해당 주에 공부한 내용을 추가할 경우!
해당 Week 폴더를 생성한 후 그 폴더 내에 추가해주세요!!😀
💵Stack
한 쪽 끝에서만 자료를 넣거나 뺄 수 있는 선형 구조 형식의 자료구조
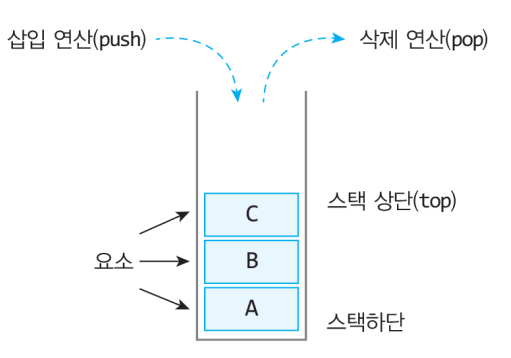
스택의 핵심 연산
push(x):새로운 요소를 스택에 삽입
pop():스택에서 맨 위에 있는 요소를 삭제하고 반환
peek():스택의 마지막 요소를 삭제 하지 않고 반환
is_empty():스택이 비어있는지 확인
size():스택에 들어 있는 요소의 개수 반환
class Stack {
constructor() {
this._arr = [];
}
push(item) {
this._arr.push(item);
}
pop() {
return this._arr.pop();
}
peek() {
return this._arr[this._arr.length - 1];
}
is_empty() {
return this.size() === 0;
}
size() {
return this._arr.length;
}
}
const stack = new Stack();
stack.push(1);
stack.push(2);
stack.is_empty(); // 2
stack.is_empty(); // false
stack.peek(); // 2
stack.push(3);
stack.pop(); // 3🎳Queue
한쪽 끝에서만 삽입이 이루어지고, 다른 한쪽 끝에서는 삭제 연산만 이루어지는 유한 순서 리스트이다.
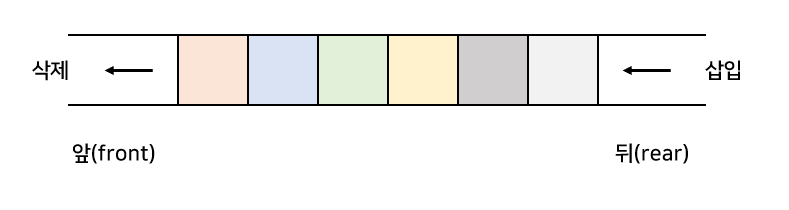
- 선형 큐
- 원형 큐
- 특징
선형 큐에서는 rear가 배열 크기와 같아지면 큐가 꽉 찼다고 판단하며, front와 rear가 동일한 위치를 가리키면 큐가 비었다고 판단한다.

- 문제점
선형 큐는 원소 삭제 시 앞에서부터 공간이 남게 되는데, 이때 뒤의 원소들을 앞으로 당겨주지 않으면 빈 공간이 많이 남아 있음에도 불구하고 더 이상 원소를 추가하지 못하는 문제가 발생할 수 있다. 그렇다고 삭제 연산이 일어날 때마다 원소들을 한칸씩 앞으로 당기기에는 매우 비효율적이다.
- 코드 구현
출처: https://hokeydokey.tistory.com/31
class queueType {
constructor(size) {
this.maxSize = size;
this.front = -1;
this.rear = -1;
this.array = [];
}
enque(item) {
if (this.rear != this.maxSize - 1) {
this.array[++this.rear] = item;
} else {
console.log(new Error("queue is full"));
}
}
deque() {
if (this.front == this.rear) {
console.log(new Error("queue is empty"));
} else {
++this.front;
return this.array[this.front];
}
}
print() {
let string = "";
for (let i = 0; i < this.maxSize; i++) {
if (this.front >= i || i > this.rear) {
string += " | ";
} else {
string += `${this.array[i]} | `;
}
}
console.log(string);
}
}
let queue = new queueType(5);
queue.enque("10");
queue.enque("23");
queue.enque("32");
queue.print();
queue.deque();
queue.deque();
queue.deque();
queue.print();- 특징
원형큐는 선형큐와 달리 원형의 모양을 하고 있으며 이 queue의 공간에 아이템이 꽉 차지 않는 이상 언제든 enque와 deque를 할 수 있다.


