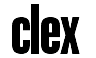
clex is a simple lexer generator for C.
With clex you can associate a regex pattern to each token type with clexRegisterKind(regex, type) call, pass the source using clexInit(source) call, and then lex the next token with clex() call.
At the end of the input string clex() returns (Token){.lexeme = NULL, .kind = 0}.
The maximum number of rules is 1024, but you can change that number in clex.h: #define CLEX_MAX_RULES 1024
#include "clex.h"
#include <assert.h>
#include <string.h>
typedef enum TokenKind {
INT,
OPARAN,
CPARAN,
OSQUAREBRACE,
CSQUAREBRACE,
OCURLYBRACE,
CCURLYBRACE,
COMMA,
CHAR,
STAR,
RETURN,
SEMICOL,
CONSTANT,
IDENTIFIER,
} TokenKind;
int main(int argc, char *argv[]) {
clexRegisterKind("int", INT);
clexRegisterKind("\\(", OPARAN);
clexRegisterKind("\\)", CPARAN);
clexRegisterKind("\\[|<:", OSQUAREBRACE);
clexRegisterKind("\\]|:>", CSQUAREBRACE);
clexRegisterKind("{|<%", OCURLYBRACE);
clexRegisterKind("}|%>", CCURLYBRACE);
clexRegisterKind(",", COMMA);
clexRegisterKind("char", CHAR);
clexRegisterKind("\\*", STAR);
clexRegisterKind("return", RETURN);
clexRegisterKind("[1-9][0-9]*([uU])?([lL])?([lL])?", CONSTANT);
clexRegisterKind(";", SEMICOL);
clexRegisterKind("[a-zA-Z_]([a-zA-Z_]|[0-9])*", IDENTIFIER);
clexInit("int main(int argc, char *argv[]) {\nreturn 23;\n}");
Token token = clex();
assert(token.kind == INT);
assert(strcmp(token.lexeme, "int") == 0);
token = clex();
assert(token.kind == IDENTIFIER);
assert(strcmp(token.lexeme, "main") == 0);
token = clex();
assert(token.kind == OPARAN);
assert(strcmp(token.lexeme, "(") == 0);
token = clex();
assert(token.kind == INT);
assert(strcmp(token.lexeme, "int") == 0);
token = clex();
assert(token.kind == IDENTIFIER);
assert(strcmp(token.lexeme, "argc") == 0);
token = clex();
assert(token.kind == COMMA);
assert(strcmp(token.lexeme, ",") == 0);
token = clex();
assert(token.kind == CHAR);
assert(strcmp(token.lexeme, "char") == 0);
token = clex();
assert(token.kind == STAR);
assert(strcmp(token.lexeme, "*") == 0);
token = clex();
assert(token.kind == IDENTIFIER);
assert(strcmp(token.lexeme, "argv") == 0);
token = clex();
assert(token.kind == OSQUAREBRACE);
assert(strcmp(token.lexeme, "[") == 0);
token = clex();
assert(token.kind == CSQUAREBRACE);
assert(strcmp(token.lexeme, "]") == 0);
token = clex();
assert(token.kind == CPARAN);
assert(strcmp(token.lexeme, ")") == 0);
token = clex();
assert(token.kind == OCURLYBRACE);
assert(strcmp(token.lexeme, "{") == 0);
token = clex();
assert(token.kind == RETURN);
assert(strcmp(token.lexeme, "return") == 0);
token = clex();
assert(token.kind == CONSTANT);
assert(strcmp(token.lexeme, "23") == 0);
token = clex();
assert(token.kind == SEMICOL);
assert(strcmp(token.lexeme, ";") == 0);
token = clex();
assert(token.kind == CCURLYBRACE);
assert(strcmp(token.lexeme, "}") == 0);
token = clex();
assert(token.kind == 0);
assert(token.lexeme == NULL);
}NFA can be drawn with Graphviz.
#include "fa.h"
int main(int argc, char *argv) {
Node *nfa = NFAFromRe("[A-Z]a(bc|de)*f");
NFADraw(nfa);
}Above code will output this to stdout:
digraph G {
1 -> 0 [label="A-Z"];
0 -> 2 [label="a-a"];
2 -> 3 [label="e"];
3 -> 4 [label="e"];
4 -> 5 [label="b-b"];
5 -> 6 [label="c-c"];
6 -> 7 [label="e"];
7 -> 8 [label="e"];
8 -> 9 [label="f-f"];
7 -> 2 [label="e"];
2 -> 10 [label="e"];
10 -> 11 [label="d-d"];
11 -> 12 [label="e-e"];
12 -> 7 [label="e"];
3 -> 8 [label="e"];
}The output can be processed with Graphviz to get the graph image: dot -Tpng output.dot > output.png.
Here's what it produces: