![]()



Awkward Array is a library for nested, variable-sized data, including arbitrary-length lists, records, mixed types, and missing data, using NumPy-like idioms.
Arrays are dynamically typed, but operations on them are compiled and fast. Their behavior coincides with NumPy when array dimensions are regular and generalizes when they're not.
Given an array of objects with x, y fields and variable-length nested lists like
array = ak.Array([
[{"x": 1.1, "y": [1]}, {"x": 2.2, "y": [1, 2]}, {"x": 3.3, "y": [1, 2, 3]}],
[],
[{"x": 4.4, "y": [1, 2, 3, 4]}, {"x": 5.5, "y": [1, 2, 3, 4, 5]}]
])the following slices out the y values, drops the first element from each inner list, and runs NumPy's np.square function on everything that is left:
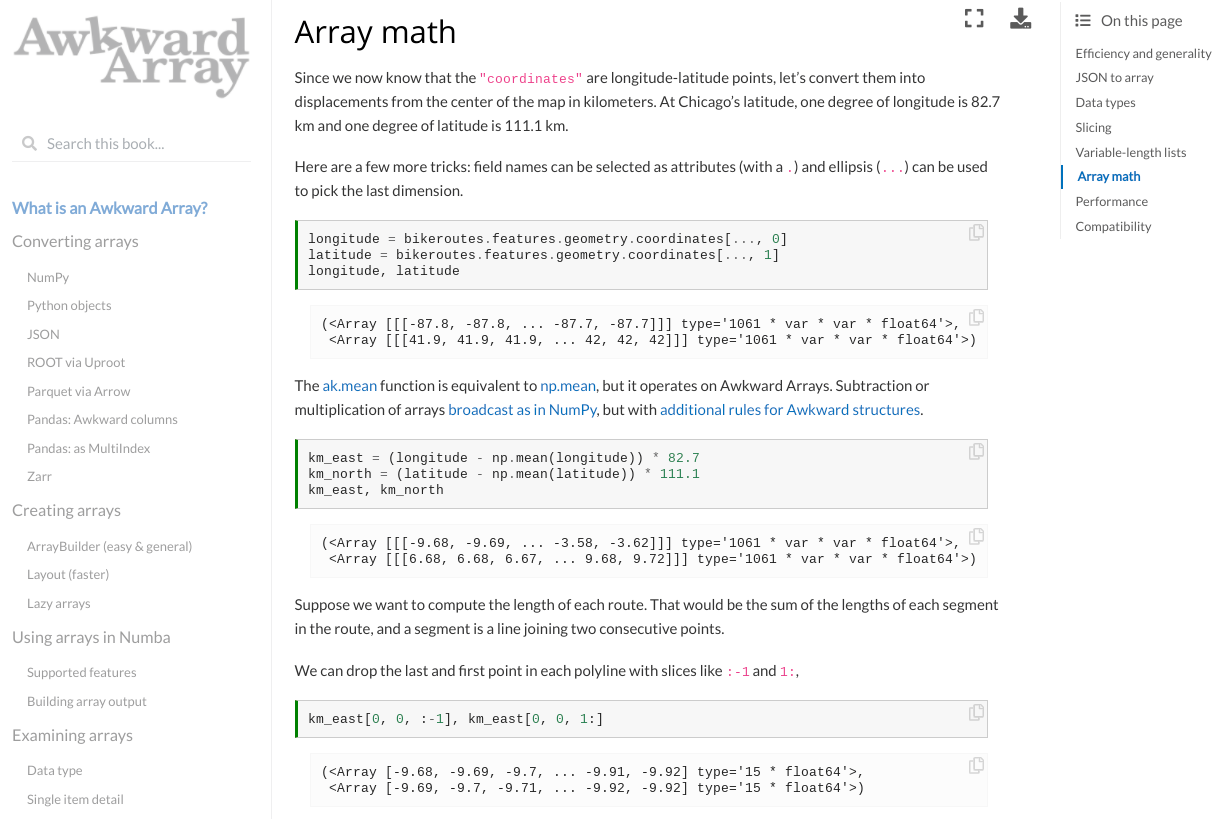
output = np.square(array["y", ..., 1:])The result is
[
[[], [4], [4, 9]],
[],
[[4, 9, 16], [4, 9, 16, 25]]
]The equivalent using only Python is
output = []
for sublist in array:
tmp1 = []
for record in sublist:
tmp2 = []
for number in record["y"][1:]:
tmp2.append(np.square(number))
tmp1.append(tmp2)
output.append(tmp1)Not only is the expression using Awkward Arrays more concise, using idioms familiar from NumPy, but it's much faster and uses less memory.
For a similar problem 10 million times larger than the one above (on a single-threaded 2.2 GHz processor),
- the Awkward Array one-liner takes 4.6 seconds to run and uses 2.1 GB of memory,
- the equivalent using Python lists and dicts takes 138 seconds to run and uses 22 GB of memory.
Speed and memory factors in the double digits are common because we're replacing Python's dynamically typed, pointer-chasing virtual machine with type-specialized, precompiled routines on contiguous data. (In other words, for the same reasons as NumPy.) Even higher speedups are possible when Awkward Array is paired with Numba.
Our presentation at SciPy 2020 provides a good introduction, showing how to use these arrays in a real analysis.
Awkward Array can be installed from PyPI using pip:
pip install awkwardYou will likely get a precompiled binary (wheel), depending on your operating system and Python version. If not, pip attempts to compile from source (which requires a C++ compiler, make, and CMake).
