22-23秋 国科大操作系统高级教程课程笔记
思考题
-
为什么开始启动计算机的时候, 执行的是BIOS代码而不是操作系统自身的代码?
计算机被设计为只能执行内存中的指令, 而刚上电时内存中什么都没有, 没有软件方案可以开始运行操作系统, 因此将硬件设计为开机就执行位于
0xFFFF0处的程序. 为了避免各操作系统分别实现只与主板而不是CPU相关的中断程序, 由主办厂商独立于操作系统开发出固化在主板上ROM中的BIOS程序, BIOS和操作系统开发团队两头约定BIOS做好准备 (如创建BIOS中断) 后从启动扇区将操作系统的代码加载到约定位置0x07C00, 从此位置开始执行. 这样各团队可以灵活地设计出具有自己特色的系统版本. -
为什么BIOS只加载了一个扇区, 后续扇区却是由bootsect代码加载? 为什么BIOS没有直接把所有需要加载的扇区都加载?
为了BIOS与各操作系统都能协同工作, BIOS与操作系统之间的协调机制是BIOS只负责把启动扇区加载到约定位置
0x07C00然后从这里开始执行操作系统的代码, 由操作系统完成后续操作. -
为什么BIOS把bootsect加载到
0x07C00, 而不是0x00000? 加载后又马上挪到0x90000处, 是何道理? 为什么不一次加载到位?0x07C00(BOOTSECT) 是BIOS与操作系统的约定地址, 是历史原因. BIOS将启动扇区的内容复制至0x07C00后会从0x07C00处开始执行指令, 如果一开始没有把bootsect放在此处无法进入Linux自己的启动流程. 之所以bootsect一开始将自己挪至0x90000是因为当时system模块长度不会超过0x80000字节 (在Linux0.11中只有120KB), 因此从0x07C00移动至0x90000能保证bootsect程序不会被自己加载的system模块覆盖. -
bootsect, setup, head程序之间是怎么衔接的? 给出代码证据. setup程序的最后是
jmpi 0,8, 为什么这个8不能简单地当作阿拉伯数字8看待, 就是有什么内涵?// boot/bootsect.s ... SETUPLEN = 4 ! nr of setup-sectors BOOTSEG = 0x07c0 ! original address of boot-sector INITSEG = 0x9000 ! we move boot here - out of the way SETUPSEG = 0x9020 ! setup starts here ... load_setup: mov dx,#0x0000 ! drive 0, head 0 mov cx,#0x0002 ! sector 2, track 0 mov bx,#0x0200 ! address = 512, in INITSEG mov ax,#0x0200+SETUPLEN ! service 2, nr of sectors int 0x13 ! read it jnc ok_load_setup ! ok - continue mov dx,#0x0000 mov ax,#0x0000 ! reset the diskette int 0x13 j load_setup ... ! ok, we've written the message, now ! we want to load the system (at 0x10000) mov ax,#SYSSEG mov es,ax ! segment of 0x010000 call read_it call kill_motor ... ! after that (everyting loaded), we jump to ! the setup-routine loaded directly after ! the bootblock: jmpi 0,SETUPSEG
在
load_setup标签后通过向通用寄存器AX, BX, CX, DX赋值来向中断向量为0x13的BIOS中断服务程序传参, 指定从0号设备0磁头对应扇面的0磁道2扇区开始加载4个扇区的内容到段基址为0x9000(INITSEG), 偏移为0x200(bx) 处. 因此将bootsect将setup加载到了0x90200处.然后在
read_it标签中又用BIOS中断int0x13将随后240个扇区的system模块 (以head程序开头) 加载到了段基址为0x1000(SYSSEG) 处.然后通过
jmpi 0, SETUPSEG跳转到了段基址为0x9020(SETUPSET), 偏移为0处, 开始执行setup// boot/setup.s ... ! first we move the system to it's rightful place mov ax,#0x0000 cld ! 'direction'=0, movs moves forward do_move: mov es,ax ! destination segment add ax,#0x1000 cmp ax,#0x9000 jz end_move mov ds,ax ! source segment sub di,di sub si,si mov cx,#0x8000 rep movsw jmp do_move ! then we load the segment descriptors end_move: mov ax,#SETUPSEG ! right, forgot this at first. didn't work :-) mov ds,ax lidt idt_48 ! load idt with 0,0 lgdt gdt_48 ! load gdt with whatever appropriate ... ! Well, now's the time to actually move into protected mode. To make ! things as simple as possible, we do no register set-up or anything, ! we let the gnu-compiled 32-bit programs do that. We just jump to ! absolute address 0x00000, in 32-bit protected mode. mov ax,#0x0001 ! protected mode (PE) bit lmsw ax ! This is it! jmpi 0,8 ! jmp offset 0 of segment 8 (cs) ... gdt: .word 0,0,0,0 ! dummy .word 0x07FF ! 8Mb - limit=2047 (2048*4096=8Mb) .word 0x0000 ! base address=0 .word 0x9A00 ! code read/exec .word 0x00C0 ! granularity=4096, 386 .word 0x07FF ! 8Mb - limit=2047 (2048*4096=8Mb) .word 0x0000 ! base address=0 .word 0x9200 ! data read/write .word 0x00C0 ! granularity=4096, 386 idt_48: .word 0 ! idt limit=0 .word 0,0 ! idt base=0L gdt_48: .word 0x800 ! gdt limit=2048, 256 GDT entries .word 512+gdt,0x9 ! gdt base = 0X9xxxx
在
do_move标签中将system模块移动到了内存地址起始位置, 然后在end_move标签中用lgdt gdt_48指令将GDT的32位线性基地址 (setup起始地址0x90200+gdt列表的标签地址偏移) 和表限长加载到GDTR (越后的字节在越高位).然后用
lmsw ax打开保护模式后内存分段机制被开启,jmpi 0,8的8不再是段基址, 而是16位段选择子[15-3: INDEX|2: TI|1-0: RPL].0x8即0b0000000000001 0 00, 表示选择GBT下标为1的项 (段描述符). 这是内核代码段的段描述符, 段基地址为0x0000 0000, 段限长为0x7FF*4KB=8MB (粒度G为1, 段长增量单位为4KB). 因此jmpi 0,8是跳到段基地址为0x0, 偏移为0处, 即head程序开头, 开始执行head. -
保护模式在"保护"什么? 它的"保护"体现在哪里? 特权级的目的和意义是什么? 分页有"保护"作用吗?
