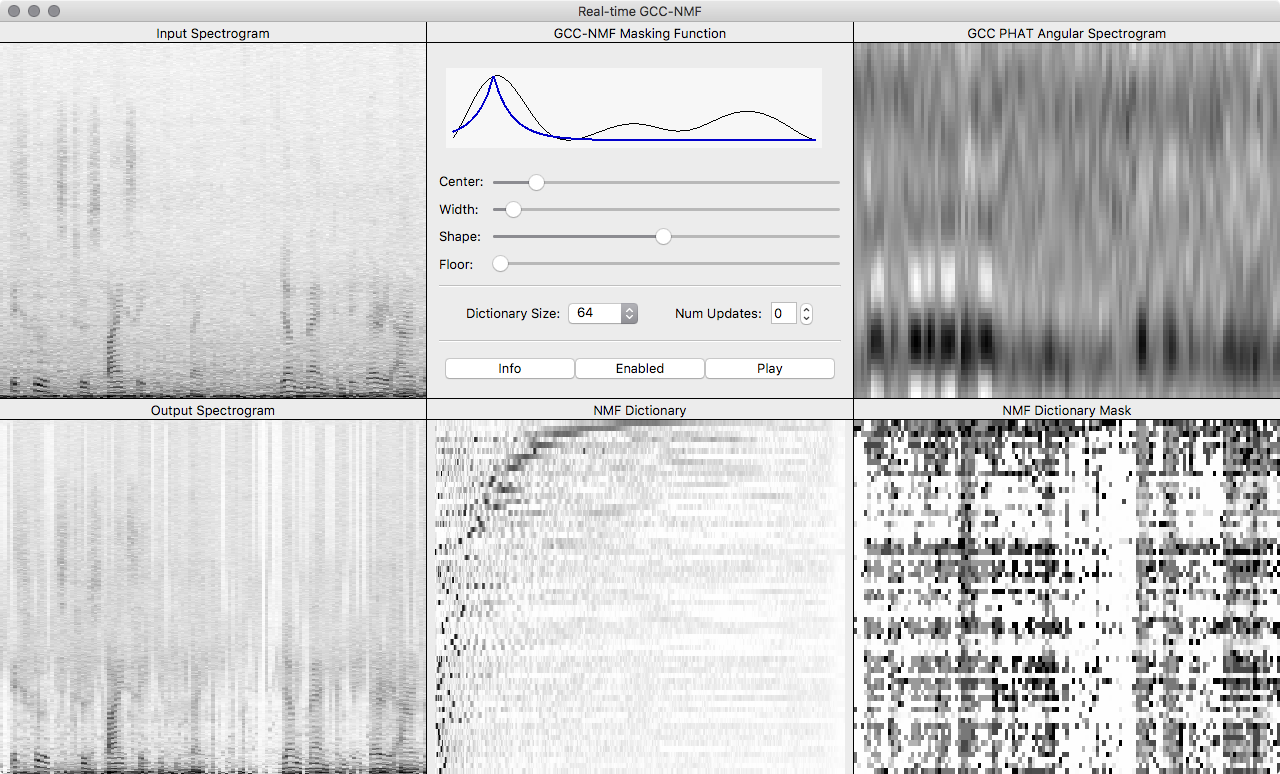
GCC-NMF is a blind source separation algorithm that combines the GCC spatial localization method with the NMF unsupervised dictionary learning algorithm. GCC-NMF has been applied to stereo speech separation and enhancement in both offline and real-time settings, though it is a generic source separation algorithm and could be applicable to other types of signals.
This GitHub repository is home to open source demonstrations in the form of iPython Notebooks:
- Offline Speech Separation
- Offline Speech Enhancement
- Online Speech Enhancement
- Low Latency Speech Enhancement
and standalone Python executables:
serving as demonstrations of material presented in the following papers:
- Sean UN Wood and Jean Rouat, Speech Separation with GCC-NMF, Interspeech 2016.
DOI: 10.21437/Interspeech.2016-1449 - Sean UN Wood, Jean Rouat, Stéphane Dupont, Gueorgui Pironkov, Speech Separation and Enhancement with GCC-NMF, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 4, pp. 745–755, 2017.
DOI: 10.1109/TASLP.2017.2656805 - Sean UN Wood and Jean Rouat, Real-time Speech Enhancement with GCC-NMF, Interspeech 2017.
