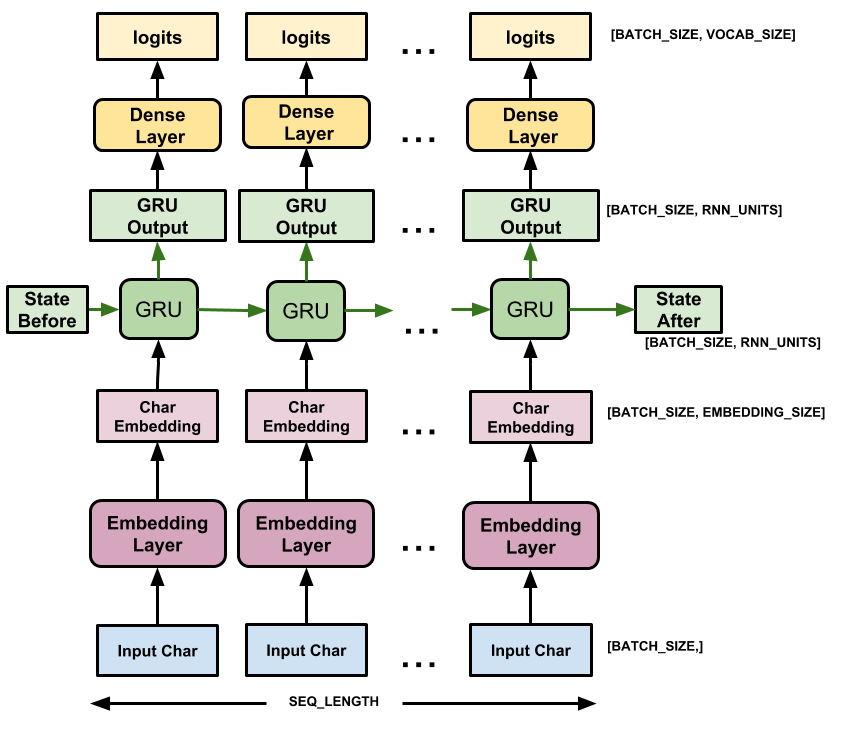
I’ve found that most gloss over text generation and take this stuff at face level without understanding the beauty which lies beneath. The purpose of this is to give you an intuition of what is going on behind the scenes.
Start by doing what’s necessary; then do what’s possible; and suddenly you are doing the impossible. - Francis of Assisi
I’ll be following the approach of this quote :)

The analogies aren’t the best, but then again I haven’t promised mathematical rigour!
P.S: I love maths, so don’t judge me!
I’m sure you’re asking yourself, why do I need this information for understanding LLMs, but I assure you, this will come back later on and is crucial for gaining an intuition :)
In it’s purest form, I would argue that computers store information in the form of binary digits, i.e. as 1s and 0s. They have a processor accepts this(maybe whole or in chunks) information in the form of inputs, does some mathematical stuff, one instruction provided by the user at a time, say foo() on them and spits out an output that is also in the form of 1s and 0s that can be interpreted to arrive at some useful conclusion.
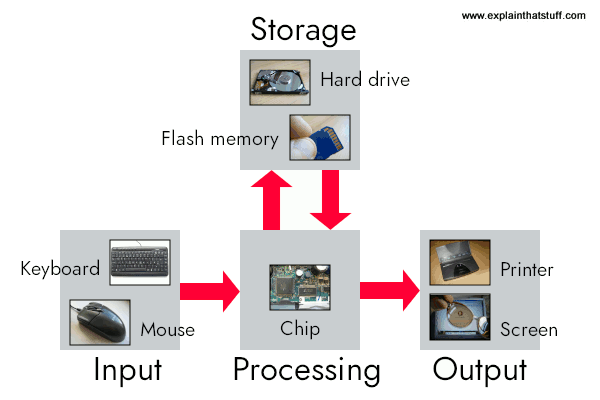
I know it’s another silly question at face value, but I promise you, it it super important for gaining an intuition behind LLMs :)
Say I gave you, the reader a task. The task goes something as follows:
I have bunch of inputs, say InpOutfoo()Outfoo()foo()
inp = data
output = foo(inp)If I were to put this in code as shown above, we could say that given the input and output, figure out how to replicate foo
Say we have another function boo()inputsweightsbiases
We could now reword the problem statement to something like
Given a bunch of inputs, expected outputs, weights and biases, adjust the weights and biases in boo()|output-output'|
inputs = data
output'= boo(inputs,weights,biases)
output = foo(inputs)In an ideal world, we want to ensure that difference(output,output')
If you’ve read through all of that, well good for you, because
[1] Natural language processing (NLP) is an interdisciplinary subfield of computer science and linguistics. It is primarily concerned with giving computers the ability to support and manipulate speech. It involves processing natural language datasets, such as text corpora or speech corpora, using either rule-based or probabilistic (i.e. statistical and, most recently, neural network-based) machine learning approaches. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.
