In this project, We are going to demonstrate all the things required to make the best ML model live for end-user.
We will go through creating AutoML experiment to deploying model for end user. Also we will evaluate the endpoint by consuming it. We will check the stability and performance of the endpoint by enabling the logs and benchmarking the endpoint. To allow other developers to understand the endpoint, we will demonstrate how to use swagger for it.
At last, to automate this process for dev-ops purpose, we will create one pipeline which uses the Azure SDK to perform all the above operations through notebook.

The key steps are as follows.
-
Automated ML Experiment
To operationalize the ML model for end users, first we should have our prepared dataset and model configuration for that dataset should be ready which is Bank marketing dataset in our case.
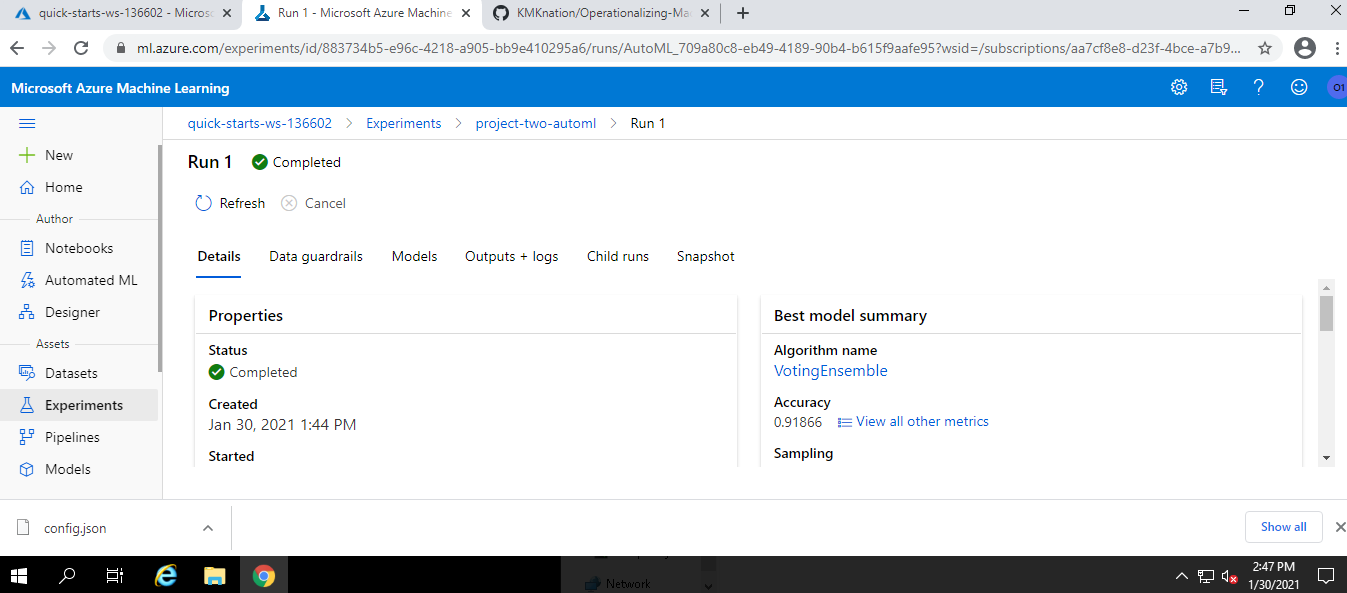
After the model configuration, we have to start the experiment and wait for the experiment to get complete.
After the successfuly run of the experiment, we would have the best model. In our case it is Voting Classifier.
