https://www.kaggle.com/sudalairajkumar/simple-exploration-notebook-2-connect
https://www.kaggle.com/poonaml/two-sigma-renthop-eda
https://www.kaggle.com/neviadomski/data-exploration-two-sigma-renthop
A Complete Tutorial which teaches Data Exploration in detail
- min/max/mean/meduim/std


- 直方(Histogram Plot)/散点(Scatter Plot)分布图
- 查看类数据分布趋势、密度和是否有离群点
- feature/label分布是否均衡
- train/test分布是否一致
- 数据是否符合i.i.d.

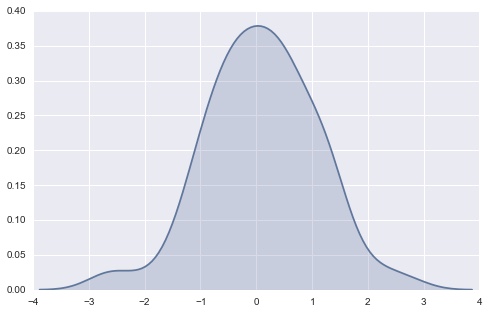
- 箱形图(Box Plot)
- 可以直观查看数值变量的分布

- 琴形图(Violin Plot)
- 表征了在一个或多个分类变量情况下连续变量数据的分布,并进行了比较,是一种观察多个数据分布有效方法

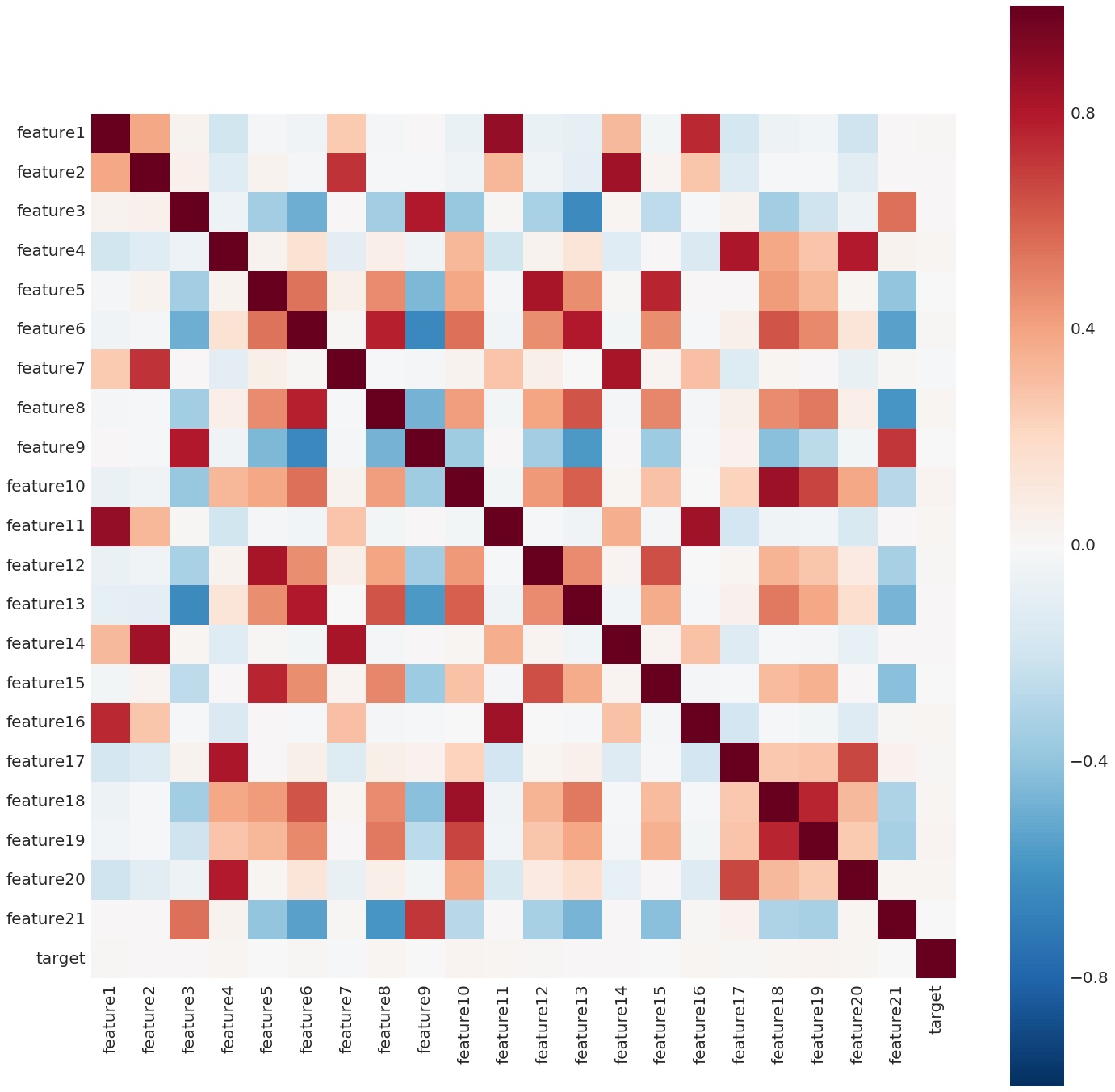
- Correlation Coefficient图,表征变量之间两两分布和相关度
- 常用工具:matplotlib/seaborn





- 数据太大 -> OOM -> batch
- 用平均值、中值、上下数据、分位数、众数、随机值等填充
- 用其他变量做预测模型来算出缺失变量
- 把变量映射到高维空间(增加缺失维度为新特征)
- 直接舍弃feature或样本(缺失值过多)
- 忽略(一些模型,如随机森林,自身能够处理数据缺失的情况)
- 时序数据:平滑、寻找相似、用插值法进行填充
- Drop Outliers
- 直接剔除样本
- 将outliers值归为上下限
- 文本数据:
- 垃圾字符、错别字(词)、数学公式、不统一单位和日期格式等
- 处理标点符号、分词、去停用词
- 英文文本可能还要词性还原(lemmatize)、抽取词干(stem)等。
- Standard Scale
- Min-Max Scale
- 一般方法:one-hot-encoding
- 类变量太多:Feature Encoding
Simple Methods to deal with Categorical Variables in Predictive Modeling
- 增强鲁棒性(降低过拟合)
- 扩充数据集
Building Powerful Image Classification Models Using Very Little Data
特征没做好,调参调到老 Kaggle:Feature 为主,调参和 Ensemble 为辅
前期:尽可能多地抽取特征,只要你认为某个特征对解决问题有帮助,它就可以成为一个特征,相信 model能够挑出最有用的feature。
- 凭经验、对任务的直观判断、思考数据集构造(magic feature)
- 数值型特征:线性组合、多项式组合来构造新feature
- 文本特征:文本长度、Word Embeddings、TF-IDF、LDA、LSI等,深度学习提取feature