- 코드 구현
출처: https://hokeydokey.tistory.com/37
class CircleQueue {
constructor(size) {
this.maxQueueSize = size;
this.array = [];
this.front = 0;
this.rear = 0;
}
isEmpyt() {
return this.front == this.rear;
}
isFull() {
return (this.rear + 1) % this.maxQueueSize == this.front;
}
enQueue(item) {
if (this.isFull()) {
console.log(new Error("큐가 포화상태입니다."));
} else {
this.rear = (this.rear + 1) % this.maxQueueSize;
this.array[this.rear] = item;
}
}
deQueue() {
if (this.isEmpyt()) {
console.log(new Error("큐가 비었습니다."));
} else {
this.front = (this.front + 1) % this.maxQueueSize;
return this.array[this.front];
}
}
print() {
if (this.isEmpyt()) {
console.log(new Error("큐가 비었습니다."));
}
let string = "";
let i = this.front;
do {
i = (i + 1) % this.maxQueueSize;
string += this.array[i] + "|";
if (i == this.rear) {
console.log(string);
break;
}
} while (i != this.front);
}
}
let queue = new CircleQueue(5);
queue.enQueue(1);
queue.enQueue(2);
queue.enQueue(3);
queue.enQueue(4);
queue.deQueue();
queue.enQueue(5);
queue.print();🔛Deque
double-ended queue의 줄임말로서 큐의 전단(front)과 후단(rear)에서 모두 삽입과 삭제가 가능한 큐를 의미한다.

스택의 핵심 연산
add_front(e): 주어진 요소e를 덱의 맨 앞에 추가한다.
delete_front(): 전단 요소를 삭제하고 반환한다.
add_rear(e): 주어진 요소도 e를 덱의 맨 뒤에 추가한다.
delete_rear(): 후단 요소를 삭제하고 반환한다.
get_front(): 전단 요소를 삭제하지 않고 반환한다.
get_rear(): 후단 요소를 삭제하지 않고 반환한다.
is_empty(): 공백 상태이면 True를 아니면 False를 반환한다.
is_full(): 덱이 가득 차 있으면 True를 아니면 False를 반환한다.
size(): 덱 내의 모든 요소들의 개수를 반환한다.
class Deque {
constructor() {
this.arr = [];
this.head = 0;
this.tail = 0;
}
push_front(item) {
if (this.arr[0]) {
for (let i = this.arr.length; i > 0; i--) {
this.arr[i] = this.arr[i - 1];
}
}
this.arr[this.head] = item;
this.tail++;
}
push_back(item) {
this.arr[this.tail++] = item;
}
pop_front() {
if (this.head >= this.tail) {
return null;
} else {
const result = this.arr[this.head++];
return result;
}
}
pop_back() {
if (this.head >= this.tail) {
return null;
} else {
const result = this.arr[--this.tail];
return result;
}
}
}
let deque = new Deque();
deque.push_front(1); // arr: [1] head: 0 tail: 1
deque.push_front(2); // arr: [2, 1] head: 0 tail: 2
console.log(deque.pop_front()); // 2, head: 1 tail: 2
deque.push_front(3); // arr: [2, 3, 1] head: 1 tail: 3
console.log(deque.pop_front()); // 3, head: 2 tail: 3
console.log(deque.pop_front()); // 1, head: 3 tail: 3
console.log(deque.pop_front()); // null
deque.push_back(5); // arr: [5] head: 3 tail: 4
// 실제 배열 출력은 arr: [2, 3, 1, 5] 이지만 배열 요소 2, 3, 1은 pop_front()를 하였기에 shift()가 된 요소로 생각할 수 있다.
console.log(deque.pop_back()); // 5, head: 3 tail: 3
console.log(deque.pop_back()); // null
deque.push_back(6); // arr: [6] head: 3 tail: 4
// 실제 배열 출력은 arr: [2, 3, 1, 6] 이지만 배열 요소 2, 3, 1 은 pop_front()를 하였기에 shift()가 된 요소로, 배열 요소 5는 pop_back()을 실행해서 pop()가 된 요소로 생각할 수 있다.
deque.push_front(9); // arr: [9, 6] head: 3 tail: 5🌻LinkedList (연결리스트)
각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 자료 구조를 말한다.
- 연결리스트 코드
한 방향으로만 이동할 수 있는 리스트를 말한다.
-
단방향 연결리스트 형태

한 노드에 데이터와 포인터가 있는데 이 포인터는 다음 값의 주소이다.
-
단방향 연결리스트에서 데이터 추가

새로 추가하려는 위치에서 왼쪽에 있는 노드가 가리키는 주소값을 바꾼다. 새로 추가하는 노드에서도 가리키는 주소값을 다음 노드로 설정한다.
