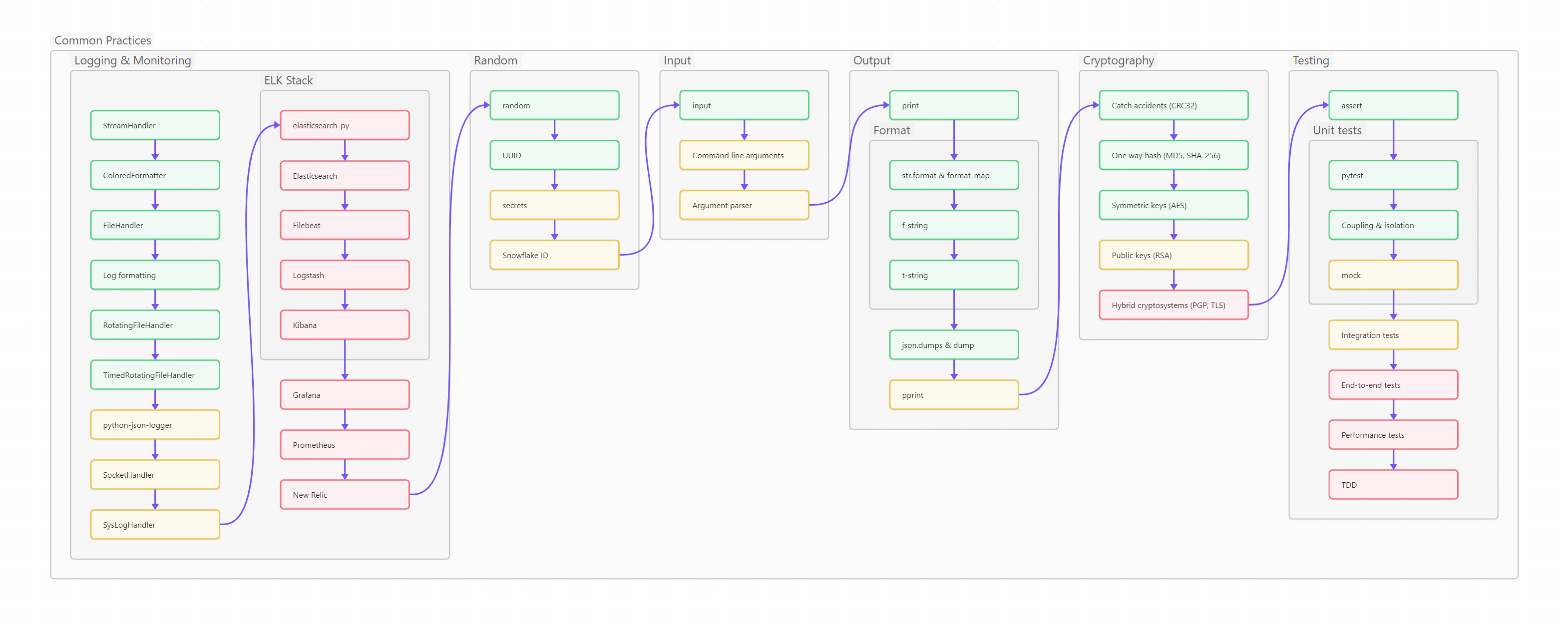
import pathlib
import sys
import logging
from logging.handlers import RotatingFileHandler
from colorlog import ColoredFormatter
class TestLogger:
@staticmethod
def get_logger(path_to_log_file: str, max_file_size: int, max_file_count: int) -> logging.Logger:
logger = logging.getLogger("sample_logger")
logger.setLevel(logging.DEBUG)
# Форматирование при выводе в файл
flog_formatter = logging.Formatter("%(asctime)s.%(msecs)03d %(filename)-24s %(levelname)-8s %(message)s",
datefmt="%a, %d %b %Y %H:%M:%S")
file_handler = RotatingFileHandler(filename=path_to_log_file, mode="a", maxBytes=max_file_size,
backupCount=max_file_count, encoding="utf-8", delay=False)
file_handler.setFormatter(flog_formatter)
logger.addHandler(file_handler)
# Форматирование при выводе в консоль
clog_formatter = ColoredFormatter("%(asctime)s.%(msecs)03d %(filename)-24s :%(lineno)4d "
"%(log_color)s%(levelname)-8s %(message)s%(reset)s",
datefmt="%a, %d %b %Y %H:%M:%S")
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(clog_formatter)
logger.addHandler(console_handler)
return logger
log_file_max_size: int = 25 * 1024 ** 2 # Максимальный размер одного файла логов
log_file_max_count: int = 10 # Максимальное количество файлов логов
log_file_path: str = "logs/sample_logger.log"
try:
path = pathlib.Path(log_file_path) # Создаем путь к файлу логов, если он не существует
path.parent.mkdir(parents=True, exist_ok=True)
logger = TestLogger.get_logger(log_file_path, log_file_max_size, log_file_max_count)
except Exception as err:
print(f"Ошибка при попытке создания файла лога: {str(err)}")
sys.exit() # Аварийный выход
logger.debug("Debug message")
logger.info("Hello, world!")
logger.error("Error!")Thu, 15 Sep 2022 17:37:36.754 1628851721.py : 44 �[37mDEBUG Debug message�[0m
Thu, 15 Sep 2022 17:37:36.755 1628851721.py : 45 �[32mINFO Hello, world!�[0m
Thu, 15 Sep 2022 17:37:36.756 1628851721.py : 46 �[31mERROR Error!�[0m
from time import time
start_time = time()
j: int = 0
for i in range(10_000_000): # Long operation
j = i ** 2
duration = time() - start_time
print(f"{duration} seconds")2.2923033237457275 seconds
from time import perf_counter
start_time = perf_counter()
j: int = 0
for i in range(10_000_000): # Long operation
j = i ** 2
duration = perf_counter() - start_time
print(f"{duration} seconds")2.2668115999549627 seconds
Try to avoid a number of common traps for measuring execution times
from timeit import timeit
def long_pow():
j: int = 0
for i in range(1_000_000): # Long operation
j = i ** 2
timeit("long_pow()", number=10, globals=globals(), setup='pass')1.8498943001031876
Создает PNG изображение графа вызовов с подсвеченными узкими местами
from pycallgraph3 import PyCallGraph
from pycallgraph3.output import GraphvizOutput
def long_pow():
j: int = 0
for i in range(1000_000): # Long operation
j = i ** 2
def short_pow():
j: int = 0
for i in range(1000): # Short operation
j = i ** 2
with PyCallGraph(output=GraphvizOutput()):
# Code to be profiled
long_pow()
short_pow()
# This will generate a file called pycallgraph3.png
import random
rf: float = random.random() # A float inside [0, 1)
print(f"Single float random: {rf}")
ri: int = random.randint(1, 10) # An int inside [from, to]
print(f"Single int random: {ri}")
rb = random.randbytes(10)
print(f"Random bytes: {rb}")
rc: str = random.choice(["Alice", "Bob", "Maggie", "Madhuri Dixit"])
print(f"Random choice: {rc}")
rs: str = random.sample([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 5)
print(f"Random list without duplicates: {rs}")
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(f"List before shuffle: {a}")
random.shuffle(a)
print(f"List after shuffle: {a}")Single float random: 0.9024807633898538
Single int random: 7
Random bytes: b'>\xe0^\x16PX\xf8E\xf8\x98'
Random choice: Bob
Random list without duplicates: [5, 10, 3, 6, 1]
List before shuffle: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
List after shuffle: [10, 4, 6, 5, 1, 8, 3, 9, 7, 2]
Reads a line from user input or pipe if present.
= input(prompt=None)
Trailing newline gets stripped. Prompt string is printed to the standard output before reading input. Raises EOFError when user hits EOF (ctrl-d/ctrl-z⏎) or input stream gets exhausted.
import sys
scripts_path = sys.argv[0]
arguments = sys.argv[1:]
from argparse import ArgumentParser, FileType
p = ArgumentParser(description=<str>)
p.add_argument('-<short_name>', '--<name>', action='store_true') # Flag.
p.add_argument('-<short_name>', '--<name>', type=<type>) # Option.
p.add_argument('<name>', type=<type>, nargs=1) # First argument.
p.add_argument('<name>', type=<type>, nargs='+') # Remaining arguments.
p.add_argument('<name>', type=<type>, nargs='*') # Optional arguments.
args = p.parse_args() # Exits on error.
value = args.<name>
Use `'help=<str>'` to set argument description.
Use `'default=<el>'` to set the default value.
Use `'type=FileType(<mode>)'` for files.
print(<el_1>, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Use `'file=sys.stderr'` for messages about errors.
Use `'flush=True'` to forcibly flush the stream.
from pprint import pprint
pprint(<collection>, width=80, depth=None, compact=False, sort_dicts=True)
Levels deeper than 'depth' get replaced by '...'.