- 保护模式保护的是进程/任务的地址空间, 其保护性体现在基于内存分段, 内存分页 (可选) 机制提供了一种将每个进程/任务地址空间隔离的机制, 控制对特定段或页的访问, 未经许可不得访问其他用户的资源, 保证多个进程/任务能运行在同一个处理器上而不会相互干扰.
- 特权级是用以实现保护模式的手段, 特权级是建立在线性地址的段上的. 处理器识别CPL, DPL, RPL三种类型的特权级, 除非某些可控制情况外, 处理器使用特权级来阻止较低特权级的进程/任务访问特权级较高的段. 依托于特权级机制才能实现对特定段/页的访问的控制.
- 我认为分页的保护作用建立在切换CR3的指令是特权指令这个基础之上. 分页机制使每个进程/任务处于不同的线性地址空间, 用户页分配机制使用户页物理地址不可预测, 而切换CR3的指令是特权指令保证了当前进程/任务地址空间外线性地址不可访问. 即便可以利用内核分页是线性映射因此地址可预测, 从而在GDT中记录的所有任务的TSS段描述符的性质获得各任务的CR3, 也无法切换CR3, 实现了各进程/任务地址空间的隔离.
-
在setup程序里曾经设置过GDT, 为什么在head程序中将其废弃, 又重新设置了一个? 为什么设置两次, 而不是一次搞好?
我认为是为了执行完head程序后内存起始位置到main之间的部分尽可能是有用的数据结构, 剩余代码也尽量保证有用, 因此Linux0.11选择将开启保护模式的代码放在setup程序中执行. 而开启保护模式后如果要用
jmpi指令跳转到不在同一段 (在setup程序中段基址为SETUPSEG) 的head程序, 需要先有GDT. 因此在setup程序中需要建立一个GDT, 其中有一个指向head程序的代码段描述符和一个指向head程序的数据段描述符. 而setup程序中的GDT之后会被缓冲区覆盖 (Linux内核设计的艺术2.10节), 因此在head程序中需要加载新的GDT, 而此GDT就放在head程序所占空间最省事. -
进程0的
task_struct在哪? 具体内容是什么? 在IA-32中, 有大约20多个指令是只能在0特权级下使用, 其他的指令, 比如cli, 并没有这个约定. 奇怪的是, 在Linux0.11中, 3特权级的进程代码并不能使用cli指令, 这是为什么? 请解释并给出代码证据.include/linux/sched.h:
/* * INIT_TASK is used to set up the first task table, touch at * your own risk!. Base=0, limit=0x9ffff (=640kB) */ #define INIT_TASK \ /* state etc */ { 0,15,15, \ /* signals */ 0,{{},},0, \ /* ec,brk... */ 0,0,0,0,0,0, \ /* pid etc.. */ 0,-1,0,0,0, \ /* uid etc */ 0,0,0,0,0,0, \ /* alarm */ 0,0,0,0,0,0, \ /* math */ 0, \ /* fs info */ -1,0022,NULL,NULL,NULL,0, \ /* filp */ {NULL,}, \ /* ldt */ { \ {0,0}, /* 进程0空段描述符 */ \ {0x9f,0xc0fa00}, /* NOTE: 进程0代码段 */ \ {0x9f,0xc0f200}, /* NOTE: 进程0数据段 */ \ }, \ /*tss*/ {0,PAGE_SIZE+(long)&init_task,0x10,0,0,0,0,(long)&pg_dir,\ 0,0,0,0,0,0,0,0, /* 第二个0是EFLAGS值 */ \ 0,0,0x17,0x17,0x17,0x17,0x17,0x17, \ _LDT(0),0x80000000, \ {} \ }, \ }
CPL, IOPL (IO特权域, EFLAGS[13:12]), CR4中VME标志 (当处于虚拟8086模式时) 决定IF标志 (中断许可, EFLAGS[9]) 是否可由
CLI,STI,POPF,POPFD,IRET指令修改. 进程0的EFLAGS被设为0, 因此无法再以3特权级执行cli等指令, 而所有其他进程都是fork进程0得到的, 因此3特权级进程都无法使用cli指令. -
内核的线性地址空间是如何分页的?画出从
0X000000开始的6个页 (包括页目录表, 页表所在页) 的挂接关系图, 第一个页表的前6个页表项指向什么位置? 给出代码证据.Linux内核设计的艺术 27-29页, 页目录表及四个内核页表的初始化.
