MixedWM38 Dataset(WaferMap) has more than 38000 wafer maps, including 1 normal pattern, 8 single defect patterns, and 29 mixed defect patterns, a total of 38 defect patterns.
Defect pattern recognition (DPR) of wafermap, especially the mixed-type defect, is critical for determining the root cause of production defect.
We collected a large amount of wafer map data in a wafer manufacturing plant. These wafer maps are obtained by testing the electrical performance of each die on the wafer through test probes. However, there are big differences between the quantity distribution of various patterns of wafermap actually collected.
To maintain the balance between the various patterns of data, we used the generative adversarial networks to generate some wafer maps to maintain the balance of the number of samples among the patterns. Finally, about 38,000 mixed-type wafermap defect dataset is formed, which are used to identify mixed-type wafermap defect and assist the research on the causes of defect in the wafer manufacturing process. In order to facilitate researchers, students, and enthusiasts in related fields to better understand the causes of defects in the wafer manufacturing process, we public this dataset of mixed-type wafermap defect for you to research.
-
Overview:
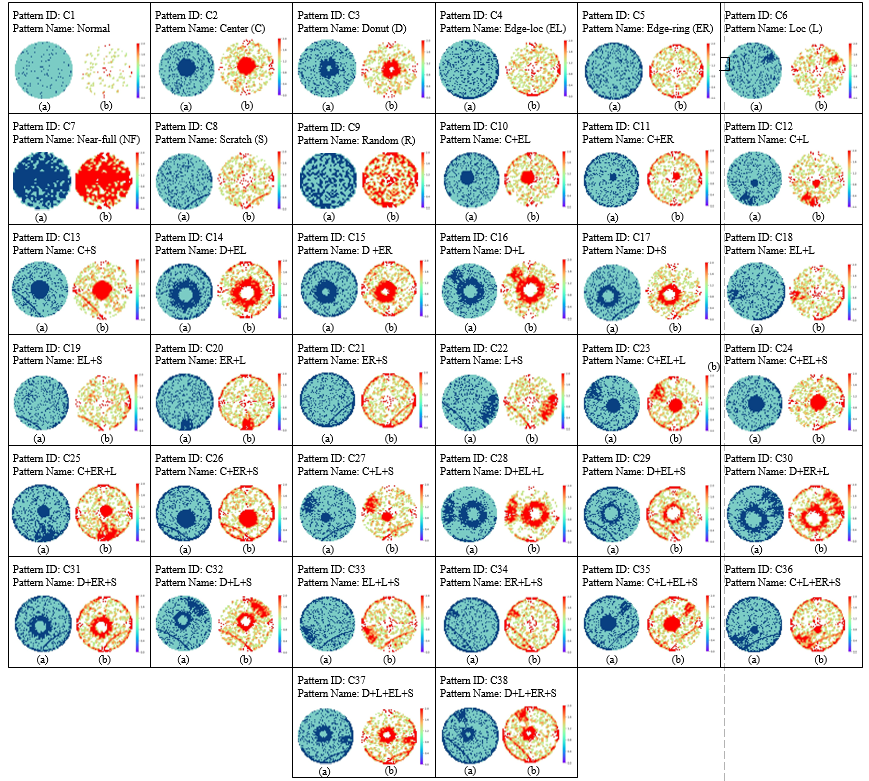
-
Patterns: Provided by Mr. Uzma Batool from the University of Technology Malaysia
Single Type(9):
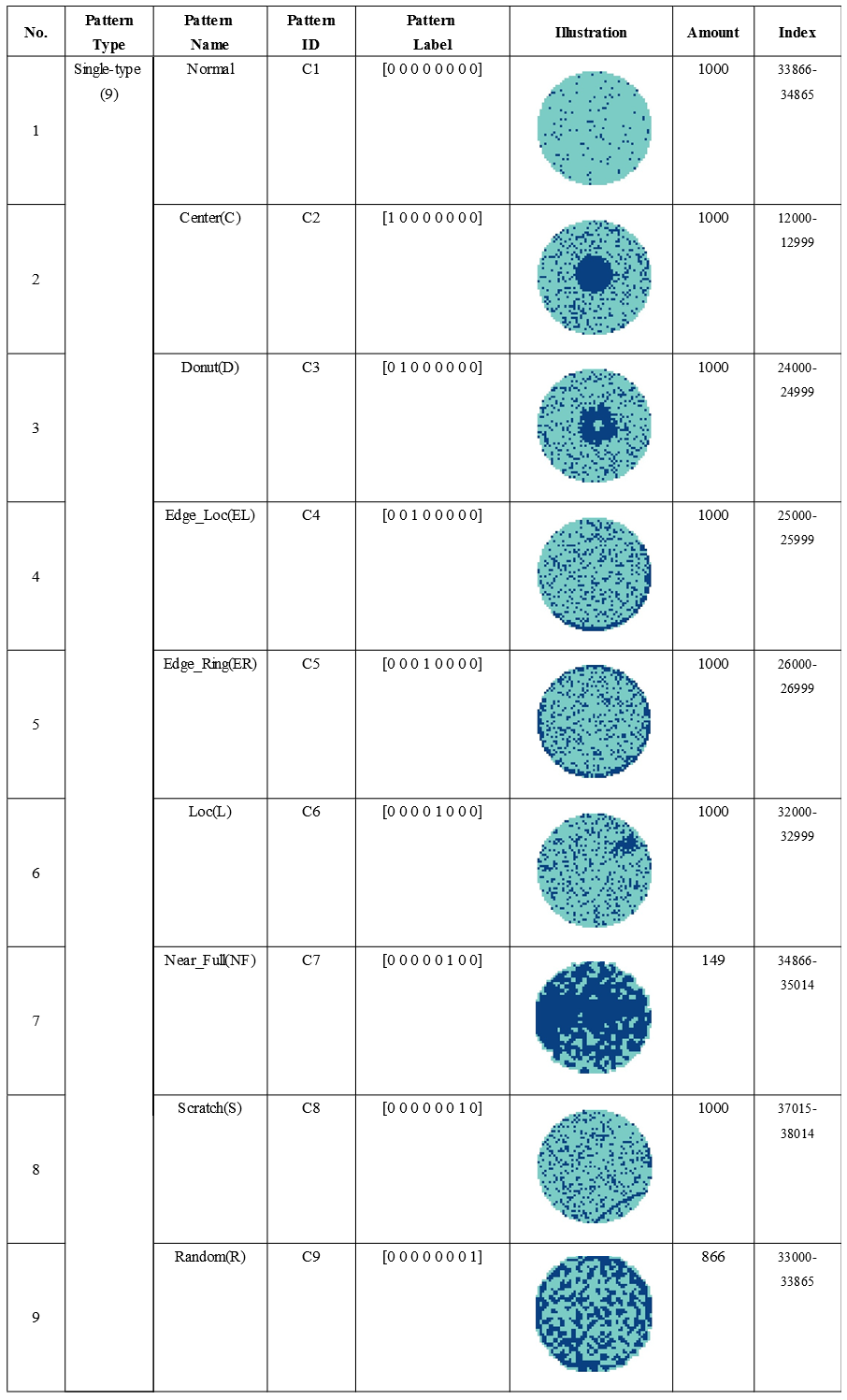
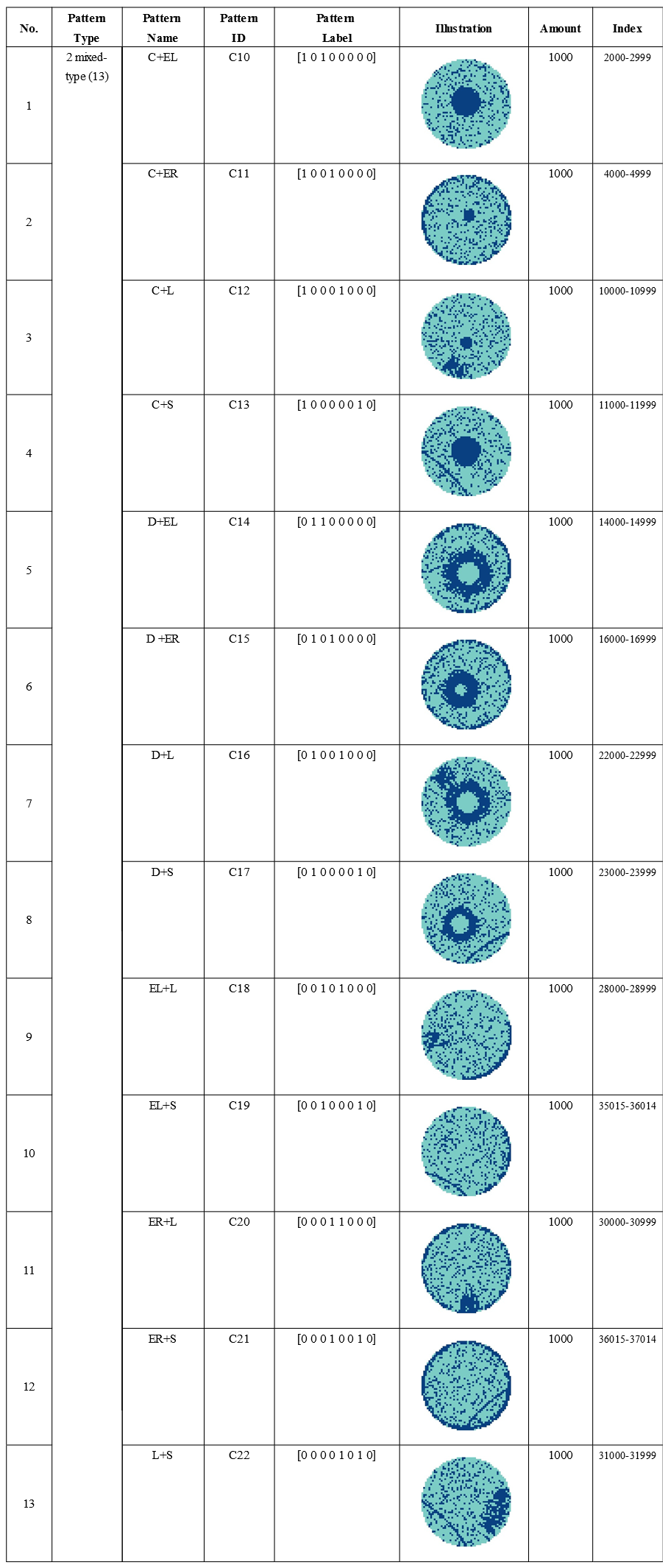
Two Mixed-Type(13):
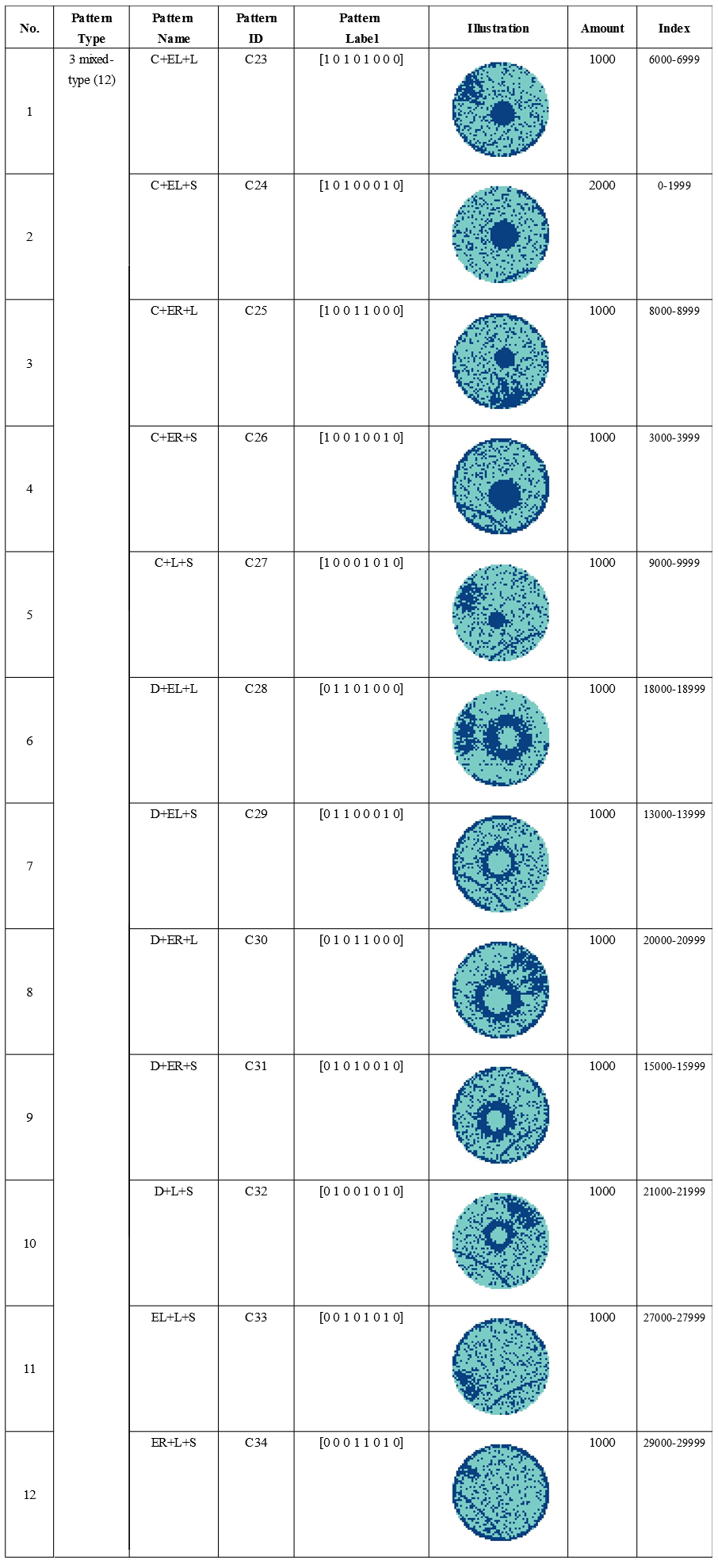
Three Mixed-Type(12):
Four Mixed-Type(4):
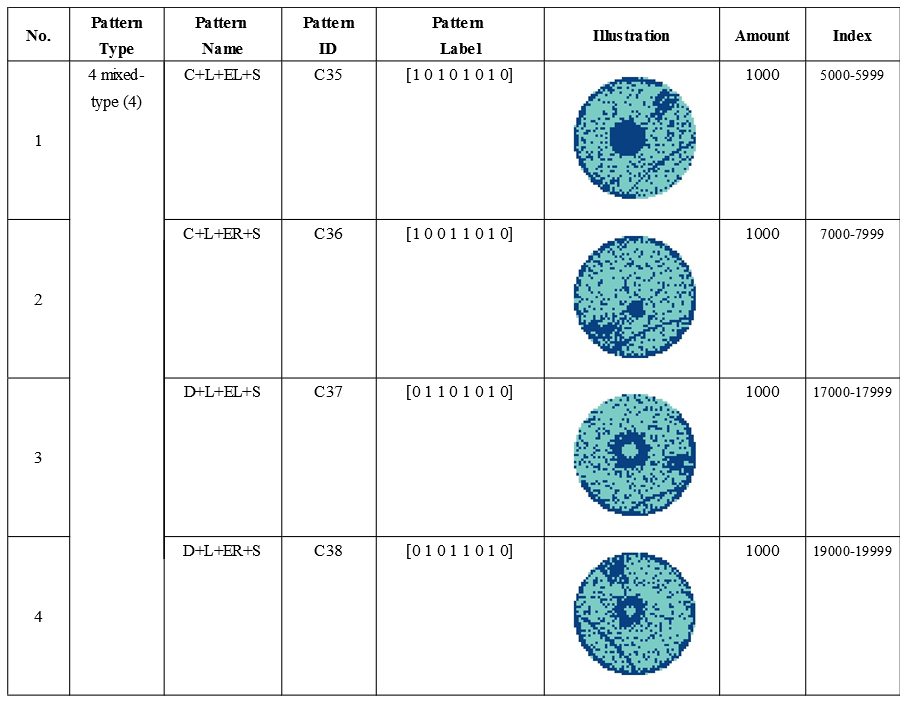
-
[‘arr_0’]: Defect data of mixed-type wafer map, 0 means blank spot, 1 represents normal die that passed the electrical test, and 2 represents broken die that failed the electrical test. The data(ndarray) shape is (52, 52).
-
[‘arr_1’]: Mixed-type wafer map defect label, using one-hot encoding, a total of 8 dimensions, corresponding to the 8 basic types of wafer map defects (C2-C9).
-
Basemodel:
Training -
More:
MixedWM38





-
Python 3+
-
numpy scipy matplotlib tensorflow keras scikit-learn
- Chinese:
混合模式晶圆图缺陷数据集
Thanks to Mr. Uzma Batool from the University of Technology Malaysia for correcting the label errors in the original dataset! The C7 and C9 labels in the dataset have been corrected!