
Adam Brzyzek - Junior Backend Developer
github: https://github.com/ABrzyzek
linkedin: https://www.linkedin.com/in/adam-brzyzek/
discord: brzyzu
Kamil Kulig - Backend Developer
github: https://github.com/KuligKamil
linkedin: https://www.linkedin.com/in/kamil-kulig-81488b89/
discord: kamilkulig
MongoDB is a source-available, cross-platform, document-oriented database program.
Classified as a NoSQL database product, MongoDB utilizes JSON-like documents with optional schemas.
"If you can’t explain it to a six-year-old, you don’t understand it yourself"
- Rule ABC
- MongoDB Popularity
- Rumors that it's easy to do MVP & have good Developer Experience
Always Be Curious!
We never use commercially use MongoDB or NoSQL Database.
We always use Relational Databases. Mostly PostgreSQL.
We want to try something new.
For showing popularity MongoDB we will show two source StackOverflow 2024 Survey Developer, DB-Engines Ranking.
-
StackOverflow 2024 Survey Developer - Database Results
65,437 Coders from 185 countries around the world. https://survey.stackoverflow.co/2024/technology#most-popular-technologies-database
-
DB-Engines Ranking The DB-Engines Ranking ranks database management systems according to their popularity. The ranking is updated monthly. https://db-engines.com/en/ranking
-
Popularity DB-Engines Ranking - Trend of Document Stores
https://db-engines.com/en/ranking_trend/document+store -
DB-Engines Ranking of Document Stores https://db-engines.com/en/ranking/document+store
-
Method of calculating the scores of the DB-Engines Ranking
GO for it here to get more details https://db-engines.com/en/ranking_definition
The best option to learn something new is to create workshop. You have perfect motivation, deadline.
Kamil Kulig
MongoDB is the most popular database that as not Relational Database.
Spoiler alert! In our opinion solid database for MVP with pleasant Developer Experience.
We want to have integration with Pydantic models, bcs we like Pydantic & FastAPI is based on it.
We would like to try asynchronous option with FastAPI.
We would like to use async framework for better performance & scalability.
But remember when you need to use async framework.

We found 4 potential candidates to use them.
-
mongoengine https://github.com/MongoEngine/mongoengine
Star history comparison with https://star-history.com/blog/how-to-use-github-star-history

PyMongo and Motor are Python drivers for asynchronous.
MongoEngine and Beanie are ODMs.
Document-Object Mapper (think ORM Object–Relational Mapping, but for document databases).
PyMongo and MongoEngine out - no asynchronous support.
For enter easier in MongoDB world & hype about tool we decide to use Beanie.
Beanie ODM - object-document mapper for MongoDB. Data models are based on Pydantic.
Pydantic for the win.
Beanie wraps Motor, Motor wraps PyMongo. The most popular python drivers.

-
Does MongoEngine support asynchronous drivers (Motor, TxMongo)? https://mongoengine-odm.readthedocs.io/faq.html?highlight=async
-
Showing wrapping of beanie motor https://github.com/search?q=repo%3ABeanieODM%2Fbeanie%20motor&type=code
-
Showing wrapping of motor pymongo https://github.com/search?q=repo%3Amongodb%2Fmotor%20pymongo&type=code
-
Link for generate star history graph [Star History Chart](https://star-history.com/#BeanieODM/beanie&mongodb/mongo-python-driver&mongodb/motor&MongoEngine/mongoengine&Date)
-
Clone the source code from the official GitHub repo for the event
-
Next go to the
mongodb-project-workshopdirectory -
Ensure you are using Python Version 3.11 or Higher. We are using Python 3.11.9 for our project.
we recommend to use pyenv & pyenv virtualenv
https://github.com/pyenv/pyenv
https://github.com/pyenv/pyenv-virtualenv
For example:
pyenv install 3.11.9
pyenv virtualenv 3.11.9 mongo-project-workshop-3.11.9
pyenv local mongo-project-workshop-3.11.9
- Setup environment.
HINT: we recommend to use PDM - Python package and dependency manager https://pdm-project.org/latest/
how to use pdm
install pdm
pip install pdm
install all dependencies
pdm install
run ruff check
pdm run ruff check
if you see All checks passed! everything setup correctly
you can use old good venv https://docs.python.org/3/library/venv.html
how to use `venv`
create venv
python -m venv .
next activate it
on mac, linux or WSL
source ./bin/activate
or on windows
- cmd.exe
C:\> .\Scripts\activate.bat
- PowerShell
PS C:\> .\Scripts\Activate.ps1
run ruff check
run ruff check
if you see All checks passed! everything setup correctly
- Create file with environment variables
.envrcfile or.envfile
- Load 12factor apps environment variables
- Create per-project isolated development environments
- Load secrets for deployment
- Set the
MONGODB_URIvariable in.envrcto for your database connection (It will be shown in the next step, how to get the variables) - Set the
PYTHONPATHvariable in.envrcto your project path in mac, linux & WSLexport PYTHONPATH=$PWDin windows link for tutorial
MongoDB Atlas is fully managed cloud database that handle all the complexity of: deploying, managing, and healing your deployments on the cloud service provider of your choice(AWS, Azure, GCP). With Atlas you can create account and set up database with only few clicks.
DBaaS(Database as a Service) is a service that allows to set up, deploy and scale database without worrying about any physical hardware, software updates and details of configuration for performance.
- Go to the MongoDb website and press the button Try Free.
- Fill your informations and agree for Terms of Service and Privacy Policy. Press Create your Atlas account button. You can also use your Google account to create the account.
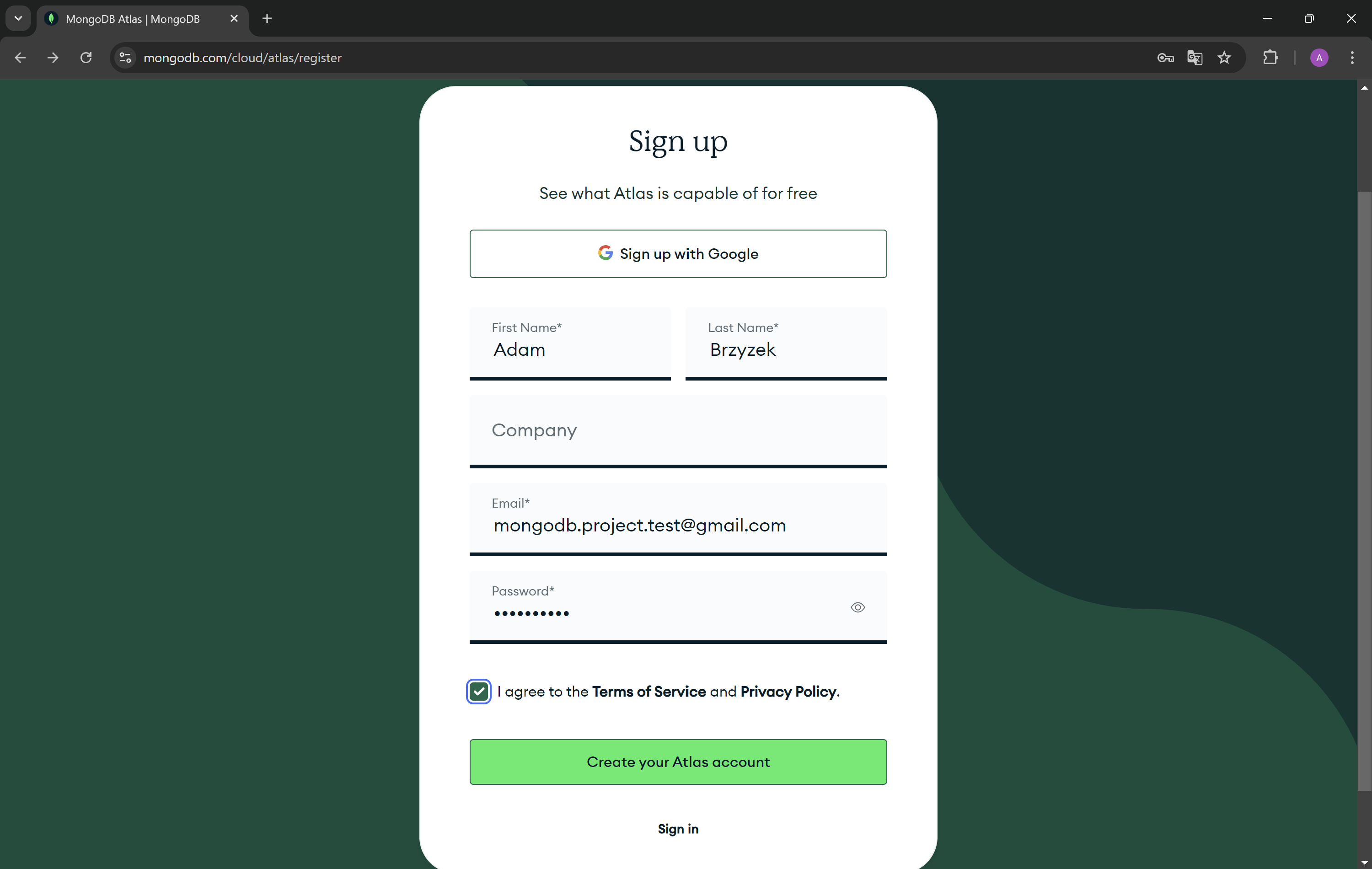
- Now you need to verify your email address.
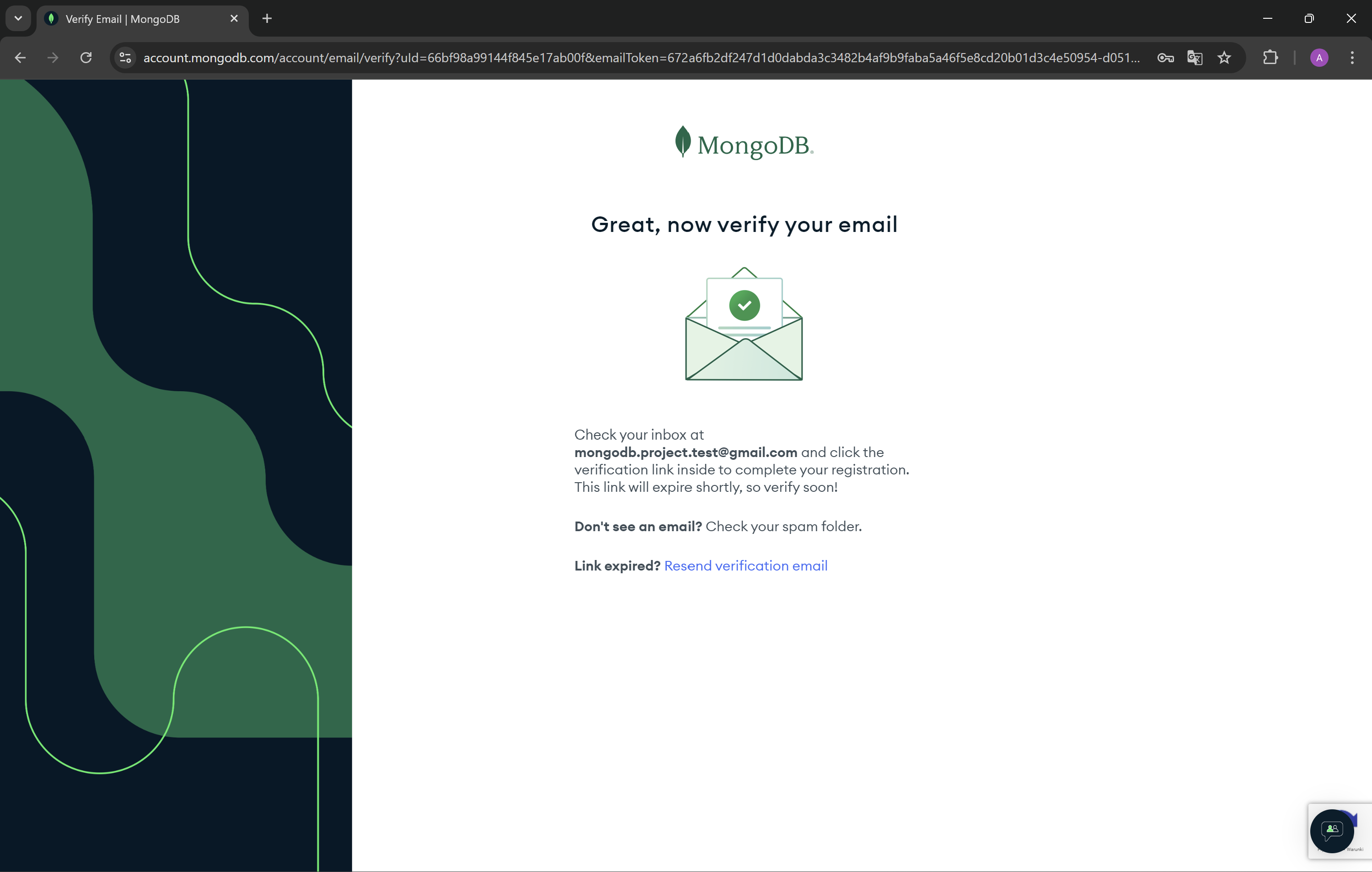
- Complete the answers to the questions below.
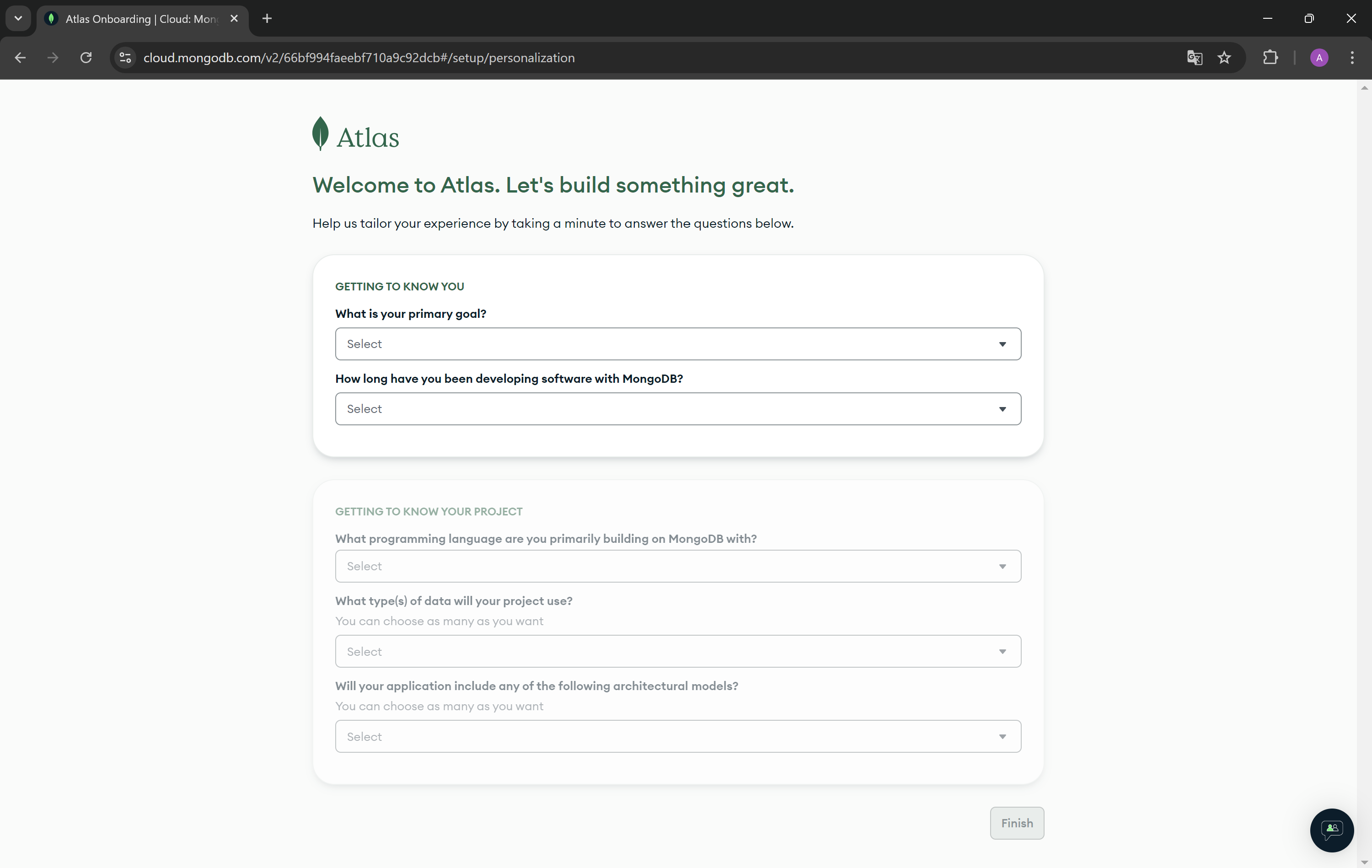
- Choose M0 tier plan created for learning and exploring MongoDB in a cloud environment. As you can see, you have 512 MB of your storage on cloud provider for free. Enter a name for your cluster. If you do not want to receive sample data, you can uncheck the Preload sample data set option.
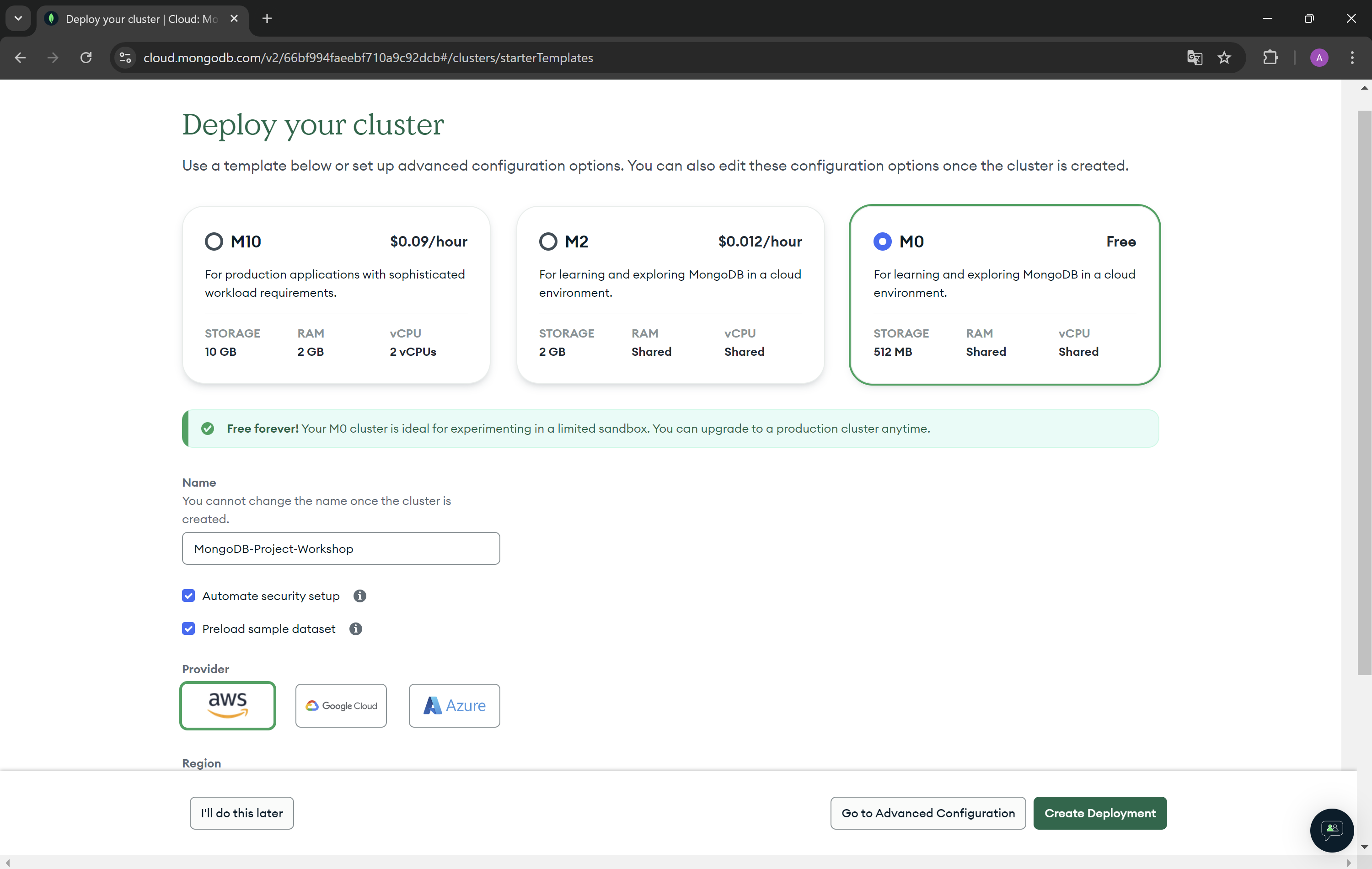
- Now create a user for your database.
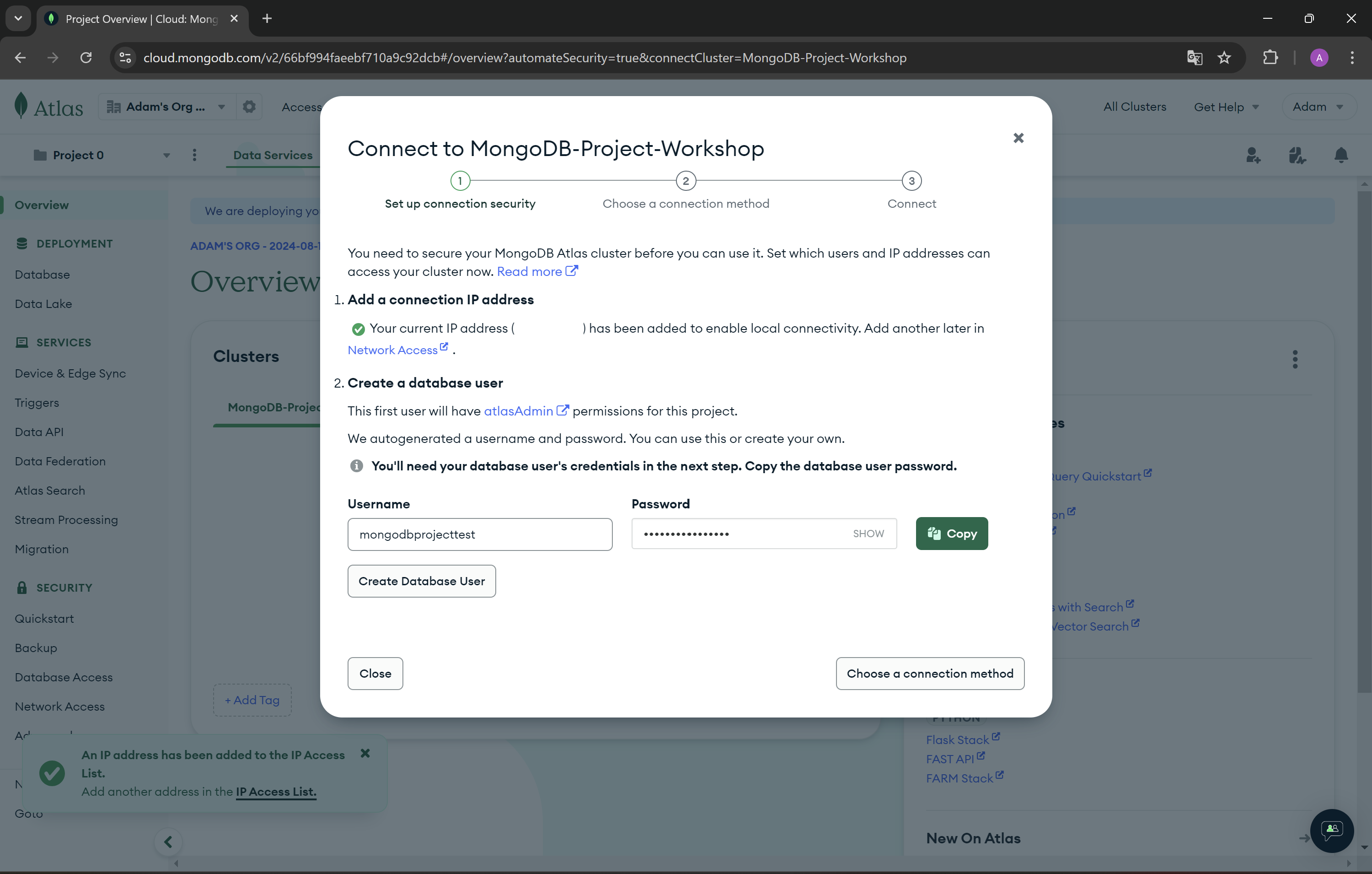 ATTENTION! Save password for user!
ATTENTION! Save password for user!







In MongoDB, databases hold one or more collections of documents.
Collections are analogous to tables in relational databases.
 Picture from mongodb.com
Picture from mongodb.com
MongoDB stores data records as documents (specifically BSON documents) which are gathered together in collections.
 JSON
https://www.mongodb.com/resources/basics/json-and-bson
JSON
https://www.mongodb.com/resources/basics/json-and-bson
BSON specification https://bsonspec.org/
Today, JSON shows up in many different cases:
- APIs
- Configuration files
- Log messages
- Database storage
However, there are several issues that make JSON less than ideal for usage inside of a database.
JSON only supports a limited number of basic data types. Most notably, JSON lacks support for datetime and binary data.
JSON objects and properties don't have fixed length which makes traversal slower.
JSON does not provide metadata and type information, taking longer to retrieve documents.
To make MongoDB JSON-first but still high-performance and general purpose, BSON was invented to bridge the gap: a binary representation to store data as JSON documents, optimized for speed, space, and efficiency. It's not dissimilar from other binary interchange formats like Protocol Buffers, or Thrift, in terms of approach.
- security not readable for people - we have tool for read it
- faster
- smaller
- contain more information
To create Document in Collections we need to use the basic class in Beanie The basic class in Beanie is Document class to create collections of Document
After inspect of the Beanie base class Document, it's inherent from pydantic Base Model.
import inspect
from beanie import Document
from pydantic import BaseModel
inspect.getmro(Document)Output
(beanie.odm.documents.Document,
lazy_model.parser.new.LazyModel,
pydantic.main.BaseModel,
beanie.odm.interfaces.setters.SettersInterface,
beanie.odm.interfaces.inheritance.InheritanceInterface,
beanie.odm.interfaces.find.FindInterface,
beanie.odm.interfaces.aggregate.AggregateInterface,
beanie.odm.interfaces.getters.OtherGettersInterface,
object)
pydantic + beanie = ❤️
when we would like to create application
we want to create for users
that why our first class will be user
Example in User class in pydantic
from pydantic import BaseModel
class User(BaseModel):
name: str
surname: str
email: strExample in User class in beanie
from beanie import Document
class User(Document):
name: str
surname: str
email: strif you run code above, you will see error message 'CollectionWasNotInitialized'. To Initialized collection need to use init_beanie function.
- In the left settings bar, go to Network Access and check if your IP address has been added successfully. You should see a green dot in the status column. If your IP address is not added, you will not be able to connect to the database from your device.
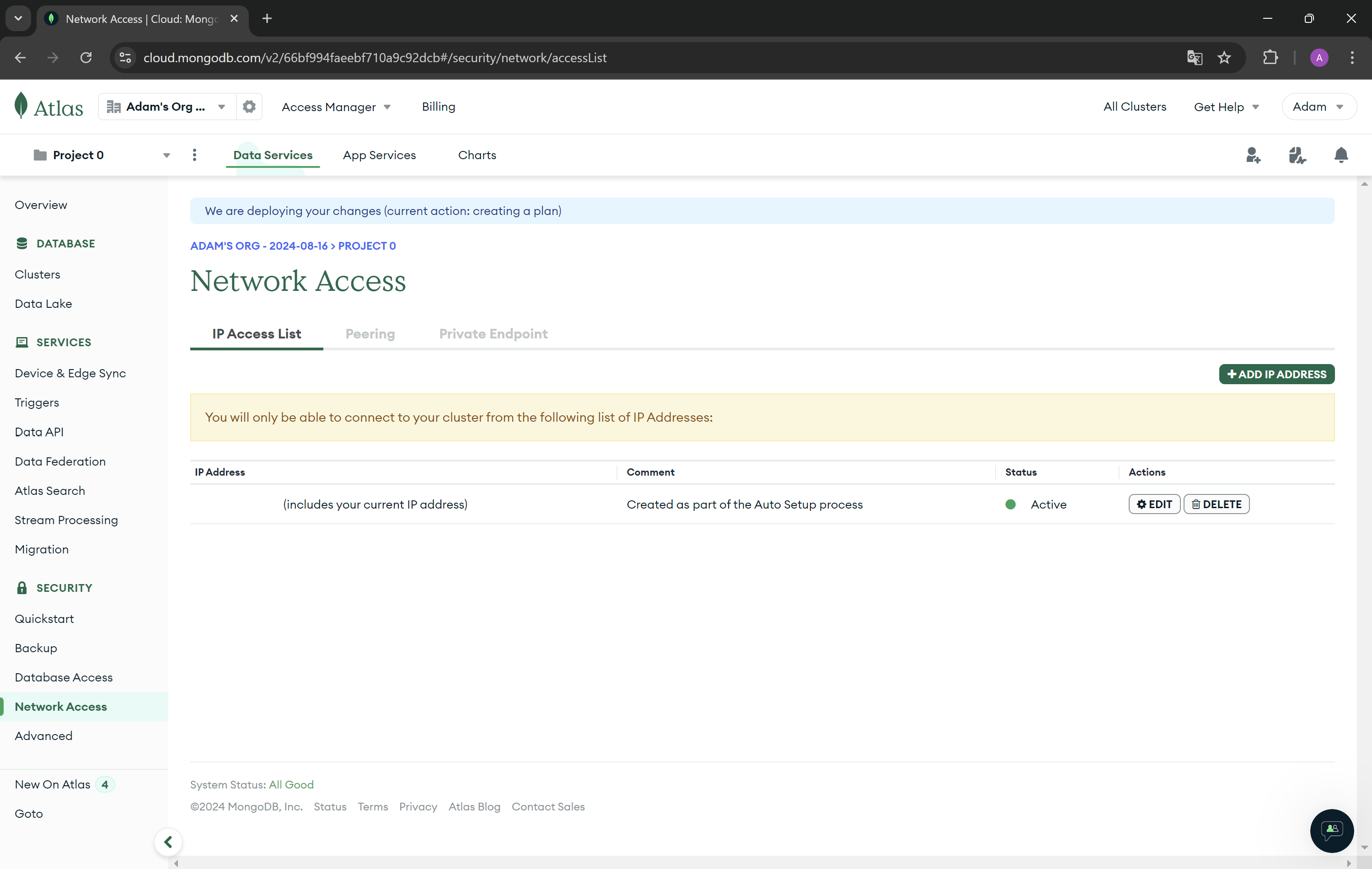
- In the left settings bar, go to Clusters and press Connect button. Then from Connect to your application choose Drivers.
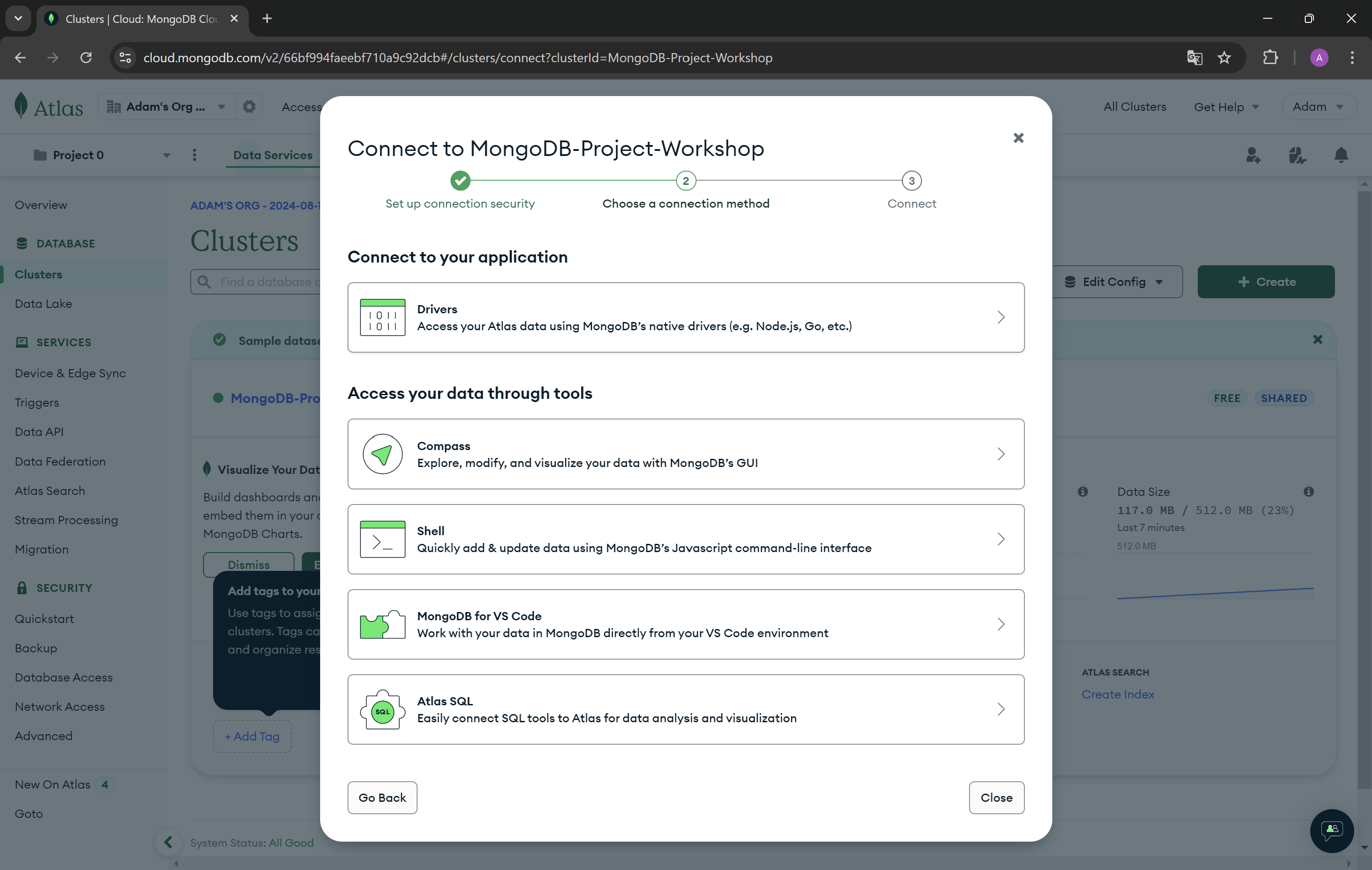
- Now copy the connection string from step 3.