- 稀疏特征:特征合并后one-hot-encoding(cat allowed和dog allowed合并成为pet allowed)
- 图片特征:bottleneck feature
- 时序问题:滑窗feature
- 通过Feature Importance(Random Forest、XGBoost对每个feature在分类上面的重要程度进行评估),对重要特种再提取
过多的feature会造成冗余、噪声、容易过拟合
- Correlation Coefficient(相关系数)衡量两个变量之间的线性关系,数值在[-1.0, 1.0]区间中。数值越接近0,两个变量越线性不相关。但数值为0时,并不能说明两个变量不相关,只是线性不相关而已。如果两个Feature的相关度很高,就有可能存在冗余。
- 训练模型来筛选特征,如Random Forest、GDBT、XGBoost等,看Feature Importance。Feature Importance 对于某些数据经过脱敏处理的比赛尤其重要。
High Categorical(高势集类别),如邮编。
- 进行经验贝叶斯转换成数值feature(统计学思路:类 -> 频率)
- 根据 Feature Importance 或变量取值在数据中的出现频率,为最重要(比如说前 95% 的 Importance)的取值创建 Dummy Variables,而其他取值都归到一个“其他”类里面
- 替换原有n个features
- 扩充为新feature
- 硬聚类算法:k-Means(k均值)算法、FCM算法
- 线性方法:PCA(主成分分析)、SVD(奇异值分解)
- 非线性方法:t-SNE聚类、Sammon映射、Isomap、LLE、CCA、SNE、MVU等
- 深度学习降维,如embedding、bottleneck feature、autoencoders、denoising autoencoder
- Baseline Model
- Week Models
- Linear Regression(带惩罚项)
- Logistic Regression
- KNN(K-Nearest Neighbor)
- Decision Tree
- Extra Tree
- SVM(SVC/SVR)
- Strong Models
- Random Forest
- GBM(Gradient Boosting Machines)
- GBDT(Gradient Boosting Decision Trees)
- GBRT(Gradient Boosted Regression Trees)
- AdaBoost
- XGBoost
- LightGBM
- CatBoost
- Temporal Models
- moving average
- exponential smoothing
- Markov Model/Hidden Markov Model
- ARIMA
- RNN/LSTM
- Neural Networks(Deep Learning)
主要目的为评估模型、用于模型选择(包括模型种类、参数、结构) CV分数很可能和LB分数不一致,如何选择Case By Case
- Simple Split
- k-Fold
- 降低variance,提升模型鲁棒性,降低overfitting的风险
- Fold越多训练也就会越慢,需要根据实际情况进行取舍
