
Table of Contents
The design of a control system for an agile mobile robot in the continuous domain is a central question in robotics. This project specifically addresses the challenge of autonomous drone flight. Model-free reinforcement learning (RL) is utilized as it can directly optimize a task-level objective and leverage domain randomization to handle model uncertainty, enabling the discovery of more robust control responses. The task analyzed in the following is a single agent stabilization task.
The gym-pybullet-drones environment is based on the Crazyflie 2.x nanoquadcopter. It implements the
OpenAI gym API for single or multi-agent reinforcement learning (MARL).
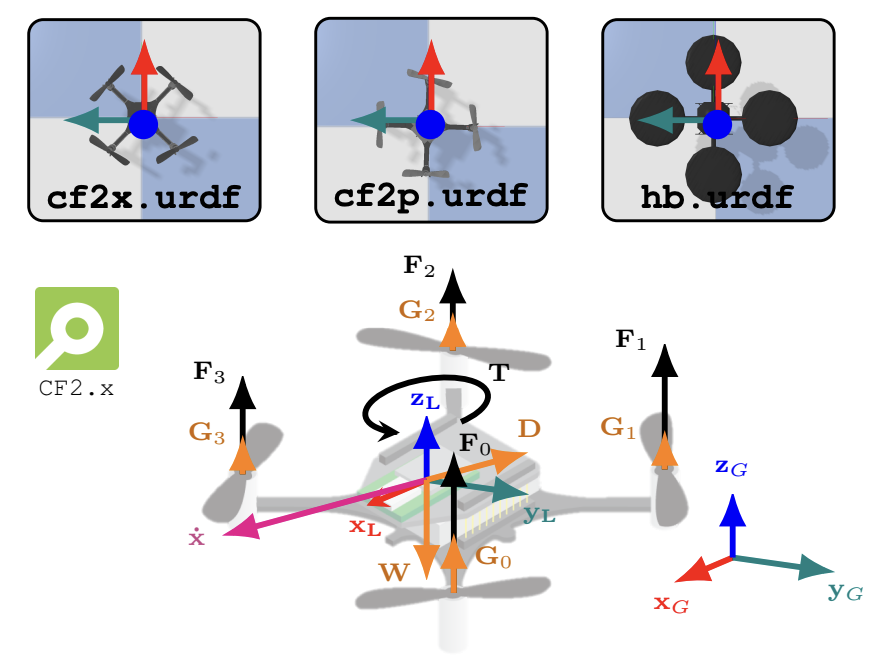
Fig. 1: The three types of
gym-pybullet-drones models, as well as the forces and torques acting on each vehicle.