# pip install pycryptodomex
import hashlib
from Cryptodome import Random
from Cryptodome.Cipher import AES
from Cryptodome.Util.Padding import pad
from Cryptodome.Util.Padding import unpad
def encrypt_data(password: str, raw_data: bytes) -> bytes:
res = bytes()
try:
key = hashlib.sha256(password.encode()).digest()
align_raw = pad(raw_data, AES.block_size)
iv = Random.new().read(AES.block_size)
cipher = AES.new(key, AES.MODE_CBC, iv)
ciphered_data = cipher.encrypt(align_raw)
res = iv + ciphered_data
except Exception as e:
print(f"Encrypt error: {str(e)}")
return res
def decrypt_data(password: str, encrypted_data: bytes) -> bytes:
res = bytes()
try:
key = hashlib.sha256(password.encode()).digest()
iv = encrypted_data[:AES.block_size]
ciphered_data = encrypted_data[AES.block_size:]
cipher = AES.new(key, AES.MODE_CBC, iv)
decrypt_data = cipher.decrypt(ciphered_data)
res = unpad(decrypt_data, AES.block_size)
except Exception as e:
print(f"Decrypt error: {str(e)}")
return res
def encrypt_file(src_file: str, dst_file: str, password: str) -> bool:
try:
with open(src_file, "rb") as reader, open(dst_file, "wb") as writer:
data = reader.read()
data_enc = encrypt_data(password, data)
writer.write(data_enc)
writer.flush()
print(f"{src_file} encrypted into {dst_file}")
return True
except Exception as e:
print(f"Encrypt_file error: {str(e)}")
return False
def decrypt_file(src_file: str, dst_file: str, password: str) -> bool:
try:
with open(src_file, "rb") as reader, open(dst_file, "wb") as writer:
data = reader.read()
data_decrypt = decrypt_data(password, data)
writer.write(data_decrypt)
writer.flush()
print(f"{src_file} decrypted into {dst_file}")
return True
except Exception as e:
print(f"Decrypt file error: {str(e)}")
return False
if __name__ == '__main__':
mes: bytes = bytes("A am the Message", "utf-8")
passw: str = "h3AC3TsU8TECvyCqd5Q5WUag5uXLjct2"
print(f"Original message: {mes}")
# Encrypt message
enc: bytes = encrypt_data(passw, mes)
print(f"Encrypted message: {enc}")
# Decrypt message
dec: bytes = decrypt_data(passw, enc)
print(f"Decrypted message: {dec}")Original message: b'A am the Message'
Encrypted message: b' E\x92\xbeH\x87\xdde\t\xd3\x9ap\x0cO\xc3\xf8\x84\xc7~\x1c\x90\xcd\x9a\xd3\x1bNd\xccDt\x1b\xfcZ\x91\xb5\xd78\x85\x91R\x1e]3\x9c\xec\xcbC\xd8'
Decrypted message: b'A am the Message'
Разница между is и ==?
Как создается объект в Python, разница между __init __() и __new __()?
В чем разница между потоками и процессами?
Какие есть виды импорта?
Что такое класс, итератор, генератор?
В чем разница между итераторами и генераторами?
В чем разница между staticmethod и classmethod?
Как работает thread locals?
Что такое type annotation?
Что такое @property?
Как работать с stdlib?
Что такое дескрипторы?
Какой будет результат операции -12 % 10?
Какой будет результат операции -12 // 10?
Какая последовательность вызова операторов в выражении a * b * c?
Что делает функция id()?
Для чего зарезервировано ключевое слово yield?
В чем разница между iter и next?
Что такое проверка типов? Какие есть типы в Python?
Как можно расширить зону видимости глобальных переменных на другие модули? Как создать класс без инструкции class?
Почему def foo(bar=[]): плохо? Приведите пример плохого случая. Как исправить? Почему нельзя сделать пустой список аргументом по умолчанию?
Функция создается однажды при загрузке модуля. Именованные параметры и их дефолтные значения тоже создаются один раз и хранятся в одном из полей объекта-функции.
В нашем примере bar равен пустому списку. Список – изменяемая коллекция, поэтому значение bar может изменяться от вызова к вызову. Пример:
def foo(bar=[]): bar.append(1) return bar foo() [1] foo() [1, 1] foo() [1, 1, 1] Хорошим тоном считается указывать параметру пустое неизменяемое значение, например 0, None, '', False. В теле функции проверять на заполненность и создавать новую коллекцию:
def foo(bar=None): if bar is None: bar = [] bar.append(1) return bar foo() [1] foo() [1] foo() [1]
Для работы с pytest внутри Jupiter notebook воспользуемся инструментом ipytest
# pip install -U ipytest
import ipytest
ipytest.autoconfig()%%ipytest
import ipytest
def test_my_func():
assert my_func(0) == 0
assert my_func(1) == 0
assert my_func(2) == 2
assert my_func(3) == 2
def my_func(x):
return x // 2 * 2 �[32m.�[0m�[32m [100%]�[0m
�[32m�[32m�[1m1 passed�[0m�[32m in 0.01s�[0m�[0m
%%ipytest
import pytest
@pytest.mark.parametrize('input,expected', [
(0, 0),
(1, 0),
(2, 2),
(3, 2),
])
def test_parametrized(input, expected):
assert my_func(input) == expected
@pytest.fixture
def my_fixture():
return 42
def test_fixture(my_fixture):
assert my_fixture == 42�[32m.�[0m�[32m.�[0m�[32m.�[0m�[32m.�[0m�[32m.�[0m�[32m [100%]�[0m
�[32m�[32m�[1m5 passed�[0m�[32m in 0.01s�[0m�[0m
Тестовый двойник - термин, описывающий все виды фальшивых (fake) зависимостей, непригодных к использованию в конечном продукте (non-production-ready). Такая зависимость выглядит и ведет себя как ее аналог, предназначенный для production, но на самом деле является упрощенной версией, которая снижает сложность и облегчает тестирование. Зависимости бывают пяти типов, но для простоты можно ограничиться двумя: моки (mock) и стабы (stub).
Моки помогают имитировать и изучать исходящие (outcoming) взаимодействия. То есть вызовы, совершаемые тестируемой системой (SUT) к ее зависимостям для изменения их состояния.
Стабы помогают имитировать входящие (incoming) взаимодействия. То есть вызовы, совершаемые SUT к ее зависимостям для получения входных данных.
Понятие моков и стабов связано с принципом command-query separation (CQS). Принцип CQS гласит, что каждый метод должен быть либо командой, либо запросом, но не обоими.
Команды - это методы, которые вызывают побочные эффекты и не возвращают никакого значения. Примеры побочных эффектов включают изменение состояния объекта, изменение файла в файловой системе и т. д.
Запросы, наоборот, не имеют побочных эффектов и возвращают значение.
Другими словами, задавая вопрос, вы не должны менять ответ. Код, который поддерживает такое четкое разделение, становится легче для чтения. Тестовые двойники, заменяющие команды, становятся моками, и, соответственно, тестовые двойники, заменяющие запросы, становятся стабами.
Как уже упоминалось, стабы помогают только эмулировать входящие взаимодействия, а не изучать их. Из этого следует, что вы никогда не должны проверять взаимодействие со стабами. Вызов от SUT к стабу не является частью конечного результата, который выдает SUT. Такой вызов - это всего лишь средство для получения конечного результата; это деталь реализации. Проверка взаимодействий со стабами является распространенным анти-паттерном, который приводит к хрупким тестам. Единственный способ избежать хрупкости тестов - это заставить эти тесты проверять конечный результат (который в идеале должен иметь значение для специалиста в предметной области, а не для программиста), а не детали реализации.
К тестам нужно относиться как к функциональному программированию: при отправке одних и тех же аргументов, мы должны получать ровно тот же результат. Тесты должны быть самодостаточны, нельзя обуславливать вызов некоторого теста предварительным вызовом какого-то другого теста.
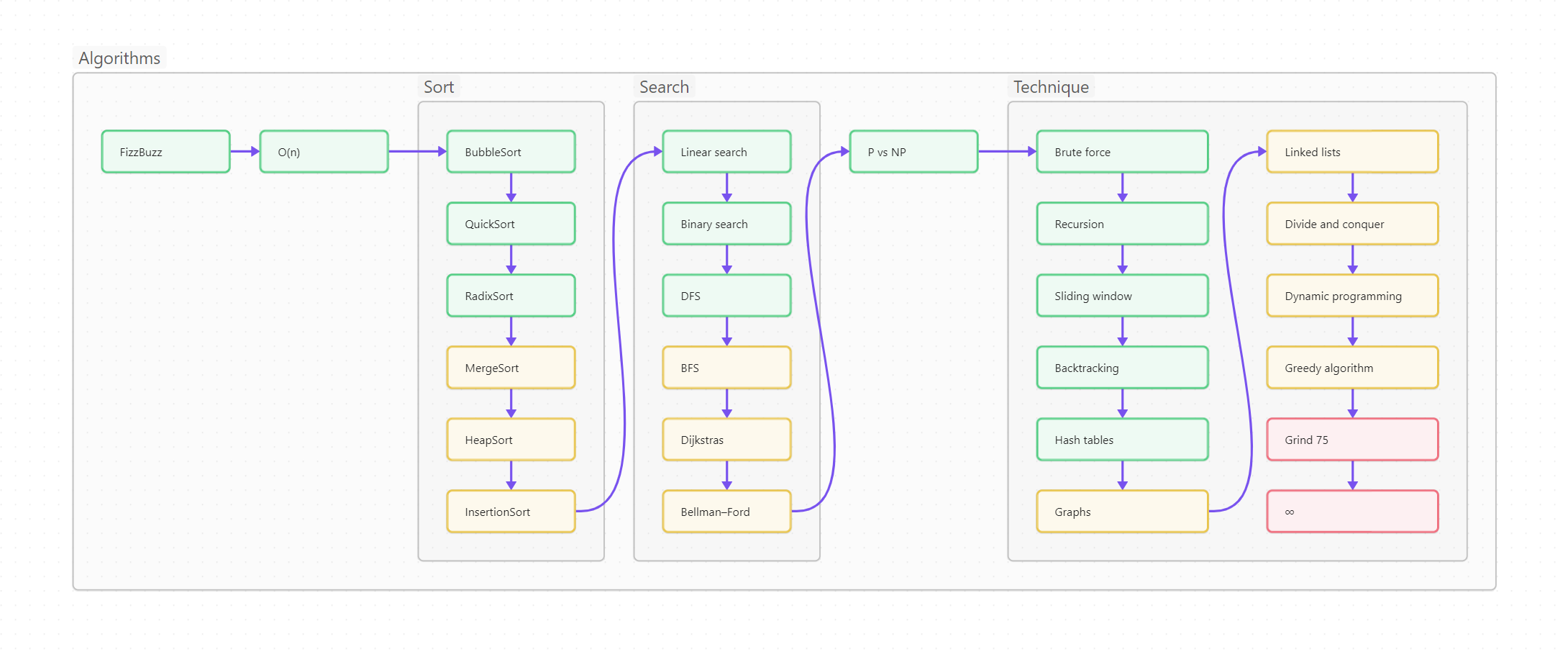
Напишите программу, которая выводит на экран числа от 1 до 100. Вместо чисел, кратных трем, программа должна выводить слово «Fizz», а вместо чисел, кратных пяти — слово «Buzz». Если число кратно и 3, и 5, то программа должна выводить слово «FizzBuzz».
