Documentação para a disciplina de Sistemas Distribuídos da Universidade Federal de Uberlândia (UFU).
- Tipos de sistemas distribuídos
- Características de sistemas distribuídos
- Clusters
- Comunicação
- Websockets
- Modelos computacionais
- Mensageria com Kafka
-
Sistemas de Computação Distribuída de Alto Desempenho (HPC) Sistemas utilizados para computação científica e engenharia, tarefas de alto desempenho, como simulações de física, processamento de imagens, etc.
-
Sistemas de Informação Distribuída Sistemas utilizados para armazenamento e processamento de dados, como bancos de dados, sistemas de arquivos, etc. Se faz necessário a interoperabilidade entre redes.
-
Sistemas Embarcados Distribuídos Sistemas utilizados para controle de dispositivos, como robôs, automóveis, etc. Normalmente de pequeno porte e baixo consumo de energia.
- Possibilidade de agregar poder de processamento de vários computadores para resolver um problema. Normalmente, via rede de computadores com alta largura de banda.
- São usados para programação paralela, onde o processamento é dividido em tarefas que são executadas simultaneamente.
- Um cluster é um conjunto de computadores interligados por uma rede de alta velocidade, que trabalham em conjunto para resolver um problema.
- Dedicados a tarefas específicas, como computação científica, processamento de imagens, etc.

- Conjunto de nós controlados por um sistema operacional distribuído, que permite a comunicação entre os nós. São acessados por um nó mestre, que é responsável por gerenciar os demais nós. O mestre é responsável por executar um middleware, que é um software que permite a comunicação entre os nós, execução de tarefas, gerenciamento de recursos, etc.
-
Administração Responsável por gerenciar os nós do cluster, como adicionar, remover, etc. Também é responsável por gerenciar os recursos do cluster, como memória, disco, etc.
-
Computação Responsável por executar as tarefas do cluster, como processamento de dados, etc.
-
Armazenamento Responsável por armazenar os dados do cluster, como arquivos, etc.
- É um tipo de computação distribuída, onde os recursos computacionais são compartilhados entre usuários, que podem acessar os recursos de forma remota. Os recursos são distribuídos em vários computadores, que podem estar em diferentes locais geográficos. São fracamente acoplados, ou seja, não há dependência entre os recursos.
- É a troca de informações entre dois ou mais processos, que podem estar em diferentes computadores. A comunicação pode ser síncrona ou assíncrona.
- Ponto a ponto
- Barramento Compartilhado
- Token Ring
- Modelo de referência para comunicação entre sistemas de computadores. Foi desenvolvido pela ISO (International Organization for Standardization) e é composto por 7 camadas.
- É a camada mais alta do modelo OSI. É responsável por fornecer serviços para as aplicações, como acesso a arquivos, acesso a banco de dados, etc.
- É responsável por converter os dados de uma aplicação para um formato que possa ser entendido por outra aplicação. Por exemplo, converter um arquivo de texto para um arquivo binário.
- É responsável por estabelecer, gerenciar e terminar uma sessão entre duas aplicações. Também é responsável por sincronizar as mensagens entre as aplicações.
- É responsável por estabelecer, gerenciar e terminar uma conexão entre duas aplicações. Também é responsável por sincronizar as mensagens entre as aplicações.
- É responsável por estabelecer, gerenciar e terminar uma conexão entre dois hosts. Também é responsável por rotear os pacotes entre os hosts.
- É responsável por estabelecer, gerenciar e terminar uma conexão entre dois dispositivos de rede. Também é responsável por sincronizar os bits entre os dispositivos.
- É responsável por transmitir os bits entre os dispositivos de rede.
- É um protocolo de comunicação que permite a comunicação bidirecional entre um cliente e um servidor. É baseado em TCP, que é um protocolo de comunicação orientado a conexão. O protocolo WebSocket foi desenvolvido para substituir o protocolo HTTP, que é um protocolo de comunicação não orientado a conexão.
| HTTP | WebSocket |
|---|---|
| Comunicação unidirecional | Comunicação bidirecional |
| Comunicação síncrona | Comunicação assíncrona |
| Comunicação baseada em requisição e resposta | Comunicação baseada em eventos |
- São funções que podem ser pausadas e retomadas a qualquer momento. São utilizadas para programação assíncrona.
Servidor:
import asyncio
import websockets
async def hello(websocket, path):
name = await websocket.recv()
print(f"< {name}")
greeting = f"Hello {name}!"
await websocket.send(greeting)
print(f"> {greeting}")
start_server = websockets.serve(hello, "localhost", 8765)
asyncio.get_event_loop().run_until_complete(start_server)
asyncio.get_event_loop().run_forever()Cliente:
import asyncio
import websockets
async def hello():
uri = "ws://localhost:8765"
async with websockets.connect(uri) as websocket:
name = input("What's your name? ")
await websocket.send(name)
print(f"> {name}")
greeting = await websocket.recv()
print(f"< {greeting}")
asyncio.get_event_loop().run_until_complete(hello())-
É um protocolo de comunicação que permite a comunicação entre processos em diferentes máquinas. É baseado em requisições e respostas. O cliente envia uma requisição para o servidor, que executa a tarefa e retorna uma resposta para o cliente.
-
Abre a possibilidade de executar tarefas em diferentes máquinas, de forma transparente para o cliente.
- É um framework RPC para Python. É baseado em protocol buffers, que é um formato de serialização de dados. O Proto é baseado em co-rotinas, que permite a comunicação assíncrona.
- É a troca de informações entre dois ou mais processos, que podem estar em diferentes computadores. A comunicação pode ser síncrona ou assíncrona.
- Os SDs têm a disposição processadores que permitem o desenvolvimento de aplicações paralelas
- Multiprocessamento é importante para o desenvolvimento de aplicações paralelas
- A Memória Compartilhada Distribuída (MCD) é um recurso importante para o desenvolvimento de aplicações paralelas
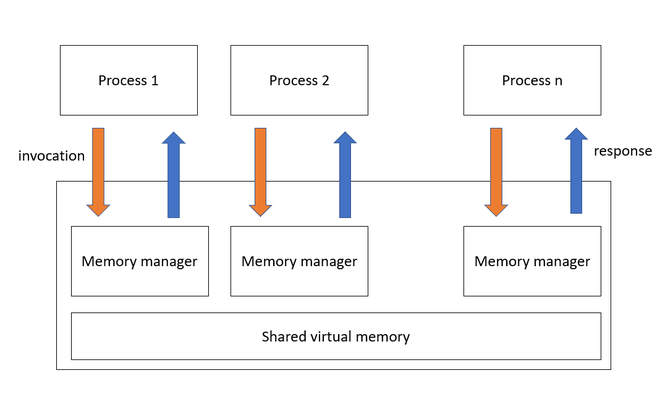
-
O conceito de processo é definido como um programa de execução
-
Concorrência x Paralelismo
- Concorrência: vários processos são executados simultaneamente, mas não necessariamente em paralelo
- Mais de um processo pode ser executado no mesmo núcleo de processamento.
- Paralelismo: vários processos são executados simultaneamente e em paralelo
- É necessário que os processos sejam executados em diferentes núcleos de processamento
- É necessário que os processos sejam executados em diferentes núcleos de processamento
- Concorrência: vários processos são executados simultaneamente, mas não necessariamente em paralelo
-
Classificação dos processos
- CPU Bound x I/O Bound
- CPU Bound: processos que utilizam mais a CPU para executar suas tarefas
- I/O Bound: processos que utilizam mais a entrada e saída para executar suas tarefas
- CPU Bound x I/O Bound

