Classical Chinese to Modern Japanese Translator, working on Universal Dependencies.
>>> import udkundoku
>>> lzh=udkundoku.load()
>>> s=lzh("不入虎穴不得虎子")
>>> t=udkundoku.translate(s)
>>> print(t)
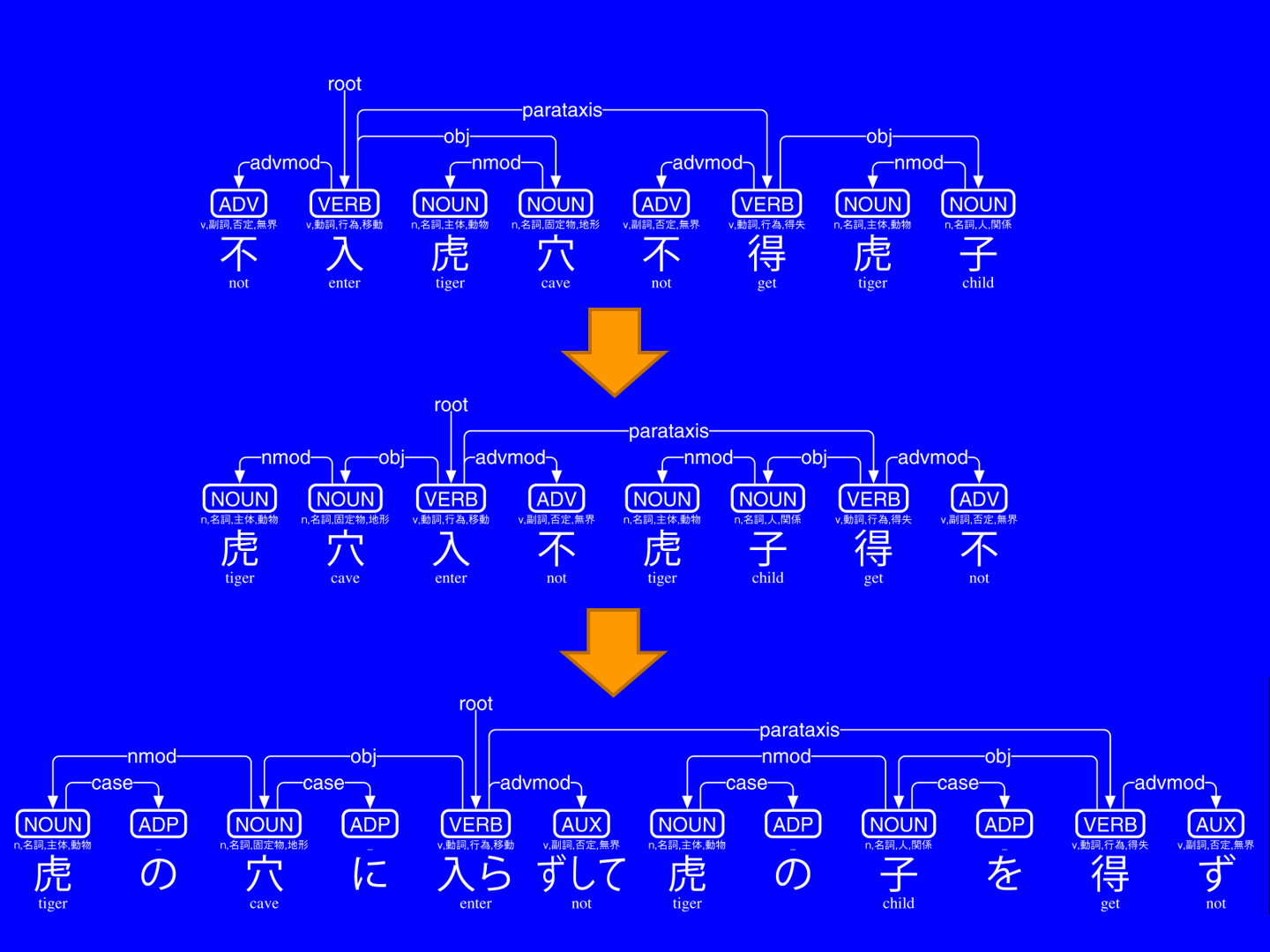
# text = 虎の穴に入らずして虎の子を得ず
1 虎 虎 NOUN n,名詞,主体,動物 _ 3 nmod _ Gloss=tiger|SpaceAfter=No
2 の _ ADP _ _ 1 case _ SpaceAfter=No
3 穴 穴 NOUN n,名詞,固定物,地形 Case=Loc 5 obj _ Gloss=cave|SpaceAfter=No
4 に _ ADP _ _ 3 case _ SpaceAfter=No
5 入ら 入 VERB v,動詞,行為,移動 _ 0 root _ Gloss=enter|SpaceAfter=No
6 ずして 不 AUX v,副詞,否定,無界 Polarity=Neg 5 advmod _ Gloss=not|SpaceAfter=No
7 虎 虎 NOUN n,名詞,主体,動物 _ 9 nmod _ Gloss=tiger|SpaceAfter=No
8 の _ ADP _ _ 7 case _ SpaceAfter=No
9 子 子 NOUN n,名詞,人,関係 _ 11 obj _ Gloss=child|SpaceAfter=No
10 を _ ADP _ _ 9 case _ SpaceAfter=No
11 得 得 VERB v,動詞,行為,得失 _ 5 parataxis _ Gloss=get|SpaceAfter=No
12 ず 不 AUX v,副詞,否定,無界 Polarity=Neg 11 advmod _ Gloss=not|SpaceAfter=No
>>> print(t.sentence())
虎の穴に入らずして虎の子を得ず
>>> print(s.to_tree())
不 <════╗ advmod
入 ═══╗═╝═╗ root
虎 <╗ ║ ║ nmod
穴 ═╝<╝ ║ obj
不 <════╗ ║ advmod
得 ═══╗═╝<╝ parataxis
虎 <╗ ║ nmod
子 ═╝<╝ obj
>>> print(t.to_tree())
虎 ═╗<╗ nmod(体言による連体修飾語)
の <╝ ║ case(格表示)
穴 ═╗═╝<╗ obj(目的語)
に <╝ ║ case(格表示)
入 ═╗═══╝═╗ root(親)
ら ║ ║
ず <╝ ║ advmod(連用修飾語)
し ║
て ║
虎 ═╗<╗ ║ nmod(体言による連体修飾語)
の <╝ ║ ║ case(格表示)