n: int = 100
for i in range(1, n + 1):
if i % 15 == 0:
item = "FizzBuzz"
elif i % 5 == 0:
item = "Buzz"
elif i % 3 == 0:
item = "Fizz"
else:
item = i
print(item, end=" ")1 2 Fizz 4 Buzz Fizz 7 8 Fizz Buzz 11 Fizz 13 14 FizzBuzz 16 17 Fizz 19 Buzz Fizz 22 23 Fizz Buzz 26 Fizz 28 29 FizzBuzz 31 32 Fizz 34 Buzz Fizz 37 38 Fizz Buzz 41 Fizz 43 44 FizzBuzz 46 47 Fizz 49 Buzz Fizz 52 53 Fizz Buzz 56 Fizz 58 59 FizzBuzz 61 62 Fizz 64 Buzz Fizz 67 68 Fizz Buzz 71 Fizz 73 74 FizzBuzz 76 77 Fizz 79 Buzz Fizz 82 83 Fizz Buzz 86 Fizz 88 89 FizzBuzz 91 92 Fizz 94 Buzz Fizz 97 98 Fizz Buzz
Простейший алгоритм, состоит из повторяющихся проходов по сортируемому массиву. В процессе каждого прохода элементы массива сравниваются попарно; элементы, не удовлетворяющие условию сортировки, меняются местами.
def bubblesort(arr):
for i in range(len(arr)):
for j in range(len(arr) - 1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
arr: list = [28, 64, 2, 1, 13, 0]
print(bubblesort(arr))[0, 1, 2, 13, 28, 64]
Идея алгоритма следующая:
- Выбирается опорный элемент, это в первом приближении может быть любой из элементов массива, например, из середины массива.
- Все элементы массива сравниваются с опорным и переставляются так, чтобы образовать новый массив, состоящий из двух последовательных сегментов - элементы меньшие опорного, равные опорному + большие опорного.
- Если длина сегментов больше 1, то рекурсивно выполнить сортировку и для них тоже.
def quicksort(arr):
less = []
equal = []
greater = []
if len(arr) > 1:
pivot = arr[0]
for x in arr:
if x < pivot:
less.append(x)
elif x == pivot:
equal.append(x)
elif x > pivot:
greater.append(x)
return quicksort(less) + equal + quicksort(greater)
else:
return arr
arr: list = [28, 64, 2, 1, 13, 0]
print(quicksort(arr))[0, 1, 2, 13, 28, 64]
Ключевым моментом сортировки слиянием является (как ни странно :) слияние двух массивов. При слиянии массивы сравниваются поэлементо и меньший элемент записывается в результирующий массив; после того, как достигнут конец одного из массивов, в результирующий массив переписывается "хвост" оставшегося массива.
Совместно со слиянием двух массивов используется рекурсивное разбиение сортируемого массива на сегменты меньшего размера.
def mergesort(arr):
if len(arr) < 2:
return arr
result, mid = [], int(len(arr)//2)
y = mergesort(arr[:mid])
z = mergesort(arr[mid:])
while (len(y) > 0) and (len(z) > 0):
if y[0] > z[0]:
result.append(z.pop(0))
else:
result.append(y.pop(0))
return result + y + z
arr: list = [28, 64, 2, 1, 13, 0]
print(mergesort(arr))[0, 1, 2, 13, 28, 64]
Превращаем массив в двоичное дерево за О(n) операций.
Раз за разом преобразуя дерево, получим отсортированный массив.
def heap_sort():
end = len(arr)
start = end // 2 - 1
for i in range(start, -1, -1):
heapify(end, i)
for i in range(end-1, 0, -1):
swap(i, 0)
heapify(i, 0)
def heapify(end,i):
l = 2 * i + 1
r = 2 * (i + 1)
max = i
if l < end and arr[i] < arr[l]:
max = l
if r < end and arr[max] < arr[r]:
max = r
if max != i:
swap(i, max)
heapify(end, max)
def swap(i, j):
arr[i], arr[j] = arr[j], arr[i]
arr: list = [28, 64, 2, 1, 13, 0]
heap_sort()
print(arr)[0, 1, 2, 13, 28, 64]
Каждый новый элемент заносится в выходную последовательность "индивидуально", т. е. каждый раз для добавления нового элемента приходится сдвигать часть массива. Алгоритм медленный, для ускорения вставки можно использовать бинарный поиск.
def insertionsort(arr):
for index in range(1, len(arr)):
currentvalue = arr[index]
position = index
while position > 0 and arr[position - 1] > currentvalue:
arr[position] = arr[position - 1]
position = position - 1
arr[position] = currentvalue
arr: list = [28, 64, 2, 1, 13, 0]
insertionsort(arr)
print(arr)[0, 1, 2, 13, 28, 64]
Комбинированный алгоритм сортировки, сочетающий сортировку вставками, сортировку слиянием и предположение, что в реальном мире данные часто уже частично упорядочены (поиск упорядоченных подмассивов). Стандарт для Python, Java, Swift.
Комбинированный алгоритм сортировки, использует быструю сортировку, плюс, при превышении глубины рекурсии некоторой величины (например, логарифма от числа сортируемых элементов), переключается на пирамидальную сортировку. Стандарт для .NET.
Сортирует только сущности, которые можно разбить на "разряды", имеющие разный вес. Это могут быть, например, целые числа или строки. Соответсвенно, элементы сортируются поразрядно, начиная с разряда, имеющего максимальный вес.
def radixsort(arr: list):
n = len(str(max(arr)))
for k in range(n):
bucket_list=[[] for i in range(10)]
for i in arr:
bucket_list[i // (10**k) % 10].append(i)
arr = sum(bucket_list, []) # Flattening a list of lists to a list
return arr
arr: list = [28, 64, 2, 1, 13, 0]
print(radixsort(arr))[0, 1, 2, 13, 28, 64]
<style> table th:first-of-type { width: 35%; } table th:nth-of-type(2) { width: 35%; } table th:nth-of-type(3) { width: 5%; } table th:nth-of-type(4) { width: 5%; } table th:nth-of-type(5) { width: 5%; } table th:nth-of-type(6) { width: 5%; } table th:nth-of-type(7) { width: 5%; } table th:nth-of-type(8) { width: 5%; } </style>
| Сортировка | Преимущество | Best | Avg | Worst | Mem | Stable | Paral |
|---|---|---|---|---|---|---|---|
| Пузырьковая (Bubble) |
Простейшая реализация | n | n^2 | n^2 | 1 | + | + |
| Быстрая (Quick) |
Хорошее быстродействие в среднем случае | n*logn | n*logn | n^2 | logn | +/- (depends) |
+ |
| Слиянием (Merge) |
Может работать со структурами, к которым возможен только последовательный доступ | n*logn | n*logn | n*logn | n (depends) |
+ | + |
| Пирамидальная (Heap) |
Предсказуемая производительность в наихудшем случае, рекомедуется для почти отсортированных данных | n*logn | n*logn | n*logn | 1 | - | - |
| Вставками (Insertion) |
Рекомедуется для почти отсортированных данных или для малого количества элементов | n | n^2 | n^2 | 1 | + | - |
| Timsort | Комбинированный алгоритм. Стандарт для Python, Java, Swift | n*logn | n*logn | n*logn | logn | - | - |
| Introsort | Комбинированный алгоритм. Стандарт для .Net | n*logn | n*logn | n*logn | logn | - | - |
| Поразрядная (Radix) |
Быстрая сортировка для целых чисел и строк | n*w | n*w | n*w | n+w | +/- (depends) |
+ |
Последовательный поиск элемента в неосортированном массиве
def linear_search(arr, x):
for i in range(len(arr)):
if arr[i] == x:
return i
return None
arr: list = [28, 64, 2, 1, 13, 0]
print(linear_search(arr, 64))1
Работает только с отсортированными массивами. Берется значение из середины массива и сравнивается с искомой величиной. В зависимости от сравнения дальнейший рекурсивный поиск продолжается в середине либо левого, либо правого подмассива.
def binary_search(arr, x):
left, right = 0, len(arr) - 1
while left <= right:
middle = (left + right) // 2
if arr[middle] == x:
return middle
if arr[middle] < x:
left = middle + 1
elif arr[middle] > x:
right = middle - 1
arr: list = [0, 24, 64, 222, 1300, 2048]
print(binary_search(arr, 64))2
Метод обхода графа. Depth-first search (DFS) можно чуть точнее перевести как "поиск в первую очередь в глубину". Соответственно, рекурсивный алгоритм поиска идет «вглубь» графа, насколько это возможно. Есть нерекурсивные варианты алгоритма, разгружающие стек вызовов.

