English Readme / 👑捐助该项目 / Q群 608815898 / 微信公众号:搜一搜“ pyvideotrans ”
这是一个视频翻译配音工具,可将一种语言的视频翻译为指定语言的视频,自动生成和添加该语言的字幕和配音。
语音识别使用
faster-whisperopenai-whisper离线模型.文字翻译支持
microsoft|google|baidu|tencent|chatGPT|Azure|Gemini|DeepL|DeepLX|离线翻译OTT,文字合成语音支持
Microsoft Edge ttsOpenai TTS-1Elevenlabs TTS自定义TTS服务器api,配合clone-voice 可实现原音色克隆配音允许保留背景伴奏音乐等(基于uvr5)
支持的语言:中文简繁、英语、韩语、日语、俄语、法语、德语、意大利语、西班牙语、葡萄牙语、越南语、泰国语、阿拉伯语、土耳其语、匈牙利语、印度语
【翻译视频并配音】根据需要设置各个选项,自由配置组合,实现翻译和配音、自动加减速、合并等
【识别字幕不翻译】选择视频文件,选择视频源语言,则从视频【语音中识别出文字】并自动导出字幕文件到目标文件夹
【提取字幕并翻译】选择视频文件,选择视频源语言,设置想翻译到的目标语言,则从【视频语音中识别出文字】并翻译为目标语言,然后导出双语字幕文件到目标文件夹
【字幕和视频合并】选择视频,然后将已有的字幕文件拖拽到右侧字幕区,将源语言和目标语言都设为字幕所用语言、然后选择配音类型和角色,开始执行
【为字幕创建配音】将本地的字幕文件拖拽到右侧字幕编辑器,然后选择目标语言、配音类型和角色,将生成配音后的音频文件到目标文件夹
【音视频识别文字】将视频或音频拖拽到识别窗口,将识别出文字并导出为srt字幕格式
【将文字合成语音】将一段文字或者字幕,使用指定的配音角色生成配音
【从视频分离音频】将视频文件分离为音频文件和无声视频
【音视频字幕合并】音频文件、视频文件、字幕文件合并为一个视频文件
【音视频格式转换】各种格式之间的相互转换
【文字字幕翻译】将文字或srt字幕文件翻译为其他语言
【人声背景乐分离】将视频中的人声和背景音乐分别分离出来,生成2个音频文件
【下载油管视频】可从youtube上下载视频
994.mp4
-
解压到英文路径下,并且路径中不含有空格。解压后双击 sp.exe (若遇到权限问题可右键使用管理员权限打开)
-
未做免杀,杀软可能误报,可忽略或使用源码部署
-
注意:必须解压后使用,不可直接压缩包内双击使用,也不可解压后移动sp.exe文件到其他位置
- 配置好 python 3.10->3.11 环境,建议3.10
git clone https://github.com/jianchang512/pyvideotranscd pyvideotranspython -m venv venv- win下执行
%cd%/venv/scripts/activate,linux和mac执行source ./venv/bin/activate pip install -r requirements.txt,如果遇到版本冲突报错,请使用pip install -r requirements.txt --no-deps
windows 和 linux 如果要启用cuda加速,继续执行 pip uninstall -y torch 卸载,然后执行pip install torch==2.1.2 --index-url https://download.pytorch.org/whl/cu121。(必须有N卡并且配置好CUDA环境)
-
win下解压 ffmpeg.zip 到根目录下 (ffmpeg.exe文件),linux和mac 请自行安装 ffmpeg,具体方法可"百度 or Google"
-
python sp.py打开软件界面 -
如果需要支持CUDA加速,需要设备具有 NVIDIA 显卡,具体安装防范见下方 CUDA加速支持
-
Ubuntu 下可能还需要安装 Libxcb 库,安装命令
sudo apt-get update sudo apt-get install libxcb-cursor0 -