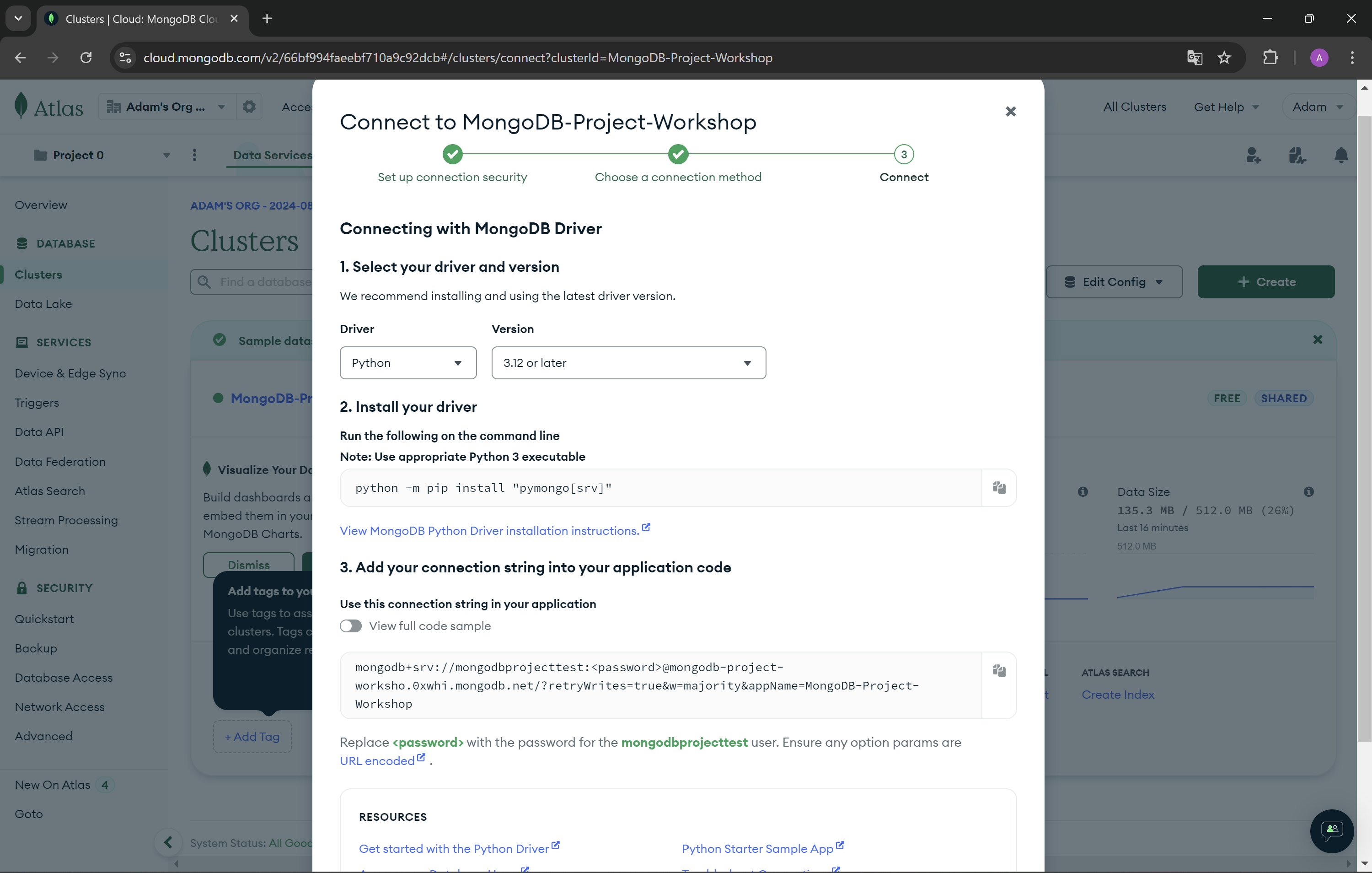
- Create a new variable in the
.envrcfile in your project. Remember to replace the password placeholder with your database user's password in the connection string.export MONGODB_URI="your_connection_string" - Install plugin for mongodb on youd IDE.
- Connect to your database from python using beanie framework.
To initialize Beanie require:
- Motor as an async database engine.
- List of your document models.




This approach isn't the way to do in production.
import os
from asyncio import run
from beanie import Document, init_beanie
from motor.motor_asyncio import AsyncIOMotorClient
async def database_init(document_models: list[Document], clear_database: bool = False) -> None:
# Create Motor client
client = AsyncIOMotorClient(os.getenv("MONGODB_URI"))
# Initialize beanie with the Sample document class and a database
await init_beanie(
database=client.workshop,
document_models=document_models,
multiprocessing_mode=True,
)
# To drop database - for easier iterate and test.
if clear_database:
client.drop_database(name_or_database=client.workshop)
run(database_init(document_models=[Task, User]))Function init_beanie also supports the parameters named:
allow_index_dropping: bool = False- If you manage the indexes by yourself, when the parameter is set toTrue, indexes will be dropped.recreate_views: bool = False- If you want to use virtual views this parameter should be set toTrue(aggregation pipelines stored in MongoDB that act as collections for reading operations).multiprocessing_mode: bool = False- If multiprocessing mode is set toTrueit will patch the motor client to use process's event loop.
Documentation for beanie initialization.
from src.database_connection import database_init
from asyncio import run
from beanie import Document
class User(Document):
name: str
surname: str
email: str
run(database_init(document_models=[User]))Do you see Schema in Atlas?
Okey, but we don't have Document.
We use will use inheritance Document class same as BaseModel class.
hot_adam = User(name="Adam", surname="Brzyzek", email="hotadam@gmail.com")
hot_adamOutput
User(id=None, revision_id=None, name='Adam', surname='Brzyzek', email='hotadam@gmail.com')We can see two additional attributes. id and revision_id.
id field reflects the unique _id field of the MongoDB document. Each object of the Document type has this field. The default type of this is PydanticObjectId.
revision_id field is for feature helps with concurrent operations.
We can use Base Model methods.
hot_adam.model_dump()
{'id': None,
'name': 'Adam',
'surname': 'Brzyzek',
'email': 'hotadam@gmail.com'}Value of id field mean that we didn't insert to database yet.
To insert OUR Adam to database we need to use one of 5 options
- insert - basic method to insert Document
- insert_many - to insert one or more Documents
- save - insert, update current object of class Document to database
- create, insert_one - synonyms for insert
Remember for each use await key word otherwise you will return couritne object & you will not insert object.
hot_adam = User(name="Adam", surname="Brzyzek", email="hotadam@gmail.com")await hot_adam.save()or
await User.save(hot_adam)or
await hot_adam.insert()or
await User.insert(hot_adam)hot_adam.model_dump()Output
{'id': '66cb3c4631b062a669d4357c',
'name': 'Adam',
'surname': 'Brzyzek',
'email': 'nothotadam@gmail.com'}How to get data?
-
find - basic function to get
- to_list
- first_or_none
-
get - get document with id, without filtering
-
find_one - get one document with filtering
-
find_all - synonyms to find({})
Get all users in database
users = await User.find().to_list()Get first user in database
result = await User.find().first_or_none()Filters Adams
adams = await User.find(User.name == "Adam").to_list()- create document Task with name, description, priority(low, normal, urgent), Size(S, M, L), Status(Backlog, TODO, InProgress, OnHold, Review, Done)
- add one user & task
example of priority type
from enum import IntEnum
class PriorityType(IntEnum):
low = 1
normal = 2
urgent = 3Solution
from enum import IntEnum
from typing import Optional
from pydantic import BaseModel
from asyncio import run
from beanie import Document
class PriorityType(IntEnum):
low = 1
normal = 2
urgent = 3
class SizeType(IntEnum):
S = 1
M = 2
L = 3
class StatusType(IntEnum):
BACKLOG = 1
TODO = 2
InProgress = 3
OnHold = 4
Review = 5
Done = 6
class Task(Document):
name: str
description: Optional[str] = None
priority: Optional[PriorityType] = None
size: Optional[SizeType] = None
status: StatusType = StatusType.BACKLOG
class User(Document):
name: str
surname: str
email: str
address: Optional[Address] = None
recently_tasks: Optional[Task] = None
run(database_init(document_models=[User, Task]))You can always extend your Document with other classes like with pydantic classes.