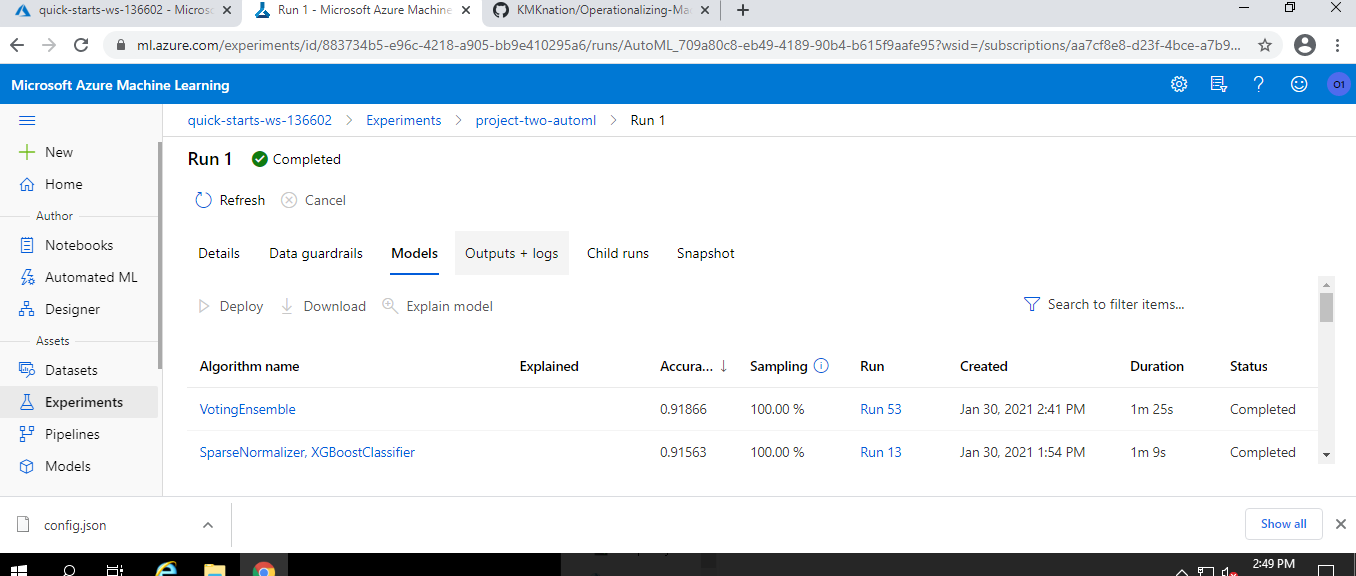
-
Deployment
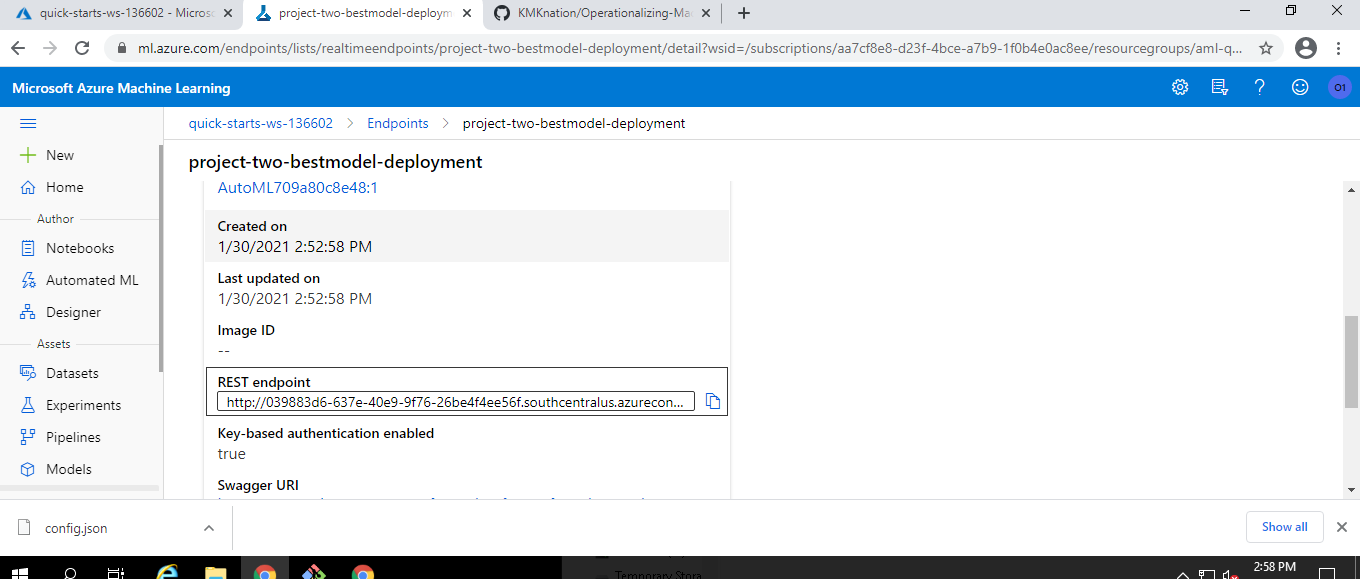
After getting the best model, now we are good to go for the deployment of the best model. We can deploy the model by clicking the Deploy button given in model details.
When the deployment gets successfull, we can see our Rest API endpoint under the endpoints section of Azure ML Studio.
-
Consume
Completing the above deployment process, we have our endpoint ready to consume. But before that there are some checklist we need to follow to ensure the stability of the endpoint.
To do that we have following checklist.
-
Enable Logs
This step is need to check whether our enpoint gets successfulyy deployed or not.
After enabling the log, we will able to see the insight url in ML Studio.
