by Jin Yamanaka, Shigesumi Kuwashima and Takio Kurita
This is a tensorflow implementation of "Fast and Accurate Image Super Resolution by Deep CNN with Skip Connection and Network in Network", a deep learning based Single-Image Super-Resolution (SISR) model. We named it DCSCN. If you are checking the paper's code and results, please check ver1 branch.
The model structure is like below. We use Deep CNN with Residual Net, Skip Connection and Network in Network. A combination of Deep CNNs and Skip connection layers is used as a feature extractor for image features on both local and global area. Parallelized 1x1 CNNs, like the one called Network in Network, is also used for image reconstruction.
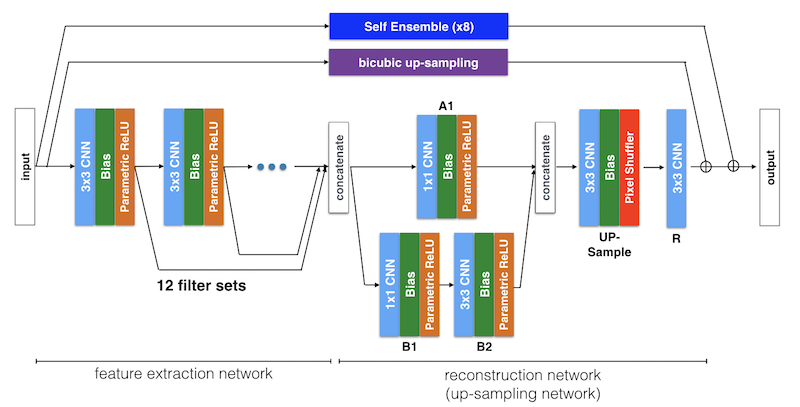
As a ver2, we also implemented these features.
-
Pixel Shuffler from "Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network"
-
Transposed-CNN (optional) from "Fully Convolutional Networks for Semantic Segmentation"
-
Self Ensemble from "Seven ways to improve example-based single image super resolution"
-
Clipping Normalization (Gradient clipping)
-
Dynamically load training images (optional)
-
Add extra layers / Update default parameters for better PSNR result

Our model, DCSCN was much lighter than other Deep Learning based SISR models which is ver 1. As a ver2, we use larger model and recent technics to get a better image restoration performace.
python > 3.5
tensorflow > 1.0, scipy, numpy and pillow
The sample result of default parameter is here. You can have even better PSNR than below with using larger filters or deeper layers with our model.
| DataSet | Bicubic | DRCN | VDSR | DCSCN (ver2) |
|---|
Results and model will be uploaded in some days!!
Learned weights for some parameters are included in this GitHub. Execute evaluate.py with these args below and you get results in output directory. When you want to evaluate with other parameters, try training first then evaluate with same parameters as training have done. Results will be logged at log.txt, please check.
Three pre-trained models (compact, normal, large) are included.
# evaluating set14 dataset
python evaluate.py --test_dataset set14 --save_results True
# evaluating set5 dataset with small model
python evaluate.py --test_dataset set5 --save_results True --layers 7 --filters 64
# evaluating all(set5,set14,bsd100) dataset
python evaluate.py --test_dataset all
Place your image file in this project directory. And then run "sr.py --file 'your_image_file'" to apply Super Resolution. Results will be generated in output directory. Please note you should use same args which you used for training.
If you want to apply this model on your image001.png file, try those.
# apply super resolution on image001.jpg (then see results at output directory)
python sr.py --file your_file.png
# apply super resolution with small model
python sr.py --file your_file.png --layers 7 --filters 64
You can train with any datasets. Put your image files as a training dataset into the directory under data directory, then specify with --dataset arg. There are some other hyper paramters to train, check args.py to use other training parameters.
Each training and evaluation result will be added to log.txt.
# training with bsd200 dataset
python train.py --dataset bsd200 --training_images 80000
# training with small model
python train.py --dataset bsd200 --layers 7 --filters 64 --training_images 40000
Important parameters are those.
| Parameter arg | Name | Default | Explanation |
|---|---|---|---|
| layers | |||
| filters | |||
| filters_decay_gamma | |||
| pixel_shuffler | |||
| self_ensemble | |||
| training_images | Batch images for training epoch | 24000 | This number of batch images are used for training one epoch. I usually use 100,000 batch images for each 10 epochs for each Learning Rate. |
| dropout_rate | |||
| initializer | |||
| activator | |||
| optimizer | |||
| batch_image_size | |||
| batch_num |
To get a better performance, data augmentation is needed. You can use augmentation.py to build an augmented dataset. The arg, augment_level = 4, means it will add right-left, top-bottom and right-left and top-bottom fillped images to make 4 times bigger dataset. And there yang91_4 directory will be generated as an augmented dataset.
To have better model, you should use larger training data like (BSD200 + Yang91) x (8 augment) dataset.
