Xiao Fu1 †,
Xian Liu1,
Xintao Wang2 ✉,
Sida Peng3,
Menghan Xia2,
Xiaoyu Shi2,
Ziyang Yuan2,
Pengfei Wan2
Di Zhang2,
Dahua Lin1✉
1The Chinese University of Hong Kong
2Kuaishou Technology
3Zhejiang University
†: Intern at KwaiVGI, Kuaishou Technology, ✉: Corresponding Authors
🔥 3DTrajMaster controls one or multiple entity motions in 3D space with entity-specific 3D trajectories for text-to-video (T2V) generation. It has the following features:
- 6 Domain of Freedom (DoF): Control 3D entity location and orientation
- Diverse Entities: Human, animal, robot, car, even abstract fire, breeze, etc
- Diverse Background: City, forest, desert, gym, sunset beach, glacier, hall, night city, etc
- Complex 3D trajectories: 3D occlusion, rotating in place, 180°/continuous 90° turnings, etc
- Fine-grained Entity Prompt: Change human hair, clothing, gender, figure size, accessory, etc
teaser.mp4
🔥 Release News
[2024/12/10]Release paper, project page, dataset, and code.
(1) Access to Our Internal Video Model
As per company policy, we may not release the proprietary trained model at this time. However, if you wish to access our internal model, please submit your request via (1) a shared document or (2) directly send us via email (lemonaddie0909@gmail.com) for request. We will respond to requests with the generated video as quickly as possible.
Please ensure your request includes the following:
- Entity prompts (1–3, with a maximum of 42 tokens, approximately 20 words per entity)
- Location prompt
- Trajectory template (You can refer to the trajectory template in our released 360°-Motion Dataset, or simply describe new ones via text)
(2) Access to Publicly Available Codebase
We are currently working on adapting our design to publicly available codebases (e.g., CogVideoX, LTX-Video, Mochi 1, Huanyuan). Below is a comparison between CogVideoX (w/o domain adaptor) and our internal video model as of 12.10. We will release an improved version for research purposes shortly.
CogVideoX-2024.12.10.mp4
📦 360°-Motion Dataset (Download 🤗)
├── 360Motion-Dataset Video Number Cam-Obj Distance (m)
├── 480_720/384_672
├── Desert (desert) 18,000 [3.06, 13.39]
├── location_data.json
├── HDRI
├── loc1 (snowy street) 3,600 [3.43, 13.02]
├── loc2 (park) 3,600 [4.16, 12.22]
├── loc3 (indoor open space) 3,600 [3.62, 12.79]
├── loc11 (gymnastics room) 3,600 [4.06, 12.32]
├── loc13 (autumn forest) 3,600 [4.49, 11.92]
├── location_data.json
├── RefPic
├── CharacterInfo.json
├── Hemi12_transforms.json
(1) Released Dataset Information (V1.0.0)
| Argument | Description | Argument | Description |
|---|---|---|---|
| Video Resolution | (1) 480×720 (2) 384×672 | Frames/Duration/FPS | 99/3.3s/30 |
| UE Scenes | 6 (1 desert+5 HDRIs) | Video Samples | (1) 36,000 (2) 36,000 |
| Camera Intrinsics (fx,fy) | (1) 1060.606 (2) 989.899 | Sensor Width/Height (mm) | (1) 23.76/15.84 (2) 23.76/13.365 |
| Hemi12_transforms.json | 12 surrounding cameras | CharacterInfo.json | entity prompts |
| RefPic | 50 animals | 1/2/3 Trajectory Templates | 36/60/35 (121 in total) |
| {D/N}_{locX} | {Day/Night}_{LocationX} | {C}_ {XX}_{35mm} | {Close-Up Shot}_{Cam. Index(1-12)} _{Focal Length} |
Note that the resolution of 384×672 refers to our internal video diffusion resolution. In fact, we render the video at a resolution of 378×672 (aspect ratio 9:16), with a 3-pixel black border added to both the top and bottom.
(2) Difference with the Dataset to Train on Our Internal Video Diffusion Model
The release of the full dataset regarding more entities and UE scenes is 1) still under our internal license check, 2) awaiting the paper decision.
