Multifarious scrapy examples with integrated proxies and agents, which make you comfy to write a spider.
Don't use it to do anything illegal!
##Real spider example: doubanbook
####Tutorial
git clone https://github.com/geekan/scrapy-examples
cd scrapy-examples/doubanbook
scrapy crawl doubanbook
####Depth
There are several depths in the spider, and the spider gets real data from depth2.
- Depth0: The entrance is
http://book.douban.com/tag/ - Depth1: Urls like
http://book.douban.com/tag/外国文学from depth0 - Depth2: Urls like
http://book.douban.com/subject/1770782/from depth1
####Example image
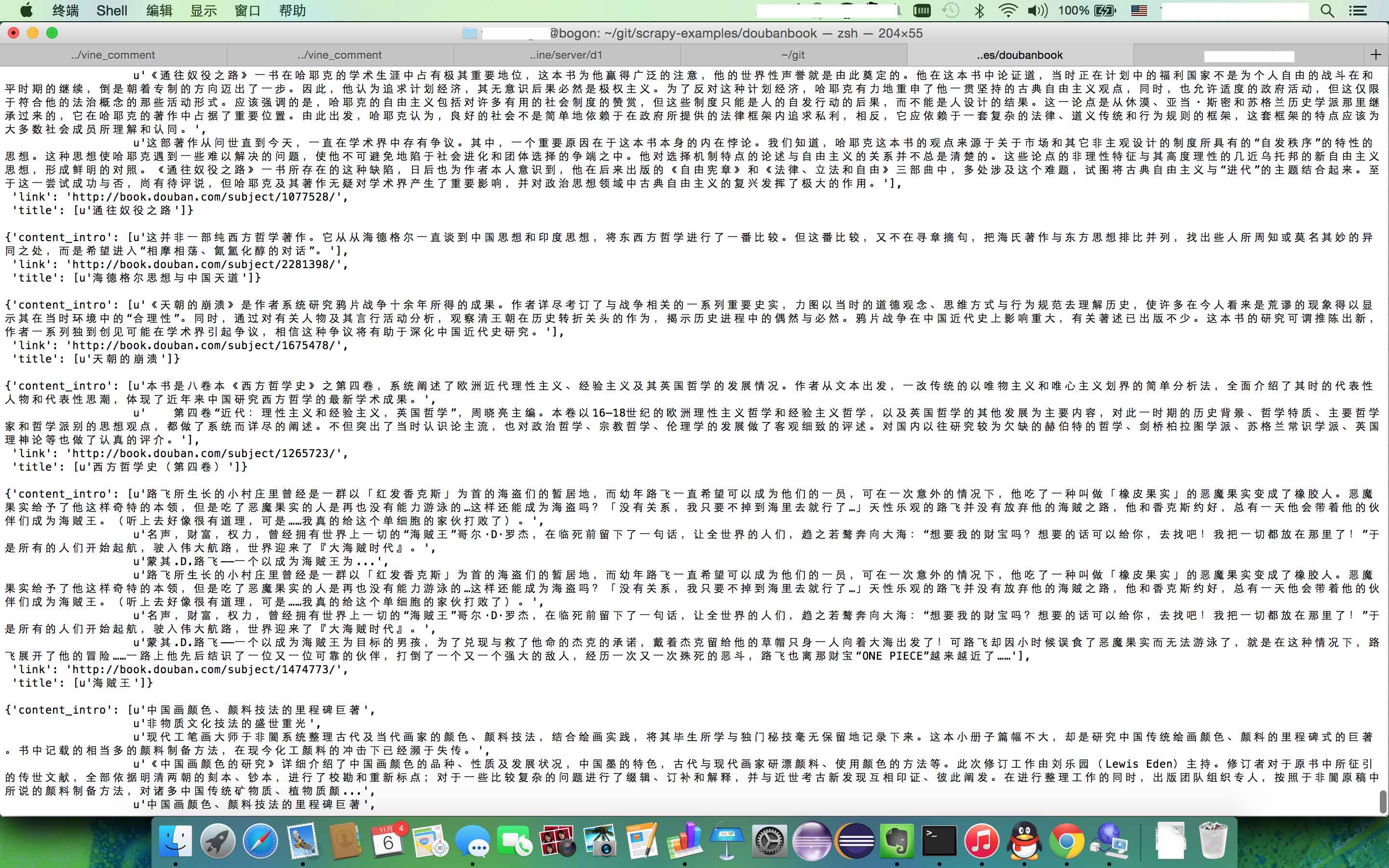
##Avaiable Spiders
- tutorial
- dmoz_item
- douban_book
- page_recorder
- douban_tag_book
- doubanbook
- hrtencent
- sis
- zhihu
- alexa
- alexa
- alexa.cn
-
Use
parse_with_rulesto write a spider quickly.
See dmoz spider for more details. -
Proxies
- If you don't want to use proxy, just comment the proxy middleware in settings.
- If you want to custom it, hack
misc/proxy.pyby yourself.
-
Notice
- Don't use
parseas your method name, it's an inner method of CrawlSpider.
- Don't use
- Run
./startproject.sh <PROJECT>to start a new project.
It will automatically generate most things, the only left things are:PROJECT/PROJECT/items.pyPROJECT/PROJECT/spider/spider.py
Hacked items.py with additional fields url and description:
from scrapy.item import Item, Field
class exampleItem(Item):
url = Field()
name = Field()
description = Field()
Hacked spider.py with start rules and css rules (here only display the class exampleSpider):
class exampleSpider(CommonSpider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.com/",
]
# Crawler would start on start_urls, and follow the valid urls allowed by below rules.
rules = [
Rule(sle(allow=["/Arts/", "/Games/"]), callback='parse', follow=True),
]
css_rules = {
'.directory-url li': {
'__use': 'dump', # dump data directly
'__list': True, # it's a list
'url': 'li > a::attr(href)',
'name': 'a::text',
'description': 'li::text',
}
}
def parse(self, response):
info('Parse '+response.url)
# parse_with_rules is implemented here:
# https://github.com/geekan/scrapy-examples/blob/master/misc/spider.py
self.parse_with_rules(response, self.css_rules, exampleItem)