-
단방향 연결리스트에서 데이터 삭제

삭제하려는 노드와의 양 옆 연결을 제거한다. 이전 노드가 가리키는 주소가 삭제할 노드를 가리키게 하지 않고 그 다음 노드를 가리키도록 바꿔준다.
양 방향으로 이동할 수 있는 리스트를 말한다.
- 양방향 연결리스트 형태
한 노드에 데이터와 포인터 2개가 있다.
포인터 한 개는 다음 값의 주소를 가지고 있고 다른 포인터 한 개는 이전 값의 주소를 가지고 있다.
- 양방향 연결리스트에서 데이터 추가
단방향 연결리스트에서의 데이터 추가 방법과 동일하다.
다만 이전 값을 가리키는 주소가 한 개 더 있기 때문에 이 주소도 추가하려는 데이터를 거치도록 바꿔준다.
- 양방향 연결리스트에서 데이터 삭제
단방향 연결리스트에서의 데이터 삭제 방법과 동일하다.
다만 이전 값을 가리키는 주소가 한 개 더 있기 때문에 이 주소도 추가하려는 데이터를 거치도록 바꿔준다.
👍
데이터 찾는 속도: 배열 > 연결리스트
연결리스트에서 데이터를 찾기 위해서는 연결 순서대로 돌아다녀야하기 때문에 배열보다 찾는 속도가 느리다.
👍
데이터 삽입/삭제 속도: 연결리스트 > 배열
연결리스트에서는 노드를 하나 새로 생성하고 추가할 자리의 양 옆 노드의 주소만 바꿔주면 되기 때문에 빠르다.
배열에서는 데이터를 중간에 삽입/삭제할 때 배열 전체가 이동하기 때문에 느리다.
출처: https://overcome-the-limits.tistory.com/16
class Node {
constructor(element) {
this.element = element;
this.next = null;
}
}
class LinkedList {
constructor() {
this.head = new Node("head");
}
append(newElement) {
let newNode = new Node(newElement); //새로운 노드 생성
let current = this.head; // 시작 노드
while (current.next != null) {
// 맨 끝 노드 찾기
current = current.next;
}
current.next = newNode;
}
insert(newElement, item) {
let newNode = new Node(newElement); //새로운 노드 생성
let current = this.find(item); // 삽입할 위치의 노드 찾기
newNode.next = current.next; // 찾은 노드가 가리키는 노드를 새로은 노드가 가리키기
current.next = newNode; // 찾은 노드는 이제부터 새로운 노드를 가리키도록 하기
}
remove(item) {
let preNode = this.findPrevious(item); // 삭제할 노드를 가리키는 노드 찾기
preNode.next = preNode.next.next; // 삭제할 노드 다음 노드를 가리키도록 하기
}
find(item) {
let currNode = this.head;
while (currNode.element !== item) {
currNode = currNode.next;