-
在head程序执行结束的时候, 在idt的前面有184个字节的head程序的剩余代码, 剩余了什么? 为什么要剩余?
after_page_tables: pushl $0 # These are the parameters to main :-) pushl $0 pushl $0 pushl $L6 # return address for main, if it decides to. /* NOTE: 这里压栈后在跳转到setup_paging执行完然后L224的ret后会进入C语言内核主函数. */ pushl $_main jmp setup_paging L6: jmp L6 # main should never return here, but # just in case, we know what happens. /* This is the default interrupt "handler" :-) */ int_msg: .asciz "Unknown interrupt\n\r" .align 2 ignore_int: pushl %eax pushl %ecx pushl %edx push %ds push %es push %fs movl $0x10,%eax mov %ax,%ds mov %ax,%es mov %ax,%fs pushl $int_msg call _printk popl %eax pop %fs pop %es pop %ds popl %edx popl %ecx popl %eax iret .align 2 setup_paging: movl $1024*5,%ecx /* 5 pages - pg_dir+4 page tables */ xorl %eax,%eax xorl %edi,%edi /* pg_dir is at 0x000 */ cld;rep;stosl movl $pg0+7,_pg_dir /* set present bit/user r/w */ // NOTE: 放到内存起始位置处 movl $pg1+7,_pg_dir+4 /* --------- " " --------- */ movl $pg2+7,_pg_dir+8 /* --------- " " --------- */ movl $pg3+7,_pg_dir+12 /* --------- " " --------- */ movl $pg3+4092,%edi movl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */ std 1: stosl /* fill pages backwards - more efficient :-) */ subl $0x1000,%eax jge 1b xorl %eax,%eax /* pg_dir is at 0x0000 */ movl %eax,%cr3 /* cr3 - page directory start */ movl %cr0,%eax orl $0x80000000,%eax movl %eax,%cr0 /* set paging (PG) bit */ // NOTE: 打开分页 ret /* this also flushes prefetch-queue */
在
setup_idt标签中将所有idt表项指向了ignore_int标签处, 作为未使用的中断描述符的默认值, 这样误用未使用中断描述符时就会打印提示信息. 而setup_paging标签中是在初始化页目录表及四个内核页表, 这是进入main函数前最后的操作, 没有办法被覆写, 只能剩余. 同时after_page_tables标签借助setup_paging标签最后的ret指令模拟压栈后main函数入口地址弹出给EIP, 切换到执行main函数. 因此after_page_tables也是必须保留的仍有用的代码. -
为什么不用
call, 而是用ret“调用”main()? 画出调用路线图, 给出代码证据.Linux内核设计的艺术 42页.
不用
call而是手动实现了call的所有操作只是一个逻辑问题: 内核主函数应当是最根本的函数, 被其他函数调用在逻辑上不够合理. 应当是面向过程式地执行一系列准备工作后执行主函数, 然后执行一些收尾操作. -
用文字和图以
set_trap_gate(0,÷_error)为例说明中断描述符表是如何初始化的, 并给出代码证据. -
读懂下面这段
include/asm/system.h中的代码. 这里中断门, 陷阱门, 系统调用门都是通过_set_gate()设置的, 用的是同一个嵌入汇编代码, 比较明显的差别是DPL一个是3, 另外两个是0, 这是为什么?#define _set_gate(gate_addr,type,dpl,addr) \ __asm__ ("movw %%dx,%%ax\n\t" \ "movw %0,%%dx\n\t" \ "movl %%eax,%1\n\t" \ "movl %%edx,%2" \ : \ : "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \ "o" (*((char *) (gate_addr))), \ "o" (*(4+(char *) (gate_addr))), \ "d" ((char *) (addr)),"a" (0x00080000)) #define set_intr_gate(n,addr) \ _set_gate(&idt[n],14,0,addr) #define set_trap_gate(n,addr) \ _set_gate(&idt[n],15,0,addr) #define set_system_gate(n,addr) \ _set_gate(&idt[n],15,3,addr)
-
进程0 fork进程1之前, 为什么先调用
move_to_user_mode()? 用的是什么方法? 解释其中的道理.Linux内核设计的艺术 78-80页.
执行
move_to_user_mode()前SS指向内存起始位置, ESP指向stack_start (user_stack[1024]的末端, 即内核栈的栈顶), 执行move_to_user_mode()后这个0特权级栈 (此时内核尚未完成初始化, 没有内核态用户态之分) 变为从内存起始位置到stack_start的3特权级0进程用户栈. -
在Linux操作系统中大量使用了中断, 异常类的处理, 究竟有什么好处?
中断和异常是一些提示性事件, 表明系统/处理器或当前执行的程序或任务中存在着某种需要处理器注意的状态. 典型情况下这些事件会导致当前运行程序/任务的执行强制转移到一个称为中断处理程序或异常处理程序的特殊软件/任务中. 处理器响应中断或异常所采取的行动称为服务.
典型情况下中断是在程序执行过程中随机发生的, 是对硬件信号的响应. 系统硬件使用中断去处理处理器的外部事件, 比如服务外设的请求. 此外软件可以使用
INT n指令产生中断.异常是在处理器执行指令的过程中发现错误状况而产生的.
中断的意义: 摆脱轮询, 允许切换到其他任务, 主动激励, 被动响应. 而异常的出现使针对特定类型错误进行相同处理成为可能. 一方面减少了系统的无效消耗, 提升了效率, 另一方面降低了开发复杂度.
-
copy_process()的参数最后五项是:long eip,long cs,long eflags,long esp,long ss, 查看栈结构确实有这五个参数, 奇怪的是其他参数的压栈代码都能找得到, 却找不到这五个参数的压栈代码, 反汇编代码中也查不到, 请解释原因.int copy_process( int nr,long ebp,long edi,long esi,long gs, long none, long ebx,long ecx,long edx,long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss )
copy_process()的参数由kernel/system_call.s中多个函数通过压栈传参. 通常最后压入栈的是最前面的参数 (可以更改). nr到gs为_sys_fork压入, none为_system_call中call _sys_call_table(,%eax,4)时压入的EIP (none只用于占位, 此EIP没有用), ebx到ds为_system_call压入, eip到ss为触发INT 80时硬件自动压入. -
分析
get_free_page()函数的代码, 叙述在主内存中获取一个空闲页的技术路线. -
分析
copy_page_tables()函数的代码, 叙述父进程如何为子进程复制页表. -
进程0创建进程1时, 为进程1建立了
task_struct及内核栈, 第一个页表, 分别位于物理内存16MB顶端倒数第一页, 第二页. 请问这两个页究竟占用的是谁的线性地址空间, 内核/进程0/进程1, 还是没有占用任何线性地址空间? 说明理由 (可以图示) 并给出代码证据. -
假设经过一段时间的运行, 操作系统中已经有5个进程在运行, 且内核分别为进程4, 进程5创建了第一个页表, 这两个页表在谁的线性地址空间? 用图表示这两个页表在线性地址空间和物理地址空间的映射关系.