# build 4x augmented dataset for yang91 dataset (will add flipped images)
python augmentation.py --dataset yang91 --augment_level 4
# build 8x augmented dataset for yang91 dataset (will add flipped and rotated images)
python augmentation.py --dataset yang91 --augment_level 8
# train with augmented data
python train.py --dataset yang91_4
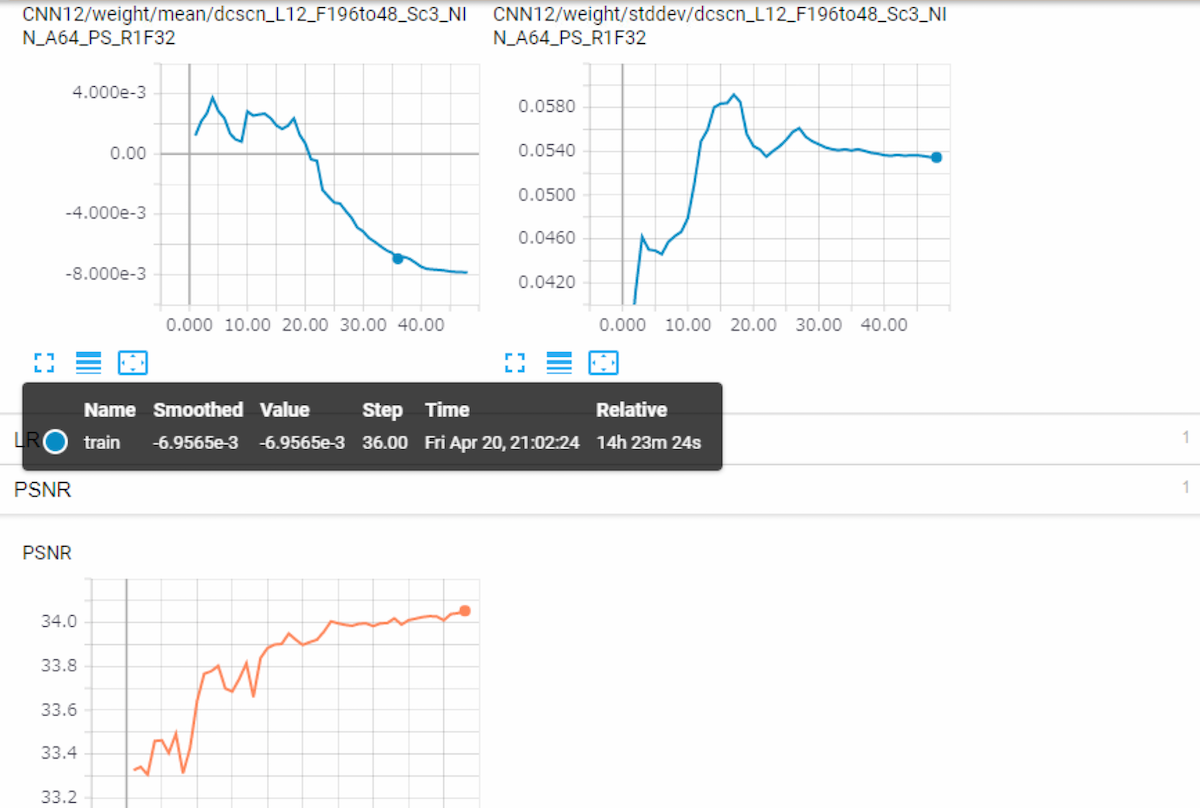
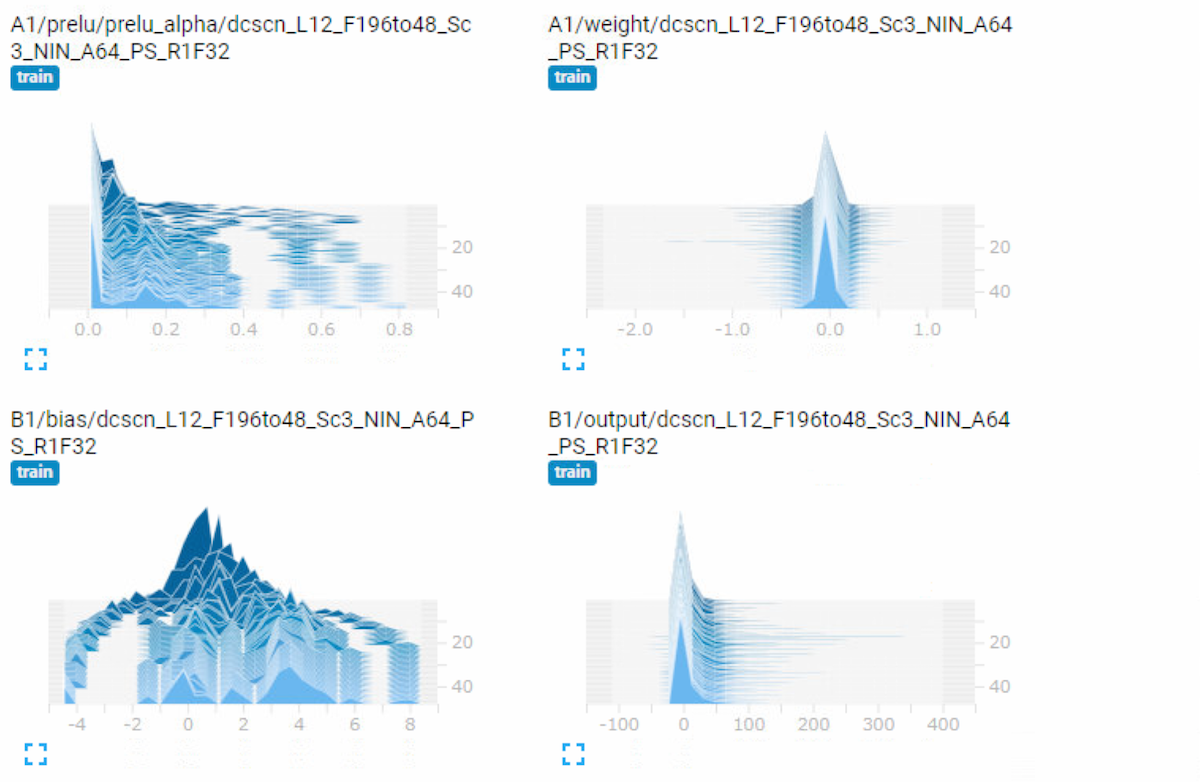
During the training, tensorboard log is available. Those are logged under tf_log directory.
You can check test PSNR transition during training. Also mean / std / histogram of every weights and biases are logged at tensorboard.