# Using a Python dictionary to act as an adjacency list
graph = {
'5' : ['3','7'],
'3' : ['2', '4'],
'7' : ['8'],
'2' : [],
'4' : ['8'],
'8' : []
}
visited = set() # Set to keep track of visited nodes of graph
def dfs(visited, graph, node): # Function for DFS
if node not in visited:
print (node)
visited.add(node)
for neighbour in graph[node]:
dfs(visited, graph, neighbour)
dfs(visited, graph, '5')5
3
2
4
8
7
В отличие от предыдущего варианта алгоритм Breadth-first search (BFS) перебирает в первую очередь вершины с одинаковым расстоянием от корня, и только потом идет «вглубь».
# https://codereview.stackexchange.com/questions/135156/bfs-implementation-in-python-3
import collections
def breadth_first_search(graph, root):
visited, queue = set(), collections.deque([root])
while queue:
vertex = queue.popleft()
for neighbour in graph[vertex]:
if neighbour not in visited:
visited.add(neighbour)
queue.append(neighbour)
if __name__ == '__main__':
graph = {0: [1, 2], 1: [2], 2: []}
breadth_first_search(graph, 0)deque([])
Находит кратчайшие пути от одной из вершин графа до всех остальных. Алгоритм работает только для графов без отрицательных рёбер.
# https://stackoverflow.com/questions/22897209/dijkstras-algorithm-in-python
nodes = ('A', 'B', 'C', 'D', 'E', 'F', 'G')
distances = {
'B': {'A': 5, 'D': 1, 'G': 2},
'A': {'B': 5, 'D': 3, 'E': 12, 'F' :5},
'D': {'B': 1, 'G': 1, 'E': 1, 'A': 3},
'G': {'B': 2, 'D': 1, 'C': 2},
'C': {'G': 2, 'E': 1, 'F': 16},
'E': {'A': 12, 'D': 1, 'C': 1, 'F': 2},
'F': {'A': 5, 'E': 2, 'C': 16}}
unvisited = {node: None for node in nodes} #using None as +inf
visited = {}
current = 'B'
currentDistance = 0
unvisited[current] = currentDistance
while True:
for neighbour, distance in distances[current].items():
if neighbour not in unvisited: continue
newDistance = currentDistance + distance
if unvisited[neighbour] is None or unvisited[neighbour] > newDistance:
unvisited[neighbour] = newDistance
visited[current] = currentDistance
del unvisited[current]
if not unvisited: break
candidates = [node for node in unvisited.items() if node[1]]
current, currentDistance = sorted(candidates, key = lambda x: x[1])[0]
print(visited){'B': 0, 'D': 1, 'E': 2, 'G': 2, 'C': 3, 'A': 4, 'F': 4}
Как и алгоритм Дейкстры, находит кратчайшие пути от одной из вершин графа до всех остальных, но, в отличие от первого, позволяет работать с графами с ребрами, имеющими отрицательный вес.
| Вид поиска | Структура данных | Avg | Worst | Mem |
|---|---|---|---|---|
| Линейный поиск | Массив | n | n | 1 |
| Бинарный поиск | Отсортированный массив | logn | n | 1 |
| Поиск в глубину (DFS) | Граф | V+E | V | |
| Поиск в ширину (BFS) | Граф | V+E | V | |
| Алгоритм Дейкстры | Граф | (V+E)logV | (V+E)logV | V |
| Алгоритм Беллмана-Форда | Граф | V*E | V*E | V |
Квадратная целочисленная матрица размера V*V, в которой значение элемента a{i, j} равно числу рёбер из i-й вершины в j-ю вершину.
Матрица смежности простого графа (не содержащего петель и кратных рёбер) является бинарной матрицей и содержит нули на главной диагонали.
Способ представления графа, в которой указываются связи между инцидентными элементами графа (ребрами и вершинами). Столбцы матрицы соответствуют ребрам, строки — вершинам. Ненулевое значение в ячейке матрицы указывает связь между вершиной и ребром (их инцидентность). Если связи между вершиной и ребром нет, то в соответствующую ячейку ставится «0».
В случае ориентированного графа каждой дуге ставится в соответствующем столбце: 1 в строке вершины x и -1 в строке вершины y.
Самый распространенный формат хранения графа. Способ представления графа в виде коллекции списков вершин. Каждой вершине графа соответствует список, состоящий из «соседей» этой вершины.
Варианты:
• использование хеш-таблицы для ассоциации каждой вершины со списком смежных вершин;
• вершины представлены числовым индексом в массиве, каждая ячейка массива ссылается на однонаправленный связанный список соседних вершин;
• специальные классы вершин и рёбер, каждый объект вершины содержит ссылку на коллекцию рёбер, каждый объект ребра содержит ссылки на исходящую и входящую вершины.
Список инцидентности похож на список смежности, только с той разницей, что в i-ой строке записываются номера ребер, инцидентных данной i-ой вершине.
| Метод | Mem | Add V | Add E | Remove V | Remove E | Проверка смежн. V |
|---|---|---|---|---|---|---|
| Матрица смежности (Adjacency matrix) |
V^2 | V^2 | 1 | V^2 | 1 | 1 |
| Матрица инцидентности (Incidence matrix) |
V*E | V*E | V*E | V*E | V*E | E |
| Список смежности (Adjacency list) |
V+E | 1 | 1 | V+E | E | V |
| Список инцидентности (Incidence list) |
V+E | 1 | 1 | E | E | E |
Нотация O - характеристика асимптотической сложности алгоритма без учета константы.
n! >> 2^n >> n^3 >> n^2 >> nlogn >> n >> logn >> 1
Задачи класса P — реально вычислимые задачи (тезис Кобэма), решаются за полиномиальное время.
NP-полные задачи — не разрешимы за полиномиальное время, но могут быть сведены к задачам разрешимости (да/нет), которые, в свою очередь, решаются за полиномиальное время.
Разделяй и властвуй (divide and conquer) — способ решения сложных задач путём рекурсивного разбиения решаемой задачи на две или более подзадачи того же типа, но меньшего размера, и комбинировании их решений для получения ответа к исходной задаче; разбиения выполняются до тех пор, пока все подзадачи не окажутся элементарными.
Динамическое программирование — способ решения сложных задач путём разбиения их на более простые подзадачи. Он применим к задачам со структурой, выглядящей как набор перекрывающихся подзадач, сложность которых меньше исходной. Ключевая идея: как правило, чтобы решить поставленную задачу, требуется решить отдельные части задачи (подзадачи), после чего объединить решения подзадач в одно общее решение. Часто многие из этих подзадач одинаковы. Подход динамического программирования состоит в том, чтобы решить каждую подзадачу только один раз, сократив тем самым количество вычислений. Это особенно полезно в случаях, когда число повторяющихся подзадач экспоненциально велико.ы
Жадный алгоритм (greedy algorithm) — алгоритм, который на каждом шагу делает локально наилучший выбор в надежде, что итоговое решение будет оптимальным.
Как определить, даст ли жадный алгоритм оптимальное решение? В соответствии с теоремой Радо-Эдмондса, если система является матроидом, то для произвольной весовой функции градиентный алгоритм всегда находит точное решение задачи. Следовательно, если доказать, что объект является матроидом, то жадный алгоритм будет выдавать оптимальный вариант.
Жадные алгоритмы проще и быстрее алгоритмов на базе динамического программирования.
Различие межде жадными алгоритмами и динамическим программированием можно пояснить так: на каждом шаге жадный алгоритм берет "самый жирный кусок", а потом уже пытается сделать наилучший выбор среди оставшихся, каковы бы они ни были; алгоритм динамического программирования принимает решение, просчитав заранее последствия для всех вариантов.
Рекурсия – определение функции через саму себя. Логика рекурсивной функции как правило состоит из двух ветвей. Длинная ветвь вызывает эту же функцию с другими параметрами, чтобы накопить результат. Короткая ветвь определяет критерий выхода из рекурсии.
Рекурсия упрощает код и делает его декларативным. Рекурсия поощряет мыслить функционально и избегать побочных эффектов.
Неоптимизированная рекурсия приводит к накладным расходам ресурсов. При большом количестве итераций можно превысить лимит на число рекурсивных вызовов (recursion depth limit reached).
Особый вид рекурсии, когда функция заканчивается вызовом самой себя без дополнительных операторов. Когда это условие выполняется, компилятор разворачивает рекурсию в цикл с одним стек-фреймом, просто меняя локальные переменные от итерации к итерации.
Так, классическое определение рекурсивного факториала return N * fact(N - 1) не поддерживает хвостовую рекурсию, потому что для каждого стек-фрейма придется хранить текущее значение N.
