![]()



LightLLM is a Python-based LLM (Large Language Model) inference and serving framework, notable for its lightweight design, easy scalability, and high-speed performance. LightLLM harnesses the strengths of numerous well-regarded open-source implementations, including but not limited to FasterTransformer, TGI, vLLM, and FlashAttention.
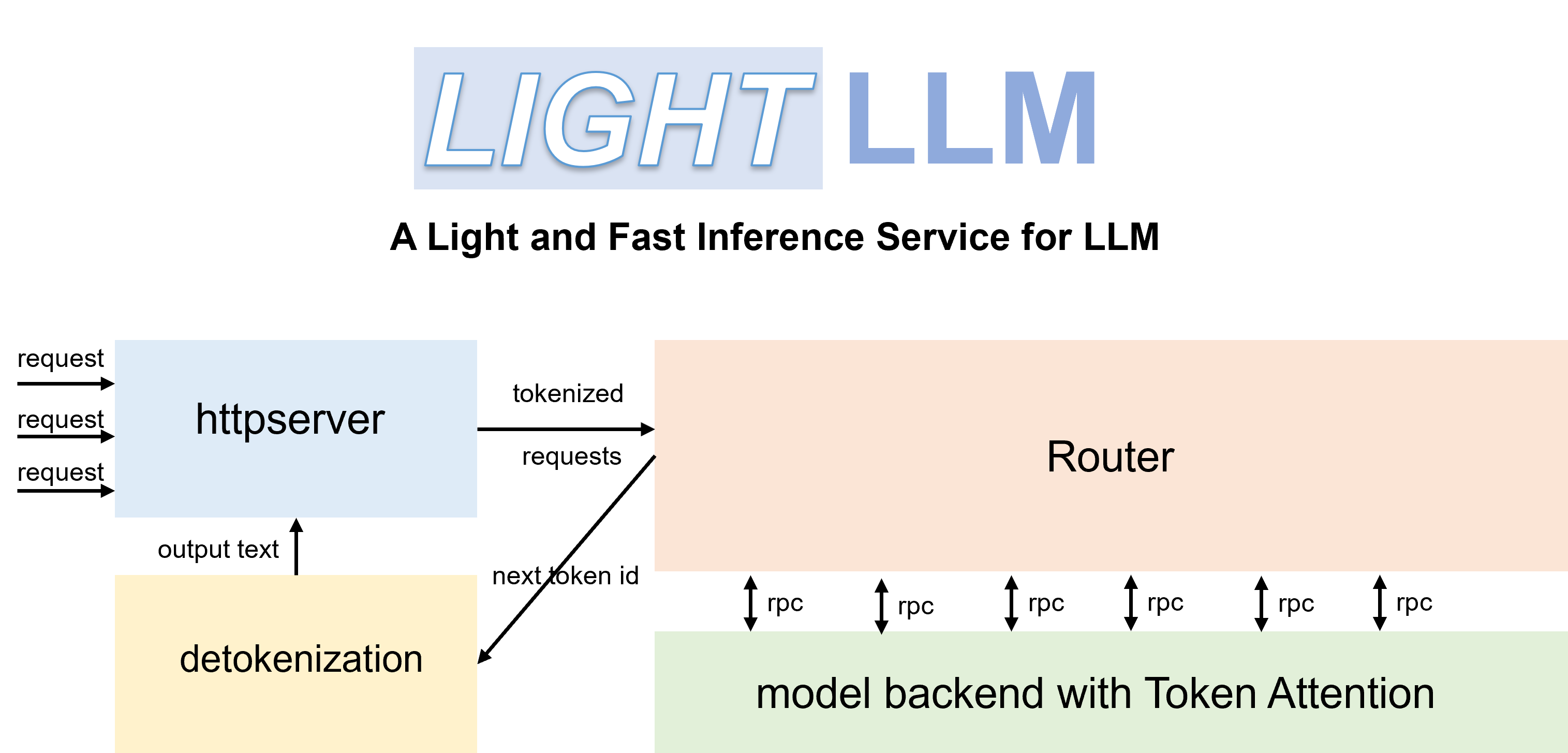
- Tri-process asynchronous collaboration: tokenization, model inference, and detokenization are performed asynchronously, leading to a considerable improvement in GPU utilization.
- Nopad (Unpad): offers support for nopad attention operations across multiple models to efficiently handle requests with large length disparities.
- Dynamic Batch: enables dynamic batch scheduling of requests
- FlashAttention: incorporates FlashAttention to improve speed and reduce GPU memory footprint during inference.
- Tensor Parallelism: utilizes tensor parallelism over multiple GPUs for faster inference.
- Token Attention: implements token-wise's KV cache memory management mechanism, allowing for zero memory waste during inference.