}
return currNode;
}
findPrevious(item) {
let currNode = this.head;
while (currNode.next != null && currNode.next.element !== item) {
currNode = currNode.next;
}
return currNode;
}
toString() {
let array = [];
let currNode = this.head;
while (currNode.next !== null) {
array.push(currNode.next.element);
currNode = currNode.next;
}
return array;
}
}
let linkedList = new LinkedList();
linkedList.insert("A", "head");
linkedList.insert("B", "A");
linkedList.insert("C", "B");
linkedList.remove("B");
linkedList.append("D");
linkedList.append("E");
console.log(linkedList.toString());🎭DFS/BFS
그래프를 탐색하는 방법 -> 하나의 노드로부터 시작하여 차례대로 모든 노드들을 한 번씩 방문하는 것
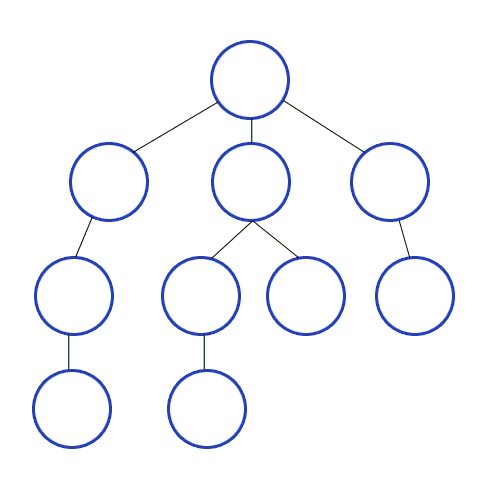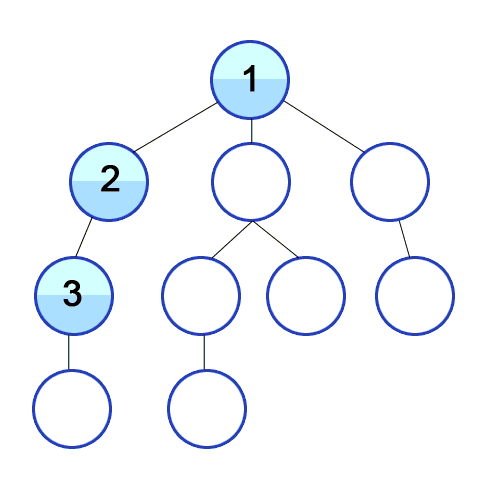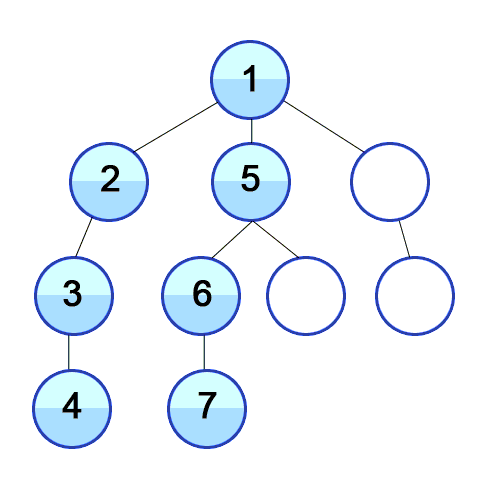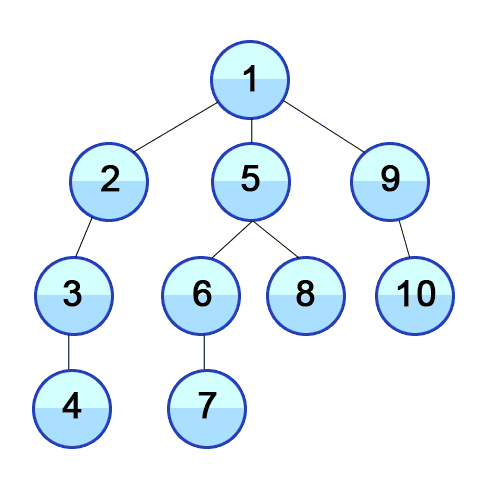
루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방식을 말합니다.
특징
모든 노드를 방문할때 사용
깊이 우선 탐색이 너비 우선 탐색보다 좀 더 간단함
검색 속도 자체는 너비 우선 탐색에 비해 느림

루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법으로, 시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법입니다.
특징
두 노드 사이의 최단 경로를 찾고 싶을 때 사용
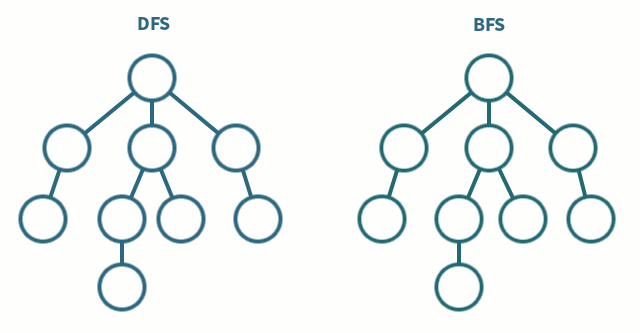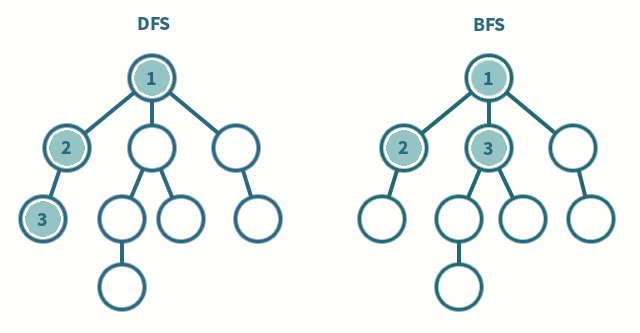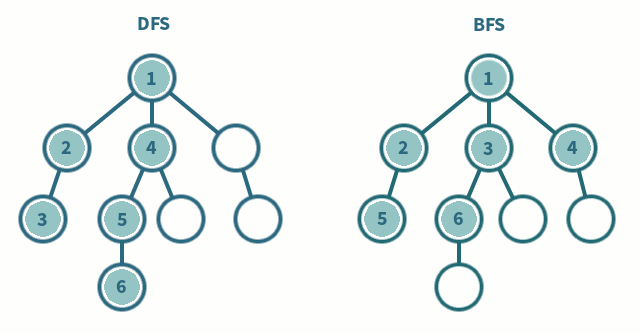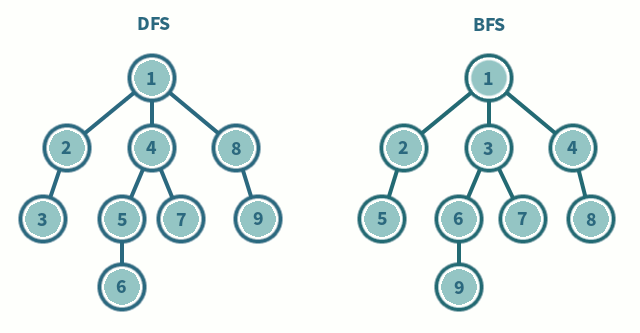
- DFS(깊이 우선 탐색)
- 현재 정점에서 갈 수 있는 점들까지 들어가면서 탐색
- 스택 또는 재귀함수로 구현
- BFS(너비 우선 탐색)
- 현재 정점엣 연결된 가까운 점들부터 탐색
- 큐를 이용해서 구현
시간복잡도 차이 O(N)
그래프의 모든 정점을 방문하는 것이 주요한 문제 -> DFS=BFS
경로에 제한이 있는 문제 -> DFS>BFS(BFS는 경로의 특징을 가지지 못한다)
최단거리를 구해야 하는 문제 -> BFS>DFS
검색 대상 그래프가 엄청 큰 문제 -> DFS>BFS
- DFS코드