Challenges in natural language processing frequently involve speech recognition, natural-language understanding, and natural-language generation.
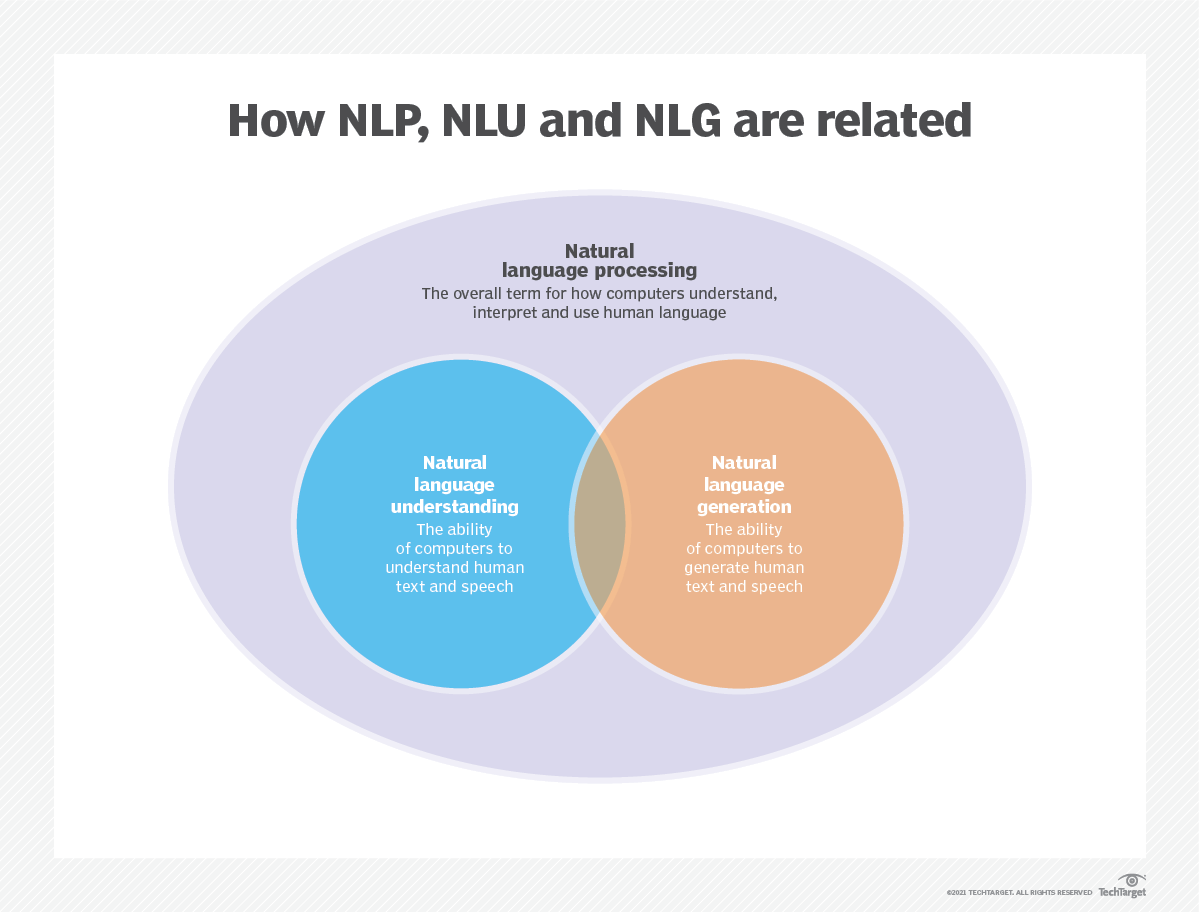
We’ll be focusing on Natural Language generation(NLG)
NLG is a multi-stage process, with each step further refining the data being used to produce content with natural-sounding language. The six stages of NLG are as follows:
Content analysis. Data is filtered to determine what should be included in the content produced at the end of the process. This stage includes identifying the main topics in the source document and the relationships between them.