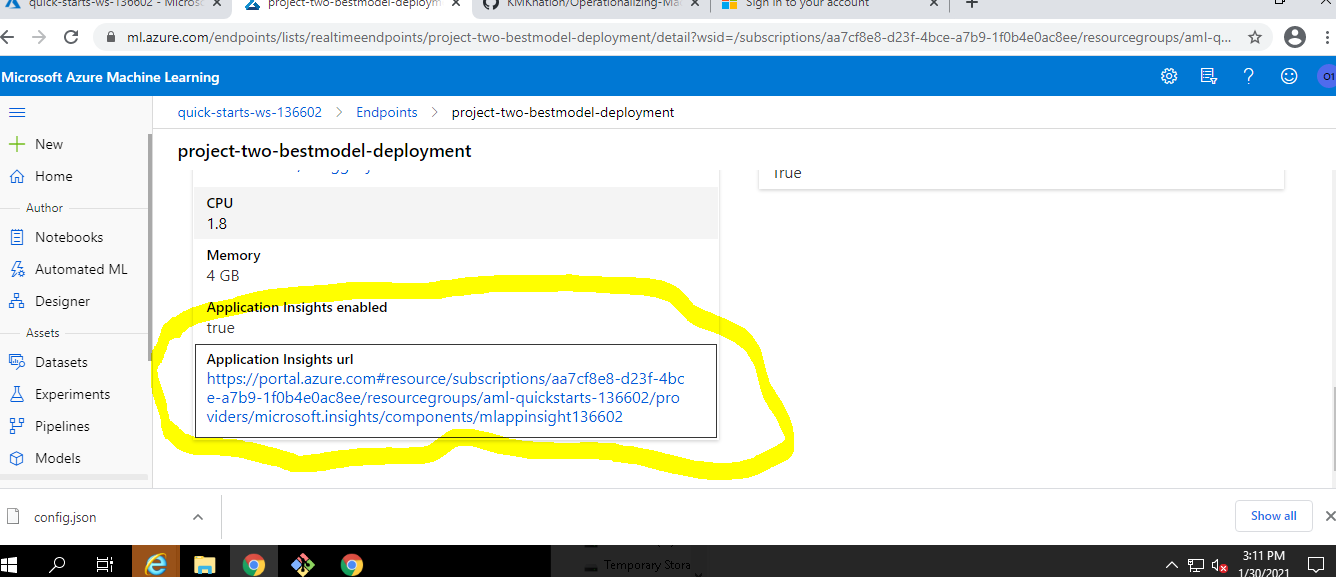
-
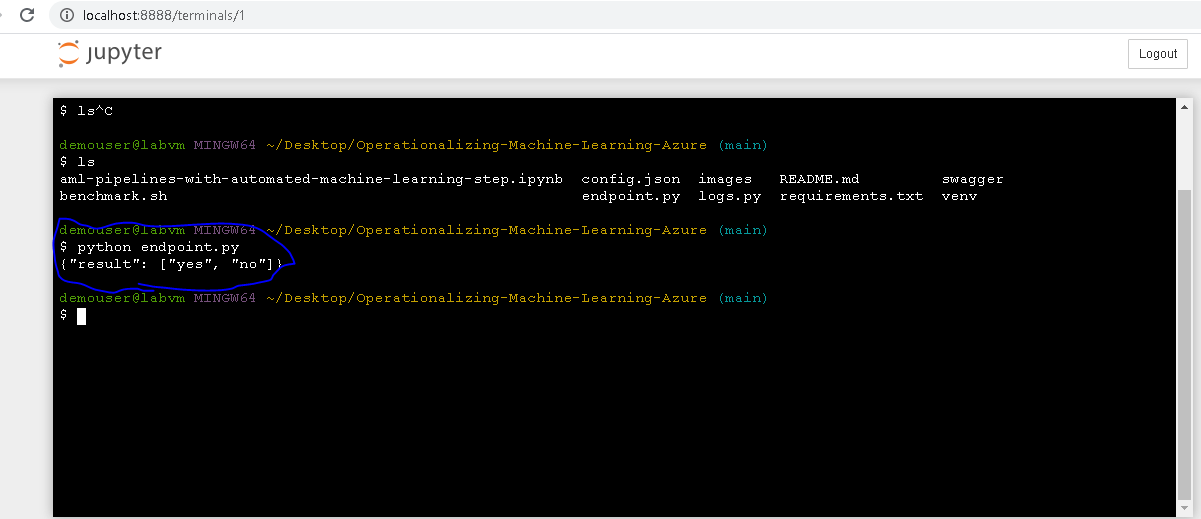
Make rest call to endpoint
When we make an API call to our endpoint with sample data, we are able to see the inference output of the model.
-
Benchmark the endpoint
However, just getting working enpoint is not enough, Thus, we also have measure the time taken by enpoint to give the output. By doing this, we can ensure that our endpoint's performance for end-user.