| Argument | Released Dataset | Our Internal Dataset |
|---|---|---|
| Video Resolution | (1) 480×720 (2) 384×672 | 384×672 |
| Entities | 50 (all animals) | 70 (20 humans+50 animals) |
| Video Samples | (1) 36,000 (2) 36,000 | 54,000 |
| Scenes | 6 | 9 (+city, forest, asian town) |
| Trajectory Templates | 121 | 96 |
(3) Load Dataset Sample
-
Change root path to
dataset. We provide a script to load our dataset (video & entity & pose sequence) as follows. It will generate the sampled video for visualization in the same folder path.python load_dataset.py
-
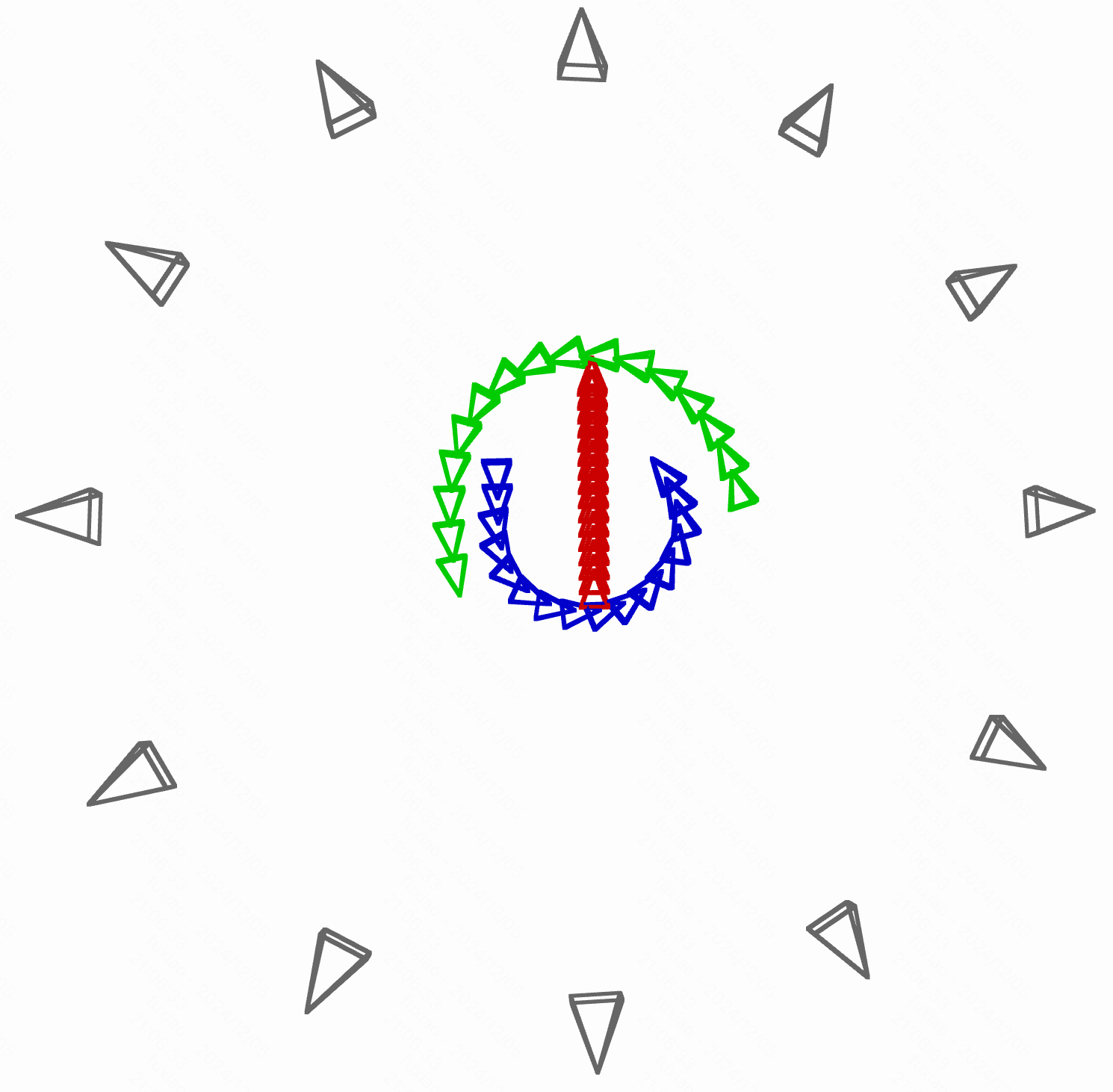
Visualize the 6DoF pose sequence via Open3D as follows.
python vis_trajecotry.py
After running the visualization script, you will get an interactive window like this.

├── eval
├── GVHMR
├── common_metrics_on_video_quality
(1) Evaluation on 3D Trajectory
-
Change root path to
eval/GVHMR. Then follow GVHMR installation to prepare the setups and (recommend using a different Conda environment to avoid package conflicts). Our evaluation input is available at here. Please note that the 3D trajectories have been downsampled from 77 frames to 20 frames to match the RGB latent space of the 3D VAE. -
Download the inference videos generated by our internal video diffusion model and corresponding evalution GT poses via the command below. You can check the 3D evaluated trajectory via our provided visualization script.
bash download_eval_pose.sh
-
Estimation for human poses on evaluation sets:
python tools/demo/demo_folder.py -f eval_sets -d outputs/eval_sets_gvhmr -s
-
Evaluation for all human samples (Note to convert the left and right hand coordinate systems) :
python tools/eval_pose.py -f outputs/eval_sets_gvhmr
(2) Evaluation on Visual Quality
-
Change root path to
eval/common_metrics_on_video_quality. Then download fvd, inference videos and base T2V inference videos through the download command belowbash download_eval_visual.sh
-
Evaluation of FVD, FID, and CLIP-SIM metrics.
pip install pytorch-fid clip bash eval_visual.sh
- MotionCtrl: the first to control 3D camera motion and 2D object motion in video generation
- TC4D: compositional text-to-4D scene generation with 3D trajectory conditions
- Tora: control 2D motions in trajectory-oriented diffusion transformer for video generation
- SynCamMaster: multi-camera synchronized video generation from diverse viewpoints
- StyleMaster: enable artistic video generation and translation with reference style image
If you find this work helpful, please consider citing:
@article{fu20243dtrajmaster,
title={3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation},
author={Fu, Xiao and Liu, Xian and Wang, Xintao and Peng, Sida and Xia, Menghan and Shi, Xiaoyu and Yuan, Ziyang and Wan, Pengfei and Zhang, Di and Lin, Dahua},
journal={arXiv preprint arXiv:2412.07759},
year={2024}
}