Чтобы сделать рекурсии хвостовой, добавляют параметры-аккумуляторы. Благодаря им функция знает о своем текущем состоянии. Пусть параметр acc по умолчанию равен 1. Тогда запись с хвостовой рекурсией будет выглядеть так:
def fact(N, acc=1):
if N == 1:
return acc
else:
return fact(N - 1, acc * N)- Метод скользящего окна (Sliding Window)
- Метод двух указателей (Two Pointers)
- Нахождение цикла (Fast & Slow Pointers)
- Интервальное слияние (Merge Intervals)
- Цикличная сортировка (Cyclic Sort)
- In-place Reversal для LinkedList (In-place Reversal of a LinkedList)
- Поиск в ширину (Tree Breadth-First Search)
- Поиск в глубину (Tree Depth First Search)
- Две кучи (Two Heaps)
- Подмножества (Subsets)
- Модифицированный бинарный поиск (Modified Binary Search)
- Побитовое исключающее ИЛИ (Bitwise XOR)
- Наибольшие K элементов (Top K Elements)
- K-образное слияние (K-way Merge)
- Задача о рюкзаке 0-1 (0/1 Knapsack)
- Задача о неограниченном рюкзаке (Unbounded Knapsack)
- Числа Фибоначчи (Fibonacci Numbers)
- Наибольшая последовательность-палиндром (Palindromic Subsequence)
- Наибольшая общая подстрока (Longest Common Substring)
- Топологическая сортировка (Topological Sort)
- Чтение префиксного дерева (Trie Traversal)
- Количество островов в матрице (Number of Island)
- Метод проб и ошибок (Trial & Error)
- Система непересекающихся множеств (Union Find)
- Задача: найти уникальные маршруты (Unique Paths)
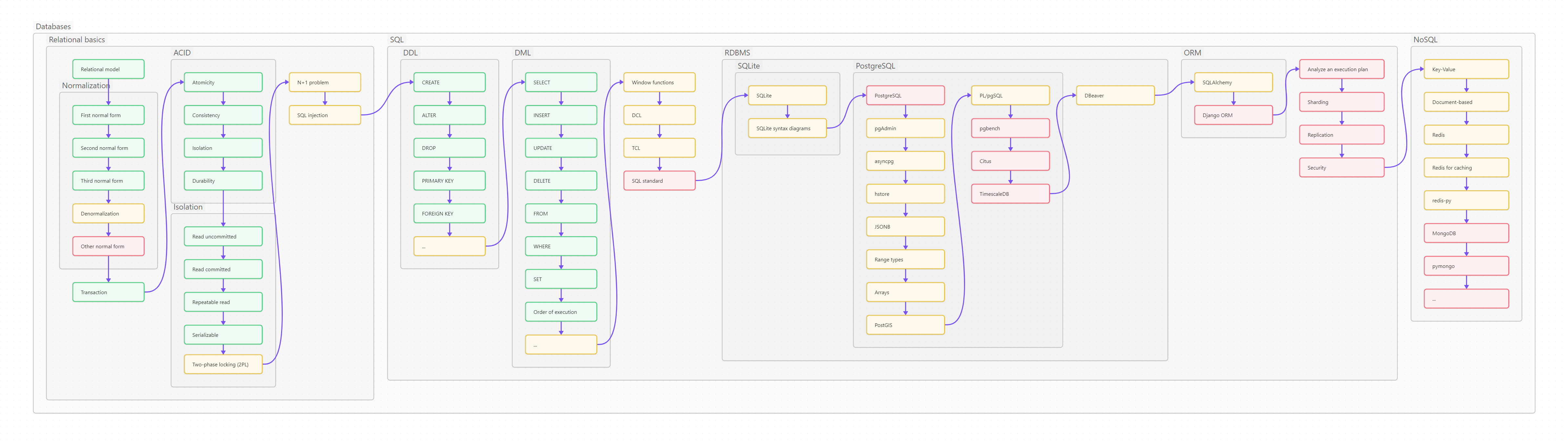
Реляционная модель данных (РМД) основана на математическом понятии отношение (relation), которое неформально можно толковать как "таблица". Соответственно, реляционную модель данных можно упрощенно воспринимать как "табличную модель данных", т. е. построенную на основе двумерных таблиц, состоящих из срок и столбцов.
Работая с реляционной БД, программисту не нужно заботиться о низкоуровневом доступе к данным, достаточно описать, что нужно получить, а как именно — описывать не нужно, эту работу берет на себя БД.
Транзакция — неделимая последовательность действий, обеспечивает выполнение либо всех действий из последовательности, либо ни одного. Если в ходе выполнения транзакции произошел сбой, состояние системы должно быть возвращено к исходному, уже выполненные действия должны быть отменены. Канонический пример — списывание денег с одного счета и зачисление на другой, для чего необходимы два процесса проведения изменений, которые гарантированно должны выполниться или не выполниться вместе.
Фантомное чтение (phantom reads) — одна транзакция в ходе своего выполнения несколько раз выбирает множество строк по одним и тем же критериям. Другая транзакция в интервалах между этими выборками добавляет строки или изменяет столбцы некоторых строк, используемых в критериях выборки первой транзакции, и успешно заканчивается. В результате получится, что одни и те же выборки в первой транзакции дают разные множества строк.
Неповторяющееся чтение (non-repeatable read) — при повторном чтении в рамках одной транзакции ранее прочитанные данные оказываются изменёнными.
«Грязное» чтение (dirty read) — чтение данных, добавленных или изменённых транзакцией, которая впоследствии не подтвердится (откатится);
Потерянное обновление (lost update) — при одновременном изменении одного блока данных разными транзакциями теряются все изменения, кроме последнего.
Выбор уровня изоляции транзакций - фактически, выбор между скоростью работы и обеспечением согласованности данных, т. к. при выполнении параллельных транзакций в СУБД всегда допускается получение несогласованных данных, и разработчик должен найти баланс между количеством параллельных транзакций и согласованностью данных.
Стандарт SQL-92 определяет шкалу из четырёх уровней изоляции: Read uncommitted, Read committed, Repeatable read, Serializable. Первый из них является самым слабым, последний — самым сильным, каждый последующий включает в себя все предыдущие.
Read uncommitted (чтение незафиксированных данных)
Низший (первый) уровень изоляции. Если несколько параллельных транзакций пытаются изменять одну и ту же строку таблицы, то в окончательном варианте строка будет иметь значение, определенное всем набором успешно выполненных транзакций. При этом возможно считывание не только логически несогласованных данных, но и данных, изменения которых ещё не зафиксированы, т. к. транзакции, выполняющие только чтение, при данном уровне изоляции никогда не блокируются. Данные блокируются на время выполнения команды записи, что гарантирует, что команды изменения одних и тех же строк, запущенные параллельно, фактически выполнятся последовательно, и ни одно из изменений не потеряется.
Read committed (чтение фиксированных данных)
Большинство СУБД, в частности, Microsoft SQL Server, PostgreSQL и Oracle, по умолчанию используют именно этот уровень. На этом уровне обеспечивается защита от чтения промежуточных данных, тем не менее, в процессе работы одной транзакции другая может быть успешно завершена и сделанные ею изменения зафиксированы. В итоге первая транзакция будет работать с другим набором данных.
Метод read committed реализуется либо при помощи блокировки данных на чтение во время записи (теряем время), либо на хранении копии данных, снятой до начала записи (теряем ОЗУ).
Repeatable read (повторяющееся чтение)
Уровень, при котором читающая транзакция блокирует изменения данных, которые были ею ранее прочитаны. При этом никакая другая транзакция не может изменять данные, читаемые текущей транзакцией, пока та не окончена.
Serializable (упорядочивание)
Самый высокий уровень изолированности; транзакции полностью изолируются друг от друга, каждая выполняется так, как будто параллельных транзакций не существует. Только на этом уровне параллельные транзакции не подвержены эффекту «фантомного чтения».
<style> table th:first-of-type { width: 20%; } table th:nth-of-type(2) { width: 20%; } table th:nth-of-type(3) { width: 20%; } table th:nth-of-type(4) { width: 20%; } table th:nth-of-type(5) { width: 20%; } </style>| Уровень изоляции | Фантомное чтение | Неповторяющееся чтение | «Грязное» чтение | Потерянное обновление |
|---|---|---|---|---|
| Отсутствие изоляции | + | + | + | + |
| Read uncommitted | + | + | + | - |
| Read committed | + | + | - | - |
| Repeatable read | + | - | - | - |
| Serializable | - | - | - | - |
проблема N + 1
SQL-инъекции
SQL - декларативный (описательный, непроцедурный) язык, стандарт для работы с данными во всех реляционных СУБД.
Операторы SQL традиционно делят на:
операторы определения данных (data definition language, DDL),
операторы манипулирования данными (data manipulation language, DML) и
операторы управления привилегиями доступа (data control language, DCL).
SQLite
Server-less database engine that stores each database into a separate file.
Opens a connection to the database file. Creates a new file if path doesn't exist.
import sqlite3 = sqlite3.connect() # Also ':memory:'. .close() # Closes the connection.
Returned values can be of type str, int, float, bytes or None.
= .execute('') # Can raise a subclass of sqlite3.Error. = .fetchone() # Returns next row. Also next(). = .fetchall() # Returns remaining rows. Also list().
.execute('') # Can raise a subclass of sqlite3.Error. .commit() # Saves all changes since the last commit. .rollback() # Discards all changes since the last commit.
with : # Exits the block with commit() or rollback(), .execute('') # depending on whether any exception occurred.
- Passed values can be of type str, int, float, bytes, None, bool, datetime.date or datetime.datetime.
- Bools will be stored and returned as ints and dates as ISO formatted strings.
.execute('', <list/tuple>) # Replaces '?'s in query with values. .execute('', <dict/namedtuple>) # Replaces ':'s with values. .executemany('', <coll_of_above>) # Runs execute() multiple times.
