This R-Package calculates the Reputation of a Subject following the methods developed by Eisenegger (2005). An English description of the method is available in this discussion paper.
The Index is calculated with the following formula:
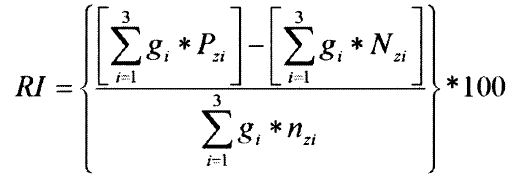
where g is the factor used for weighting, P are the positively and N the negatively rated elements (eg. articles/texts/tweets) and n is the total sample. The index can take values from -100 to +100.
# The easiest way to get eisenrep is to install it from Github:
devtools::install_github("LTribelhorn/eisenrep")
# and load it into the environment
library(eisenrep)If the devtools are not already installed these need to be installed first with:
install.packages("devtools")
library(devtools)The Input needs to be a dataframe containing texts (eg. Tweets, Articles, etc.) or their corresponding IDs, their rating ("positiv", "negativ", "ambivalent" or "neutral") and optionally a column with numeric values used as weigth (eg. Nr of Retweets, Nr of Recipients, Centrality of Agent, etc.).
eisenrep(df, rating, followers_count)
#> [1] "The weighted Reputationindex (following Eisenegger, 2005) is 6.97397566612722."
#> [1] "The unweighted Reputationindex (following Eisenegger, 2005) is -53.3333333333333."
#> $gRepIndex
#> [1] 6.973976
#>
#> $RepIndex
#> [1] -53.33333
rep <- eisenrep(df, rating, followers_count)
#> [1] "The weighted Reputationindex (following Eisenegger, 2005) is 6.97397566612722."
#> [1] "The unweighted Reputationindex (following Eisenegger, 2005) is -53.3333333333333."
eisenrep(df, rating)
#> [1] "The unweighted Reputationindex (following Eisenegger, 2005) is -53.3333333333333."
#> $RepIndex
#> [1] -53.33333If you encounter a bug, please file a minimal reproducible example on github. If you have a feature request please file an issue as well. If you have questions or encounter problems, please contact me via Email, via Twitter, or send a pigeon over.