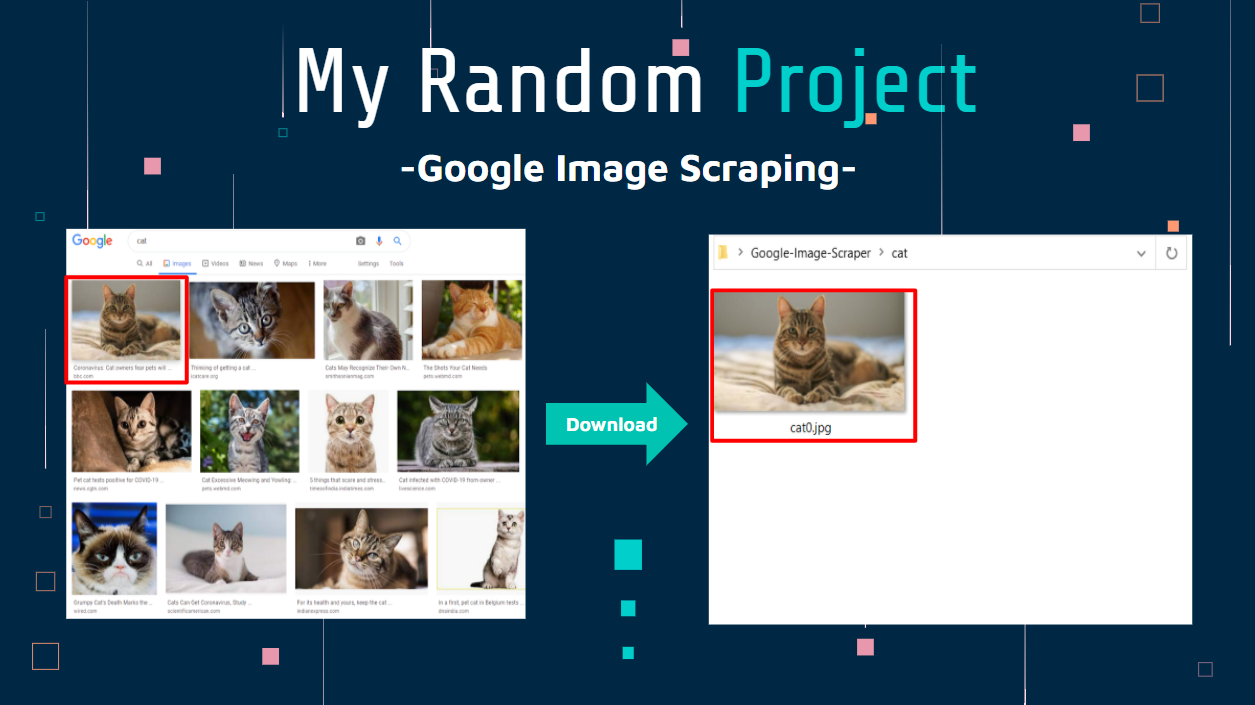
A library to scrape images from websites like Google, Getty and many more in the future.
- conda create --name imagescraper python==3.8.8
- pip install -r requirements.txt
- Download Google Chrome
- Download Google Webdriver based on your Chrome version (See Setup below for more info)
- Open cmd
- Clone the repository (or download)
git clone https://github.com/JJLimmm/Google-Image-Scraper - Install Dependencies
pip install -r requirements.txt - Download the Chrome Webdriver
- Download from here
- Change certain configs in main.py
- line 21 website_list[index] for the website you want to scrape from
- line 24 to add in the names of different objects you want to find
- line 27 for the number of images you want to scrape
- Run the code
python main.py
#Import libraries (Import in other website scrapers in the future)
from GoogleImageScrapper import GoogleImageScraper
from GettyImagesScrapper import GettyImageScraper
import os
from patch import webdriver_executable
#Define file path (Don't change)
webdriver_path = os.path.normpath(os.path.join(os.getcwd(), 'webdriver', webdriver_executable()))
image_path = os.path.normpath(os.path.join(os.getcwd(), 'photos'))
#Website used for scraping:
website_list = ['google', 'getty', 'shutterstock', 'bing']
search_site = website_list[1] #change index number here to select the website you are using
#Add new search key into array ["cat","t-shirt","apple","orange","pear","fish"]
search_keys= ["cat","t-shirt"]
#Parameters
number_of_images = 10
headless = True
min_resolution=(0,0)
max_resolution=(1920,1080)
#Main program
#Choose if using Google or Getty Images Scrapper (or add in other options next time)
for search_key in search_keys:
if search_site == 'google':
image_scrapper = GoogleImageScraper(webdriver_path,image_path,search_key,number_of_images,headless,min_resolution,max_resolution)
if search_site == 'getty':
image_scrapper = GettyImageScraper(webdriver_path,image_path,search_key,number_of_images,headless,min_resolution,max_resolution)
if search_site == 'shutterstock':
image_scrapper = ShutterstockImageScraper(webdriver_path,image_path,search_key,number_of_images,headless,min_resolution,max_resolution)
if search_site == 'bing':
image_scrapper = BingImageScraper(webdriver_path,image_path,search_key,number_of_images,headless,min_resolution,max_resolution)
image_urls = image_scrapper.find_image_urls()
image_scrapper.save_images(image_urls)
#Release resources
del image_scrapper[x] Add Scraping from Getty Images
[ ] Add scraping for shutterstock and bing (In-Progress)
[ ] Streamline all website scrapers into one script (Code Refactoring)
[ ] Support for other website browsers (Firefox, Edge)
[ ] Add in support for multiple image formats (e.g: jpg, png, jpeg) and reformat non-conventional image formats (webp, etc...)
Credits to ohyicong's initial Google Image Scraper
=======