

![]()


- Install
- Usage
- Details
- Functionalities
- Benchmarks
- Quantized model scores
- further improvements
- License
- Get Help
- Acknowledgements
T5 models can be used for several NLP tasks such as summarization, QA, QG, translation, text generation, and more. Sequential text generation is naturally slow, and for larger T5 models it gets even slower. fastT5 makes the T5 models inference faster by running it on onnxruntime. and it also decreases the model size by quantizing it.
fastT5 library allows you to convert a pretrained T5 model to onnx, quantizes it, and gives the model as output which is running on an onnxruntime in a single line of code. You can also customize this whole process.
You can install fastT5 from PyPI:
pip install fastt5If you want to build from source:
git clone https://github.com/Ki6an/fastT5
cd fastT5
pip3 install -e .The export_and_get_onnx_model() method exports the given pretrained T5 model to onnx, quantizes it and runs it on the onnxruntime with default settings. The returned model from this method supports the generate() method of huggingface.
If you don't wish to quantize the model then use
quantized=Falsein the method.
from fastT5 import export_and_get_onnx_model
from transformers import AutoTokenizer
model_name = 't5-small'
model = export_and_get_onnx_model(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
t_input = "translate English to French: The universe is a dark forest."
token = tokenizer(t_input, return_tensors='pt')
tokens = model.generate(input_ids=token['input_ids'],
attention_mask=token['attention_mask'],
num_beams=2)
output = tokenizer.decode(tokens.squeeze(), skip_special_tokens=True)
print(output)to run the already exported model use
get_onnx_model()
you can customize the whole pipeline as shown in the below code example:
from fastT5 import (OnnxT5, get_onnx_runtime_sessions,
generate_onnx_representation, quantize)
from transformers import AutoTokenizer
model_or_model_path = 't5-small'
# Step 1. convert huggingfaces t5 model to onnx
onnx_model_paths = generate_onnx_representation(model_or_model_path)
# Step 2. (recommended) quantize the converted model for fast inference and to reduce model size.
quant_model_paths = quantize(onnx_model_paths)
# step 3. setup onnx runtime
model_sessions = get_onnx_runtime_sessions(quant_model_paths)
# step 4. get the onnx model
model = OnnxT5(model_or_model_path, model_sessions)
...By default, fastT5 creates a models folder in the current directory and stores all the models. You can provide a custom path for a folder to store the exported models. And to run already exported models that are stored in a custom folder path: use get_onnx_model(onnx_models_path="/path/to/custom/folder/")
from fastT5 import export_and_get_onnx_model, get_onnx_model
model_name = "t5-small"
custom_output_path = "/path/to/custom/folder/"
# 1. stores models to custom_output_path
model = export_and_get_onnx_model(model_name, custom_output_path)
# 2. run already exported models that are stored in custom path
# model = get_onnx_model(model_name, custom_output_path)T5 is a seq2seq model (Encoder-Decoder), as it uses decoder repeatedly for inference, we can't directly export the whole model to onnx. We need to export the encoder and decoder separately.
past_key_valuescontain pre-computed hidden-states (key and values in the self-attention blocks and cross-attention blocks) that can be used to speed up sequential decoding.
models can only be exported with a constant number of inputs. Contrary to this, the decoder of the first step does not take past_key_values and the rest of the steps decoders do. To get around this issue, we can create two decoders: one for the first step that does not take past_key_values and another for the rest of the steps that utilize the past_key_values.
Next, we'll export all three models (encoder, decoder, init_decoder). And then quantize them, quantizing 32bit to 8bit should give the 4x memory reduction. Since there is an extra decoder the model size reduces by 3x.
Finally, we'll run the quantized model on onnx runtime.
The inference is simple as the model supports the
generate()method of huggingface.
