The project is aimed at constructing automatic aiming system based on object detection algorithm, in order to have fun in CS 1.6.
- Finish training and test of
YOLO v5andFaster-RCNN. - Finish deployment pipeline.
- Construct automatic aiming system and test.
I have published my home made dataset in Kaggle. If you want to launch my project, please download the dataset first and unzip to folder dataset in root path.
root
|--datasets
|--faster-rcnn
|--yolov5
...
run python script in console:
$python script/make_meta.py -t 20-t 20 means size of test dataset is 20. This is the default value.
Traning config of two algorithm is almost the same.
$cd yolov5
$python train.py --img 640 --batch 4 --epochs 25 --data "CS.yaml" --weights "models/pretrained/yolov5m.pt"Where models/pretrained/yolov5m.pt is the pretrained weight and will determine the specific structure of YOLO v5(yolov5m means the middle version of YOLO v5)
$python detect.py --weights "runs/train/exp/weights/best.pt" --img 640 --device 0 --source <media path>Where runs/train/exp/weights/best.pt is the finetone weight and <media path> can be path of image, video or the folder of both. If <media path> is set to 0, then webcam will be used.
python train.py --weights "default" --data "CS.yaml" --epochs 20 --batch 4weights is set to "default" in default, which means use pretrained faster-rcnn backbone. If you want to use custom weights, please set the argument. Other arguments are the same as YOLO's train.py.
$python detect.py --weights "runs/train/exp/weights/best.pt" --score 0.6 --device cuda --source <media path>Where runs/train/exp/weights/best.pt is the finetone weight and <media path> can be path of image, video or the folder of both. If <media path> is set to 0, then webcam will be used.
I have tried Faster-RCNN and YOLO v5m to realise the task. Here are the results.
I have published a demo video on My bilibili Channel to show the comparsion, there is a screenshot.