Mac下可能需要执行`
brew install libsndfile`安装libsndfile
-
选择视频:点击选择mp4/avi/mov/mkv/mpeg视频,可选择多个视频;
-
保存到..:如果不选择,则默认生成在同目录下的
_video_out,同时在该目录下的srt文件夹中将创建原语言和目标语言的两种字幕文件 -
翻译渠道:可选 microsoft|google|baidu|tencent|chatGPT|Azure|Gemini|DeepL|DeepLX|OTT 翻译渠道
-
代理地址:如果你所在地区无法直接访问 google/chatGPT,需要在软件界面 网络代理 中设置代理,比如若使用 v2ray ,则填写
http://127.0.0.1:10809,若clash,则填写http://127.0.0.1:7890. 如果你修改了默认端口或使用的其他代理软件,则按需填写 -
原始语言:选择待翻译视频里的语言种类
-
目标语言:选择希望翻译到的语言种类
-
TTS和配音角色:选择翻译目标语言后,可从配音选项中,选择配音角色;
硬字幕: 是指始终显示字幕,不可隐藏,如果希望网页中播放时也有字幕,请选择硬字幕嵌入,硬字幕时可通过videotrans/set.ini 中 fontsize设置字体大小
软字幕: 如果播放器支持字幕管理,可显示或者隐藏字幕,该方式网页中播放时不会显示字幕,某些国产播放器可能不支持,需要将生成的视频同名srt文件和视频放在一个目录下才会显示
-
语音识别模型: 选择 base/small/medium/large-v2/large-v3, 识别效果越来越好,但识别速度越来越慢,所需内存越来越大,内置base模型,其他模型请单独下载后,解压放到
当前软件目录/models目录下.如果GPU显存低于4G,不要使用 large-v3整体识别/预先分割: 整体识别是指直接发送整个语音文件给模型,由模型进行处理,分割可能更精确,但也可能造出30s长度的单字幕,适合有明确静音的音频; 预先分割时指先将音频按10s左右长度切割后再分别发送给模型处理。
特别注意
faster模型:如果下载的是faster模型,下载后解压,将压缩包内的"models--Systran--faster-whisper-xx"文件夹复制到models目录内,解压复制后 models 目录下文件夹列表如下

openai模型:如果下载的是openai模型,下载后直接将里面的 .pt 文件复制到 models文件夹下即可。
-
配音语速:填写 -90到+90 之间的数字,同样一句话在不同语言语音下,所需时间是不同的,因此配音后可能声画字幕不同步,可以调整此处语速,负数代表降速,正数代表加速播放。
-
音视频对齐: 分别是“配音自动加速”和“视频自动降速”
翻译后不同语言下发音时长不同,比如一句话中文3s,翻译为英文可能5s,导致时长和视频不一致。
2种解决方式:
1. 强制配音加速播放,以便缩短配音时长和视频对齐 2. 强制视频慢速播放,以便延长视频时长和配音对齐。可同时选中两种方式,将把各自的速度调整为单独使用时的一半
-
静音片段: 填写100到2000的数字,代表毫秒,默认 500,即以大于等于 500ms 的静音片段为区间分割语音
-
CUDA加速:确认你的电脑显卡为 N卡,并且已配置好CUDA环境和驱动,则开启选择此项,速度能极大提升,具体配置方法见下方CUDA加速支持
-
TTS: 可用 edgeTTS 和 openai TTS-1模型、Elevenlabs、clone-voice、自定义TTS,openai需要使用官方接口或者开通了tts-1模型的三方接口,也可选择clone-voice进行原音色配音。同时支持使用自己的tts服务,在设置菜单-自定义TTS-API中填写api地址
-
点击 开始按钮 底部会显示当前进度和日志,右侧文本框内显示字幕
-
字幕解析完成后,将暂停等待修改字幕,如果不做任何操作,30s后将自动继续下一步。也可以在右侧字幕区编辑字幕,然后手动点击继续合成
-
将在目标文件夹中视频同名的子目录内,分别生成两种语言的字幕srt文件、原始语音和配音后的wav文件,以方便进一步处理.