- group-k-fold(reduce overfitting)
- Adversarial Validation
- 从train set中选出和test set中最相似的部分作为valid set
- Adversarial Validation
- 时序问题:valid在train后、滑窗
Improve Your Model Performance using Cross Validation
- MSE/RMSE
- L1_Loss(误差接近0的时候不平滑)/L2_Loss
- Hinge_Loss/Margin_Loss
- Cross-entropy_Loss/Sigmoid_Cross-ntropy_Loss/Softmax_Cross-entropy_Loss
- Log_Loss
- ROC/AUC
- 难以定义目标loss:End2End强化学习
- Algorithms:
- Random Search
- Grid Search
- TPOT(Tree-based Pipeline Optimisation Technique),基于遗传算法自动选择、优化机器学习模型和参数
- Steps:
- 根据经验,选出对模型效果影响较大的超参
- 按照经验设置超参的搜索空间,比如学习率的搜索空间为[0.001,0.01, 0.1]
- 选择搜索算法,如Grid Search、一些启发式搜索的方法
- 验证模型的泛化能力
Complete Guide to Parameter Tuning in Gradient Boosting (GBM)
Complete Guide to Parameter Tuning in XGBoost
Feature决定了模型效果的上限,而Ensemble就是让你更接近这个上限。 将多个不同的Base Model组合成一个Ensemble Model。可以同时降低最终模型的Bias和Variance,从而在提高分数的同时又降低Overfitting的风险。
Kaggle: 不用Ensemble几乎不可能得奖
Averaging: 对每个Base Model生成的结果取(加权)平均。 Voting: 对每个Base Model生成的结果进行投票,并选择最高票数的结果为最终结果。
- Bagging:使用训练数据的不同随机子集来训练每个Base Model,最后进行每个Base Model权重相同的Average或Vote。
- 多个Base Model的线性组合。
- 也是Random Forest的原理。
- Quick Guide to Boosting Algorithms in Machine Learning
- Boosting:“知错能改”。迭代地训练也是Random Forest的原理,每次根据上一个迭代中预测错误的情况修改训练样本的权重。
- 比Bagging效果好,但更容易Overfit。
- 也是Gradient Boosting的原理。
- Blending:用不相交的数据训练不同的Base Model,将它们的输出取(加权)平均。
- 实现简单,但对训练数据利用少了。
- Stacking:用新的Stack Model学习怎么组合那些Base Model。
- 多个Base Model的非线性组合。
- 为了避免Label Leak,需要对每个学习器使用k-Fold,将k个模型对valid set的预测结果拼起来,作为下一层学习器的输入。 - feature复用