- Threads
- Multithreading
- Multiprocessing
- Threads são processos leves, que são executados dentro de um processo
- É a execução de múltiplas threads em um mesmo processo
- Vantagens
- Melhor utilização da CPU
- Melhor utilização da memória
- Melhor utilização dos recursos computacionais
- Vantagens
- É a execução de múltiplos processos em um mesmo computador
- Vantagens
- Realizar tarefas em um período de tempo menor
- Velocidade alta de processamento
- Se um processo falhar, os outros processos continuam funcionando
- Vantagens
- Kafka é uma plataforma de streaming de dados distribuída, que permite a publicação e assinatura de mensagens. É baseado em tópicos, que são fluxos de dados. Os tópicos são divididos em partições, que são os fluxos de dados. As partições são divididas em segmentos, que são os dados. Os segmentos são divididos em mensagens, que são os dados. As mensagens são divididas em registros, que são os dados.
-
Usar
- Quando a aplicação precisa de um sistema de mensageria
- Quando a aplicação precisa de um sistema de streaming de dados
- Quando a aplicação precisa de um sistema de processamento de dados em tempo real
- Quando a aplicação precisa de um sistema de processamento de dados em lote
- Quando a aplicação precisa de um sistema de processamento de dados em tempo real e em lote
-
Não usar
- Quando a aplicação não precisa de um sistema de mensageria
- Quando a aplicação não precisa de um sistema de streaming de dados
- Quando a aplicação não precisa de um sistema de processamento de dados em tempo real
- Quando a aplicação não precisa de um sistema de processamento de dados em lote
- Quando a aplicação não precisa de um sistema de processamento de dados em tempo real e em lote
- Kafka é baseado em tópicos, que são fluxos de dados. Os tópicos são divididos em partições, que são os fluxos de dados. As partições são divididas em segmentos, que são os dados. Os segmentos são divididos em mensagens, que são os dados. As mensagens são divididas em registros, que são os dados.

from kafka import KafkaProducer
from kafka import KafkaConsumer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send('meu-topico', b'Hello, World!')
consumer = KafkaConsumer('meu-topico', bootstrap_servers='localhost:9092')
for msg in consumer:
print (msg)