-
代码中的
ljmp %0\n\t很奇怪, 按理说jmp指令跳转到的位置应该是一条指令的地址, 可是这行代码却跳到了"m" (*&__tmp.a), 这明明是一个数据的地址, 更奇怪的, 这行代码竟然能正确执行. 请论述其中的道理#define switch_to(n) {\ struct {long a,b;} __tmp; \ __asm__("cmpl %%ecx,_current\n\t" \ "je 1f\n\t" \ "movw %%dx,%1\n\t" \ "xchgl %%ecx,_current\n\t" \ "ljmp %0\n\t" \ "cmpl %%ecx,_last_task_used_math\n\t" \ "jne 1f\n\t" \ "clts\n" \ "1:" \ ::"m" (*&__tmp.a),"m" (*&__tmp.b), \ "d" (_TSS(n)),"c" ((long) task[n])); \ }
Linux内核设计的艺术 106-107页.
这个
ljmp不能按字面意思理解为跳转到TSS这个数据段, 而是通过任务门机制保存当前进程任务现场至TSS, 并恢复进程n的TSS记录的任务现场, 强行切换至进程n. -
进程0开始创建进程1, 调用
fork(), 跟踪代码时我们发现,fork()代码执行了两次, 第一次, 执行fork()代码后, 跳过init()直接执行了for(;;) pause(), 第二次执行fork()代码后, 执行了init(). 奇怪的是我们在代码中并没有看到跳转向fork()的goto语句, 也没有看到循环语句, 是什么原因导致fork反复执行? 请说明理由 (可以图示), 并给出代码证据. -
getblk()中, 申请空闲缓冲块的标准就是b_count为0, 而申请到之后为什么在wait_on_buffer(bh)后又执行if (bh->b_count)来判断b_count是否为0? -
b_dirt已经被置为1的缓冲块, 同步前能够被进程继续读/写?给出代码证据.
-
分析
panic()的源代码, 根据你学过的操作系统知识, 完整准确地判断panic()所起的作用。假如操作系统设计为支持内核进程 (始终运行在0特权级的进程), 你将如何改进panic()? -
详细分析进程调度的全过程. 考虑所有可能 (signal, alarm除外)
-
wait_on_buffer()函数中为什么不用if而是用while?因为当
sleep_on()返回时当前在等待的缓冲块不一定解锁了, 可能当前进程触发的中断还没处理完, 也可能又被其他进程上锁了. 因此需要用while确保在当前块解锁的情况下才退出wait_on_buffer()函数 -
操作系统如何利用b_uptodate保证缓冲块数据的正确性?
new_block(int dev)函数新申请一个缓冲块后并没有读盘, b_uptodate却被置1, 是否会引起数据混乱? 详细分析理由. -
add_request()函数中下列代码前两行是什么意思?if (!(tmp = dev->current_request)) { dev->current_request = req; sti(); (dev->request_fn)(); return; }
-
do_hd_request()函数中dev的含义始终一样吗? -
read_intr()函数中, 下列代码是什么意思? 为什么这样做?if (--CURRENT->nr_sectors) { do_hd = &read_intr; return; }
-
bread()函数代码中为什么要做第二次if (bh->b_uptodate)判断?if (bh->b_uptodate) return bh; ll_rw_block(READ,bh); wait_on_buffer(bh); if (bh->b_uptodate) return bh;
-
getblk()函数中, 两次调用wait_on_buffer()函数, 两次的意思一样吗? -
说明
getblk()函数中下列代码什么情况下执行continue/breakdo { if (tmp->b_count) continue; if (!bh || BADNESS(tmp)<BADNESS(bh)) { bh = tmp; if (!BADNESS(tmp)) break; } /* and repeat until we find something good */ } while ((tmp = tmp->b_next_free) != free_list);
-
make_request()函数中下列代码中sleep_on(&wait_for_request)是谁在等? 等什么?if (req < request) { if (rw_ahead) { unlock_buffer(bh); return; } sleep_on(&wait_for_request); goto repeat; }
32位80x86架构基础知识
架构


32位80x86系列处理器采用全32位结构, 寄存器, ALU, 操作, 数据线, 地址线均为32位, 因此最大可寻址物理地址空间为$2^{32}$B=4GB.
寄存器


- 通用寄存器:
- SP (Stack Pointer): 栈顶指针寄存器 (栈由高地址向低地址生长)
- BP (Base Pointer): 基址指针寄存器/栈帧指针寄存器, 此指针始终指向栈最上面 (最新) 一个栈帧的底部, 主要用于保存/恢复栈帧. 当栈帧为空时ESP与EBP重合.
- 栈帧: EBP指向当前栈帧底部, ESP指向当前栈帧顶部. 当有函数调用时, 新维护的内容由低地址到高地址大致有:
- 函数返回地址 (代码中函数调用指令下一条指令的地址)
- 上一个栈帧的EBP所指地址
- (新栈帧的EBP所指位置) 当前函数的局部变量等临时变量
- ...(新栈帧的ESP所指位置)
- 栈帧: EBP指向当前栈帧底部, ESP指向当前栈帧顶部. 当有函数调用时, 新维护的内容由低地址到高地址大致有:
- ...
- 段寄存器: 段寄存器有对用户可见和不可见两部分 (不可见部分也被称为段描述符寄存器/描述符高速缓存等), 当段选择子被装载到段寄存器段可见部分时, 处理器也将段选择子指向的段描述符装载到不可见部分. 段寄存器保存的信息使得处理器在进行地址转换时不需要花费额外的总线周期来从段描述符中获取段基地址及段界限.