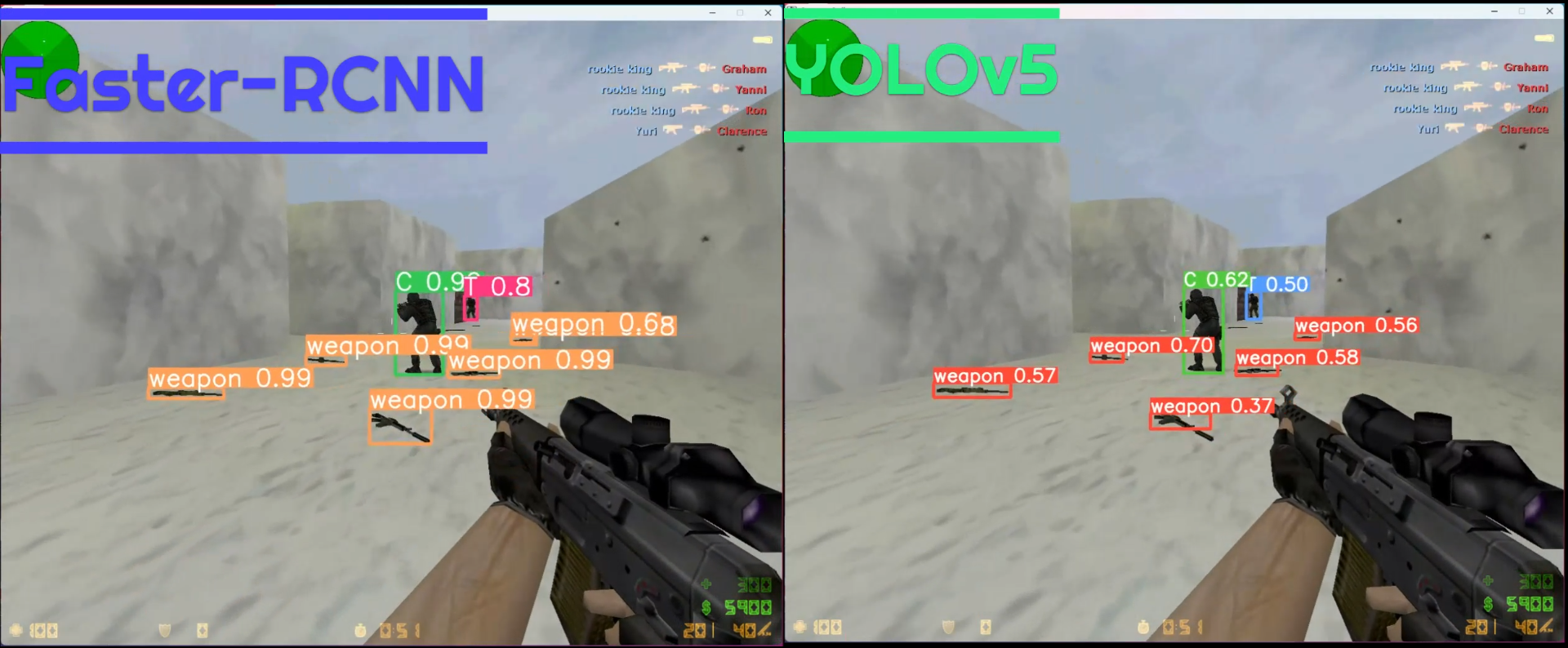
Emm, maybe the fact that different color is used on the same class should be mentioned. But I think most of you don't care :D
| model name | inference time(ms) | model size(MB) |
|---|---|---|
| Faster-RCNN | 78.51 | 158 |
| YOLO-v5m | 20.2 | 40.2 |
| model name | mAP@0.5 | weighted mAP@0.5 | bbox loss |
|---|---|---|---|
| Faster-RCNN | 0.725 | 0.190 | 0.014 |
| YOLO-v5m | 0.389 | 0.115 | 0.017 |
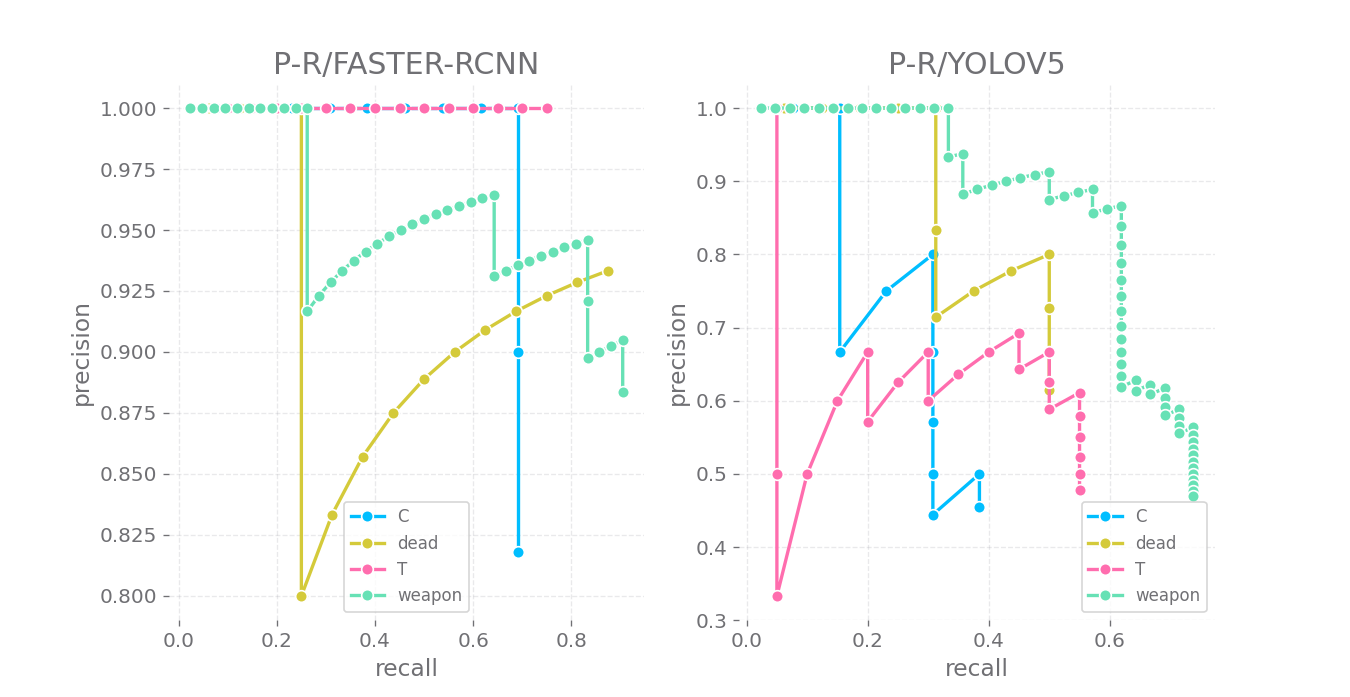
I choose Faster-RCNN for real-time inference, based on which a auto-aim and fire system is constructed.
If you want to use it, cstrike.exe must be installed in your computer (Yeah, my OS is windows11. If you use Unix, please give it a try).
At least, you should ensure that a handler named Counter-Strike can be found in your task list. First, launch cstrike.exe, choose map "ice world" and play the role of counter strike.
I suggest running the game in window mode
Then, train the weight of Faster-RCNN and suppose that the weight file is saved in "./faster-rcnn/runs/train/exp1/weights/best.pth", then run the command in your console:
$python autoaim.py --weights "../faster-rcnn/runs/train/exp1/weights/best.pth" --device cuda --score 0.6 --debug --auto-aim --auto-fire--device cudameans we use GPU to accelerate inference.--score 0.6means only bbox whose confidence is greater 0.6 will be displayed or considered in later process.--debugmeans run the program in a debug mode, then an extra window which is rendered with bbox and its corresponding predicted class will be generated.--auto-aimmeans program will move your mouse if it detected enemy.--auto-firemeans program will open the fire automatically.
Why model's accuary is low when the enemy is counter strike or the map is not "ice world"?
Emm, I only construct the dataset in the view of counter strike in this map, so if you like ...