const graph = {
A: ["B", "C"],
B: ["A", "D"],
C: ["A", "G", "H", "I"],
D: ["B", "E", "F"],
E: ["D"],
F: ["D"],
G: ["C"],
H: ["C"],
I: ["C", "J"],
J: ["I"],
};
const DFS = (graph, startNode) => {
const visited = []; // 탐색을 마친 노드들
let needVisit = []; // 탐색해야할 노드들
needVisit.push(startNode); // 노드 탐색 시작
while (needVisit.length !== 0) {
// 탐색해야할 노드가 남아있다면
const node = needVisit.shift(); // queue이기 때문에 선입선출, shift()를 사용한다.
if (!visited.includes(node)) {
// 해당 노드가 탐색된 적 없다면
visited.push(node);
needVisit = [...graph[node], ...needVisit];
}
}
return visited;
};
console.log(DFS(graph, "A"));
// ["A", "B", "D", "E", "F", "C", "G", "H", "I", "J"]- BFS코드
const graph = {
A: ["B", "C"],
B: ["A", "D"],
C: ["A", "G", "H", "I"],
D: ["B", "E", "F"],
E: ["D"],
F: ["D"],
G: ["C"],
H: ["C"],
I: ["C", "J"],
J: ["I"]
};
const BFS = (graph, startNode) => {
const visited = []; // 탐색을 마친 노드들
let needVisit = []; // 탐색해야할 노드들
needVisit.push(startNode); // 노드 탐색 시작
while (needVisit.length !== 0) { // 탐색해야할 노드가 남아있다면
const node = needVisit.shift(); // queue이기 때문에 선입선출, shift()를 사용한다.
if (!visited.includes(node)) { // 해당 노드가 탐색된 적 없다면
visited.push(node);
needVisit = [...needVisit, ...graph[node]];
}
}
return visited;
};
console.log(BFS(graph, "A"));
// ["A", "B", "C", "D", "G", "H", "I", "E", "F", "J"]😱완전탐색
가능한 모든 경우의 수를 다 체크해서 정답을 찾는 방법이다.
- BFS, DFS
- 완전탐색 코드
반복/조건문을 활용하여 모든 가능한 경우의 수를 확인하는 것을 말한다.
🧐순열이란? 서로 다른 n개중에 r개를 선택하는 경우의 수를 말한다.
- 순열은 순서가 상관이 있기 때문에 순서가 중요하다!
- N개의 데이터를 순열로 나타낸다면 전체 순열의 가지 수는 N!개가 된다.
🧐재귀란? 자기 자신을 호출하는 것을 말한다.