- CS (Code Segment Register): 代码段寄存器, 在CPU中, 记录当前执行代码段在内存中起始位置
- ...
- 有两种载入段寄存器的指令:
- 直接载入指令: 如
MOV,POP,LDS,LSS等. 这些指令明确指定了相应的寄存器. - 隐含的载入指令: 如远指针型的
CALL,JMP,RET指令,IRET,INT[n]等指令. 伴随这些指令CS寄存器的内容被改变 (有时也包括其他段寄存器).
- 直接载入指令: 如
- 💡任何程序要执行都至少要给CS, DS, SS赋予有效段选择子. ES, FS, GS是为当前执行程序/任务提供额外数据段的段寄存器.
- IP (Instruction Pointer): 指令指针寄存器, 记录将要执行的指令在代码段中偏移地址.
CS<<4+IP即下一条执行的指令的内存地址. 实模式下IP为16位物理地址, 保护模式下为32位线性地址 (EIP). - 系统寄存器: 为了更好进行处理器初始化及控制系统运行, IA-32架构提供了几个系统寄存器及若干在EFLAGS寄存器内的系统标志
- EFLAGS寄存器内系统标志和IOPL域控制着任务和模式的切换, 中断处理, 指令跟踪和访问权限.
- 控制寄存器 (CR0, CR1, CR2, CR3)
- 内存管理寄存器
- GDTR: GDT基地址寄存器. GDT可以存放在内存任何位置, 操作系统对GDT初始化后用
LGDT指令将GDT基地址加载到GDTR, 通过GDTR维护其基地址. - IDTR: IDT基地址寄存器. 同理IDT也可以在内存任何位置.
- LDTR: 如上图所示, LDTR只有低16位是对用户可见的, 当用
LLDT指令装载一个段选择子到LDTR中时, LDT描述符的基地址, 段限长, 属性就会自动装载到不可见部分 (对不可见部分的描述见段寄存器). - TR: 任务寄存器.
- GDTR: GDT基地址寄存器. GDT可以存放在内存任何位置, 操作系统对GDT初始化后用
- 测试寄存器
- 模型相关寄存器 (MSR)
保护模式
- 实地址模式: 该模式提供intel8086处理器编程环境并稍作扩展 (如可以切换到保护模式/系统管理态). 在实地址模式下使用0~19号共20根地址线对
0XFFFFFB=1MB物理地址空间寻址. 实模式下当程序寻址超过0XFFFFF时, 该值将溢出, 即0XFFFFF+1=0X00000. - 80x86处理器在上电或复位后进入实地址模式, 将CR0最低位PE标志置1后进入保护模式
- 进入保护模式后改为使用32根地址线对4GB虚拟地址空间寻址. 因此在实模式下寻址
0x100000将溢出, 寻址到0x00000, 而在保护模式下则会寻址到线性地址0x100000.- 检测保护模式是否有效: 利用刚上电时内存各字节初始化值为0的特性, 只要
0x00000处值非0, 比较0x00000与0x100000处值, 若不一样即可知A20地址线成功打开, 保护模式成功生效.
- 检测保护模式是否有效: 利用刚上电时内存各字节初始化值为0的特性, 只要
- 在保护模式下分段机制是必须的, 分页机制是通过CR0最高位PG标志可选开启的.
- 打开保护模式后除了CR3, 页目录表, 页表中存有物理地址, 其他地方使用的都是线性地址, 从线性地址到物理地址的转换是由MMU根据页目录表, 页表, 页的设置由硬件自动完成的.
保护模式内存管理

分页机制: 当一个进程/任务试图访问线性地址空间的一个地址时, 处理器通过页目录表及页表将线性地址转换为物理地址, 然后对对应物理地址执行要求的操作 (读/写)
RPL是请求特权级, 另外还有CPL (当前任务的当前特权级), DPL (描述符特权级). 仅当CPL为0时才能执行特权指令, 否则会产生一般保护错误 (#GP)
IA-32架构保护模式内存管理分为两部分:
- 分段机制: 提供了一种将每个进程/任务的代码, 数据和栈的模块隔离开的机制, 保证多个进程/任务能在同一个处理器上运行而不相互干扰.
- 分页机制: 分页机制是为了实现传统的请求调页虚拟内存系统. 在这种系统中程序的执行环境块按需要被映射到物理内存中.
💡在内存中做出数据有两种方式:
- 划分一块内存区域并初始化数据 (手动给定值), 看护住这块内存, 使之能被找到
- 由代码做出数据, 如用
push压栈, 做出数据
分段机制
段用来装载一个程序的代码/数据或堆栈/系统的数据结构 (TSS, LDT等). 段由段描述符定义, 通过段选择子和段描述符访问. 可以定义有很多个段, 但只有段选择子被装载到了段寄存器的段才可以被程序访问到. 分段是历史上为了让程序能够链接子程序 (函数)的方法, 所有程序的设计都是基于段. IA32架构对进程线性地址空间保护是基于段的, 即==特权级是建立在段上的==.
段通常与所保存的代码或数据结构大小一致, 如果只使用分段进行地址转换则一个数据结构必须全部保存在物理内存中. 而页有固定大小 (4KB/4MB/..., 4KB最常见), 可以将一个数据结构部分存在内存中, 部分存在硬盘中. 这让虚拟内存大小不完全受制于物理内存大小.
💡线性地址空间是一维的, 因此我们只需段头和段尾地址就能看护住一个段, 但Intel早期CPU为了降低成本只设计了段头寄存器, 没有段尾寄存器, 为了兼容早期CPU, GDTR, IDTR, 段寄存器不可见部分中包含了限长, 等效于有段尾寄存器了.