-
-
Swagger Documentation
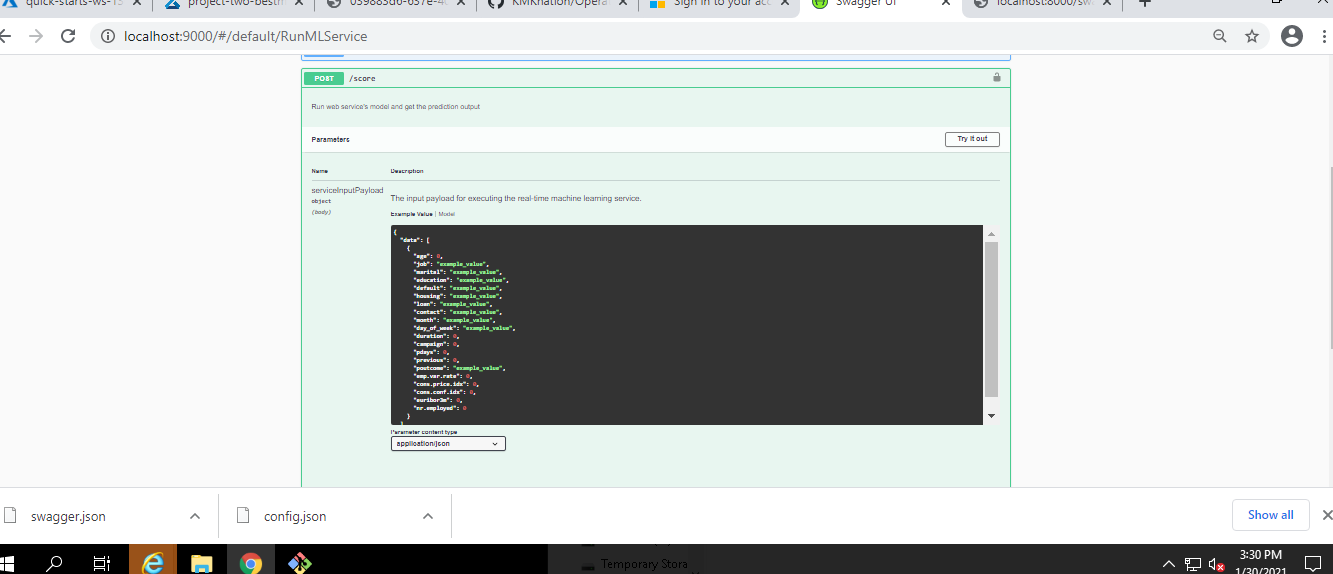
At this point, we have our model endpoint is ready and consummable but we also have to document the endpoint so that the other developers can able to understand the usecase of the endpoint.
Swagger document can be available in endpoint details section as a swagger.json file.
-
Pipeline Automation
All the above steps, needs manual intervation for each thing. To automate above steps, Azure ML provides this pipeline option.