- Sean UN Wood and Jean Rouat, Real-time Speech Enhancement with GCC-NMF: Demonstration on the Raspberry Pi and NVIDIA Jetson, Interspeech 2017 Show and Tell Demonstrations.
- Sean UN Wood and Jean Rouat, Towards GCC-NMF Speech Enhancement for Hearing Assistive Devices: Reducing Latency with Asymmetric Windows, 1st International Workshop on Challenges in Hearing Assistive Technology, CHAT 2017.
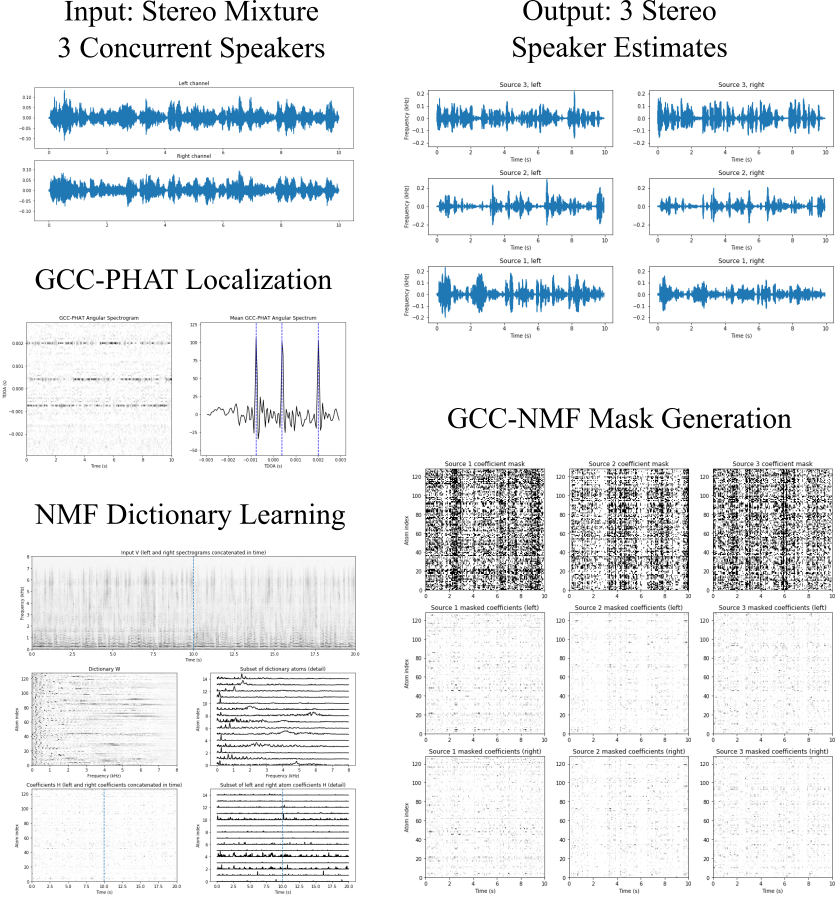
The Offline Speech Separation iPython notebook shows how GCC-NMF can be used to separate multiple concurrent speakers in an offline fashion. The NMF dictionary is first learned directly from the mixture signal, and sources are subsequently separated by attributing each atom at each time to a single source based on the dictionary atoms' estimated time delay of arrival (TDOA). Source localization is achieved with GCC-PHAT.