Awkward Array is also available using conda, which always installs a binary:
conda install -c conda-forge awkwardIf you have already added conda-forge as a channel, the -c conda-forge is unnecessary. Adding the channel is recommended because it ensures that all of your packages use compatible versions:
conda config --add channels conda-forge
conda update --all
|
|
- Report bugs, request features, and ask for additional documentation on GitHub Issues.
- You can vote for issues by adding a "thumbs up" (👍) using the "smile/pick your reaction" menu on the top-right of the issue. See the prioritized list of open issues.
- If you have a "How do I...?" question, start a GitHub Discussion with category "Q&A".
- Alternatively, ask about it on StackOverflow with the [awkward-array] tag. Be sure to include tags for any other libraries that you use, such as Pandas or PyTorch.
- To ask questions in real time, try the Gitter Scikit-HEP/awkward-array chat room.
Be sure to clone this repository recursively to get the header-only C++ dependencies.
git clone --recursive https://github.com/scikit-hep/awkward-1.0.gitAlso be aware that the default branch is named main, not master, which could be important for pull requests from forks.
You can install it on your system with pip, which uses exactly the same procedure as deployment. This is recommended if you do not expect to change the code.
pip install .[test,dev]Or you can build it locally for incremental development. The following reuses a local directory so that you only recompile what you've changed. This is recommended if you do expect to change the code.
python localbuild.py --pytest testsThe --pytest tests runs the integration tests from the tests directory (drop it to build only).
For more fine-grained testing, we also have tests of the low-level kernels, which can be invoked with
python dev/generate-tests.py
python -m pytest -vv -rs tests-spec
python -m pytest -vv -rs tests-cpu-kernelsFurthermore, if you have an Nvidia GPU, you can build and locally install the experimental CUDA plug-in with
pip uninstall -y awkward-cuda-kernels
python dev/generate-cuda.py
./cuda-build.sh --installThe --install does a local pip install on your system, which is the only way to use it. You can run its tests with
python dev/generate-tests.py
python -m pytest -vv -rs tests-cuda-kernels
python -m pytest -vv -rs tests-cuda- Continuous integration and continuous deployment are hosted by Azure Pipelines.
- Release history (changelog) is hosted by ReadTheDocs.
- awkward-array.org is hosted by Netlify.
- CONTRIBUTING.md for technical information on how to contribute.
- Code of conduct for how we work together.
- The LICENSE is BSD-3.
Python projects can simply import awkward.
C++ projects can link against the shared libraries libawkward-cpu-kernels.so and libawkward.so or their static library equivalents. These libraries are shipped, along with the include files, as part of pip's installation.
- See the dependent-project directory for examples.
Since version 0.4.0, Awkward Array has been compiled with versions of pybind11 that have ABI version 4. Any other Python extension built with pybind11 ABI version 4 can consume and produce Awkward Arrays in the way described here.
The table below indicates when interface-breaking changes are planned; each is discussed in pull requests and issues. It doesn't include new additions that don't interfere with old behavior or corrections to bugs (i.e. behaviors that were never intended and fixed immediately). Each deprecated feature is announced by a FutureWarning that indicates the target removal version/date.
See release history for a detailed changelog of past releases. See projects for planning and prioritizing future fixes and features.
| Version number | Release date | Deprecated features removed in this version |
|---|---|---|
| 1.0.0 | 2020-12-05 | Broadcasting NumPy ufuncs through records (#457), lazy_cache="attach" option in ak.from_parquet (#576). |
| 1.1.0 | 2021-02-09 | Removed ak.to_arrayset/ak.from_arrayset in favor of ak.to_buffers/ak.from_buffers (#592). |
| 1.2.0 | 2021-04-01 | (none) |
| 1.3.0 | 2021-06-01 | (none) |
| Version number | Target date | Deprecated features to remove in this version |
|---|---|---|
| 1.4.0 | 2021-06-28 (for PyHEP) | |
| 1.5.0 | 2021-08-01 | |
| 1.6.0 | 2021-10-01 | |
| 1.7.0 | 2021-12-01 | |
| 1.8.0 | 2022-02-01 |
You can vote for issues by adding a "thumbs up" (👍) using the "smile/pick your reaction" menu on the top-right of the issue. Issues with the most "thumbs ups" will be prioritized, though this isn't the only consideration determining when an issue gets addressed. (An estimate of how long it will take is also important.)
See the prioritized list of open issues.
- Original motivations document from July 2019, now out-of-date.
- StrangeLoop talk on September 14, 2019.
- PyHEP talk on October 17, 2019.
- CHEP talk on November 7, 2019.
- CHEP 2019 proceedings (to be published in EPJ Web of Conferences).
- Demo for Coffea developers on December 20, 2019.
- Demo for Numba developers on January 22, 2020.
- Summary poster on February 27, 2020.
- Demo for Electron Ion Collider users (video) on April 8, 2020.
- Presentation at SciPy 2020 (video) on July 5, 2020.
- Tutorial at PyHEP 2020 (video with interactive notebook on Binder) on July 13, 2020.
Support for this work was provided by NSF cooperative agreement OAC-1836650 (IRIS-HEP), grant OAC-1450377 (DIANA/HEP) and PHY-1520942 (US-CMS LHC Ops).
We also thank Erez Shinan and the developers of the Lark standalone parser, which is used to parse type strings as type objects.
Thanks especially to the gracious help of Awkward Array contributors (including the original repository).


























💻: code, 📖: documentation, 🚇: infrastructure, 🚧: maintainance, ⚠: tests and feedback, 🤔: foundational ideas.