In this pipeline, the developer have to create a python script or notebook with following steps.
- Create an Experiment in an existing Workspace.
- Create or Attach existing AmlCompute to a workspace.
- Define data loading in a TabularDataset.
- Configure AutoML using AutoMLConfig.
- Use AutoMLStep
- Train the model using AmlCompute
- Explore the results.
- Test the best fitted model.
Through these above steps, we can also automate the MLOps pipeline through one script.
Following are screenshout which we can see in Azure ML Studio.
-
Pipeline Creation
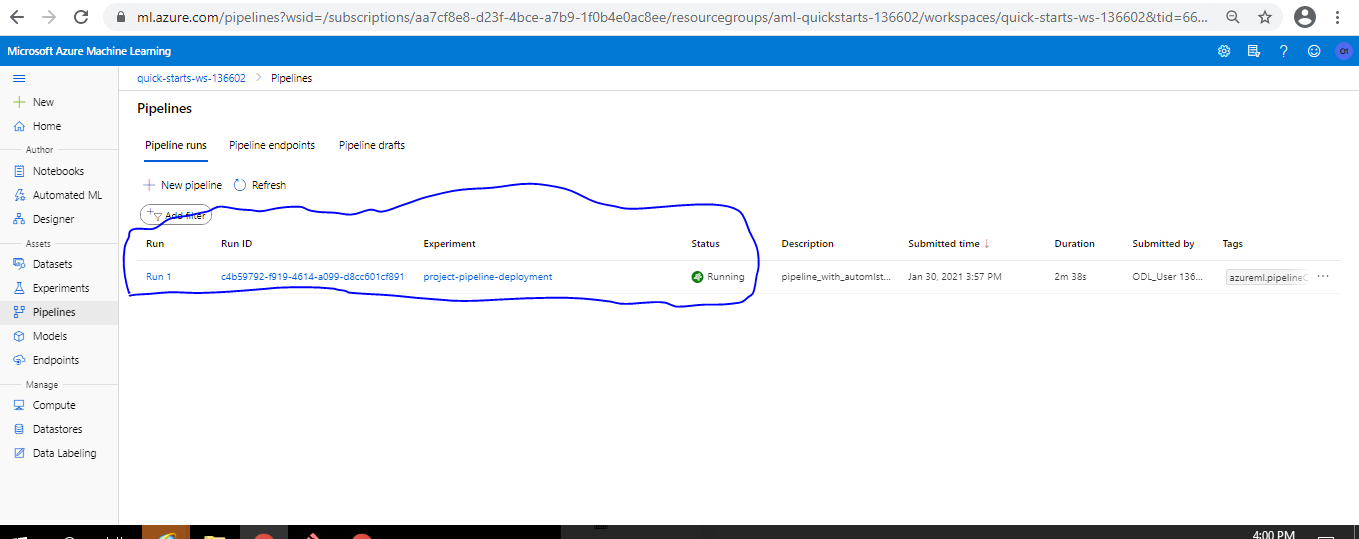