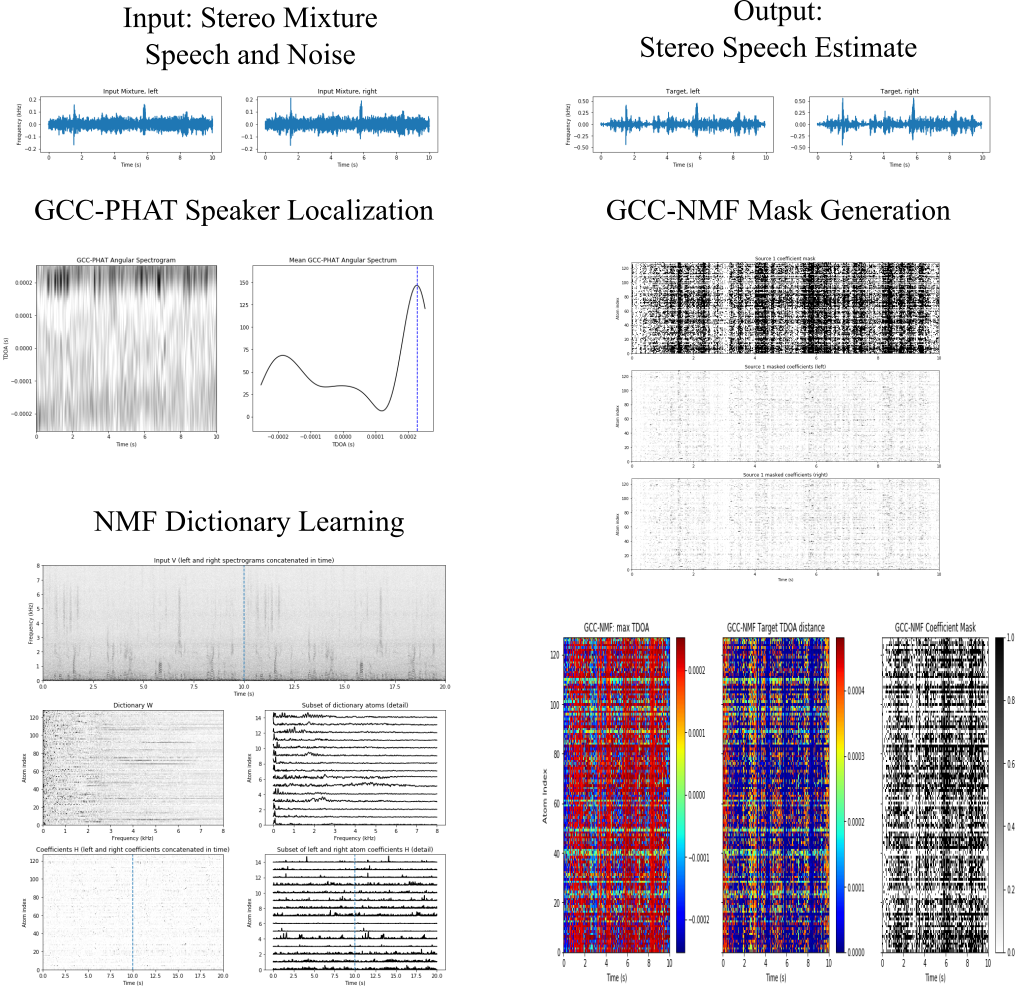
The Offline Speech Enhancement iPython notebook demonstrates how GCC-NMF can can be used for offline speech enhancement, where instead of multiple speakers, we have a single speaker plus noise. In this case, individual atoms are attributed either to the speaker or to noise at each point in time base on the the atom TDOAs as above. The target speaker is again localized with GCC-PHAT.
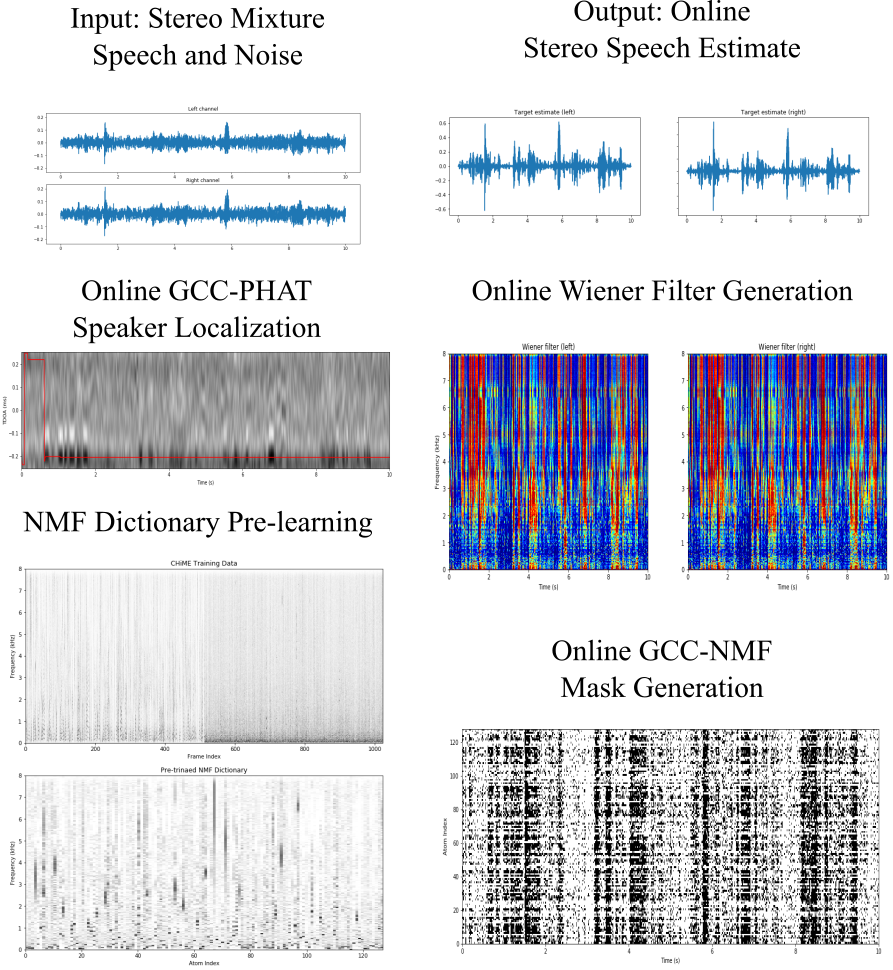
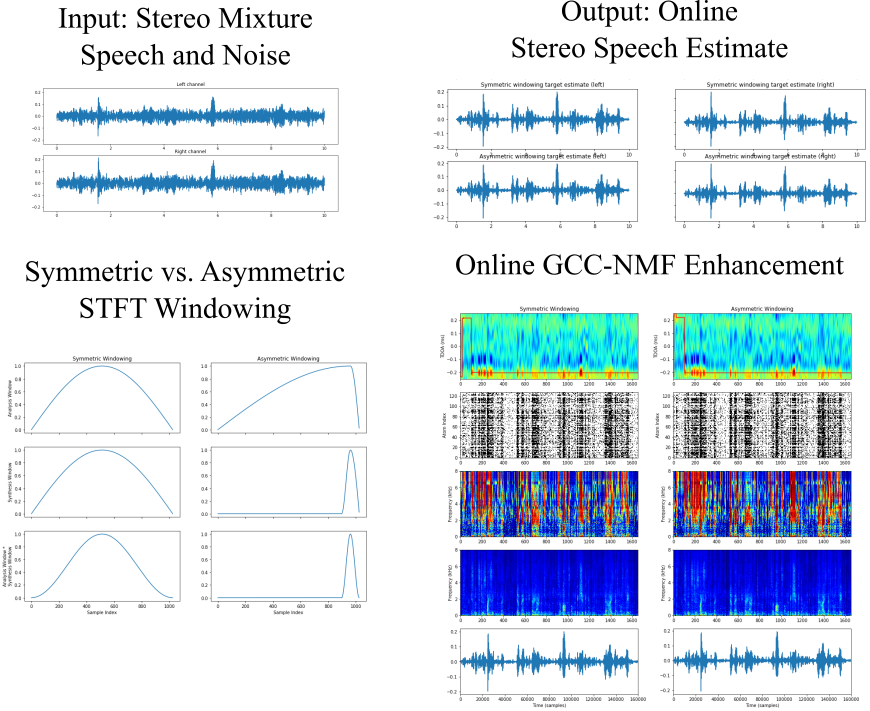
The Online Speech Enhancement iPython notebook demonstrates an online variant of GCC-NMF that works in a frame-by-frame fashion to perform speech enhancement in real-time. Here, the NMF dictionary is pre-learned from a different dataset than used at test time, NMF coefficients are inferred frame-by-frame, and speaker localization is performed with an accumulated GCC-PHAT method.
In the Low Latency Speech Enhancement iPython notebook we extend the online GCC-NMF approach to reduce algorithmic latency via asymmetric STFT windowing strategy. Long analysis windows maintain the high spectral resolution required by GCC-NMF, while short synthesis windows drastically reduce algorithmic latency with little effect on speech enhancement quality. Algorithmic latency can be reduced from over 64 ms using traditional symmetric STFT windowing to below 2 ms with the proposed asymmetric STFT windowing, provided sufficient computational power is available.
The Real-time Speech Enhancement standalone Python executable is a real-time implementation of the online GCC-NMF speech enhancement algorithm. Users may interactively modify system parameters including the NMF dictionary size and GCC-NMF masking function parameters, where the effects on speech enhancement quality may be heard in real-time.