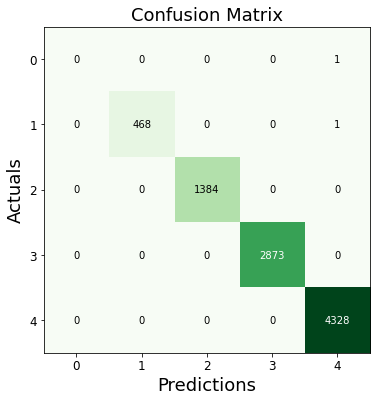
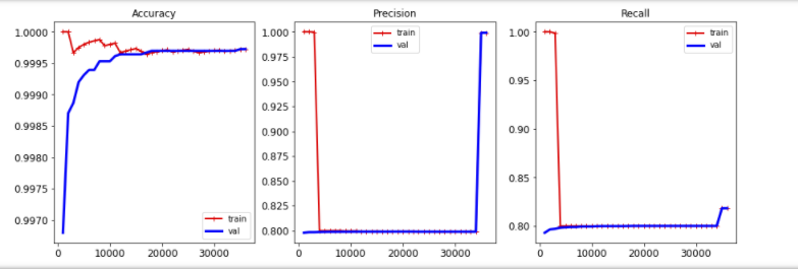
To see if drivers were being profiled. I built a Support Vector Machine (SVM) classifier and a randomForest classifier to predict a driver's race given the traffic's stop's details. Successful classification will indicate the existence of bais in the traffic stops' data.
Two Data Tables:
- Traffic Stop Data
- Socio Economic Data for Zip Codes where Stops happen
Traffic Stop Data
| Unnamed: 0 | Stop_Key | Type | TCOLE_Sex | TCOLE_RACE_ETHNICITY | Standardized_Race_Known | Reason_for_Stop | Street_Type | Search_Yes_or_No | TCOLE_Search_Based_On | TCOLE_Search_Found | TCOLE_Result_of_Stop | TCOLE_Arrest_Based_On | Council_District | COUNTY | Custody | Location | Sector | Standardized_Race | Stop_Time |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20201-459626502-25962 | WARNING | Male | White | NO - RACE OR ETHNICITY WAS NOT KNOWN BEFORE STOP | Moving Traffic Violation | City Street | NO | N/A - No Search was conducted | N/A - No Search was conducted | Verbal Warning | N/A - No Arrest Conducted | Council District 9 | TRAVIS COUNTY | NOT APPLICABLE | 500 E 8TH ST | GEORGE | WHITE | 2154.0 |
Socio Economic Data for Zip Codes
| index | Zip_Code_1 | Zip_Code | latitude | longitude | propertyTaxRate | numPriceChanges | avgSchoolRating | MedianStudentsPerTeacher |
|---|---|---|---|---|---|---|---|---|
| 0 | 78617 | 78617 | 30.16451458598292 | -97.63406638211984 | 1.9799999999999984 | 2.558139534883721 | 3.1589147286821717 | 13.965116279069768 |
| 1 | 78619 | 78619 | 30.136290550231934 | -97.97578048706056 | 2.01 | 1.9166666666666667 | 7.388888888888889 | 15.666666666666666 |
racialProf = racialProfUpdated.merge(socioEcoZipCodesInfo, on ='Zip_Code', how = 'outer')
| index | Unnamed: 0 | Stop_Key | Type | TCOLE_Sex | TCOLE_RACE_ETHNICITY | Standardized_Race_Known | Reason_for_Stop | Street_Type | Search_Yes_or_No | TCOLE_Search_Based_On | TCOLE_Search_Found | TCOLE_Result_of_Stop | TCOLE_Arrest_Based_On | Council_District | COUNTY | Custody | Location | Sector | Standardized_Race | Stop_Time |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 20201-459626502-25962 | WARNING | Male | White | NO - RACE OR ETHNICITY WAS NOT KNOWN BEFORE STOP | Moving Traffic Violation | City Street | NO | N/A - No Search was conducted | N/A - No Search was conducted | Verbal Warning | N/A - No Arrest Conducted | Council District 9 | TRAVIS COUNTY | NOT APPLICABLE | 500 E 8TH ST | GEORGE | WHITE | 2154.0 |
Shape: (45274, 33)
numeric_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='constant',fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
numeric_features = train.select_dtypes(include=['int64','float64']).columns
categorical_features = train.select_dtypes(include=['object']).drop(['TCOLE_RACE_ETHNICITY'], axis=1).columns
preprocessor = ColumnTransformer( transformers=[('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
train, test, = train_test_split(racialProf,
test_size=0.2)
rf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', RandomForestClassifier(n_estimators = 13, max_depth=10))])
X_train = train.drop('TCOLE_RACE_ETHNICITY', axis=1)
y_train = train['TCOLE_RACE_ETHNICITY']
rf.fit(X_train ,y_train)
train_pred = rf.predict (X_train)


X_test = test.drop('TCOLE_RACE_ETHNICITY', axis=1)
y_test = test['TCOLE_RACE_ETHNICITY']
test_predRF = rf.predict (X_test)


param_grid = {
'classifier__n_estimators': [200, 500],
'classifier__max_features': ['auto', 'sqrt', 'log2'],
'classifier__max_depth' : [4,5,6,7,8],
'classifier__criterion' :['gini', 'entropy']}
from sklearn.model_selection import GridSearchCV
CV = GridSearchCV(rf, param_grid, n_jobs= 1)
CV.fit(X_train, y_train)
print(CV.best_params_)
print(CV.best_score_)
# Suggested parameters from grid search
from sklearn.ensemble import RandomForestClassifier
rf_GridSearch = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', RandomForestClassifier(criterion = 'entropy',
max_depth = 8, max_features= 'sqrt',
n_estimators= 200))])
rf_GridSearch.fit(X_train, y_train)

test_predRFGRID = rf_GridSearch.predict (X_test)
svm_classifier = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', SVC(kernel="poly", degree=3))])
X_train = train.drop('TCOLE_RACE_ETHNICITY', axis=1)
y_train = train['TCOLE_RACE_ETHNICITY']
svm_classifier.fit(X_train, y_train)
train_predSVM = svm_classifier.predict (X_train)

X_test = test.drop('TCOLE_RACE_ETHNICITY', axis=1)
y_test = test['TCOLE_RACE_ETHNICITY']
test_predSVM = svm_classifier.predict (X_test)


param_grid = {
'classifier__kernel': ['poly'],
'classifier__degree': [1,2,3],
'classifier__decision_function_shape': ['ovr','ovo']}
from sklearn.model_selection import GridSearchCV
CV1 = GridSearchCV(svm_classifier, param_grid, n_jobs= 1)
CV1.fit(X_train, y_train)
print(CV1.best_params_)
print(CV1.best_score_)
# Suggested Parameters from Grid-Search
svm_classifierGridSearch = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', SVC(decision_function_shape= 'ovr', degree= 1, kernel= 'poly'
))])
svm_classifierGridSearch.fit(X_train, y_train)
train_predSVMGRID = svm_classifierGridSearch.predict (X_train)

test_predSVMGRID = svm_classifierGridSearch.predict (X_test)