-
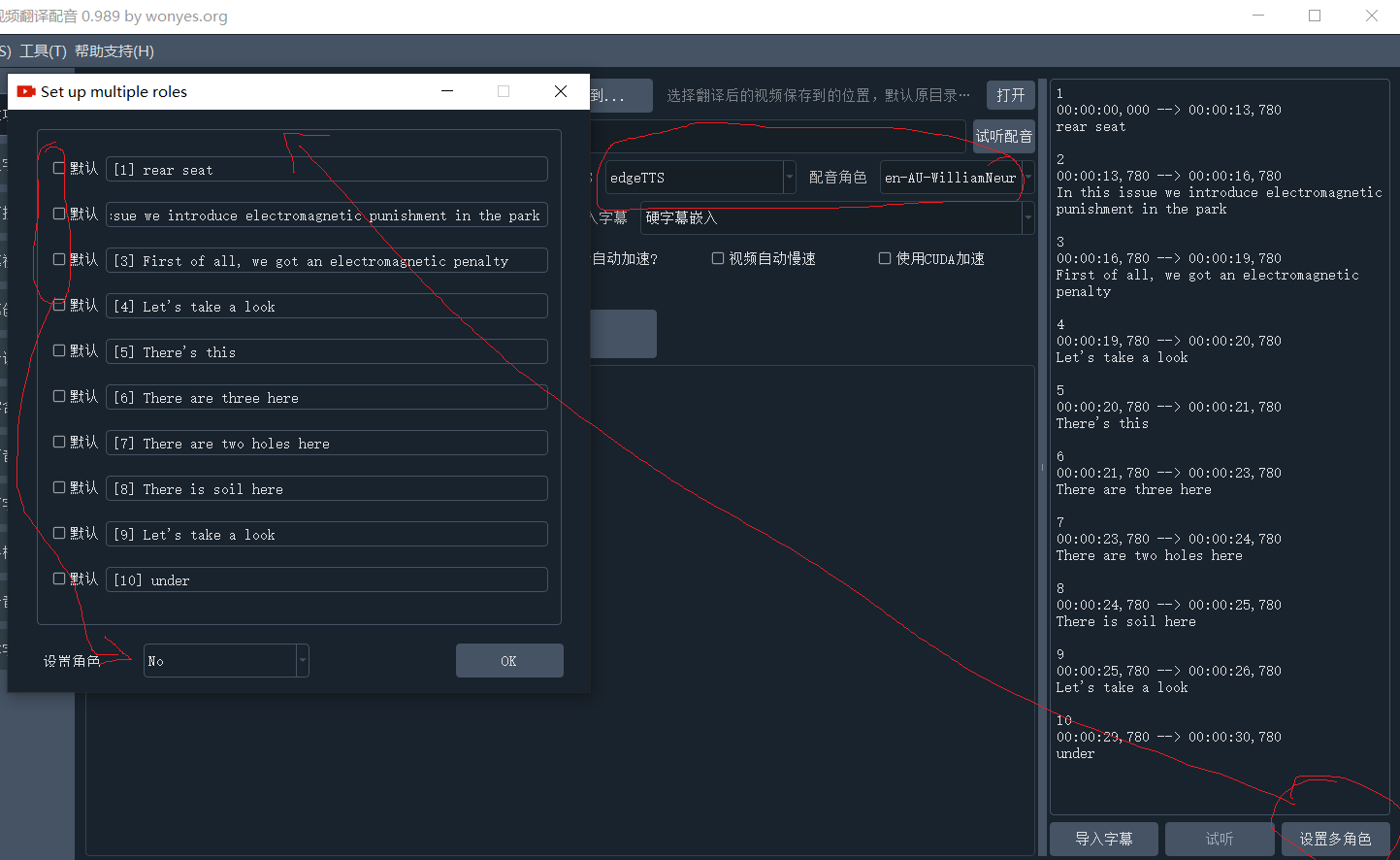
设置行角色:可对字幕中的每行设定发音角色,首先左侧选好TTS类型和角色,然后点击字幕区右下方“设置行角色”,在每个角色名后面文本中中,填写要使用该角色配音的行编号,如下图:
-
保留背景音:如果选择该项,则会先将视频中的人声和背景伴奏分离出来,其中背景伴奏最终再和配音音频合并,最后生成的结果视频中将保留背景伴奏。注意:该功能基于uvr5实现,如果你没有足够的N卡GPU显存,比如8G以上,建议慎重选择,可能非常慢并非常消耗资源。
-
原音色克隆配音:首先安装部署clone-voice项目, 下载配置好“文字->声音”模型,然后在本软件中TTS类型中选择“clone-voice”,配音角色选择“clone”,即可实现使用原始视频中的声音进行配音。使用此方式时,为保证效果,将强制进行“人声背景乐分离”。请注意此功能较慢,并且比较消耗系统资源。
-
在
videotrans/chatgpt.txtvideotrans/azure.txtvideotrans/gemini.txt文件中,可分别修改 chatGPT、AzureGPT、Gemini Pro 的提示词,必须注意里面的{lang}代表翻译到的目标语言,不要删除不要修改。提示词需要保证告知AI将按行发给它的内容翻译后按行返回,返回的行数需要同发给它的行数一致。 -
添加背景音乐:该功能和“保留背景音”类似,但实现方式不同,只可在“标准功能模式”和“字幕创建配音”模式下使用。 “添加背景音乐”是预先从本地计算机中选择一个作为背景声音的音频文件,文件路径显示在右侧文本框中,在处理结束输出结果视频时,将该音频混入,最终生成的视频里会播放该背景音频文件。

如果同时也选中了“保留背景音”,那么原始视频里的背景音也会保留。
添加背景音乐后,如果又不想要了,直接在右侧文本框中删掉显示的内容即可。
-
使用google翻译或者chatGPT,提示出错
国内使用google或chatGPT官方接口,都需要挂梯子
-
已使用了全局代理,但看起来并没有走代理
需要在软件界面“网络代理”中设置具体的代理地址,格式为 http://127.0.0.1:端口号
-
提示 FFmepg 不存在
首先查看确定软件根目录下存在 ffmpeg.exe, ffprobe.exe 文件或是否存在ffmpeg目录,如果不存在,解压 ffmpeg.7z,将这2个文件放到软件根目录下
-
windows上开启了 CUDA,但是提示错误
A: 首先查看详细安装方法,确定你已正确安装了cuda相关工具,如果仍存在错误,点击下载 cuBLAS,解压后将里面的dll文件复制到 C:/Windows/System32下
B: 若确定和A无关,那么请检查视频是否是H264编码的mp4,有些高清视频是 H265 编码的,这种不支持,可尝试在“视频工具箱”中转为H264视频
C: GPU下对视频进行硬件解码编码对数据正确性要求严格,容错率几乎为0,任何一点错误都会导致失败,加上显卡型号、驱动版本、CUDA版本、ffmpeg版本不同版本之间的差异等,导致很容易出现兼容性错误。目前加了回退,GPU上失败后自动使用CPU软件编解码。失败时logs目录下日志里会记录出错信息。
-