- Export any pretrained T5 model to ONNX easily (with
past_key_values). - The exported model supports beam search and greedy search and more via
generate()method. - Reduce the model size by
3Xusing quantization. - Up to
5Xspeedup compared to PyTorch execution for greedy search and3-4Xfor beam search.
The benchmarks are the result of the T5-base model tested on English to French translation.
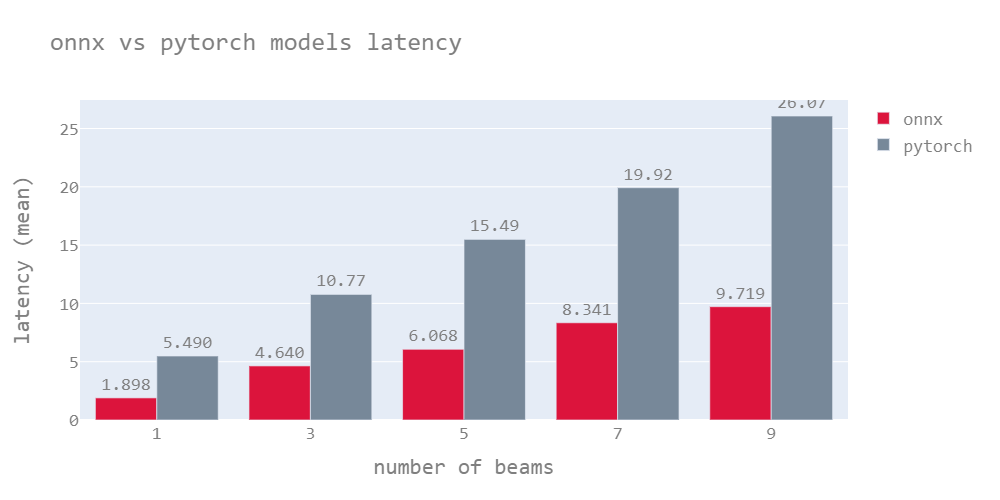
The following graph shows the latency of the quantized onnx model vs the PyTorch model for beam numbers varying from 1 to 9. The latencies shown here are for the mean of sequence lengths up to 130.
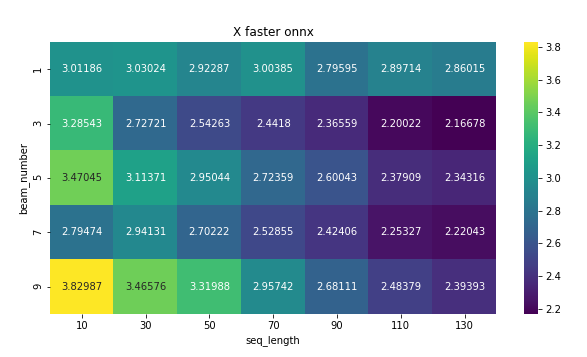
The following heat map shows the X times faster which the ratio of latency of PyTorch to onnx model. The onnx model outperforms most cases. however, the speed of the model drops for a longer sequence length.
Quantized models are lightweight models as mentioned earlier, these models have almost the same accuracy as the original model (quantized model scores are mentioned in the next section). Quantized onnx models have the lowest latency compared to both Onnx & PyTorch models.