Values are not actually saved in this example because 'conn.commit()' is omitted!
conn = sqlite3.connect('test.db') conn.execute('CREATE TABLE person (person_id INTEGER PRIMARY KEY, name, height)') conn.execute('INSERT INTO person VALUES (NULL, ?, ?)', ('Jean-Luc', 187)).lastrowid 1 conn.execute('SELECT * FROM person').fetchall() [(1, 'Jean-Luc', 187)]
SQLite Small. Fast. Reliable. Choose any three.
https://sqlite.org/index.html https://github.com/sqlite/sqlite https://habr.com/ru/post/149356/ https://github.com/sqlitebrowser/sqlitebrowser
Syntax Diagrams https://www.sqlite.org/syntaxdiagrams.html
Has a very similar interface, with differences listed below.
from mysql import connector
= connector.connect(host=, …) # user=<str>, password=<str>, database=<str>.
= .cursor() # Only cursor has execute() method.
.execute('') # Can raise a subclass of connector.Error.
.execute('', <list/tuple>) # Replaces '%s's in query with values.
.execute('', <dict/namedtuple>) # Replaces '%()s's with values.
- A sequence object that points to the memory of another object.
- Each element can reference a single or multiple consecutive bytes, depending on format.
- Order and number of elements can be changed with slicing.
- Casting only works between char and other types and uses system's sizes and byte order.
= memoryview(<bytes/bytearray/array>) # Immutable if bytes, else mutable. = [] # Returns an int or a float. = [] # Mview with rearranged elements. = .cast('') # Casts memoryview to the new format. .release() # Releases the object's memory buffer.
Каскадные триггеры. Если триггерная функция выполняет команды SQL, эти команды могут заново запускать триггеры.
hstore. Возможность создавать и манипулировать данными с функциональность словаря (dictionary).
JSONB. Парсинг JSON осуществляется однократно, во время записи. Более медленная однократная запись, но более быстрые многократные чтения. По умолчанию рекомендуется использовать JSONB, а не JSON.
Range Types. Никаких больше колонок planned_worktime_start и planned_worktime_end и пляски с операторами сравнения для нахождения других строк, у которых интервал, задаваемый этими колонками пересекается с этой строкой. Всё необходимое уже есть (включая constraints, про которые обещали рассказать в соседнем топике).
Прочие нативные типы: interval, cidr и другие, со встроенными методами работы с ними.
Массивы — нарушение 1-й нормальной формы, но когда всё, что необходимо — это сохранить несколько строчек, то горождение отдельной таблицы с перспективой JOIN'а с ней выглядит совсем непривлекательно.
У PostgreSQL полностью транзакционный DDL, т.е. можно в транзакциях менять схему данных, и эти изменения буду транзакционными. Соответственно, возможны миграции без остановки записи.
PostGIS. Бесплатное расширение для PostgreSQL с открытым исходным кодом для работы с географическими объектами, дополняющее встроенные возможности БД (point, gist). Работает с точками, ломаными линиями, полигонами, растрами, а также использует их для разных операций, например, поиска.
PL/pgSQL. Процедурный язык для PostgreSQL. Функции PL/pgSQL могут использоваться везде, где допустимы встроенные функции. Например, можно создать функции со сложными вычислениями и условной логикой, а затем использовать их при определении операторов или в индексных выражениях.
Полная SQL-совместимость.
Механизм, который неявно задействован при создании точек сохранения и при обработке исключений.
Что такое курсор и зачем он нужен?
Что делает оператор JOIN, какие виды бывают?
Что делает оператор HAVING, примеры?
В каких случаях вы бы предпочли нереляционную БД?
Что такое функциональный индекс?
Команда VACUUM высвобождает пространство, занимаемое «мертвыми» кортежами, что актуально для часто используемых таблиц. При обычных операциях в Postgres кортежи, удаленные или устаревшие в результаты обновления, физически не удаляются, а сохраняются в таблице до очистки.
EXPLAIN ANALYZE – в отличие от просто EXPLAIN не только показывает план выполнения запроса, но и непосредственно выполняет запрос и показывает реальное время выполнения.
Способ работы с результатом запроса в базу данных, который позволяет не загружать весь объем данных в память, позволяет работать с большими объемами данных. Дополнительно углубленно можно поговорить про особенности работы в связке с pgbouncer.
Е. П. Моргунов. PostgreSQL. Основы языка SQL.
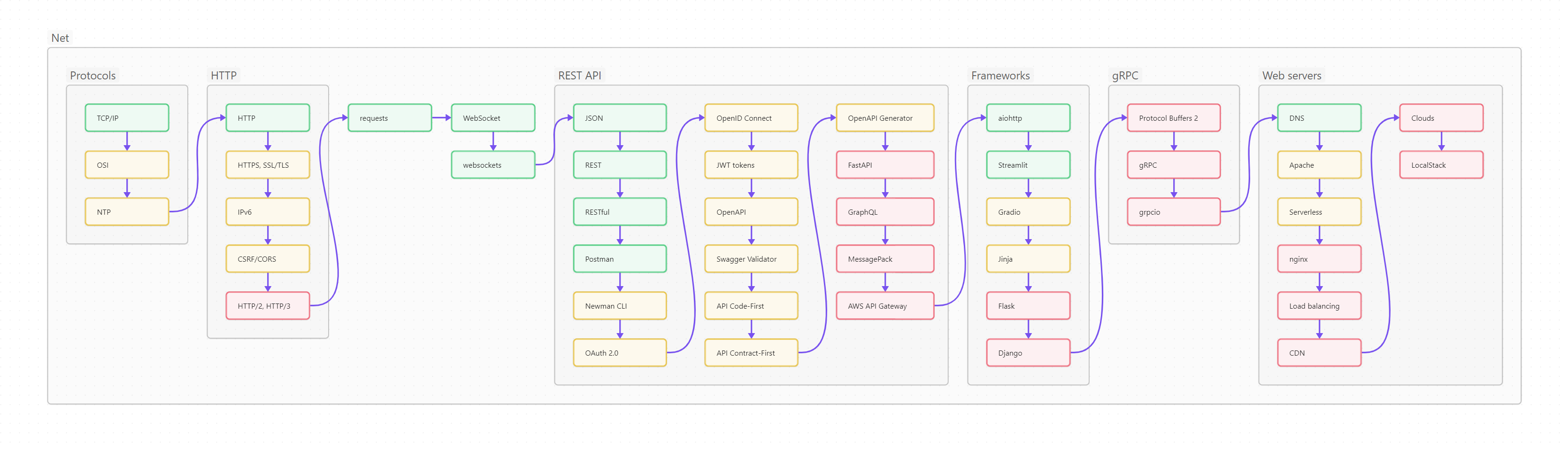
REST, Restfull!!!
HTTP. Какие у него есть методы?!!!
Какие методы в HTTP идемпотентные, а какие — нет?!!!
HTTP и HTTPS!!!
CSRF-token!!!
44 Авторизация и аутентификация
Основы работы интернета. Понимание основных протоколов, моделей OSI/TCP IP. Чаще всего можно задать «простой» вопрос — что происходит «за ширмой», когда в поиске вбиваешь Google.com.
Что такое REST?
REST (Representational state transfer) – соглашение о том, как выстраивать сервисы. Под REST часто имеют в виду т.н HTTP REST API. Как правило, это веб-приложение с набором урлов – конечных точек. Урлы принимают и возвращают данные в формате JSON. Тип операции задают методом HTTP-запроса, например:
GET – получить объект или список объектов POST – создать объект PUT – обновить существующий объект DELETE – удалить объект HEAD – получить метаданные объекта REST-архитектура активно использует возможности протокола HTTP, чтобы избежать т.н. “велосипедов” – собственных решений. Например, параметры кеширования передаются стандартными заголовками Cache, If-Modified-Since, ETag. Авторизациция – заголовком Authentication.
Что такое CSRF?
Сross Site Request Forgery (межсайтовая подделка запроса). Вид уязвимости, когда сайт А вынуждает пользователя выполнить запрос на сайт Б. Это может быть тег img или script для GET-запроса, или форма со специальным атрибутом target.
Чтобы предотвратить уязвимость, сайт Б должен убедиться, что запрос пришел именно с его страницы.
Например, пользователь должен заполнить форму. В нее помещают скрытое поле token – одноразовую последовательность символов. Этот же токен сохраняют в куки пользователя. При отправке формы поле и куки должны совпасть. Способ не является надежным и обходится скриптом.
HTTP Как устроен протокол HTTP?
HTTP – текстовый протокол, работающий поверх TCP/IP. HTTP состоит из запроса и ответа. Их структуры похожи: стартовая строка, заголовки, тело ответа.
Стартовая строка запроса состоит из метода, пути и версии протокола:
GET /index.html HTTP/1.1 Стартовая строка ответа состоит из версии протокола, кода ответа и текстовой расшифровке ответа.
HTTP/1.1 200 OK Заголовки – это набор пар ключ-значение, например, User-Agent, Content-Type. В заголовках передают метаданные запроса: язык пользователя, авторизацию, перенаправление. Заголовок Host должен быть в запросе всегда.
Тело ответа может быть пустым, либо может передавать пары переменных, файлы, бинарные данные. Тело отделяется от заголовков пустой строкой.
Написать raw запрос главной Яндекса
GET / HTTP/1.1 Host: ya.ru
Как клиенту понять, удался запрос или нет?
Проверить статус ответа. Ответы разделены по старшему разряду. Имеем пять групп со следующей семантикой:
1xx: используется крайне редко. В этой группе только один статус 100 Continue. 2xx: запрос прошел успешно (данные получены или созданы) 3xx: перенаправление на другой ресурс 4xx: ошибка по вине пользователя (нет такой страницы, нет прав на доступ) 5xx: ошибка по вине сервера (ошибка в коде, сети, конфигурации) Что нужно отправить браузеру, чтобы перенаправить на другую страницу?