提示模型不存在?
模型分为两类:
一类是适用于“faster模型”的。
下载解压后,会看到文件夹,类似 “models--Systran--faster-whisper-xxx”形式的,xxx代表模型名,比如 base/small/medium/large-v3等,解压后直接将该文件夹复制到此目录下即可。
如果所有faster模型下载后,当前models文件夹下应该能看到这几个文件夹
models--Systran--faster-whisper-base models--Systran--faster-whisper-small models--Systran--faster-whisper-medium models--Systran--faster-whisper-large-v2 models--Systran--faster-whisper-large-v3
另一类是适用于"openai模型的",下载解压后,直接就是 xx.pt 文件,比如 base.pt/small.pt,/medium.pt/large-v3.pt, 直接将该pt文件复制到此文件夹内即可。
如果所有openai模型下载后,当前models文件夹下应该能直接看到 base.pt, small.pt, medium.pt, large-v1.pt, large-v3.pt
-
提示目录不存在或权限错误
在sp.exe上右键使用管理员权限打开
-
提示错误,但没有详细出错信息
打开logs目录,找到最新的log日志文件,拉到最底部,即可看到报错信息。
-
large-v3模型非常慢
如果你没有N卡GPU,或者没有配置好CUDA环境,或者显存低于8G,请不要使用这个模型,否则会非常慢和卡顿
-
提示缺少cublasxx.dll文件
有时会遇到“cublasxx.dll不存在”的错误,此时需要下载 cuBLAS,然后将dll文件复制到系统目录下
点击下载 cuBLAS ,解压后将里面的dll文件复制到 C:/Windows/System32下
-
怎样使用自定义音色
设置菜单-自定义TTS-API,填写自己的tts服务器接口地址。
将以POST请求向填写的API地址发送application/www-urlencode数据:
# 发送的请求数据:
text:需要合成的文本/字符串
language:文字所属语言代码(zh-cn,zh-tw,en,ja,ko,ru,de,fr,tr,th,vi,ar,hi,hu,es,pt,it)/字符串
voice:配音角色名称/字符串
rate:加减速值,0或者 '+数字%' '-数字%',代表在正常速度基础上进行加减速的百分比/字符串
ostype:win32或mac或linux操作系统类型/字符串
extra:额外参数/字符串
# 期待从接口返回json格式数据:
{
code:0=合成成功时,>0的数字代表失败
msg:ok=合成成功时,其他为失败原因
data:在合成成功时,返回mp3文件的完整url地址,用于在软件内下载。失败时为空
}
- 字幕语音无法对齐
翻译后不同语言下发音时长不同,比如一句话中文3s,翻译为英文可能5s,导致时长和视频不一致。
2种解决方式:
1. 强制配音加速播放,以便缩短配音时长和视频对齐 2. 强制视频慢速播放,以便延长视频时长和配音对齐。
