| Method | Backbone | Fine-tuning | Config | Precision (%) | Recall (%) | F-measure (%) | Model | Log |
|---|---|---|---|---|---|---|---|---|
| mmocr_PANet | Resnet18 | N | ctw_config | 77.6 | 83.8 | 80.6 | -- | -- |
| PAN (paper) | ResNet18 | N | config | 84.6 | 77.7 | 81.0 | - | - |
| PaddlePaddle_PANet | ResNet18 | N | panet_r18_ctw.py | 84.51 | 78.62 | 81.46 | Model | Log |
这是发在2019ICCV上的一篇一阶段场景文本检测论文。主要是PSENet的升级版。PSENet虽然处理速度很快,准确度很高,但后处理过程繁琐,而且没办法和网络模型融合在一起,实现训练。PANet很好的解决了这一问题,把后处理过程也放入网络中,预测出三个loss,最后进行融合。
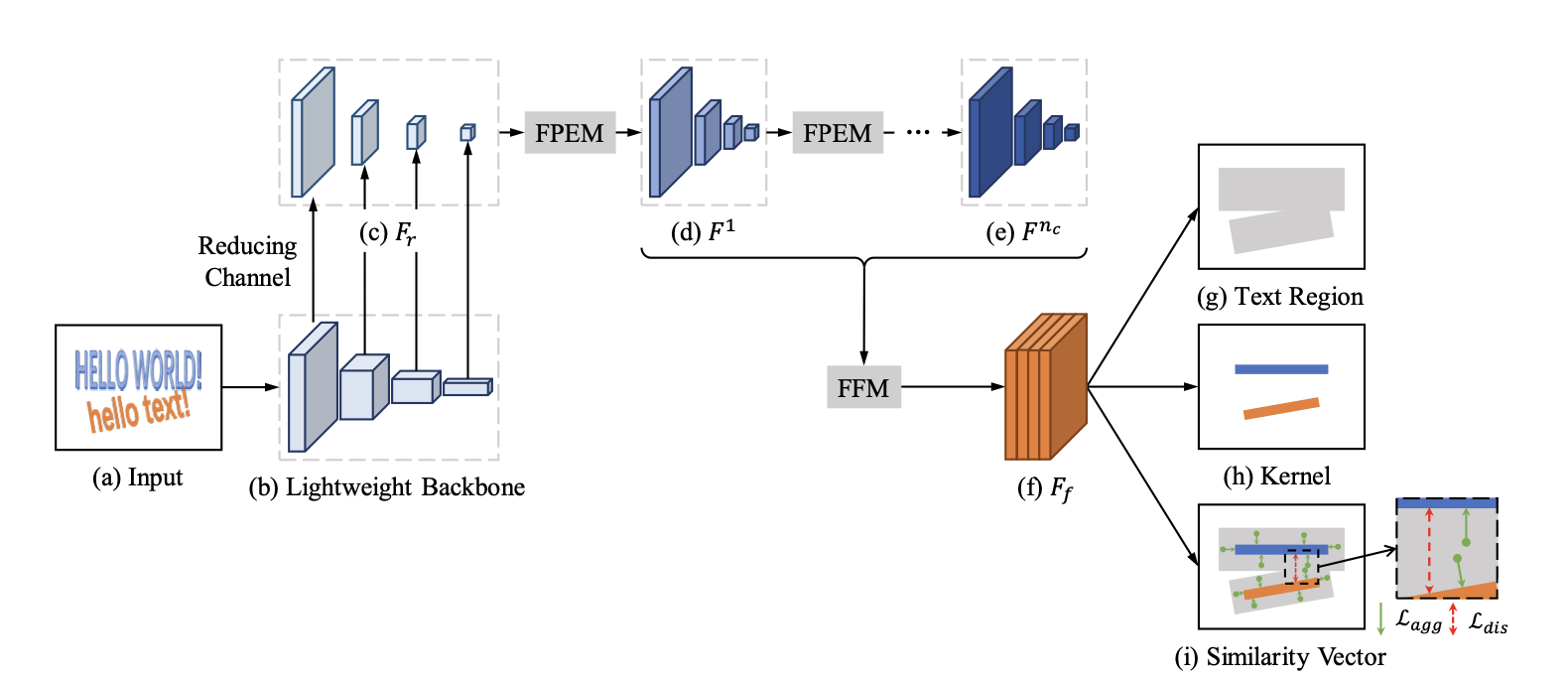
本文使用ResNet-18作为PAN的默认Backbone,并提出了低计算量的Segmentation Head(FPFE + FFM)以解决因为使用ResNet-18而导致的特征提取能力较弱,特征感受野较小且表征能力不足的缺点。
此外,为了精准地重建完整的文字实例(text instance),提出了一个可学习的后处理方法——像素聚合法(PA),它能够通过预测出的相似向量来引导文字像素聚合到正确的kernel上去。
下面将详细介绍一下上面的各个部分。
Backbone选择的是resnet18, 提取stride为4,8,16,32的conv2,conv3,conv4,conv5的输出作为高低层特征。每层的特征图的通道数都使用1*1卷积降维至128得到轻量级的特征图Fr。
PAN使用resNet-18作为网络的默认backbone,虽减少了计算量,但是backbone层数的减少势必会带来模型学习能力的下降。为了提高效率,作者在 resNet-18基础上提出了一个低计算量但可高效增强特征的分割头Segmentation Head。它由两个关键模块组成:特征金字塔增强模块(Feature Pyramid Enhancement Module,FPEM)、特征融合模块(Feature Fusion Module,FFM)。
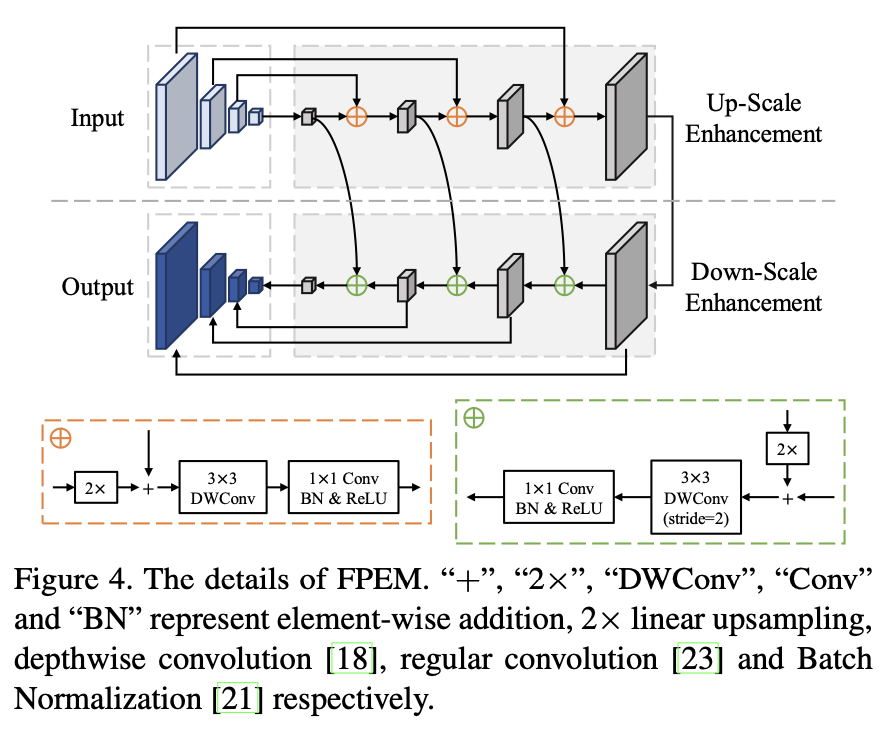
Feature Pyramid Enhancement Module(FPEM),即特征金字塔增强模块。FPEM呈级联结构且计算量小,可以连接在backbone后面让不同尺寸的特征更深、更具表征能力,结构如下:
Feature Fusion Module(FFM)模块用于融合不同尺度的特征,其结构如下:

最后通过上采样将它们Concatenate到一起。
模型最后预测三种信息: 1、文字区域 2、文字kernel 3、文字kernel的相似向量


Python 3.6+
paddlepaddle-gpu 2.0.2
nccl 2.0+
mmcv 0.2.12
editdistance
Polygon3
pyclipper
opencv-python 3.4.2.17
Cython
Install paddle following the official tutorial.
pip install -r requirement.txt
./compile.shPlease refer to dataset/README.md for dataset preparation.
download resent18 pre-train model in
pretrain/resnet18.pdparams
pretrain_resnet18 password: j5g3
CUDA_VISIBLE_DEVICES=0,1,2,3 python dist_train.py ${CONFIG_FILE}
For example:
CUDA_VISIBLE_DEVICES=0,1,2,3 python dist_train.py config/pan/pan_r18_ctw.py
#checkpoint continue
python3.7 dist_train.py config/pan/pan_r18_ctw_train.py --nprocs 1 --resume checkpoints/pan_r18_ctw_trainThe evaluation scripts of CTW 1500 dataset. CTW
Text detection
./start_test.shThis project is developed and maintained by IMAGINE Lab@National Key Laboratory for Novel Software Technology, Nanjing University.
This project is released under the Apache 2.0 license.
@inproceedings{wang2019efficient,
title={Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network},
author={Wang, Wenhai and Xie, Enze and Song, Xiaoge and Zang, Yuhang and Wang, Wenjia and Lu, Tong and Yu, Gang and Shen, Chunhua},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
pages={8440--8449},
year={2019}
}