For example we can add technical attribute if user is active and reuse it in the task too.
from pydantic import BaseModel
from beanie import Document
class Active(BaseModel):
active: bool = True
class User(Document, Active):
name: str
surname: str
email: str
hot_adam = User(
name="Adam",
surname="Brzyzek",
email="hotadam@gmail.com")
hot_adam.model_dump()Output
{'active': True,
'id': None,
'name': 'Adam',
'surname': 'Brzyzek',
'email': 'hotadam@gmail.com'}In a relational database, you store each individual entity in its own table, and link them together through foreign keys. While MongoDB certainly supports references from one document to another, and even multi-document joins, it’s a mistake to use a document database the same way you use a relational one.
Embedded documents are an efficient and clean way to store related data, especially data that’s regularly accessed together.
In general, when designing schemas for MongoDB, you should prefer embedding by default, and use references and application-side or database-side joins only when they’re worthwhile. The more often a given workload can retrieve a single document and have all the data it needs, the more consistently high-performance your application will be.
Link to documentation for MongoDB - Embedding MongoDB https://www.mongodb.com/resources/products/fundamentals/embedded-mongodb
Example Embedded Document - User Address
from pydantic import BaseModel
from beanie import Document
from typing import Optional
class Address(BaseModel):
country: str
city: str
street: str
building_number: str
zip_code: str
class User(Document):
name: str
surname: str
email: str
address: Optional[Address] = None
hot_adam = User(
name="Adam",
surname="Brzyzek",
email="hotadam@gmail.com",
address=Address(
country="Poland",
city="Gliwice",
street="Jana Matejki 3",
building_number="IBU Craft Beers",
zip_code="44-100",
),
)Our Favorite bar in Gliwice https://maps.app.goo.gl/Jscx2wCmkE5cr2ke9
- add to User Document recently task added by user
- add extend tables with technical tables like active, create_data & update_data
- add one user & one task
Solution
from pydantic import BaseModel
from beanie import Document
from typing import Optional
from datatime import datetime
class Date(BaseModel):
create_date: datetime = datetime.now()
update_date: datetime = datetime.now()
class Address(BaseModel):
country: str
city: str
street: str
building_number: str
zip_code: str
class User(Document, Active, Date):
name: str
surname: str
email: str
address: Optional[Address] = None
recently_tasks: Optional[Task] = NoneThe document can contain links to other documents in their fields.
Example add link Task to User
from asyncio import run
from pydantic import BaseModel
from beanie import Document
from typing import Optional
User = ForwardRef("User")
class Task(Document, Date, Active):
name: str
status: StatusType = StatusType.BACKLOG
user: Link[User]
class User(Document, Date, Active):
name: str
surname: str
email: str
address: Optional[Address] = None
recently_tasks: Optional[list[Task]] = []
run(database_init(document_models=[User, Task], clear_database=True))
hot_adam = User(name="Adam",surname="Brzyzek",email="hotbrzyzek@gmail.com")
await User.insert(hot_adam)
tasks = [
Task(name="sail", user=hot_adam.id), # TODO: CHECK IF IT WORKING with hot_adam without id
Task(name="drink beers", user=hot_adam.id),
]
await Task.insert_many(tasks)
user.recently_tasks = tasks
await user.save()- create document TaskLogStatus for log task status, needs to have priority, size, status, date, link to user and task
- add task change status
Solution
class TaskLogStatus(Document, Date):
priority: Optional[PriorityType] = None
size: Optional[SizeType] = None
status: StatusType = StatusType.BACKLOG
date: datetime = datetime.now()
task: Link[Task]
user: Link[User]Updating & Deleting documentation: https://beanie-odm.dev/tutorial/updating-%26-deleting/
For update we have couple options
- save
- replace - throws: - a ValueError if the document does not have an id yet, or - a beanie.exceptions.DocumentNotFound
- update, set, inc - can be performed on the result of a find or find_one query, or on a document that was returned from an earlier query.
- set
- upsert - to insert a document when no documents are matched against the search criteri
user = await User.find(User.name == "Adam").first_or_none()
user = await user.set({User.name: "John"})
user.model_dump()Output
{'id': '66cbc95d9721746de2ec9ee6',
'name': 'John',
'surname': 'Brzyzek',
'email': 'hotbrzyzek@gmail.com'}To delete use method delete() XD
toxic_workshop_instructor = await User.find_one(User.name == "Kamil")
await toxic_workshop_instructor.delete()- Update task and user with 2 different method.
- Delete something or somebody. Do it
Solution
Come on. Don't cheat XD- This returns a FindMany object, which can be used to access the results in different ways. To loop through the results, use a async for loop:
async for result in User.find():
print(result)- When only a part of a document is required, projections can save a lot of database bandwidth and processing. For simple projections we can just define a pydantic model with the required fields and pass it to project() method
class UserBasicInfo(BaseModel):
name: str
surname: str
adams = await User.find(User.name == "Adam").project(UserBasicInfo).to_list()
adamsOutput
[]-
Settings add option from settings https://beanie-odm.dev/tutorial/defining-a-document/
-
We recommend to try interactive tutorial prepared at official website mongodb.com https://www.mongodb.com/docs/manual/tutorial/getting-started/
-
Good to check setting parameter is_root = True https://beanie-odm.dev/tutorial/inheritance/
To fill our database with data we need to generate dummy data. For that purpose has been used Faker. Faker is a Python package that generates fake data for you. List of Standard Providers you can find here.
- Creation and initialization of a Faker - dummy data generator. Below you can see the code for the init faker. Has been added the locale argument to return localized data from Poland. Seed value has been set to 2137, it will be helpful to compare the results of our queries later in the workshop.
from faker.factory import Factory
fake = Factory.create(locale="pl_PL")
fake.seed(2137)Exercise 1 - Complete the generator that will return the number of User objects determined in advance. Address fields are missing.
from collections.abc import Generator
from faker.factory import Factory
from faker.generator import Generator as FakerGenerator
from models import Address, PriorityType, SizeType, StatusType, Task, User
def user_generator(fake: FakerGenerator, number_of_iterations: int) -> Generator[User]:
for _ in range(number_of_iterations):
address = Address()
creation_date = fake.date_time_this_year(before_now=True, after_now=False)
yield User(
create_date=creation_date,
update_date=creation_date,
active=fake.pybool(truth_probability=90),
name=fake.first_name(),
surname=fake.last_name(),
email=fake.ascii_email(),
address=address
)
fake = Factory.create(locale="pl_PL")
fake.seed(2137)
print(list(user_generator(fake=fake, number_of_iterations=10)))Solution to Exercise 1
from collections.abc import Generator
from faker.factory import Factory
from faker.generator import Generator as FakerGenerator
from models import Address, PriorityType, SizeType, StatusType, Task, User
def user_generator(fake: FakerGenerator, number_of_iterations: int) -> Generator[User]:
for _ in range(number_of_iterations):
address = Address(
country="Poland",
city=fake.city(),
street=fake.street_name(),
building_number=fake.building_number(),
zip_code=fake.postcode(),
)
creation_date = fake.date_time_this_year(before_now=True, after_now=False)
yield User(
create_date=creation_date,
update_date=creation_date,
active=fake.pybool(truth_probability=90),
name=fake.first_name(),
surname=fake.last_name(),
email=fake.ascii_email(),
address=address
)
fake = Factory.create(locale="pl_PL")
fake.seed(2137)
print(list(user_generator(fake=fake, number_of_iterations=10)))Exercise 2 - Using created generator in exercise 1 create async main function that will generate 50 users and save them to your database.