The following shows a training result where the agent has learned to control the four independent rotors to overcome simulated physical forces (e.g. gravity) by the Bullet physics engine, stabilize and go into steady flight.
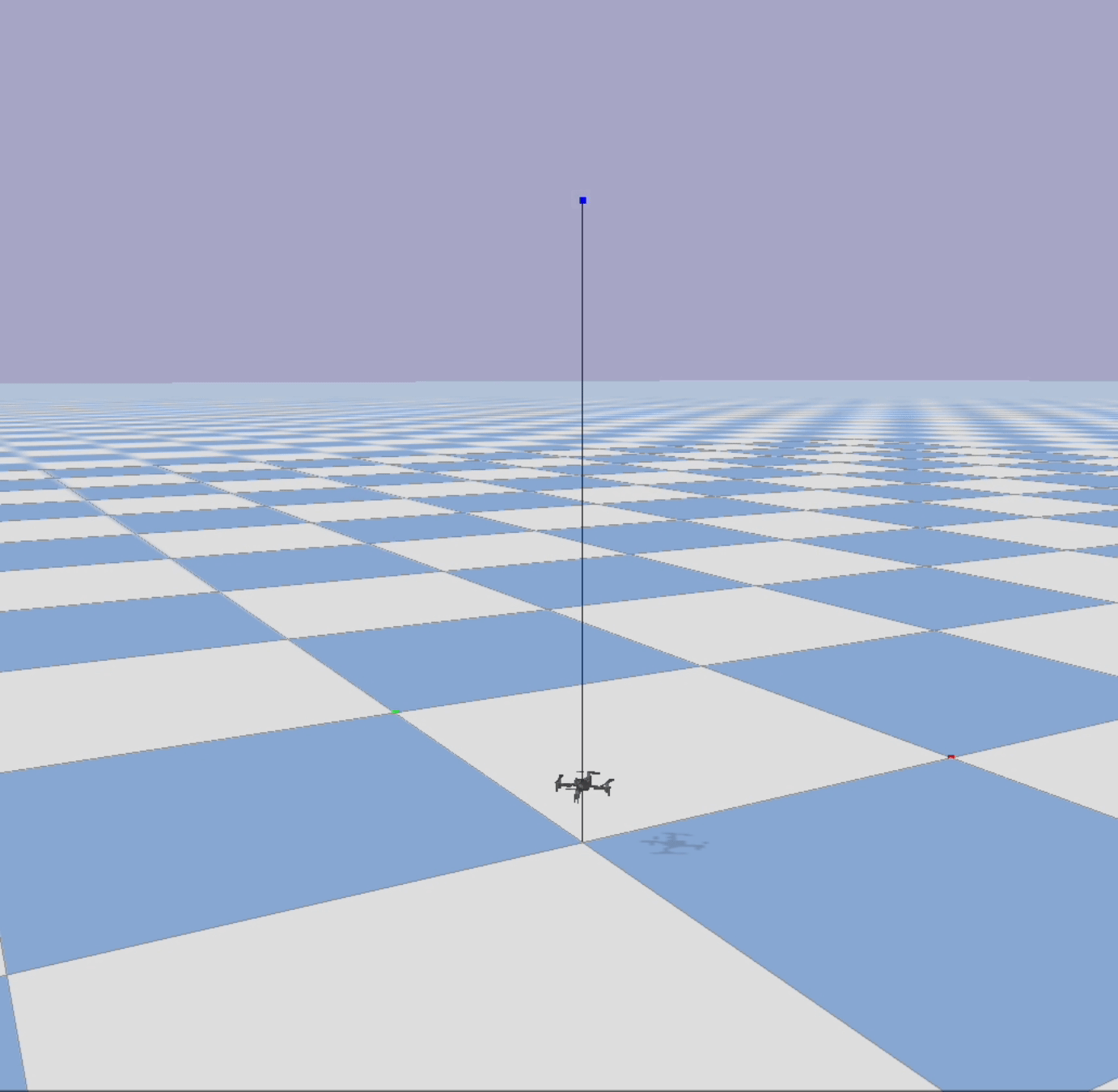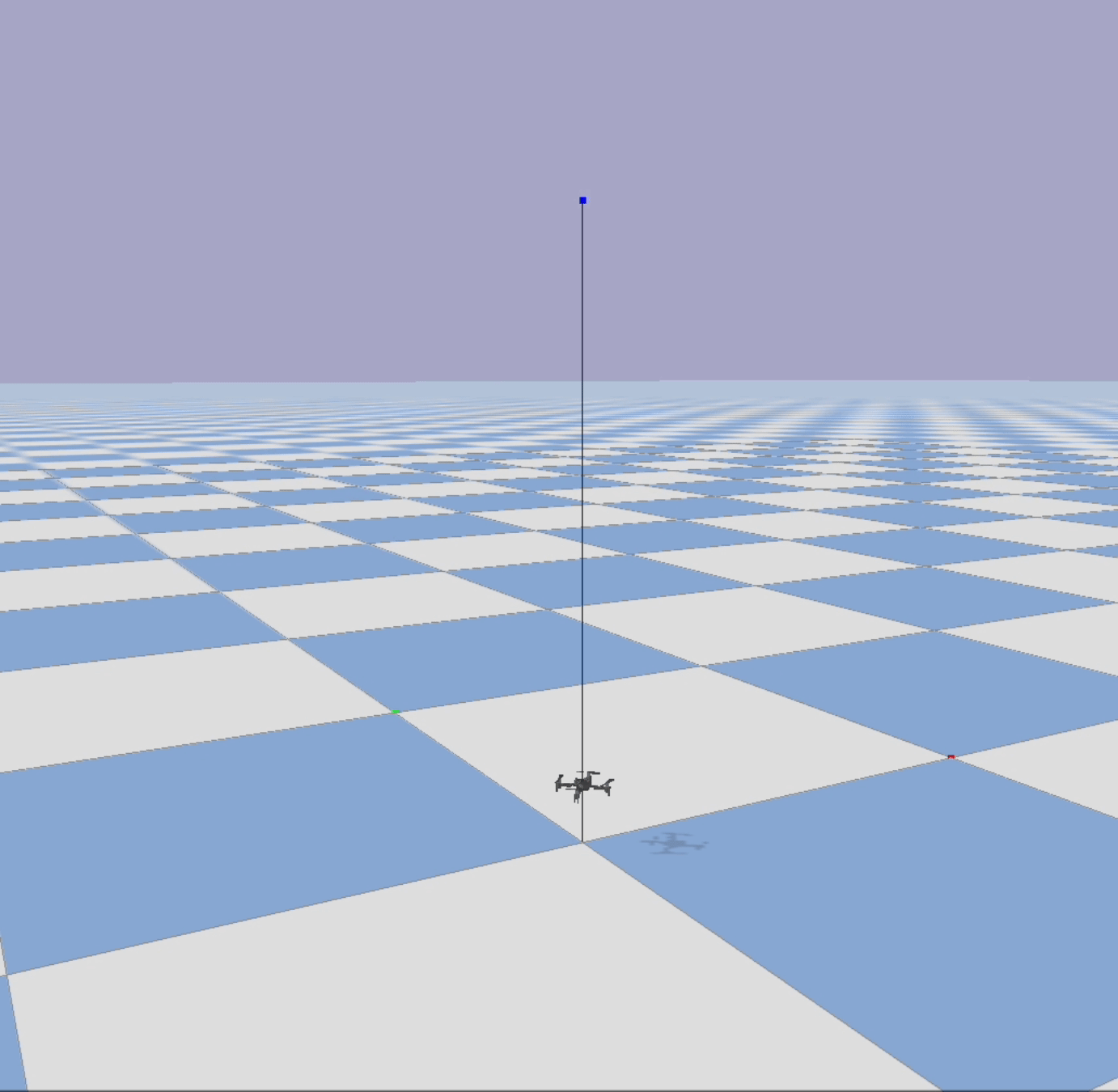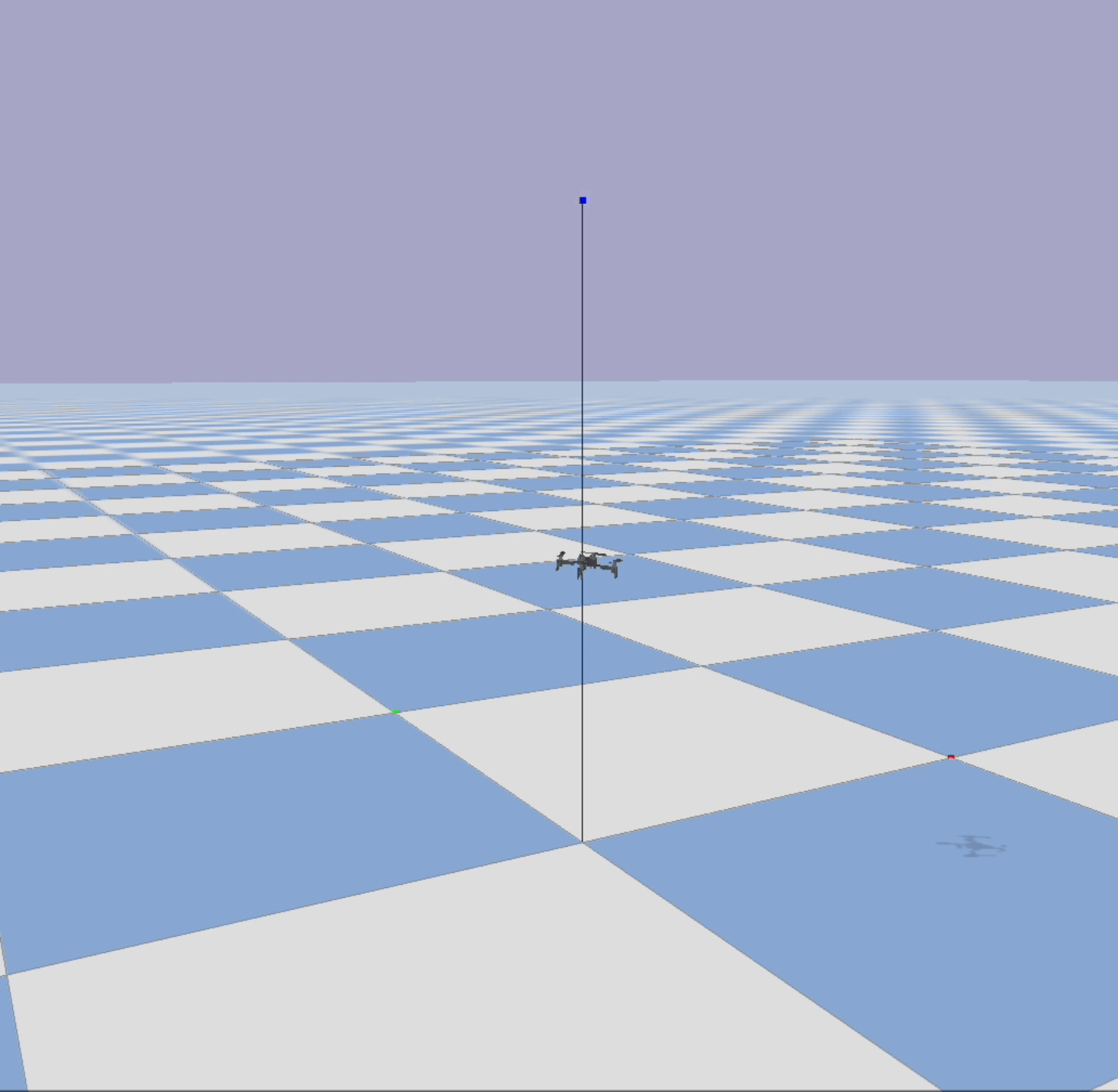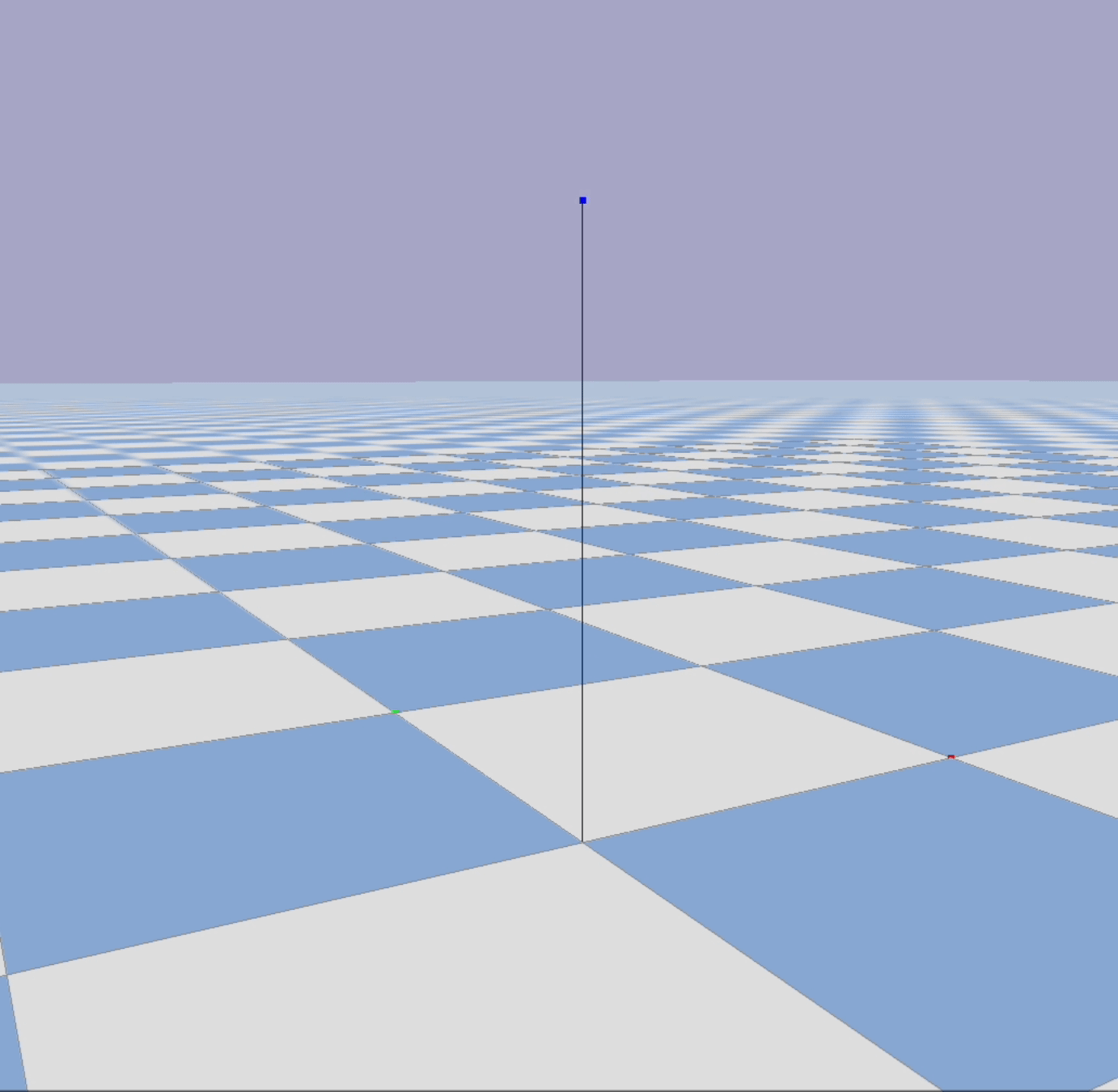
Fig. 2: Rendering of a
gym-pybullet-drones stable flight with a Crazyflie 2.x during inference.
In this project the policy gradient method is used for training with a custom implementation of Proximal Policy Optimization (PPO).

Fig. 3: Overview of the Actor-Critic Proximal Policy Optimisation Algorithm process