IA32架构定义了两个系统段: TSS (Task State Stack, 任务状态段), LDT (Local Descriptor Table, 局部描述符表). ==GDT, IDT不是段==, 因为没有定义GDT, IDT的段描述符, 这两者也不是通过段选择子与段描述符访问的.
- GDT (Global Descriptor Table): 全局描述符表, 系统中唯一存放段寄存器内容 (段描述符) 的数组
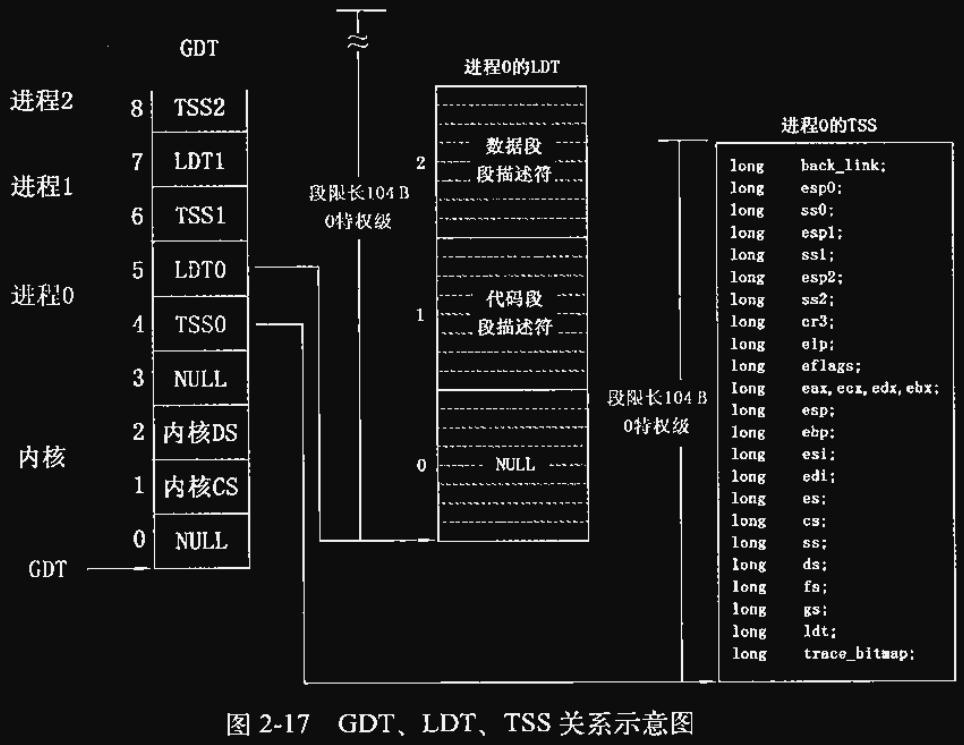 GDT第0项的NULL描述符是不被使用的. 指向这个描述符的段选择子为空段选择子. 空段选择子可以被装载入数据段寄存器 (DS/ES/FS/GS), 但试图将空段选择子装入CS/SS会直接产生一个一般保护异常. 实际上所有段寄存器值默认初始化为0, 即空段选择子. 而虽然可以将空段选择子装载在数据段寄存器, 但任何试图通过值为空段选择子的段寄存器来访问段的操作都会产生一个一般保护异常. 利用这个特性可以很好地检测出对未使用数据段寄存器的访问.
GDT第0项的NULL描述符是不被使用的. 指向这个描述符的段选择子为空段选择子. 空段选择子可以被装载入数据段寄存器 (DS/ES/FS/GS), 但试图将空段选择子装入CS/SS会直接产生一个一般保护异常. 实际上所有段寄存器值默认初始化为0, 即空段选择子. 而虽然可以将空段选择子装载在数据段寄存器, 但任何试图通过值为空段选择子的段寄存器来访问段的操作都会产生一个一般保护异常. 利用这个特性可以很好地检测出对未使用数据段寄存器的访问. - IDT (Interrupt Descriptor Table): 中断描述符表, 保存保护模式下所有中断服务程序的入口地址, 类似实模式下中断向量表. 此时的中断服务程序不再是BIOS提供的, 而是操作系统提供的.
- 高版本Linux系统中每个进程独占一整个4G线性地址空间 (32位处理器最大可寻址空间), 因此不再需要LDT, 只需要使用GDT. 但同时一个页目录表不再足以维护所有进程的内存空间, 切换进程时需要同时切换页目录表, 即改变CR3值.

分页机制
若没有开启分页, 线性地址空间与物理地址空间之间为直接映射, 但在多任务计算系统中通常会定义一个比实际物理内存空间大很多的线性地址空间, 因此需要一些方法将线性地址空间虚拟化, IA32采用处理器的分页机制来实现.
分页机制支持的虚拟内存环境以较小的物理内存 (RAM, ROM) 及一些磁盘储存空间来模拟一个很大的线性地址空间. 分段机制的段通常与所保存的代码或数据结构的大小相同, 因此如果只使用分段进行地址转换则一个数据结构必须全部保存在物理内存中. 不同于此, 分页机制的页为固定大小 (通常为4KB大小), 因此启用了分页后一个数据结构可以部分在物理内存中, 部分在磁盘中.
如果被访问的页不在当前物理内存中, 处理器会产生一个页故障异常 (#PF) 并中断当前进程执行, 待页故障异常中断服务程序从磁盘上将这个页读取到物理内存后 (这个过程中可能有另一个页被从内存调到磁盘), 继续执行该进程.
