Try to use the SAM-ViT as the backbone to create the visual prompt tuning model for semantic segmentation. More of the details can be seen at the technical report at link
As the original SAM can not be used at the optical images like color fundus and OCT (As the following image shows.), thus we introduce the learnable prompt layer (Adapter) to fine-tune the SAM.


-
The results of the one-shot learning:
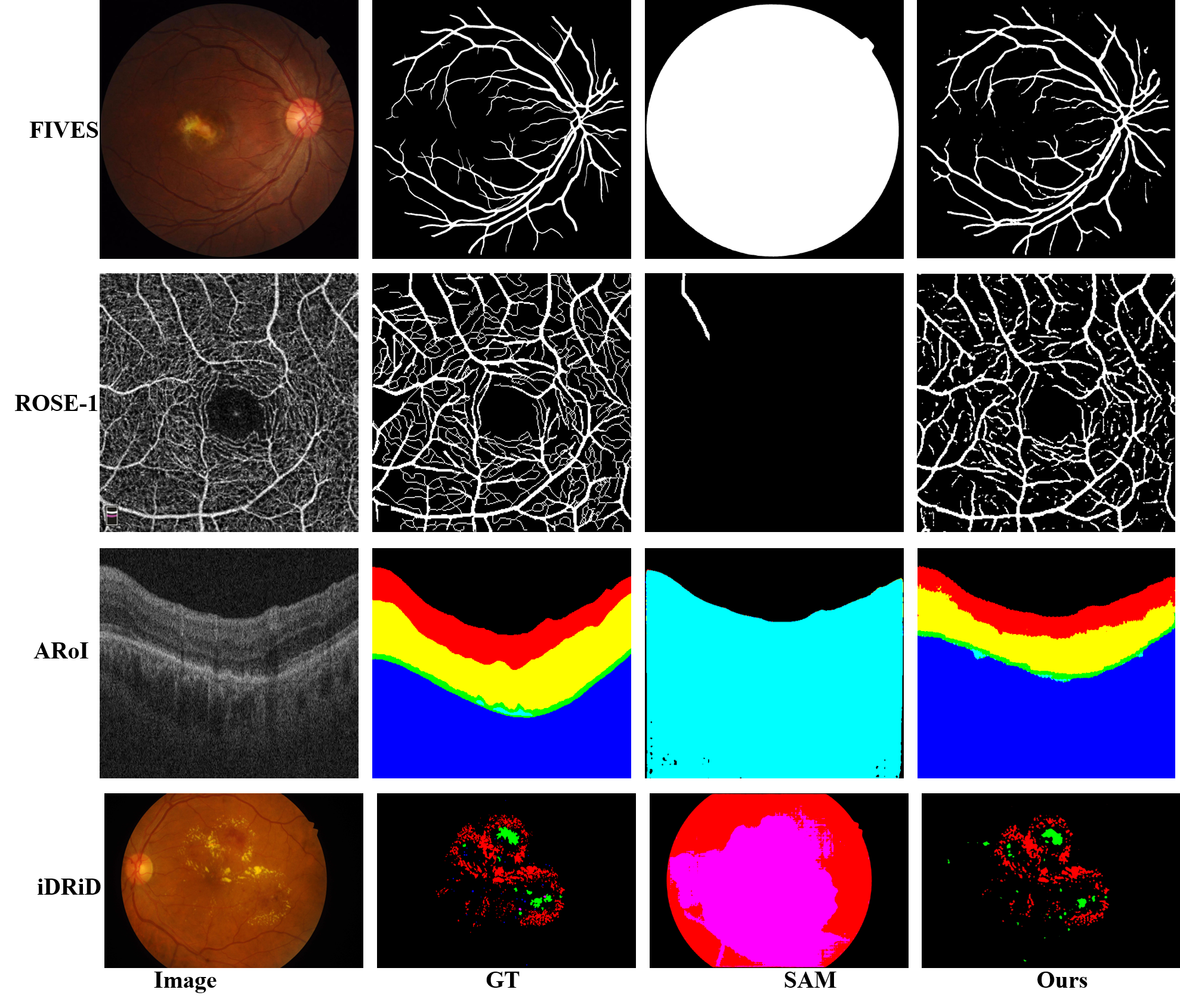
-
Results for the zero-shot after tuned.