from asyncio import run
from database_connection import database_init
async def main():
pass
run(main())Solution to Exercise 2
from asyncio import run
from database_connection import database_init
async def main():
await database_init()
fake = Factory.create(locale="pl_PL")
fake.seed(2137)
number_of_iterations = 50
users = list(user_generator(fake=fake, number_of_iterations=number_of_iterations))
await User.insert_many(users)
run(main())Exercise 3 - Create a generator that will return the number of Tasks for each User.
def task_generator(
fake: FakerGenerator, users: list[User], number_of_tasks_for_user: int
) -> Generator[Task]:
passSolution to Exercise 3
from datetime import date
def task_generator(
fake: FakerGenerator, users: list[User], number_of_tasks_for_user: int
) -> Generator[Task]:
for user in users:
for _ in range(number_of_tasks_for_user):
create_date = user.create_date + fake.time_delta(
end_datetime=date(2026, 1, 1)
)
yield Task(
create_date=create_date,
update_date=create_date,
active=fake.pybool(truth_probability=90),
name=fake.pystr(prefix="task_", max_chars=10),
description=fake.pystr(prefix="description_", max_chars=10),
priority=fake.enum(PriorityType),
size=fake.enum(SizeType),
status=fake.enum(StatusType),
user=user,
)Exercise 4 - Update the main function for generation 10 tasks for each created User and save them to your database.
from beanie.operators import In
async def main():
pass
run(main())Solution to Exercise 4
from beanie.operators import In
async def main():
await database_init()
fake = Factory.create(locale="pl_PL")
fake.seed(2137)
number_of_iterations = 50
users = list(user_generator(fake=fake, number_of_iterations=number_of_iterations))
users = await User.insert_many(users)
users = await User.find_many(
In(User.id, users.inserted_ids),
).to_list()
tasks = list(task_generator(fake=fake, users=users, number_of_tasks_for_user=10))
await Task.insert_many(tasks)
run(main())Exercise 5 - Create a function that updates all users and saves their last recent tasks. Also update main function to execute that function and saves last 3 tasks for each user.
from pymongo import DESCENDING
async def user_update_recent_tasks(users: list[User], number_of_tasks: int):
pass
async def main():
pass
run(main())Solution to Exercise 5
from pymongo import DESCENDING
async def user_update_recent_tasks(users: list[User], number_of_tasks: int):
for user in users:
tasks = (
await Task.find_many(Task.user.id == PydanticObjectId(user.id))
.sort((Task.create_date, DESCENDING))
.to_list(number_of_tasks)
)
user.recently_tasks = tasks
await user.save()
async def main():
await database_init()
fake = Factory.create(locale="pl_PL")
fake.seed(2137)
number_of_iterations = 50
users = list(user_generator(fake=fake, number_of_iterations=number_of_iterations))
users = await User.insert_many(users)
users = await User.find_many(
In(User.id, users.inserted_ids),
).to_list()
tasks = list(task_generator(fake=fake, users=users, number_of_tasks_for_user=10))
tasks = await Task.insert_many(tasks)
tasks = await Task.find_many(
In(Task.id, tasks.inserted_ids),
).to_list()
await user_update_recent_tasks(users=users, number_of_tasks=3)In MongoDb Atlas you can browse data from your database. On the page, you need to select Clusters from the options on the left bar and then press button Browse Collection. From this level of the page you can see the filter field used for query data. You can use all the MongoDB query operators except the $text and $expr operators.

Cheat sheet MongoDb Atlas filter.
Logical:
- AND:
{ $and: [ { field: value, field: value } ] } - OR:
{ $or: [ { field: value }, { field: value } ] } - NOT:
{ field: { $not: { $eq: value } } } - NOR:
{ $nor: [ { field: value }, { field: value } ] }
Comparison:
- Greater than:
{ field: { $gt: value } } - Greater than or equal:
{ field: { $gte: value } } - Less than:
{ field: { $lt: value } } - Less than or equal:
{ field: { $lte: value } } - In an array:
{ field: { $in: [value1, value2, ... valueN ] } } - Not in an array:
{ field: { $nin: [ value1, value2 ... valueN ] } } - Equal to:
{ field: { $eq: value } } - Not equal to:
{ field: { $ne: value } }
Embedded Field: { "field.embedded_field": value }
Exists: { field: { $exists: boolean } }
Type: { field: { $type: BSON type } }
Any of the listed types: { field: { $type: [ BSON type1 , BSON type2, ... BSON typeN ] } }
Let's create some queries in MongoDb Altas.
Exercise 1 - Search for user with id.
HINT: BSON object to contain id in mongo db is ObjectId().
Solution to Exercise 1.
{_id: ObjectId("66cb3940ad0f1a3e611edd3b")}Exercise 2 - Search for user which surname is Olko.
Solution to Exercise 2.
{surname: "Olko"}Exercise 3 - Search for users whose city address is Warszawa.
Solution to Exercise 3.
{"address.city": "Warszawa"}Exercise 4 - Search for users whose name is Krzysztof, Nicole or Angelika.
Solution to Exercise 4.
{"name": {$in: ["Krzysztof", "Nicole", "Angelika"]}}{$or: [{"name": "Krzysztof"}, {"name": "Nicole"}, {"name": "Angelika"}]}Exercise 5 - Search for tasks whose priority is low or status is Review.
HINT: Priority int enum for low is 1 and status int enum for Review is 5.
Solution to Exercise 5.
{$or: [{priority: 1}, {status: 5}]}Exercise 6 - Search for all active tasks whose creation date is after 2024-07-18.
HINT: BSON object for date in mongo db is ISODate().
Solution to Exercise 6.
{active: true, create_date: {$gt: ISODate("2024-07-18")}}create functions, for example
- get task for specific user id
- get all tasks from active users
- get created logs in date range
- create User, Task & TaskLogStatus
- delete/deactivate user, task & TaskLogStatus
Solution
Come on. Again?! XD-
Documentation for MongDB https://www.mongodb.com/docs/
-
Documentation Beanie https://beanie-odm.dev/
-
Please join official Beanie Discord Channel https://discord.gg/AwwTrbCASP
-
Official channel MongoDB - we recommend
-
Code with Mark Smith on official channel
-
Presentation on PyCon by Mark Smith - Everything You Know About MongoDB is Wrong! link
[OPTIONAL INFO] Mongoose https://www.mongodb.com/docs/mongodb-shell/
The MongoDB Shell, mongosh, is a JavaScript and Node.js REPL environment for interacting with MongoDB deployments in Atlas , locally, or on another remote host. Use the MongoDB Shell to test queries and interact with the data in your MongoDB database.
If you would like more native approach in MongoDB