- 页目录表: 一个页目录表放在一个4KB页中, 最多包含1K个页目录表项, 即记录1K个页表
- 页表: 一个页表存放于一个4KB页中, 最多记录1K个页 (当页的大小为2MB/4MB或更大时不使用页表, 此时页直接被记录在页目录表中)
- 页: 一个4KB/2MB或更大的连续地址空间
页目录表和页表必须存放于内存中
💡为了减少地址转换所使用的总线周期, 最近被访问过的页目录表项及页表项都被高速缓存在TLB (translation lookaside buffers, 转换后备缓冲区). TLB可以满足多数的读当前页目录表/页表的请求, 而不使用总线周期. 仅当所访问的页表不在TLB中时, 才需要额外的总线周期, 而这种情景通常只在访问一个很久不曾访问的页时才发生.
常用数值
- 1KB:
0X400 - 4KB:
0X1000($2^{12}$ ) - 1MB:
0X100000
操作系统授权体系的设计指导**
公理化操作系统
术语
-
亚里士多德的直言三段论
三段论是演绎推理中一种简单推理判断, 包含大前提, 小前提, 结论三部分. 全集为真则子集为真.
-
证明
由公理经由可靠的论证 (如三段论) 推出命题.
-
公理, 公设
公理是不证自明 (目前无法举出反例) 的一个命题, 是推导其他命题的起点. 在传统逻辑中, 公设是在一特定数学理论中的定义性的性质. 公设并不是不证自明的命题, 而是在构建一个数学理论的过程中被用来推导的一个形式逻辑表达式. 而在近代, 公理和公设不再有区别. 在一个公理化体系中所有其他命题都必须由公理证明.
-
科学
科学的范畴是可观察范围内, 科学的标准是可证伪 (因为无法直接获得真理, 科学无法证实). 而数学不可观察, 可证实 (基于公理), 因此不算在科学范畴内.
操作系统的内核
操作系统为什么一定要有内核
现代操作系统是多用户, 实时, 多任务的, 访问应当经过授权.
授权: 未经许可不得访问其他用户的资源.
- 用户: shell绑定的是用户, 包括文件, 进程, 外设等很多东西
- 资源: 包括主机上的 (数据, 代码, 进程), 外设 (显示器, 键盘等)
- 授权是面向访问的, 一项访问一项授权
- 授权有三要素: 用户, 操作, 数据 (一次访问所需信息至少包括这三项, 也可以有更多信息, 比如时间), 单独任意一项都无法完全限定一次访问的权限, 如授权A用户读取X文件的权限, 授权B用户读写X文件的权限.
操作系统应当尽可能赋予用户操作的自由, 因此用户代码会具有不确定性 (不确定会对什么数据/代码做什么), 为了保证所有访问都是经过授权的, 要求:
- 未经许可用户不得访问外设中自己的资源, 因为同一外设端口下可能有其他用户的资源 (比如同一硬盘中有多个用户的数据)
- 💡现有体系结构中访问外设有两种方式:
- IO指令: 较老, 新处理器中基本弃用这种方式. 禁止非特权用户使用, 剥夺普通用户IO能力
- MMIO (内存映射): 仅将合法资源映射到内存中用户能访问到的部分
- 💡现有体系结构中访问外设有两种方式:
- 同一用户两进程间不共享资源 (历史上先有程序概念后有用户概念, 为保兼容性, 权限管理以进程为单位而不是以用户为单位)
然而如此一来违背了"用户访问自己的资源无需授权"的设想, 因此引入一组由授权体系设计者实现的确定的程序, 即内核来代替用户完成访问. 此处的确定指访问的过程和对象都确定.
为什么要有特权级
💡相关文档在IA32手册4.5节
-
特权级建立在线性地址空间中的代码段上
- ==特权本质上是对访问的控制==
- 虚拟地址空间: CPU可访问地址空间, intel称线性地址空间
- 访问控制技术都是施加在线性地址层面的, 因此段的地址都是线性空间地址
-
一共有四种情况: (在只有两种特权级的系统中0特权级/3特权级也称内核态/用户态)
发起者 操作 对象 0特权指令 访问 0特权数据 0特权指令 跳转 0特权指令 3特权指令 访问 3特权数据 3特权指令 跳转 3特权指令 0特权指令直接跳转到3特权指令不被允许, 否则若特权级不变, 内核与应用程序就混淆起来了.
内核为什么一定要有结构
接续访问机制: 用户发起 -> 内核接续 (IO操作) -> 交付用户
-
内核是应用程序访问的延续, 所有访问都由应用程序发起
- 一次访问至少需要至少包含用户, 操作, 数据三项在内的各种信息
- 访问种类过多, 因此应当预先设定好一组服务
-
intel的门机制: 为确保由用户接续到内核过程中状态翻转的确定性, 要求指令确定, 跳转地址确定.
若跳转地址不确定, 可以直接跳转到内核函数代码段进行特权级操作. 返回的跳转地址也确定 (跳转指令的下一条)
接续访问的重要保障是能在内核态与用户态间借由一些硬件机制建起"一道墙" (进程管理信息数据结构), 确保用户态与内核态的隔离, 但内核可以借助这些机制"建墙"理论上用户就可以利用这些机制"拆墙". 这里利用时间的不可逆实现空间的不可逆. 由"拆墙需要为内核态, 想成为内核态需要先拆墙"互为必要条件锁死, 最先创建的用户会具有完全权限, 0特权级.
IA32的实现方式是将CR0寄存器的PE位置1, 将处理器切换到保护模式后就开启了分段机制, 而一旦进入保护模式就无法再关闭分段机制. 同样, CR0中PG位置1启用分页机制后也无法再关闭分页. (但分段和分页都可以在事实上关闭, 参见IA32手册4.1)
从开机到执行main的过程
从按下开机键到执行32位main函数分下面标题的三步准备工作. 准备工作完成后内存分布如图所示.

启动BIOS, 准备实模式下的中断向量表和中断服务程序
CPU的逻辑电路被设计为只能运行内存中的程序, 因此加电瞬间intel80x86系列CPU进入16位实模式, CS:IP被硬件强制置为0xFFFF0 (CS<<4+IP), 即BIOS程序此时在内存中的入口地址, 从而开始执行BIOS程序.