子 ═╗═╝<╗ ║ obj(目的語)
を <╝ ║ ║ case(格表示)
得 ═╗═══╝<╝ parataxis(隣接表現)
ず <╝ advmod(連用修飾語)udkundoku.load() is an alias for udkanbun.load() of UD-Kanbun. udkundoku.translate() is a transcriptive converter from Classical Chinese (under Universal Dependencies of UD-Kanbun) into Modern Japanese (under Universal Dependencies of UniDic2UD). udkundoku.reorder() is called to rearrange Classical Chinese into Japanese word-order inside udkundoku.translate(). to_tree() and to_svg() are borrowed from those of UD-Kanbun.
You can simply use udkundoku on the command line:
echo 不入虎穴不得虎子 | udkundoku -jpython -m udkundoku.server 5000Try to connect http://127.0.0.1:5000 with your local browser. Input a Classical Chinese sentence there and push 解析-button (at least) three times.
Tar-ball is available for Linux, and is installed by default when you use pip:
pip install udkundoku旧仮名口語UniDic is automatically downloaded for UniDic2UD.
Make sure to get gcc-g++ python37-pip python37-devel packages, and then:
pip3.7 install udkundokuUse python3.7 command in Cygwin instead of python.
!pip install udkundokuTry notebook for Google Colaboratory.
Koichi Yasuoka (安岡孝一)
- 安岡孝一: 漢文の依存文法解析にもとづく自動訓読システム, 日本漢字学会第3回研究大会予稿集(2020年11月), pp.60-73.
- 安岡孝一: 漢文の依存文法解析と返り点の関係について, 日本漢字学会第1回研究大会予稿集(2018年12月), pp.33-48.