Data understanding. The data is interpreted, patterns are identified and it’s put into context. Machine learning is often used at this stage.
Document structuring. A document plan is created and a narrative structure chosen based on the type of data being interpreted.
Sentence aggregation. Relevant sentences or parts of sentences are combined in ways that accurately summarize the topic.
Grammatical structuring. Grammatical rules are applied to generate natural-sounding text. The program deduces the syntactical structure of the sentence. It then uses this information to rewrite the sentence in a grammatically correct manner.
Language presentation. The final output is generated based on a template or format the user or programmer has selected.
5. In our case, we are looking at generative AI. Specifically, given some input text, we want a response, also in text which is human readable.
Throwback to what we did in the previous section, i.e. adjust weights and biases of boo() such that it approximates foo()
In our case, since we are looking at generative AI with NLP.
Specifically, we have an imginary function foo(), which given some input text, gives us a relevant response, also in text which is human readable. Find a function boo()
Remember how I said that there are many ways of going about finding the weights and biases such that output-output' is as small as possible? Yeah, from this point onwards, each chapter is one such method. They get progressively better at this. In other words, output-output' keeps getting smaller :)
6. Hidden Markovian Models
Let’s take a step back and think about the problem.
We are trying to generate coherent sentences that are relevant to us.
Well, if we have a sample text of what we expect from our function boo()
This is called a co-occurence matrix :)
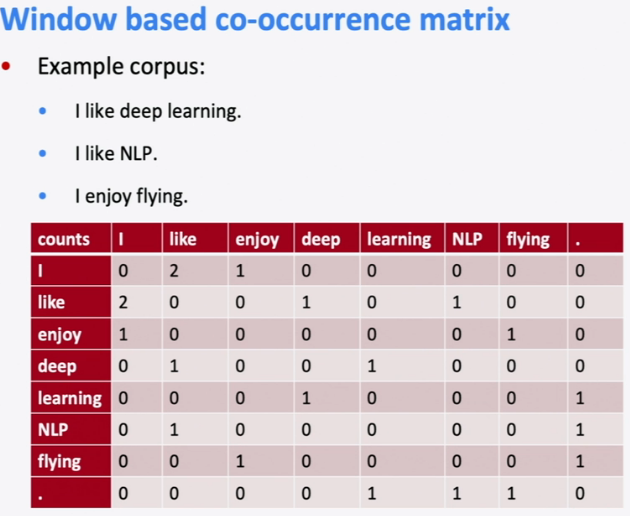
We can now use this information to generate sentences.
Mathematically, this idea can be represented using Markov models.
In this, we’ll specifically be dealing with Hidden Markov models.
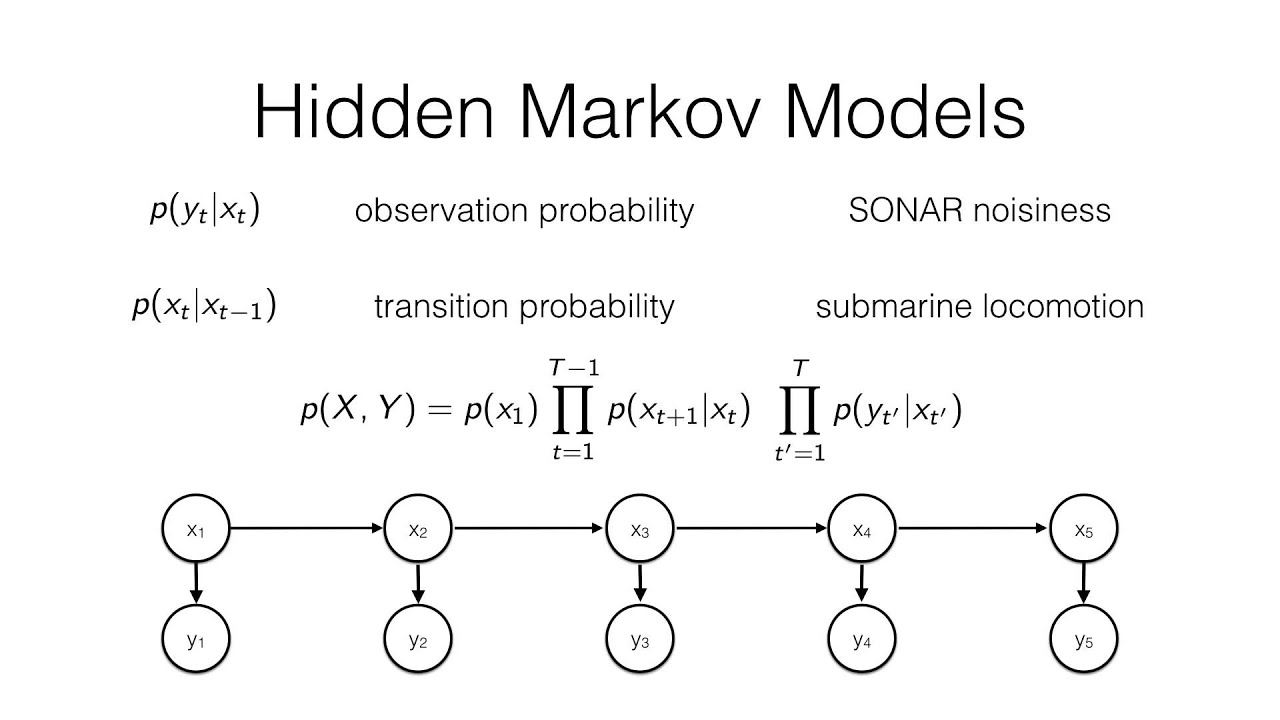

I’ve added two text generation models that use HMMs. You can find them
Okay, that’s a good start, sort off…