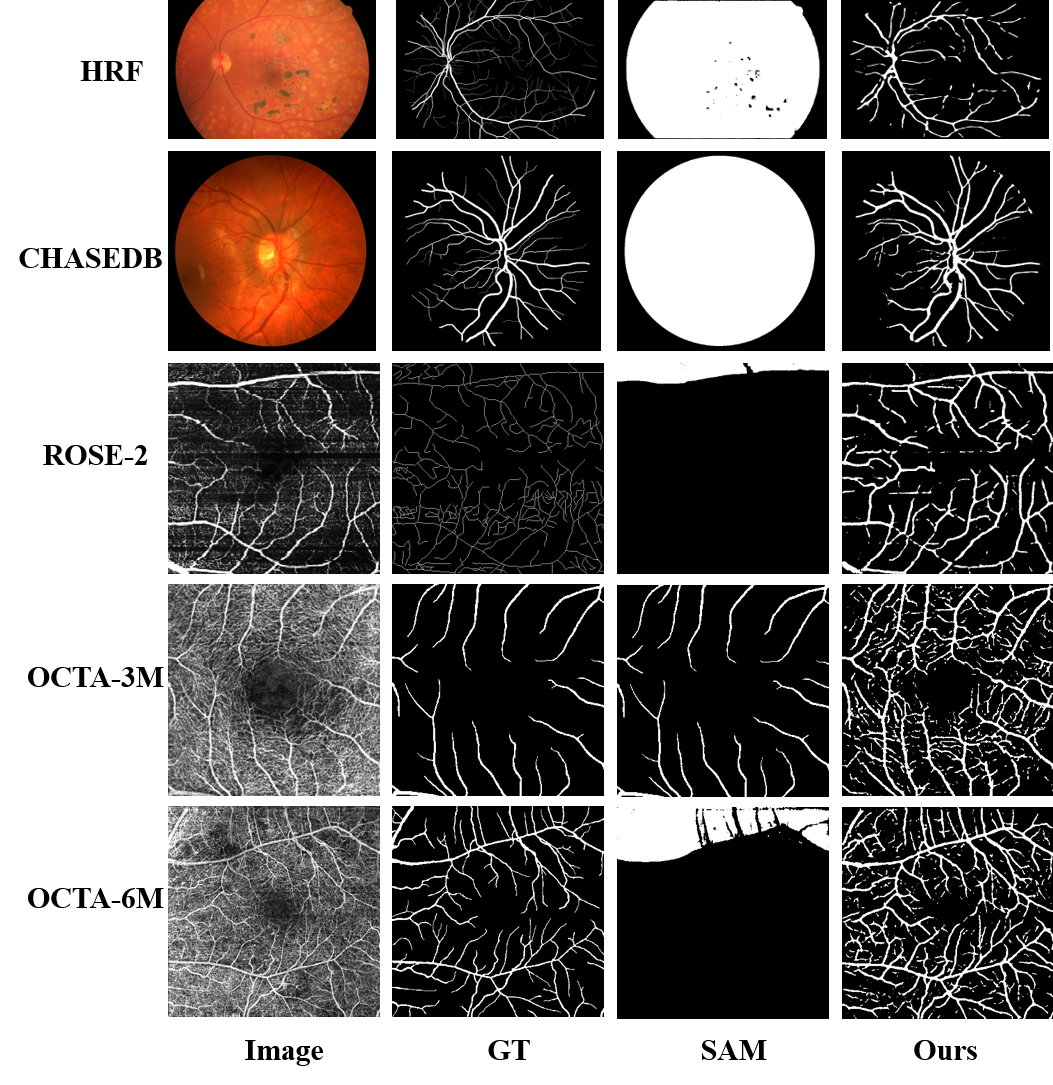


-
Clone the code to your PC.
git clone https://github.com/Qsingle/LearnablePromptSAM.git
-
Download the weights from original repository.
-
Fine-tune the model with our code (In our experiments, we found that
lr=0.05can get a better results. You can change it.).python train_learnable_sam.py --image /path/to/the/image \ --mask_path /path/to/the/mask \ --model_name vit_h \ --checkpoint /path/to/the/pretrained/weights \ --save_path /path/to/store/the/weights \ --lr 0.05 \ --mix_precision \ --optimizer sgd
- Update README
- Update code.
- Upload the sample code for the model.
- Update the README
- Given the sample for the one-shot learning.
TODO
-
Dynamic Head for segmentation.
-
Optimize the training process.
-
Support for the training of few-shot learning.
-
Improving the performance of the model.