- 字幕不显示或显示乱码
采用软合成字幕:字幕作为单独文件嵌入视频,可再次提取出,如果播放器支持,可在播放器字幕管理中启用或禁用字幕;
注意很多国内播放器必须将srt字幕文件和视频放在同一目录下且名字相同,才能加载软字幕,并且可能需要将srt文件转为GBK编码,否则显示乱码,
- 如何切换软件界面语言/中文or英文
打开软件目录下 videotrans/set.ini 文件,然后将 lang= 后填写语言代码,zh代表中文,en代表英文,修改后重启软件
;The default interface follows the system and can also be specified manually here, zh=Chinese interface, en=English interface.
;默认界面跟随系统,也可以在此手动指定,zh=中文界面,en=英文界面
lang =
- 尚未执行完毕就闪退
如果启用了cuda并且电脑已安装好了cuda环境,但没有手动安装配置过cudnn,那么会出现该问题,去安装和cuda匹配的cudnn。比如你安装了cuda12.3,那么就需要下载cudnn for cuda12.x压缩包,然后解压后里面的3个文件夹复制到cuda安装目录下。具体教程参考 https://juejin.cn/post/7318704408727519270
如果cudnn按照教程安装好了仍闪退,那么极大概率是GPU显存不足,可以改为使用 medium模型,显存不足8G时,尽量避免使用largev-3模型,尤其是视频大于20M时,否则可能显存不足而崩溃
- 如何调节字幕字体大小
如果嵌入硬字幕,可以通过修改 videotrans/set.ini 中的 fontsize=0为一个合适的值,来调节字体大小。0代表默认尺寸,20代表字体尺寸为20个像素
请勿随意调整,除非你知道将会发生什么
;如果你不确定修改后将会带来什么影响,请勿随意修改,修改前请做好备份, 如果出问题请恢复
;If you are not sure of the impact of the modification, please do not modify it, please make a backup before modification, and restore it if something goes wrong.
;升级前请做好备份,升级后按照原备份重新修改。请勿直接用备份文件覆盖,因为新版本可能有新增配置
;Please make a backup before upgrading, and re-modify according to the original backup after upgrading. Please don't overwrite the backup file directly, because the new version may have added
;The default interface follows the system and can also be specified manually here, zh=Chinese interface, en=English interface.