- 주의할 점
- 현재 함수의 상태를 저장하는 parameter와 재귀를 탈출하기 위한 탈출 조건이 필요
- return문을 명확하게 정의
비트(bit) 연산을 통해서 부분 집합을 표현하는 것을 말한다.
1. And(&) : 둘 다 1이면 1
2. OR(|) : 둘 중 1개만 1이면 1
3. NOT(~) : 1이면 0, 0이면 1
4. XOR(^) : 둘의 관계가 다르면 1, 같으면 0
5. Shift(<<, >>) : A << B라고 한다면 A를 좌측으로 B 비트만큼 밀기.
- 비트마스크를 사용하는 이유
- 배열 활용만으로 해결할 수 없는 문제를 해결할 수 있다.
- 적은 메모리와 빠른 수행시간으로 문제 해결이 가능하다. (원소의 수는 많지 않아야 한다.)
- 집합을 배열의 인덱스로 표현할 수 있다.
- 코드가 간결해진다.
그래프 자료구조에서 모든 노드를 탐색하기 위한 방법이다.
BFS: 너비 우선 탐색
DFS: 깊이 우선 탐색
출처
-
https://hongjw1938.tistory.com/78
순열 관련 코드
const getPermutations = function (arr, selectNumber) { const results = []; if (selectNumber === 1) return arr.map((value) => [value]); // 1개씩 택할 때, 바로 모든 배열의 원소 return arr.forEach((fixed, index, origin) => { const rest = [ ...origin.slice(0, index), ...origin.slice(index + 1), ]; // 해당하는 fixed를 제외한 나머지 배열 const permutations = getPermutations(rest, selectNumber - 1); // 나머지에 대해 순열을 구한다. const attached = permutations.map((permutation) => [ fixed, ...permutation, ]); // 돌아온 순열에 대해 떼 놓은(fixed) 값 붙이기 results.push(...attached); // 배열 spread syntax 로 모두다 push }); return results; // 결과 담긴 results return }; const arr = [1, 2, 3, 4]; const result = getPermutations(arr, 3); console.log(result); // => [ // [ 1, 2, 3 ], [ 1, 2, 4 ], // [ 1, 3, 2 ], [ 1, 3, 4 ], // [ 1, 4, 2 ], [ 1, 4, 3 ], // [ 2, 1, 3 ], [ 2, 1, 4 ], // [ 2, 3, 1 ], [ 2, 3, 4 ], // [ 2, 4, 1 ], [ 2, 4, 3 ], // [ 3, 1, 2 ], [ 3, 1, 4 ], // [ 3, 2, 1 ], [ 3, 2, 4 ], // [ 3, 4, 1 ], [ 3, 4, 2 ], // [ 4, 1, 2 ], [ 4, 1, 3 ], // [ 4, 2, 1 ], [ 4, 2, 3 ], // [ 4, 3, 1 ], [ 4, 3, 2 ] // ]
♾️다이나믹 프로그래밍
동적 계획법(dynamic programming, DP)
특정 범위까지의 값을 구하기 위해서 그것과 다른 범위까지의 값을 이용하여 효율적으로 값을 구하는 알고리즘 설계 기법 큰 문제를 작은 문제들로 분할하여 푼다. 분할정복 알고리즘과 비슷하지만 한번 계산했던 값을 저장한다는 점에서 분할정복과의 차이점이 있다.(메모이제이션)
큰 문제를 유사한 형태의 작은 문제로 나눌 수 있으며, 작은 문제의 답을 모아 큰 문제를 해결한다.
동일한 작은 문제를 반복적으로 해결해야 한다.
//메모이제이션하기 위한 리스트 초기화
array = new Array(100).fill(0);
function fibo(x) {
// 종료 조건
if (x === 1 || x === 2) {
return 1;
}
// 한번 해결한 문제는 여러번 해결하지 않도록 한다.
if (array[x] != 0) {
return array[x];
}
// 아직 계산하지 않은 문제라면 점화식에 따라서 피보나치 결과 반환
array[x] = fibo(x - 1) + fibo(x - 2);
return array[x];
}- 문제 이해
- 점화식 찾아내기
- 구현 방식(상향식/하향식) 결정
- 상향식: 반복문을 이용해 초기 항부터 계산
- 하향식: 재귀함수로 큰 항을 구하기 위해 작은 항을 호출하는 방식이다.-> 이미 구한 함수 값을 담는 테이블을 흔히 DP 테이블이라고 한다.
- 점화식 실제 코드 구현