![]()
VCD: Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding
This is the official repo for Visual Contrastive Decoding, a simple, training-free method for mitigating hallucinations in LVLMs during decoding without utilizing external tools.
- [2023-11-29]: ⭐️ Paper of VCD online. Check out this link for details.
- [2023-11-28]: 🚀🚀 Codes released.

- We introduce Visual Contrastive Decoding (VCD), a simple and training-free method that contrasts output distributions derived from original and distorted visual inputs.
- The new contrastive probability distribution for decoding is formulated as follows:
- The proposed VCD effectively reduces the over-reliance on statistical bias and unimodal priors, two essential causes of object hallucinations.
conda create -yn vcd python=3.9
conda activate vcd
cd VCD
pip install -r requirements.txt-
VCD significantly mitigates the object hallucination issue across different LVLM families.
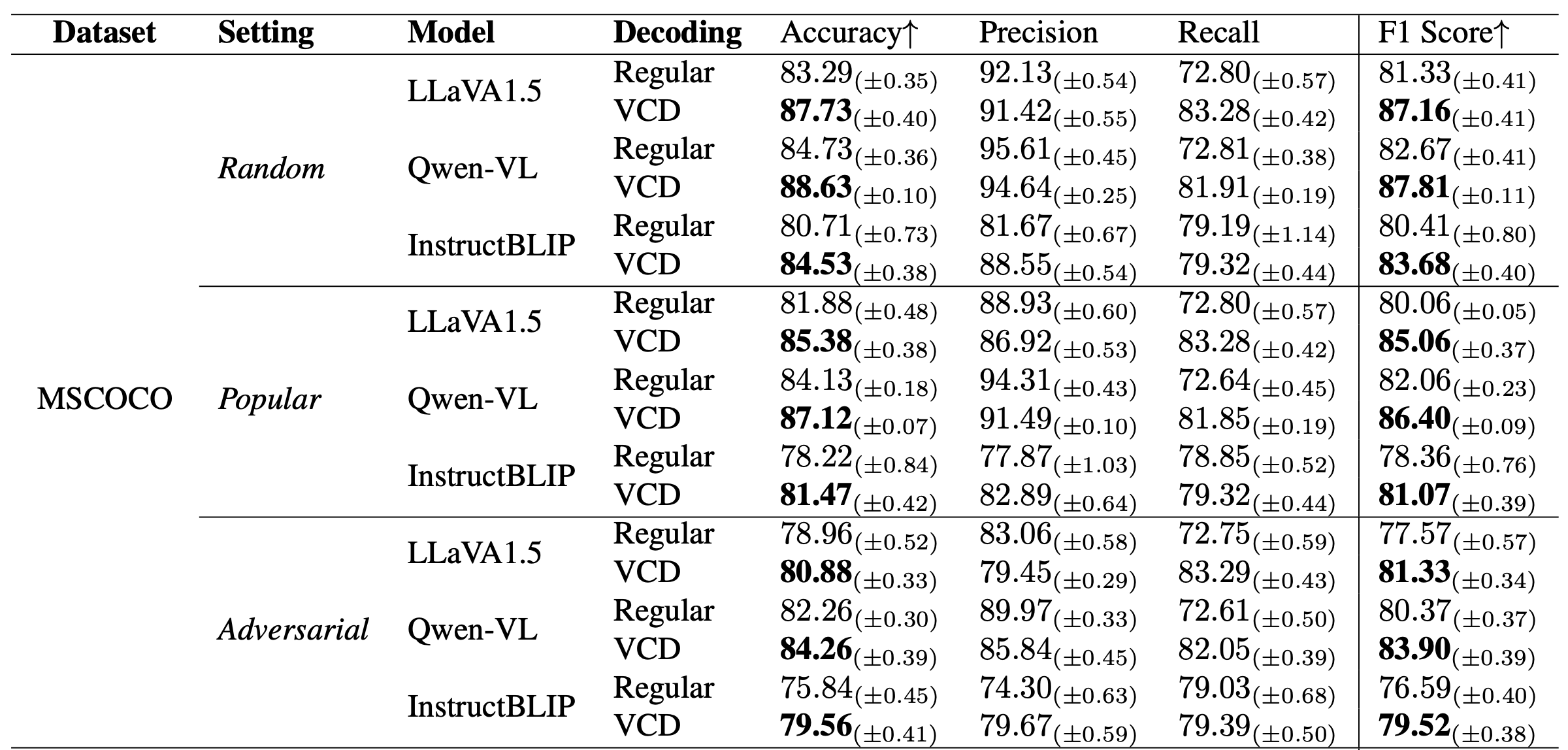 table 1(Part of). Results on POPE. Regular decoding denotes direct sampling, whereas VCD refers to sampling from our proposed contrastive distribution pvcd. The best performances within each setting are bolded.
table 1(Part of). Results on POPE. Regular decoding denotes direct sampling, whereas VCD refers to sampling from our proposed contrastive distribution pvcd. The best performances within each setting are bolded. -
Beyond mitigating object hallucinations, VCD also excels in general LVLM benchmarks, highlighting its wide-ranging applicability.