;默认界面跟随系统,也可以在此手动指定,zh=中文界面,en=英文界面
lang =
;Video processing quality, integer 0-51, 0 = lossless processing with large size is very slow, 51 = lowest quality with smallest size is the fastest processing speed
;视频处理质量,0-51的整数,0=无损处理尺寸较大速度很慢,51=质量最低尺寸最小处理速度最快
crf=13
;The number of simultaneous voiceovers, 1-10, it is recommended not to be greater than 5, otherwise it is easy to fail
;同时配音的数量,1-10,建议不要大于5,否则容易失败
dubbing_thread=5
;Maximum audio acceleration, default 0, i.e. no limitation, you need to set a number greater than 1-100, such as 1.5, representing the maximum acceleration of 1.5 times, pay attention to how to set the limit, then the subtitle sound will not be able to be aligned
;音频最大加速倍数,默认0,即不限制,需设置大于1-100的数字,比如1.5,代表最大加速1.5倍,注意如何设置了限制,则字幕声音将无法对齐
audio_rate=0
;Maximum permissible slowdown times of the video frequency, default 0, that is, no restriction, you need to set a number greater than 1-20, for example, 1 = on behalf of not slowing down, 20 = down to 1/20 = 0.05 the original speed, pay attention to how to set up the limit, then the subtitles and the screen will not be able to be aligned
;视频频最大允许慢速倍数,默认0,即不限制,需设置大于1-20的数字,比如1=代表不慢速,20=降为1/20=0.05原速度,注意如何设置了限制,则字幕和画面将无法对齐
video_rate=0
;Number of simultaneous translations, 1-20, not too large, otherwise it may trigger the translation api frequency limitation
;同时翻译的数量,1-20,不要太大,否则可能触发翻译api频率限制
trans_thread=15
;Hard subtitles can be set here when the subtitle font size, fill in the integer numbers, such as 12, on behalf of the font size of 12px, 20 on behalf of the size of 20px, 0 is equal to the default size
;硬字幕时可在这里设置字幕字体大小,填写整数数字,比如12,代表字体12px大小,20代表20px大小,0等于默认大小
fontsize=0
;Number of translation error retries
;翻译出错重试次数
retries=5
;chatGPT model list
;可供选择的chatGPT模型,以英文逗号分隔
chatgpt_model=gpt-3.5-turbo,gpt-4,gpt-4-turbo-preview
;When separating the background sound, cut the clip, too long audio will exhaust the memory, so cut it and separate it, unit s, default 1800s, i.e. half an hour.
;背景音分离时切分片段,太长的音频会耗尽显存,因此切分后分离,单位s,默认 600s
separate_sec=600
;The number of seconds to pause before subtitle recognition is completed and waiting for translation, and the number of seconds to pause after translation and waiting for dubbing.
;字幕识别完成等待翻译前的暂停秒数,和翻译完等待配音的暂停秒数
countdown_sec=30
;Accelerator cuvid or cuda
;硬件编码设备,cuvid或cuda
hwaccel=cuvid
; Accelerator output format = cuda or nv12
;硬件输出格式,nv12或cuda
hwaccel_output_format=nv12
;not decode video before use -c:v h264_cuvid,false=use -c:v h264_cuvid, true=dont use
;Whether to disable hardware decoding, true=disable, good compatibility; false=enable, there may be compatibility errors on some hardware.
;是否禁用硬件解码,true=禁用,兼容性好;false=启用,可能某些硬件上有兼容错误
no_decode=true
;cuda data type when recognizing subtitles from video, int8 = consumes fewer resources, faster, lower precision, float32 = consumes more resources, slower, higher precision, int8_float16 = device of choice
;从视频中识别字幕时的cuda数据类型,int8=消耗资源少,速度快,精度低,float32=消耗资源多,速度慢,精度高,int8_float16=设备自选
cuda_com_type=int8
;中文语言的视频时,用于识别的提示词,可解决简体识别为繁体问题。但注意,有可能直接会将提示词作为识别结果返回
initial_prompt_zh=转录为简体中文。
; whisper thread 0 is equal cpu core,
;字幕识别时,cpu进程
whisper_threads=4
;whisper num_worker
;字幕识别时,同时工作进程
whisper_worker=1
;Subtitle recognition accuracy adjustment, 1-5, 1 = consume the lowest resources, 5 = consume the most, if the video memory is sufficient, can be set to 5, may achieve more accurate recognition results
;字幕识别时精度调整,1-5,1=消耗资源最低,5=消耗最多,如果显存充足,可以设为5,可能会取得更精确的识别结果
beam_size=1
best_of=1
;Enable custom mute segmentation when in subtitle overall recognition mode, true=enable, can be set to false to disable when video memory is insufficient.
;字幕整体识别模式时启用自定义静音分割片段,true=启用,显存不足时,可以设为false禁用
vad=true
;0 = less GPU resources but slightly worse results, 1 = more GPU resources and better results
;0=占用更少GPU资源但效果略差,1=占用更多GPU资源同时效果更好
temperature=0
;Same as temperature, true=better with more GPUs, false=slightly worse with fewer GPUs.