Минимальный ответ должен иметь статус 301 или 302. Заголовок Location указывает адрес ресурса, на который следует перейти.
В теле ответа можно разместить HTML со ссылкой на новый ресурс. Тогда пользователи старых браузеров смогут перейти вручную.
Как управлять кешированием в HTTP?
Существуют несколько способов кешировать данные на уровне протокола.
Заголовки Cache и Cache-Control регулируют сразу несколько критериев кеша: время жизни, политику обновления, поведение прокси-сервера, тип данных (публичные, приватные). Заголовки Last-Modified и If-Modified-Since задают кеширование в зависимости от даты обновления документа. Заголовок Etag кеширует документ по его уникальному хешу. Как кэшируются файлы на уровне протокола?
Когда Nginx отдает статичный файл, он добавляет заголовок Etag – MD5-хеш файла. Клиент запоминает этот хеш. В следующий раз при запросе файла клиент посылает хеш. Сервер проверяет хеш клиента для этого файла. Если хеш не совпадает (файл обновили), сервер отвечает с кодом 200 и выгружает актуальный файл с новым хешем. Если хеши равны, сервер отвечает с кодом 304 Not Modified с пустым телом. В этом случае браузер подставляет локальную копию файла.
Всё просто — нужно использовать nginx всегда, когда есть возможность. Apache — для шаред хостингов, но даже на шаред хостингах часто фронтендом стоит nginx (без возможности настройки), а уже за ним — настраиваемый Apache и настраиваемый PHP.
Архитектура: Apache слздает отдельный поток для каждого соединения, nginx работает по асинхронной модели. Статический контент: nginx в 2 раза быстрее Apache. Динамический контент: ничья. Функционал: Apache разработан только как веб-сервер, nginx может работать и как веб-сервер, так и как прокси-сервер. Настройка: nginx проще в настройке.
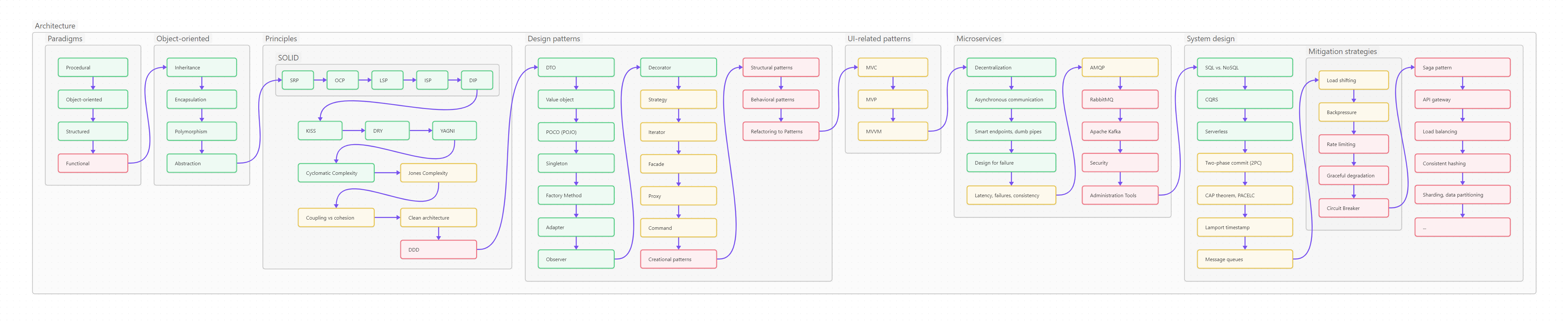
Что такое архитектура
Использование принципов SOLID помогает создавать расширяемые и поддерживаемые системы. Принципы SOLID также можно использовать в качестве ориентиров в процессе рефакторинга кода.
Single-responsibility principle, принцип единственной ответственности. Предполагает проектирование классов, имеющих только одну причину для изменения, позволяет вести проектирование в направлении, противоположном созданию «Божественных объектов». Класс должен отвечать за удовлетворение запросов только одной группы лиц.
Open–closed principle, принцип открытости/закрытости. Классы должны быть закрыты от изменения (чтобы код, опирающийся на эти классы, не нуждался в обновлении), но открыты для расширения (классу можно добавить новое поведение). Вкратце — хочешь изменить поведение класса — не трогай старый код (не считая рефакторинга, т. е. изменение программы без изменения внешнего поведения), добавь новый. Если расширение требований ведет к значительным изменениям в существующем коде, значит, были допущены архитектурные ошибки.
Liskov substitution principle, принцип подстановки Барбары Лисков: поведение наследующих классов должно быть ожидаемым для кода, использующего переменную базового класса. Или, другими словами, подкласс не должен требовать от вызывающего кода больше, чем базовый класс, и не должен предоставлять вызывающему коду меньше, чем базовый класс.
Interface segregation principle, принцип разделения интерфейса. Клиент интерфейса не должен зависеть от неиспользуемых методов. В соответствии с принципом ISP рекомендуется создавать минималистичные интерфейсы, содержащие минимальное количество специфичных методов. Если пользователь интерфейса не пользуется каким-либо методом интерфейса, то лучше создать новый интерфейс, без этого метода.
Dependency inversion principle, принцип инверсии зависимостей. Модули верхнего уровня не должны обращаться к модулям нижнего уровня напрямую, между ними должна быть «прокладка» из абстракций (т. е. интерфейсов). Причем абстракции не должны зависеть от реализаций, реализации должны зависеть от абстракций.
Keep it simple, stupid — принцип проектирования ПО, в соотвтствии с которым простота системы деклариуется как одна из основополагающих ценностей (иногда даже простота объявляется более важной, чем любые другие свойства системы, см. Worse is Better Ричарда Гэбриела), одно из практических приложений «Бритвы Оккама» — не создавай новых сущностей без крайней необходимости.
Don’t repeat yourself (не повторяйся) — принцип, в соответствии с которым изменение любого элемента системы не должно требовать внесения изменений в другие, логически не связанные элементы. Логически же связанные элементы изменяются предсказуемо и единообразно.
You aren't gonna need it (вам это не понадобится) — если в определенном функционале нет потребности прямо здесь и прямо сейчас — не добавляй его. Этим ты не только отнимешь время, необходимое на разработку и тестирование действительного функционала, но и можешь подложить себе мину замедленного действия на будущее, когда контуры развития системы станут более четкими.

https://en.wikipedia.org/wiki/Programming_paradigm
Методика, в соответствии с которой последовательно выполняемые операторы собирают в подпрограммы, то есть более крупные целостные единицы кода
Понимание того, что можно исключить опреатор goto и представть программу в виде иерархической структуры блоков (из трёх базовых управляющих конструкций: последовательность, ветвление, цикл).
Объектно-ориентированное программирование
Методология, основанная на представлении программы в виде совокупности взаимодействующих объектов, каждый из которых является экземпляром определённого класса, а классы образуют иерархию наследования.
Функциональное программирование
Программирование на базе математических функций. Математические функции не являются методами в программном смысле, их лучше всего рассматривать как канал (pipe), преобразующий любое значение, которое мы передаем, в другое значение.
Программный метод становится математической функцией после выполнеия двух требований:
- Он должен быть ссылочно прозрачным (referentially transparent). Ссылочно прозрачная функция всегда дает один и тот же результат, если вы предоставляете ей одни и те же аргументы; Это означает, что такая функция должна работать только со значениями, которые мы передаем, она не должна ссылаться ни на какие глобальноые состояния.
- Сигнатура метода должна передавать всю информацию о возможных входных значениях, которые он принимает, и о возможных результатах, которые он может дать.
Преимущество функционального программирования — относительная простота, так как каждый метод, выполняющий два требования, указанных выше, можно рассматривать и отлаживать в условиях полной изоляции от остальной кодовой базы. Плюс, иммутабельность позволяет компилятору применять более агрессивные методы оптимизации.
Способность компонента базироваться на другом компоненте. Можно создать общий класс, который будет определять характеристики и поведение, свойственные набору связанных объектов.
Сокрытие внутренних данных компонента и деталей его реализации от других компонентов приложения и предоставление набора методов для взаимодействия с ним (API).
Способность компонента выбирать внутреннюю процедуру (метод) исходя из типа данных, принятых в сообщении.
Представление объекта минимальным набором данных и методов с точностью, достаточной для решаемой для решаемой задачи.
Практики
Agile
Scrum
Kanban
- Какие есть семь этапов разработки продукта в Software Development lifecycle
Определение требований Проектирование Конструирование (также «реализация» либо «кодирование») Воплощение Тестирование и отладка (также «верификация») Инсталляция Поддержка
Микросервисы
https://habr.com/ru/post/249183/
Messaging
RabbitMQ Apache Kafka NATS
https://habr.com/ru/company/innotech/blog/698838/
Цитата из статьи:
Выбирая между Kafka и RabbitMQ На самом деле, категорично сравнивать брокеры сообщений очень сложно. У всех существуют свои задачи и области применения. В случае с Apache Kafka и RabbitMQ это немного разный уровень, где лучшего не существует.
Kafka используется для обработки больших объёмов данных, сотен тысяч сообщений в секунду, которые подолгу хранятся на диске и много раз читаются сотнями или даже тысячами подписчиков. Kafka — это легко масштабируемая система, обладающая повышенной отказоустойчивостью, что очень важно в крупных проектах.