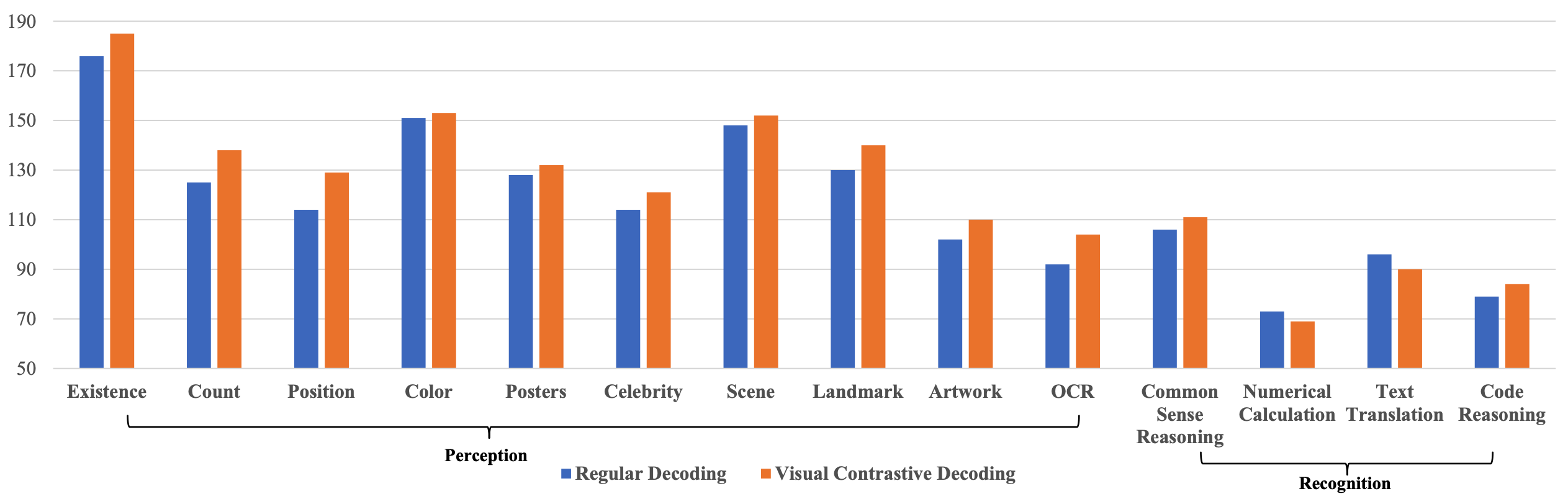 figure 4. MME full set results on LLaVA-1.5. VCD consistently enhances LVLMs’ perception capacities while preserving their recognition competencies.
figure 4. MME full set results on LLaVA-1.5. VCD consistently enhances LVLMs’ perception capacities while preserving their recognition competencies.



table 3. Results of GPT-4V-aided evaluation on open-ended generation. Accuracy measures the response’s alignment with the image content, and Detailedness gauges the richness of details in the response. Both metrics are on a scale of 10.
- Please refer to our paper for detailed experimental results.
 figure 5. Illustration of hallucination correction by our proposed VCD with two samples from LLaVA-Bench. Hallucinated objects from LVLM's regular decoding are highlighted in red.
figure 5. Illustration of hallucination correction by our proposed VCD with two samples from LLaVA-Bench. Hallucinated objects from LVLM's regular decoding are highlighted in red.
 figure 8. More examples from LLaVA-Bench of our proposed VCD for enhanced general perception and recognition capacities.
figure 8. More examples from LLaVA-Bench of our proposed VCD for enhanced general perception and recognition capacities.
 figure 7. More examples from LLaVA-Bench of our proposed VCD for hallucination corrections. Hallucinated objects from LVLM's regular decoding are highlighted in red.
figure 7. More examples from LLaVA-Bench of our proposed VCD for hallucination corrections. Hallucinated objects from LVLM's regular decoding are highlighted in red.
If you find our project useful, we hope you can star our repo and cite our paper as follows:
@article{damonlpsg2023vcd,
author = {Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, Lidong Bing},
title = {Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding},
year = 2023,
journal = {arXiv preprint arXiv:2311.16922},
url = {https://arxiv.org/abs/2311.16922}
}
- Contrastive Decoding: Open-ended Text Generation as Optimization
- InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
- Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- LLaVA 1.5: Improved Baselines with Visual Instruction Tuning