- feature复用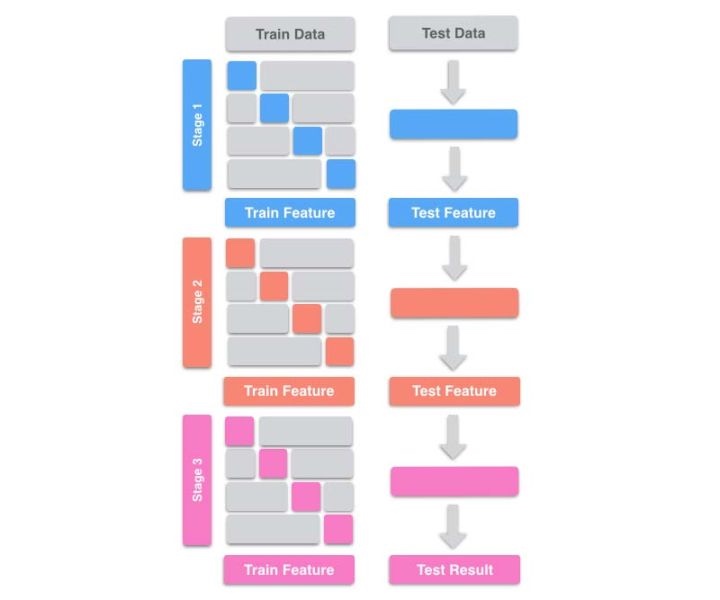


- Base Model 之间的相关性要尽可能的小。Ensemble 的 Diversity 越大,最终 Model 的 Bias 就越低。
- Base Model 之间的性能表现不能差距太大。
- Trade-off
Basics of Ensemble Learning Explained in Simple English
- Naive Bayes
- Bayes networks
- EM(Expectation Maximization Algorithm)
- Gaussian Mixture Models
- Mixture of Gaussians Clustering
label类别不均衡问题。
- Stratified k-Fold
- under-sampling(欠采样)
- EasyEnsemble
- over-sampling(过采样)
- SMOTE(Synthetic Minority Over-sampling Technique)
- Borderline-SMOTE,将少数类样本根据距离多数类样本的距离分为noise,safe,danger三类样本集,只对danger中的样本集合使用SMOTE算法
- 移动阈值
How to handle Imbalanced Classification Problems in machine learning
8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset
- 自动化
- 封装性
- 保存所有log
- 保存模型 -> 复现
- seed
- train_seed
- cv_seed
- global_seed
- 关于比赛
- 泛化性能衡量
- 规则、先验知识
- PRML(Pattern Recognition and Machine Learning)
- EoS(The Elements of Statistical Learning)
- CO(Convex Optimization)
- 统计学习方法(李航,清华大学出版社)
- 机器学习(周志华, 清华大学出版社)- 西瓜书
- 机器学习实战(Peter Harrington,人民邮电出版社出版)
- UFLDL Tutorial: Unsupervised Feature Learning and Deep Learning
- Best Machine Learning Resources for Getting Started
- A Tour of Machine Learning Algorithms
- Machine Learning GitHub
- How to start doing Kaggle competitions?
- What do top Kaggle competitors focus on?
- A Journey Into Data Science
- Techniques to improve the accuracy of your Predictive Models
##网盘:
- https://pan.baidu.com/s/1skU0xEt
- 密码:nxnc