In this case, we have a few issues
-
The generated text is as good as the input corpus (garbage in garbage out)
More importantly,
-
We find the need to create multiple n-gram Markov Chains (high order model) to captue the context.
Going back to what we discussed in the, we find a problem. This is going to cost us a ton of resources computationally :P
Sure, it may get better eventually, and we could optimize our work by doing stuff in parallel and foo, but, what’s the use of the model if it takes 20000 years to get decent at generation of coherent sentences?
Can we do better than this? Yes, bring on RNNs
Well before there were RNNs, we had simple Feed Forward Neural networks :)
While these don’t add much value to our discussion about solving the text generation problem, they are important for understanding RNNs!
-
A feed forward neural network consists, surprise-surprise, neurons!
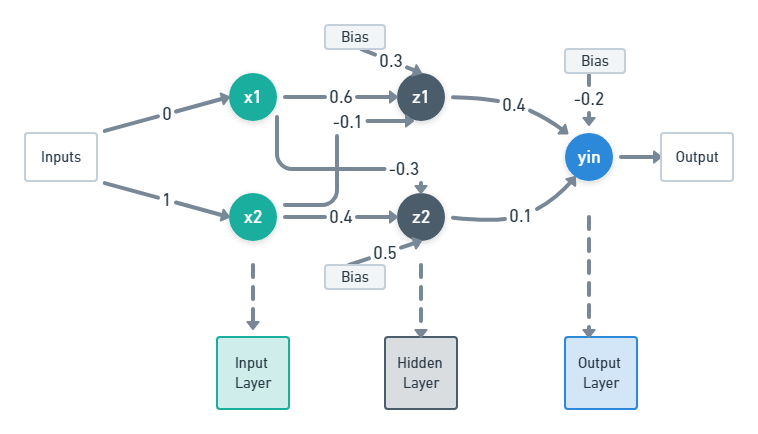
Well, throw back to out function boo()
Right now, we aren’t concerned with the exact structure of our Neural network. What we are concerned with is generating coherent text!
The reason I said that FFNs aren’t great for our task is cause they are a one time thing.
The output of our network only depends upton the input you feed into it at the time of execution and does not depend upon past inputs.
This causes a ton of problems when we are trying to model something the is sequential, such as language!
As we have previously discussed, the past word is important for us to predict the next word. How do we get around this in an FFN? Well we add a recurrent element to the Network. Let’s call this element history
Remember how I said boo()
We add the historic term histboo(inputs, weights, biases, hist)
What’s the purpose of hist? To track/model the current state of the RNN. Yes, we now have ourselves a fancy(and very powerful) state machine :)
Well, they’re the big brother of Markovian Models :) Sort off! I’d argue that an RNN is a more specific version of a Markov Model; A Markov Model with a fancy hat on????
It is difficult for me to explain what I mean by this without additional information. Heck, this is not a book, it’s just a repository!