利用queue,threading两个模块设计生产者消费者模型
def request(self):
for i in range(1, self.page+1):
try:
print(self.url)
req = requests.get(self.url + '6-0-0-0-0-{}.html'.format(i), headers=self.header, timeout=10, verify=True)
print('正在爬取第%d页的数据' %i)
if req.status_code == 200:
bs = BeautifulSoup(req.text)
for _, n in zip(bs.find_all('video', src=True), bs.find_all('img', {'class': 'scrollLoading'})):
self.que.put({'url': 'http:'+_['src'], 'name':n['alt']})
except Exception as e:
print(e)
pass
print('共有{}条视频需要下载!'.format(self.que.qsize())) def download(self, path=os.getcwd()):
while not self.que.empty():
data = self.que.get()
try:
req = requests.get(url=data['url'],headers=self.header, verify=False)
if req.status_code == 200:
print('-'*10,data['url'],'-'*10)
if not os.path.exists(path):
os.mkdir(path.strip().rstrip('\\'))
with open(os.path.join(path, data['name']), 'wb') as f:
f.write(req.content)
else:
time.sleep(2)
req2 = requests.get(url=data['url'], headers=self.header, verify=False)
if req2.status_code ==200:
print('+'*10, data['url'], '+'*10)
with open(os.path.join(path, data['name']), 'wb') as f:
f.write(req.content)
else:
self.fail.put(data)
print(data['name'] +'\t'+'下载失败!')
except Exception as e:
print(e)
continue这个网站是我无意间发现的,看到里面有简单的素材视频,打算下载下来使用:
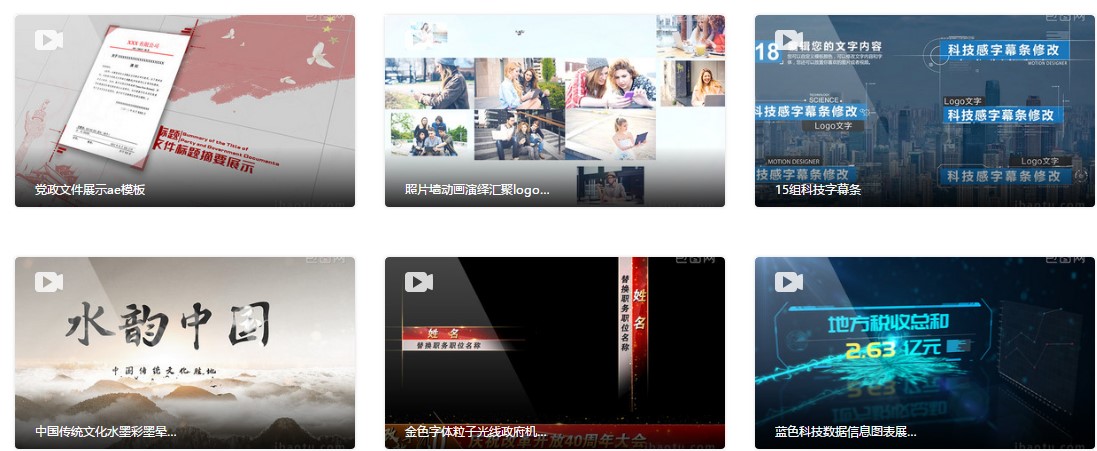
通过分析找到每个视频的url和name:
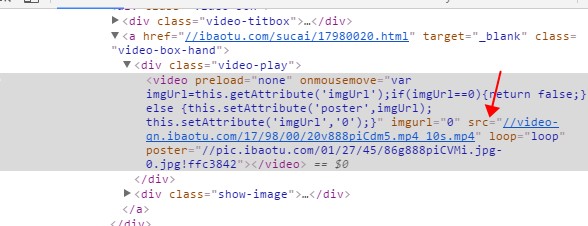
视频url
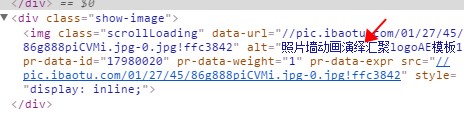
视频name
然后可以将每页的视频都爬取下来,具体操作间request函数,download函数采用多线程进行爬取,但是由于该网站发爬虫机制的存在导致有少部分的视频下载失败。 具体代码都写有注释:
参见github