;同 temperature, true=占用更多GPU效果更好,false=占用更少GPU效果略差
condition_on_previous_text=false
安装CUDA工具 详细安装方法
必须 cuda和cudnn都安装好,否则可能会闪退。
安装完成后执行 python testcuda.py 或 双击 testcuda.exe 如果输出均是 ok ,说明可用
有时会遇到“cublasxx.dll不存在”的错误, 或者未遇到此错误,并且CUDA配置正确,但始终出现识别错误,需要下载 cuBLAS,然后将dll文件复制到系统目录下
点击下载 cuBLAS,解压后将里面的dll文件复制到 C:/Windows/System32下
cli.py 是命令行执行脚本,python cli.py 是最简单的执行方式
接收的参数:
-m mp4视频的绝对地址
具体各项配置参数可在 位于 cli.py 同目录的 cli.ini 中配置,其他待处理的mp4视频地址,也可以通过命令行参数 -m mp4视频绝对地址 方式来配置,比如 python cli.py -m D:/1.mp4.
cli.ini 里是各项完整参数,第一个参数source_mp4即代表待处理的视频,如果命令行通过 -m 传参,则使用命令行参数,否则使用此source_mp4.
-c 配置文件地址
你也可以复制 cli.ini 到其他位置后,通过命令行上 -c cli.ini的绝对路径地址 来指定要使用的配置文件,比如 python cli.py -c E:/conf/cli.ini, 则会使用该文件里的配置信息,而忽略项目目录下的配置文件。
-cuda无需后跟值,只要添加即代表启用CUDA加速(如果可用) python cli.py -cuda
示例:python cli.py -cuda -m D:/1.mp4
;命令行参数
;待处理的视频绝对地址,正斜杠做路径分隔符,也可在命令行参数中 -m 后传递
source_mp4=
;网络代理地址,google chatGPT官方china必填
proxy=http://127.0.0.1:10809
;输出结果文件到目录
target_dir=
;视频发音语言,从这里选择 zh-cn zh-tw en fr de ja ko ru es th it pt vi ar tr
source_language=zh-cn
;语音识别语言 无需填写
detect_language=
;翻译到的语言 zh-cn zh-tw en fr de ja ko ru es th it pt vi ar tr
target_language=en
;软字幕嵌入时的语言,不填写
subtitle_language=
;true=启用CUDA
cuda=false
;角色名称,openaiTTS角色名称“alloy,echo,fable,onyx,nova,shimmer”,edgeTTS角色名称从 voice_list.json 中对应语言的角色中寻找。elevenlabsTTS 的角色名称从 elevenlabs.json 中寻找
voice_role=en-CA-ClaraNeural
; 配音加速值,必须以 + 号或 - 号开头,+代表加速,-代表减速,以%结尾
voice_rate=+0%
;可选 edgetTTS openaiTTS elevenlabsTTS
tts_type=edgeTTS
;静音片段,单位ms
voice_silence=500
;all=整体识别,split=预先分割声音片段后识别
whisper_type=all
;语音识别模型可选,base small medium large-v3
whisper_model=base
;翻译渠道,可选 google baidu chatGPT Azure Gemini tencent DeepL DeepLX
translate_type=google
;0=不嵌入字幕,1=嵌入硬字幕,2=嵌入软字幕
subtitle_type=1
;true=配音自动加速
voice_autorate=false
;true=视频自动慢速
video_autorate=false
;deepl翻译的接口地址
deepl_authkey=asdgasg
;自己配置的deeplx服务的接口地址
deeplx_address=http://127.0.0.1:1188
;腾讯翻译id
tencent_SecretId=
;腾讯翻译key
tencent_SecretKey=
;百度翻译id
baidu_appid=
;百度翻译密钥
baidu_miyue=
; elevenlabstts的key
elevenlabstts_key=
;chatGPT 接口地址,以 /v1 结尾,可填写第三方接口地址
chatgpt_api=
;chatGPT的key
chatgpt_key=
;chatGPT模型,可选 gpt-3.5-turbo gpt-4
chatgpt_model=gpt-3.5-turbo
; Azure 的api接口地址
azure_api=
;Azure的key
azure_key=
; Azure的模型名,可选 gpt-3.5-turbo gpt-4
azure_model=gpt-3.5-turbo
;google Gemini 的key
gemini_key=

本程序主要依赖的部分开源项目
- ffmpeg
- PySide6
- edge-tts
- faster-whisper

如果觉得该项目对你有价值,并希望该项目能一直稳定持续维护,欢迎捐助