RabbitMQ более простой в установке и настройке, успешно справляется с асинхронным обменом данными в микросервисной архитектуре. Не требует дополнительных компонентов и затрат на дисковые ресурсы, так как все сообщения после чтения из очереди удаляются. По сравнению с Kafka обладает большими возможностями по настройке шаблонов обмена сообщениями. Отличный выбор, если нет завышенных требований к отказоустойчивости и пропускной способности.
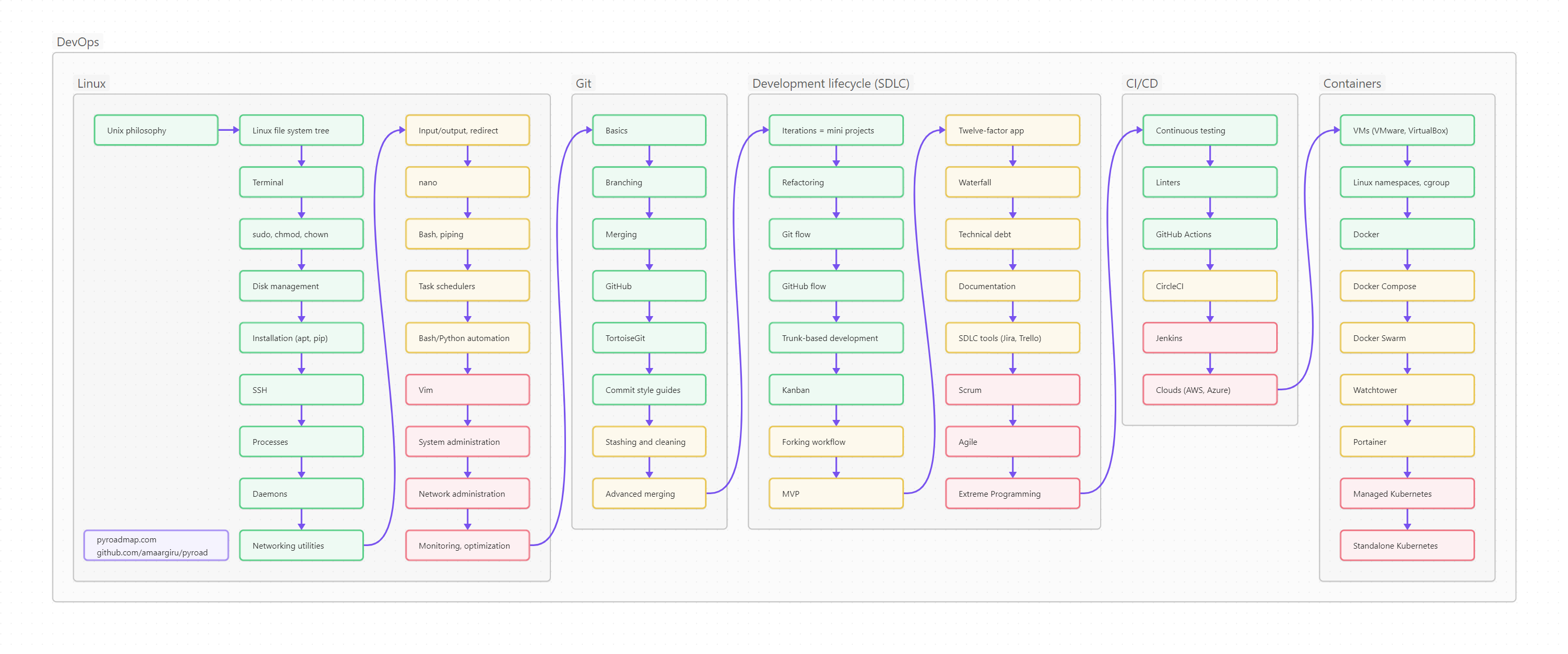

В целом, в настоящее время модель git-flow используется сравнительно редко. Эта модель ветвления основана на предсказуемом, долгосрочном цикле релиза новых версий, а не на выпуске нового кода каждые несколько часов. Git-flow сильно усложняет continuous delivery, когда разработчики выпускают частые обновления путем слияния с мастером (фактически, непосредственно в production) и плохо подходит для проектов, разбитых на сервисы.
Единственный вариант, неплохо подходящий под git-flow — большая команда (20+ человек), планомерно выпускающая несколько параллельных релизов или занимающаяся поддержкой нескольких версий приложения параллельно. В таком случае git-flow действительно может помочь навести порядок.
Магистральная разработка (trunk-based development) фактически является обязательной практикой CI/CD и предполагает небольшие частые обновления главной ветки. Подразумевает ежедневные коммиты, многоуровневое автоматическое тестирование и быструю кеширующую сборку.
git config --global core.editor "'C:/Program Files/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin"
Создать новый репозитарий: git init
Добавить файлы: git add --all
git commit
Добавляем в текстовом файле первой строкой англоязычный заголовок коммита, второй и далее строками можно добавить русскоязычное описание. Сохраняем, закрываем.
Список веток: git branch --list
Создаем новую ветку, переключение на ветку не выполняется: git branch small-update
Переключение на вновь созданную ветку: git checkout small-update
Переключение на ветку master: git checkout master
Слияние веток: git merge small-update
git log --graph --full-history --all --color --pretty=format:"%x1b[31m%h%x09%x1b[32m%d%x1b[0m%x20%s"
Слияние коммитов:
git rebase
squash
Попытка перенести одиночный коммит из ветки в ветку: cherry pick
Правка истории git с риском затереть чужие коммиты: git push origin master --force-with-lease (форсированный push)
Хуки (скрипты на shell'ах или Python), позволяющие: выполнять проверку отправляемого в репозиторий кода на валидность (PEP8, документация и т. д.); выполнять комплексное тестирование проекта; прерывать операцию commit'а в случае обнаружения ошибок и отображать подробный журнал ошибок.
Разумеется, администрирование подразумевает работу в консоли. Ничего сложного в этом нет, в конце-концов, Анджелина Джоли в «Хакерах» и Кэрри-Энн Мосс в «Матрице» прекрасно справились!
CI/CD
Continuous testing GitHub Actions Jenkins
Containers
Docker Kubernetes
Официальная документация Python docs.python.org, включающая The Python Standard Library.
Весьма подробное руководство (совсем уж базовый синтаксис не включен): Comprehensive Python Cheatsheet.
Руководство с включением базового синтаксиса: Python Cheatsheet. Включает практические Jupiter Notebooks.
Сипсок библиотек и фреймворков: Awesome Python.
Около-питоновские практические советы (pip, virtualenv, pyInstaller и т. д.): "The Hitchhiker’s Guide to Python".
Мануал для начинающих дата-сайентистов: Joel Grus, "Data Science from Scratch".
Руководство для начинающих: "Python Notes for Professionals".
Руководство для опытных программистов: "Python 3 Patterns, Recipes and Idioms".
Архитектурные паттерны: Harry Percival & Bob Gregory, "Architecture Patterns with Python".
Статья 2010 года, положившая начало распростанения git-flow. Сам автор сделал в 2020 дополнение к статье, где рекомендует командам, придерживающихся continuous delivery, переходить на GitHub flow: A successful Git branching model.
git-flow (компания Atlassian изменила текст страницы, теперь там размещены рекомендации перехода на магистральную разработку): git-flow.
Критика git-flow.
GitHub flow.
Ну что ж, дорогие читатели, теперь, после прочтения этого краткого путеводителя по языку программирования Python и окружающей его инфраструктуре, надеюсь, что вы закрыли некоторые лакуны в своих знаниях, даже если до этого обладали околонулевым опытом программирования. Еще больше надеюсь, что у вас появилась масса других вопросов, уже более оформившихся и структурированных, а желание немедленно сесть и что-нибудь эдакое запрограммировать только возросло.
Разумеется, изучение кратких спецификаций строительных блоков является только первым этапом любого процесса созидания, но за год-полтора постоянной практики вы вполне можете заложить не просто фундамент, а дойти, скажем так, до уровня пола. И когда вам по рабочей надобности или просто в тексте вакансии будет встречаться какая-то неизвестная аббревиатура, вроде RabbitMQ, ELK Stack или Kubernetes, вы, пользуясь накопленным багажом, будете в силах самостоятельно разобраться в их плюсах, минусах и особенностях применения, или, говоря словами классика, «Какой с отбитым углом, с помятым ребром или с приливом — сразу Шухов это видит, и видит, какой стороной этот шлакоблок лечь хочет, и видит то место на стене, которое этого шлакоблока ждет», потому что мутные баззворды превратятся для вас во вполне конкректные, живые технологии.
Напомню, что исходные коды этой статьи в формате Jupiter Notebook лежат на github/amaargiru/pycore, вы всегда можете их дополнить или просто звездануть.
Не хотелось бы затертых фраз про «непростое время», время сейчас попросту тяжелое, гадкое; и, к несчастью, судьба в любой момент может бросить на стол злобного джокера, которого нам нечем будет крыть. Так что если вы испытаваете тягу к... кхм... Тягу к личностному росту и к перемене мест, то сейчас самое время перестать сидеть на попе ровно, ощущая, как литосферные плиты своим неторопливым дрейфом делают вам ненавязчивый массаж.
Попробуйте изменить свою судьбу, только не эмоциональными поступками и всякими резкими телодвижениями, но, напротив, ежедневной кропотливой работой, познанием нового, расширением границ своих знаний. Привыкайте тянуть эту тяжелую сеть, хотя бы и в учебных целях, и рано или поздно в ней забъется живая рыба. �