-
Pipeline Runnning
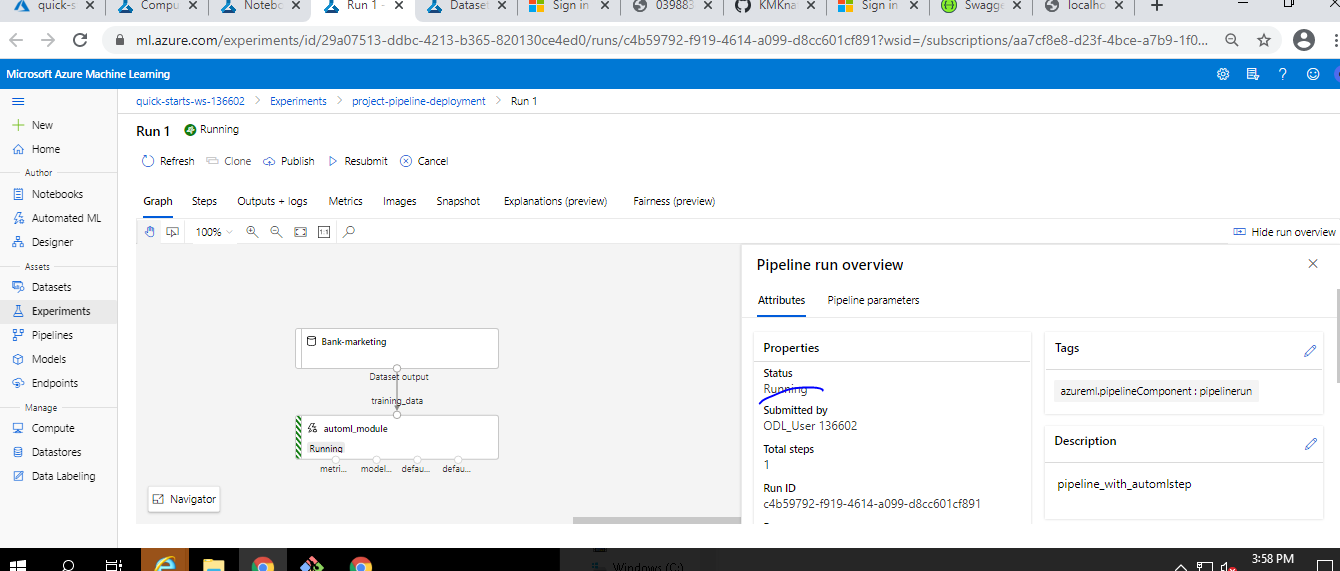
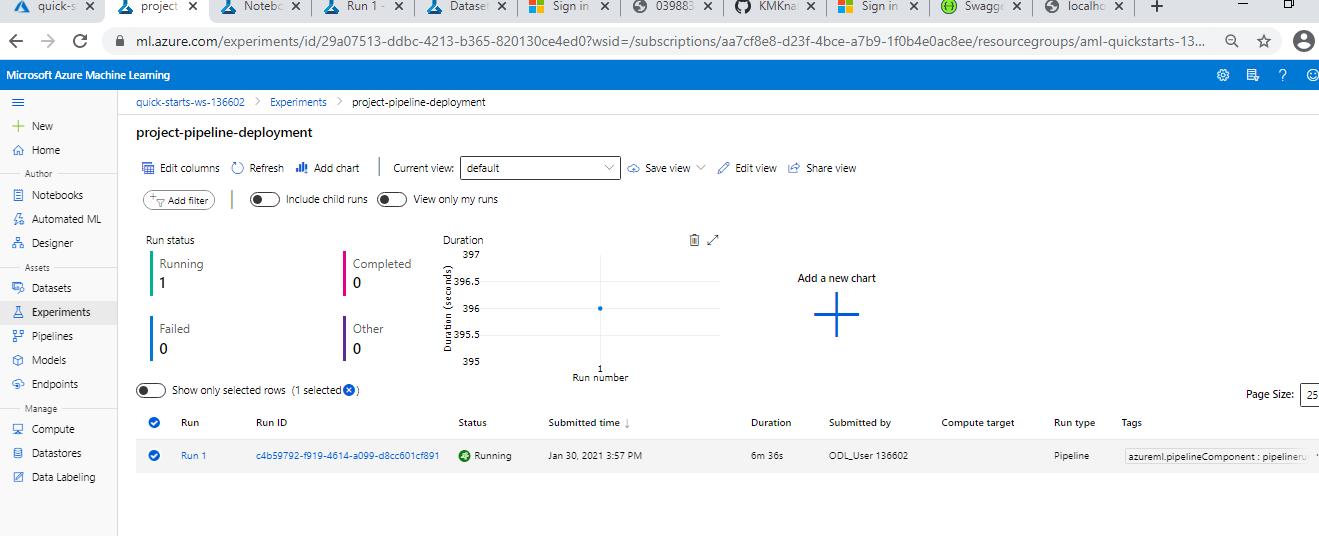
-
Pipeline Complete
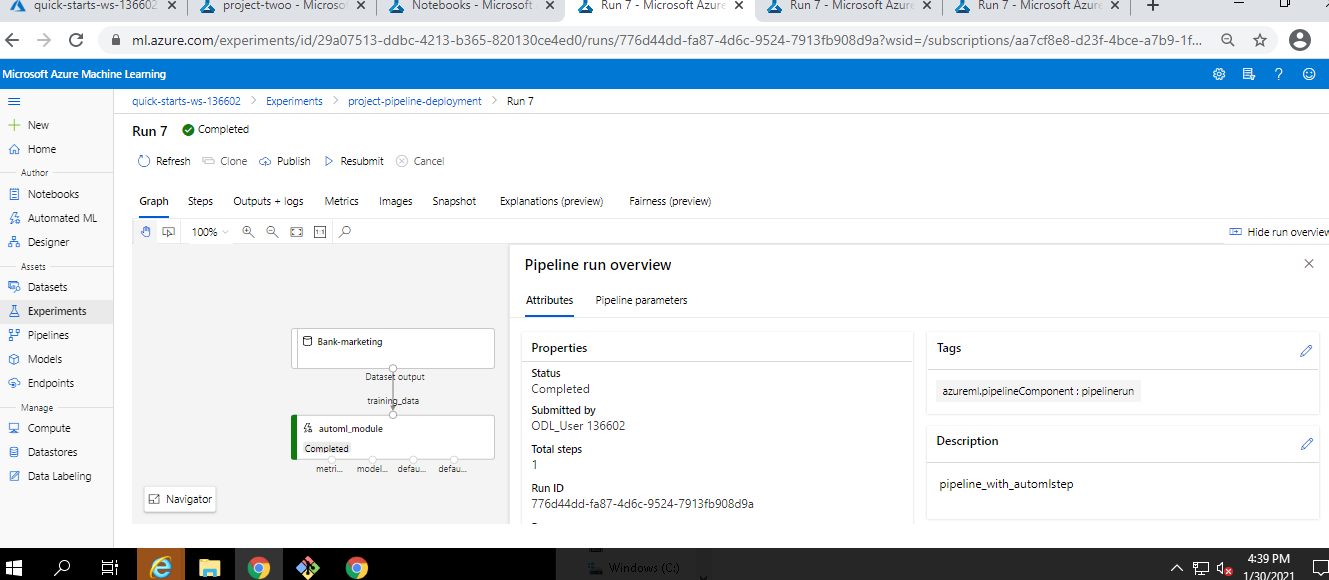
-
Pipeline Run Log
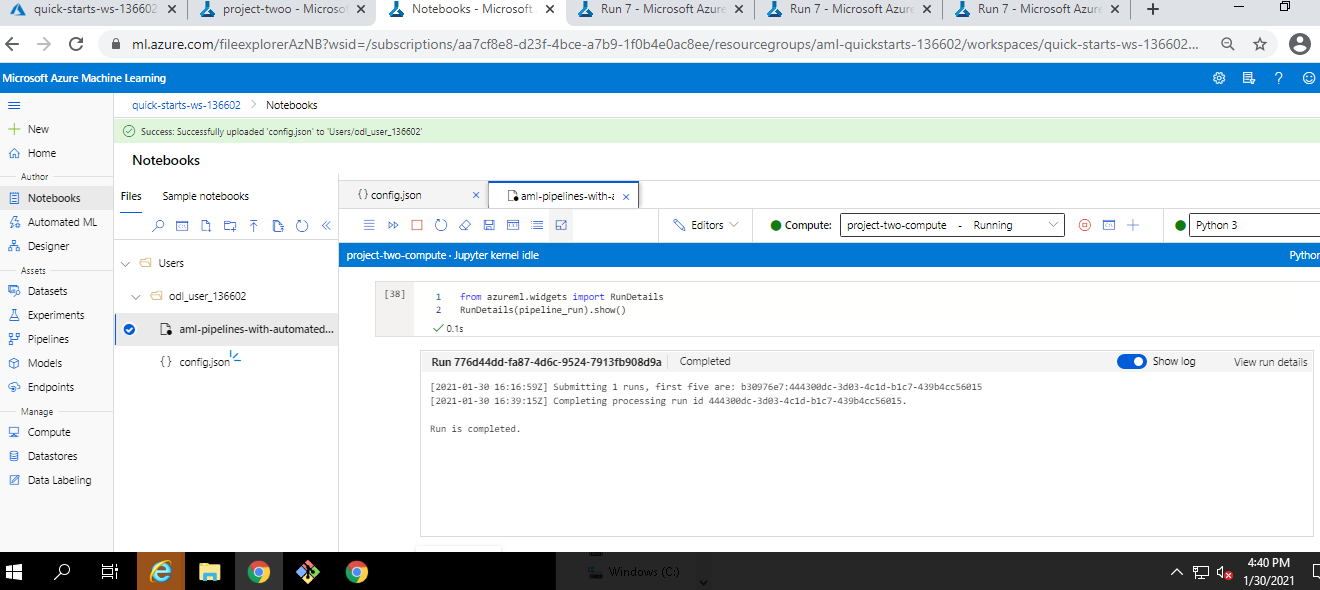
-
Pipeline Endpoint Active
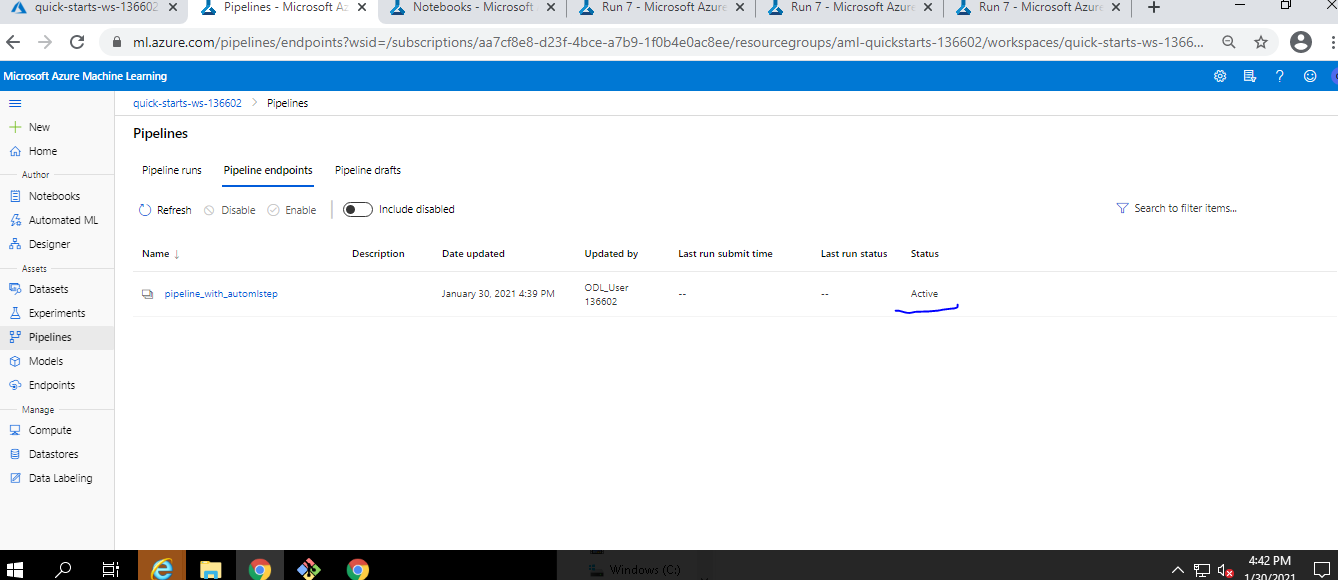
-
Pipeline End Point URL
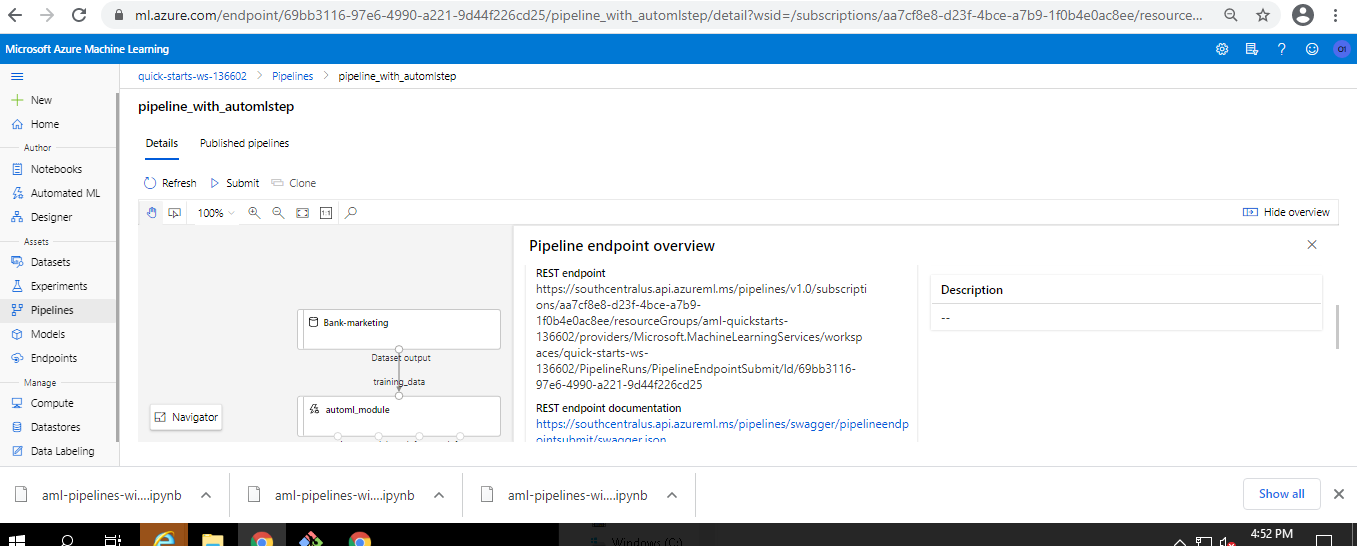
-
Deallocate Compute Cluster
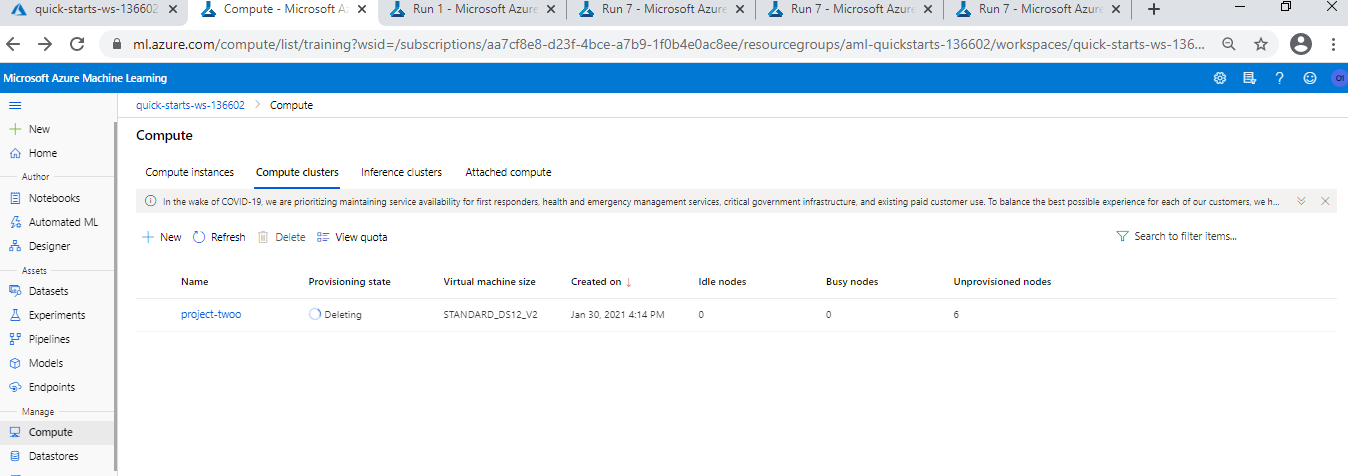

















URL: https://youtu.be/pndxfhW3kp0
- Right now, we have to set the minimum cluster and maximum hours to train. But If we connect this both things just ask user to enter minutes to complete the whole automl cycle and the studio automatically allocates clusters to achieve concurrency would be great. However this is one of costlier thing to do but in some emergency scenario, it might be usefull one.
- Right now, this whole solution is on cloud. Hence, For first run, we are just experimenting which code gets run perfectly on cloud and keeps improving the pipeline which leads to multiple consumption of compute clusters or instances for just experiment. If in future there would be option to run the azure solution by using local computer's resource for experiments and then deploying the soluiton with azure cloud would be must cost savier.
- There should be a option to set enable push notification on failure/suceess of the deployment/training process.
- There should also have one option allowing the developer to choose type of documentation to download. Like swagger or postman.
- It would be nice if we can automate the pipeline for CNN type algorithms.