- High-performance Router: collaborates with Token Attention to meticulously manage the GPU memory of each token, thereby optimizing system throughput.
- Int8KV Cache: This feature will increase the capacity of tokens to almost twice as much. only llama support.
- BLOOM
- LLaMA
- LLaMA V2
- StarCoder
- Qwen-7b
- ChatGLM2-6b
- Baichuan-7b
- Baichuan2-7b
- Baichuan-13b
- InternLM-7b
When you start Qwen-7b, you need to set the parameter '--eos_id 151643 --trust_remote_code'.
ChatGLM2 needs to set the parameter '--trust_remote_code'.
Baichuan and Baichuan2 needs to set the parameter '--trust_remote_code'.
InternLM needs to set the parameter '--trust_remote_code'.
The code has been tested with Pytorch>=1.3, CUDA 11.8, and Python 3.9. To install the necessary dependencies, please refer to the provided requirements.txt and follow the instructions as
pip install -r requirements.txtYou can use the official Docker container to run the model more easily. To do this, follow these steps:
-
Pull the container from the GitHub Container Registry:
docker pull ghcr.io/modeltc/lightllm:main
-
Run the container with GPU support and port mapping:
docker run -it --gpus all -p 8080:8080 \ --shm-size 1g -v your_local_path:/data/ \ ghcr.io/modeltc/lightllm:main /bin/bash -
Alternatively, you can build the container yourself:
docker build -t <image_name> . docker run -it --gpus all -p 8080:8080 \ --shm-size 1g -v your_local_path:/data/ \ <image_name> /bin/bash
-
You can also use a helper script to launch both the container and the server:
python tools/quick_launch_docker.py --help
-
Note: If you use multiple GPUs, you may need to increase the shared memory size by adding
--shm-sizeto thedocker runcommand.
- Install from the source code by
python setup.py installThe code has been tested on a range of GPUs including A100, A800, 4090, and H800. If you are running the code on A100, A800, etc., we recommend using triton==2.0.0.dev20221202 or triton==2.1.0. If you are running the code on H800, etc., it is necessary to compile and install the source code of triton==2.1.0 from the GitHub repository. If the code doesn't work on other GPUs, try modifying the triton kernel used in model inference.
- Install Triton Package
use triton==2.0.0.dev20221202
pip install triton==2.0.0.dev20221202use triton==2.1.0 (Better performance, but the code is under continuous development and may be unstable.)
pip install -U --index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/Triton-Nightly/pypi/simple/ triton-nightlyWith efficient Routers and TokenAttention, LightLLM can be deployed as a service and achieve the state-of-the-art throughput performance.
Launch the server:
python -m lightllm.server.api_server --model_dir /path/llama-7B \
--host 0.0.0.0 \
--port 8080 \
--tp 1 \
--max_total_token_num 120000The parameter max_total_token_num is influenced by the GPU memory of the deployment environment. A larger value for this parameter allows for the processing of more concurrent requests, thereby increasing system concurrency. For more startup parameters, please refer to api_server.py or ApiServerArgs.md.
To initiate a query in the shell:
curl http://127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"What is AI?","parameters":{"max_new_tokens":17, "frequency_penalty":1}}' \
-H 'Content-Type: application/json'To query from Python:
import time
import requests
import json
url = 'http://localhost:8080/generate'
headers = {'Content-Type': 'application/json'}
data = {
'inputs': 'What is AI?',
"parameters": {
'do_sample': False,
'ignore_eos': False,
'max_new_tokens': 1024,
}
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
print(response.json())
else:
print('Error:', response.status_code, response.text)We compared the service performance of LightLLM and vLLM==0.1.2 on LLaMA-7B using an A800 with 80G GPU memory.
To begin, prepare the data as follows:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.jsonLaunch the service:
python -m lightllm.server.api_server --model_dir /path/llama-7b --tp 1 --max_total_token_num 121060 --tokenizer_mode autoEvaluation:
cd test
python benchmark_serving.py --tokenizer /path/llama-7b --dataset /path/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 2000 --request-rate 200The performance comparison results are presented below:
| vLLM | LightLLM |
|---|---|
| Total time: 361.79 s Throughput: 5.53 requests/s |
Total time: 188.85 s Throughput: 10.59 requests/s |
For debugging, we offer static performance testing scripts for various models. For instance, you can evaluate the inference performance of the LLaMA model by
cd test/model
python test_llama.py- The LLaMA tokenizer fails to load.
- consider resolving this by running the command
pip install protobuf==3.20.0.
- consider resolving this by running the command
error : PTX .version 7.4 does not support .target sm_89- launch with
bash tools/resolve_ptx_version python -m lightllm.server.api_server ...
- launch with
For further information and discussion, join our discord server.
This repository is released under the Apache-2.0 license.
We learned a lot from the following projects when developing LightLLM.