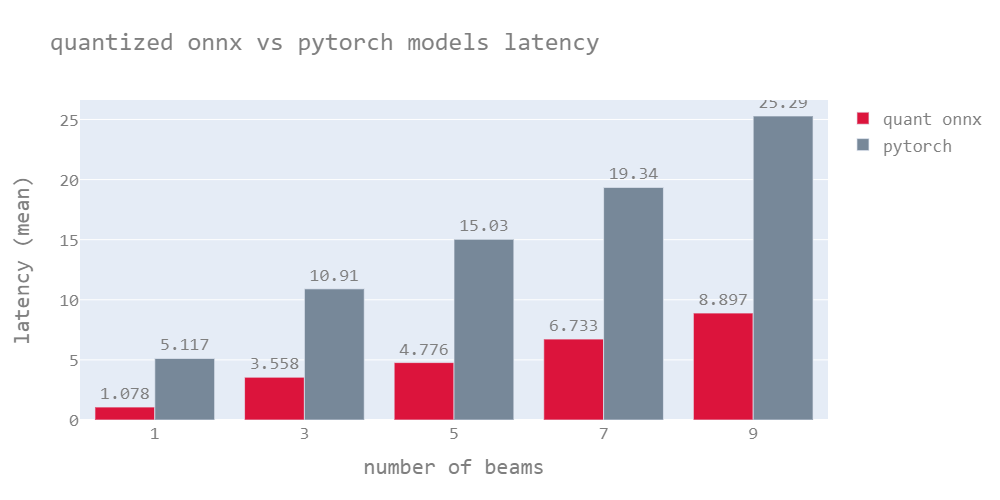
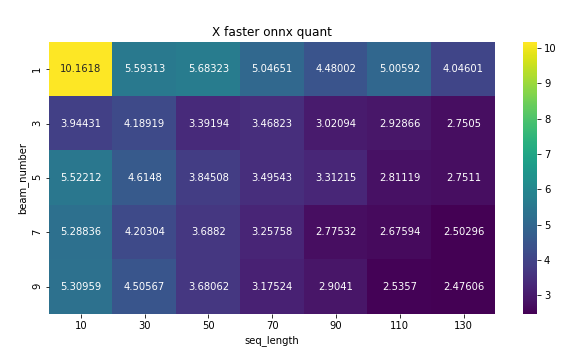
The model outperforms the PyTorch model by 5.7X for greedy search on average and 3-4X for beam search.
Note : The results were generated on
AMD EPYC 7B12, these results may vary from device to device. The Onnx models usually perform well on high-end CPUs with more cores.
The results were tested for English to French translation with beam search number of 3.
| Bleu_4 | METEOR | ROUGE_L | |
|---|---|---|---|
| t5-small (quant) | 0.240769 | 0.282342 | 0.468817 |
| t5-small (pytorch) | 0.254601 | 0.295172 | 0.492749 |
| t5-base (quant) | 0.267606 | 0.306019 | 0.499188 |
| t5-base (pytorch) | 0.268346 | 0.304969 | 0.503306 |
| t5-large (quant) | 0.286726 | 0.316845 | 0.503585 |
| t5-large (pytorch) | 0.294015 | 0.315774 | 0.508677 |
The HuggingFace model hub supports private models. To use a private, pre-trained version of T5 with fastT5 you first must have authenticated into HuggingFace ecosystem with $ transformers-cli login. Then, when using fastT5, there is an extra import and call:
from fastT5 import (
OnnxT5,
get_onnx_runtime_sessions,
generate_onnx_representation,
quantize,
set_auth_token)
from transformers import AutoTokenizer
set_auth_token(True)
# the rest of the code is the same as using a public modelIf you are unable to call $ transformers-cli login or prefer to use your API Key, found at https://huggingface.co/settings/token (or https://huggingface.co/organizations/ORG_NAME/settings/token for organizations), you can pass that as a string to set_auth_token. Avoid hard-coding your API key into code by setting the environment variable HF_API_KEY=<redacted>, and then in code:
import os
from fastT5 import (
OnnxT5,
get_onnx_runtime_sessions,
generate_onnx_representation,
quantize,
set_auth_token)
from transformers import AutoTokenizer
auth_token = os.environ.get("HF_API_KEY")
set_auth_token(auth_token)
# code proceeds as normal- currently the fastT5 library supports only the cpu version of onnxruntime, gpu implementation still needs to be done.
- graph optimization of the onnx model will further reduce the latency.
- Contact me at kiranr8k@gmail.com
- If appropriate, open an issue on GitHub
- original T5 paper
- transformers by huggingface
- onnx
- onnxruntime by microsoft
- onnxt5
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}