The architecture consists of two separate neural networks: the actor network and the critic network. The actor network is responsible for selecting actions given the current state of the environment, while the critic network is responsible for evaluating the value of the current state.
The actor network takes the current state
where
The critic network takes the current state
$$ L^{critic}(\theta) = \mathbb{E}{t} \left[ \left(V{\theta}(s_t) - R_t\right)^2 \right] $$
where
The observation space is defined through the quadrotor state, which includes the position, linear velocity, angular velocity, and orientation of the drone. The action space is defined by the desired thrust in the z direction and the desired torque in the x, y, and z directions.
The reward function defines the problem specification as follows:
where
The environment is a custom OpenAI Gym environment built using PyBullet for multi-agent reinforcement learning with quadrotors.
Fig. 4: 3D simulation of the drone's orientation in the x, y, and z axes.
- stabilize drone flight
The project was developed using Python and the PyTorch machine learning framework. To simulate the quadrotor's environment, the Bullet physics engine is leveraged. Further, to streamline the development process and avoid potential issues, the pre-built PyBullet drone implementation provided by the gym-pybullet-drones library is utilized.
Programming Languages-Frameworks-Tools
This is an example of how you may give instructions on setting up your project locally. To get a local copy up and running follow these simple example steps.
This repository was written using Python 3.10 and Anaconda tested on macOS 14.4.1.
Major dependencies are gym, pybullet, stable-baselines3, and rllib
-
Create virtual environment and install major dependencies
$ pip3 install --upgrade numpy matplotlib Pillow cycler $ pip3 install --upgrade gym pybullet stable_baselines3 'ray[rllib]'or requirements.txt
$ pip install -r requirements_pybullet.txt -
Video recording requires to have
ffmpeginstalled, on macOS$ brew install ffmpegor on Ubuntu
$ sudo apt install ffmpeg -
The
gym-pybullet-dronesrepo is structured as a Gym Environment and can be installed with pip install --editable$ cd gym-pybullet-drones/ $ pip3 install -e .
- Add Changelog
- Add back to top links
- Fix sparse reward issue by adding prox rewards
- Adjustment of the reward function to achieve the approach of a target
- Implement in Unity with ML agents
- Adjust Readme file
Distributed under the MIT License. See LICENSE.txt for more information.
Project Link: Autonomous-Explorer-Drone