![]()
![]()
![]()
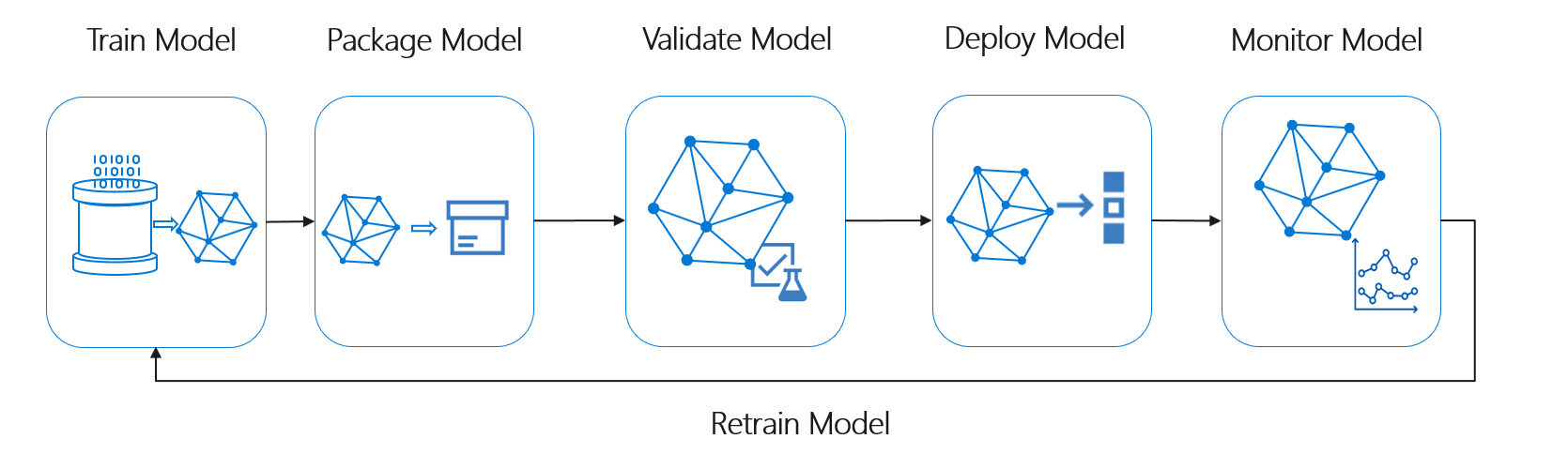
This project will be a guideline for you to get started with machine learning cycle from development to production. It will explain step-by-step from data analysis, data preprocessing, data augmentation pipeline, building model training pipeline using PyTorch Lightning, tracking the experiments with W&B, and finally deploying the model using FastAPI.
Altough this guideline explains about computer vision, but it is also aplicable to other modalitites.
Deep learning has revolutionized the field of computer vision, enabling computers to understand and interpret visual data with remarkable accuracy. This project aims to provide a beginner-friendly approach to explore into the deep learning for computer vision. By following the outlined steps, you will gain hands-on experience in developing a simple classification model using the Food-101-tiny dataset.
The project consists of the following stages:
- Data Analysis: Exploring and analyzing the dataset to gain insights.
- Data Preprocessing and Augmentation: Preparing the data and Implementing techniques augment the dataset.
- Data Visualization using Fiftyone: Using fiftyone to visualize dataset.
- Simple Lightning Pipeline: Constructing a pipeline to train the model using PyTorch Lightning.
- Tracking Experiments with W&B: Monitoring and tracking the experiments using W&B.
- Advanced Training Pipeline: Advanced method to run multiple experiments and hyperparameter search using Hydra and Optuna.
- Model Optimization: Optimizing model latency using ONNX.
- Deploying the Model using Gradio: Deploying model with simple interface using Gradio.
- Deploying the Model using FastAPI: Deploying model as a web app using FastAPI.
The project includes the following folders:
- src: Contains model development scripts, e.g. model, dataset, and utilities
- configs: Configuration files to run lightning pipeline using Hydra
- pretrained: Pretrained model for inference
Each folder will have several notebooks, each corresponding to a specific step in the process.

For this project, we will be using the Food-101-tiny dataset. It is a collection of images categorized into 101 different food classes. The dataset provides a diverse range of food images for classification tasks. The original Food-101 dataset contains images for 101 different classes of foods. Each class has 750 training images and 250 test images.
The original purpose of this dataset was to speed development and prototyping of an image classifier on the full Food-101 dataset and was used to experiment with a variety of techniques, including progressive resizing, label smoothing, and mixup. Training times should be under 30 seconds per epoch when using an image size of 224 or 256 and under a minute when using the max image size 512. We hope it will help anyone who's looking to quickly test out new ideas for improving performance on the original Food-101 dataset.
Food-101-tiny only contains 150 training images and 50 validation images for 10 easily classified foods: apple pie, bibimbap, cannoli, edamame, falafel, french toast, ice cream, ramen, sushi, and tiramisu.
Please ensure you have downloaded and set up the dataset before proceeding with the project.
KAGGLE_USERNAME=kaggle_username KAGGLE_KEY=kaggle_secret_key sh download_dataset.sh
Let's dive into the exciting world of deep learning for computer vision and develop a powerful food classification model together!