💡实模式有20位存储器地址空间, 即1MB内存可被寻址 (按字节), 按物理地址寻址.
站在操作系统角度BIOS最重要的功能就是==将操作系统最开始执行的程序 (通常是引导程序) 加载到内存并跳转执行, 从而进入操作系统自己的启动流程==. BIOS程序构建中断向量表, 加载中断服务程序, 然后硬件触发BIOS提供的中断int 0x19加载bootsect引导程序到内存中约定地址0X07C00 (BOOTSEG), 然后开始执行位于0X07C00的bootsect (对应boot/bootsect.s).
💡int 0x19的唯一作用就是将软盘第一扇区512B的内容复制到内存0X07C00处.
💡BIOS创建的中断向量表 (0X000000X003FF) 及加载的中断服务程序 (0x0E05B0X0FFFE) 在setup程序将120KB的system模块 (head程序及以main函数开始的内核程序) 复制至内存起始位置时被覆盖.
从启动盘加载操作系统程序到内存并为保护模式做准备

bootsect程序最主要作用是将setup程序和system模块加载到内存中. 上图中代码在内存中移动的一些解释:
- bootsect程序通过触发BIOS提供的中断
int 0x13将指定扇区内容加载到内存指定位置 (通过设置寄存器的值来传参) - bootsect程序一开始先将自己移动到
0X90000是因为当时system模块长度不会超过0X80000字节 (在Linux0.11中只有120KB), 因此从0X07C00移动到0X90000能保证bootsect程序不会被自己加载的system模块覆盖. - system模块一开始被bootsect程序加载到
0X10000而不是内存起始位置是因为只有使用BIOS提供的中断int 0x13才能从软盘读取system模块所在扇区, 使用指令无法操作外部设备, 而直接将system模块加载到内存起始位置会导致BIOS的中断向量表和中断服务程序被覆盖, 无法再加载system模块. 因此只能先将system模块加载至内存中别的地方, 再在关掉中断后用指令将system模块挪到内存起始位置.
setup程序在一开始利用BIOS提供的中断提取到了一些机器信息存放至内存0X90000~0X901FC, 基本覆盖了bootsect程序. 这之后就不再用到BIOS提供的中断服务程序, 甚至关闭中断, 覆盖掉了BIOS的中断向量表和中断服务程序.
为执行32位的main函数做准备
因为将system模块挪至内存起始位置会覆盖掉BIOS的中断向量表和中断服务程序, 为了避免问题setup程序先用cli将CPU的EFLAGS中中断允许标志 (IF) 置为0==关闭了中断==, 然后才将system模块挪至内存起始位置.
内核态与用户态的内存分页管理方式是不同的, 内核态的线性地址空间与物理地址空间是直接映射的, 内核可以直接获得物理地址, 而用户态线性地址与物理地址映射没有规律. 这样用户程序就无法根据线性地址推算对应物理地址, 使得内核能访问用户程序而用户程序无法访问其他用户的程序, 同时权限限制了用户程序无法访问内核内存空间 (其中是内核代码及数据).
设备环境初始化
进程不会直接读写硬盘, 而是读写的内存中的缓冲区, 而缓冲区与硬盘间有同步机制. 进程并不知道数据何时被写到硬盘.
每个进程有个用户栈, 也有个内核栈.
为了在线性地址层面分隔进程的内存空间, Linux0.11的策略是将4GB线性地址空间分为互不重叠的64等份 (每份64MB), 每个进程一份, 最多同时维护64个进程. 通过硬件禁止进程进行越界访问, 实现在线性地址层面对进程内存空间的保护.
所有进程的登记, 注销都在task[64]维护.

在进程0之前的内存是各种全局变量, 是内核的公共部分. 可以看作各个进程都可以向这里 (比如buffer_head) 读写.
进程0创建进程1
fork()中触发int $80软中断系统门前都是3特权, 这之后进入进程0的内核栈, 栈被硬件压到了内核栈, 这样到时候才能从进程0内核栈返回.
进程1的执行
硬盘读写缓冲的存在是为了快, 之所以能快是因为可能有多个进程对硬盘读写, 映射到内存的缓冲区能被复用. 如果没有被复用, 反而会更慢些. 因此缓冲区设计的核心有二:
- 追求高命中率, 这样才能最大程度复用. 通过==使已经进入缓冲区的数据停留尽可能久==实现
- 要求高一致性, 在进程的内存空间和硬盘之间多了一个缓冲区, 则要求缓冲区能与两者具有高一致性
从硬盘读取新的块一定是先在缓冲区建立对应的缓冲块, 然后从硬盘将数据读到缓冲块, 然后从缓冲区读到内存. 整个同步过程都加锁, 禁止进程读写
pause() -> int80 -> sys_pause() -> schedule() -> switch_to() -> ljmp行后切换进程, 或switch_to当前进程, 直接跳出. 切换到的进程一定是之前挂起, 停在了ljmp下一行
bread()
进程1在bread()中在执行ll_rw_block()调用内核读盘后会进入wait_on_buffer() , 在sleep_on()中尝试是否调度到其他进程. 如果还在等待硬盘, 进程1处于挂起状态, 此时再没有除了进程0的其他进程, 因此切到进程0, 循环for(;;){pause();}这段

写硬盘时改写需要缓冲块与硬盘块的一致性, 新写不需要一致性 (反正会覆盖掉硬盘块的内容)

等待队列
bread()中wait_on_buffer()里的bh->b_wait
两个进程在等同一个块, 则b_wait就是同一个.

中断的意义: 摆脱轮询, 允许切换到其他任务, 主动激励, 被动响应.
请求项的队列是一类设备在一个队列, 但是都在request列表
