


Easy-to-use word-to-word translations for 3,564 language pairs.
- A large collection of freely & publicly available word-to-word translations for 3,564 language pairs across 62 unique languages.
- Easy-to-use Python interface.
- Constructed using an efficient approach that is quantitatively examined by proficient bilingual human labelers.
First, install the package using pip:
pip install word2wordAlternatively:
git clone https://github.com/Kyubyong/word2word.git
python setup.py install
Then, in Python, download the model and retrieve top-k word translations of any given word to the desired language:
from word2word import Word2word
en2fr = Word2word("en", "fr")
print(en2fr("apple"))
# out: ['pomme', 'pommes', 'pommier', 'tartes', 'fleurs']
print(en2fr("worked", n_best=2))
# out: ['travaillé', 'travaillait']
en2zh = Word2word("en", "zh_cn")
print(en2zh("teacher"))
# out: ['老师', '教师', '学生', '导师', '墨盒']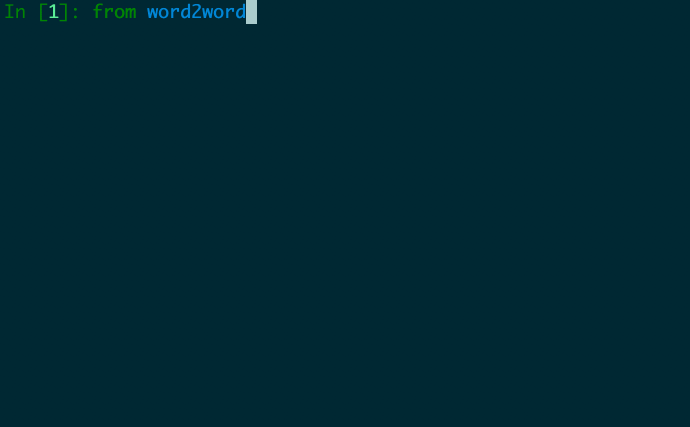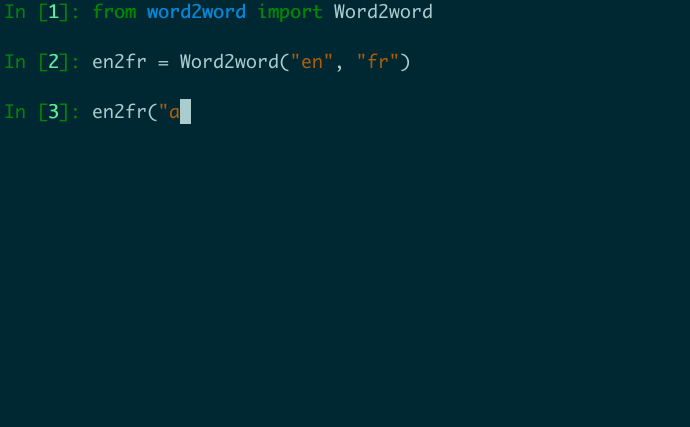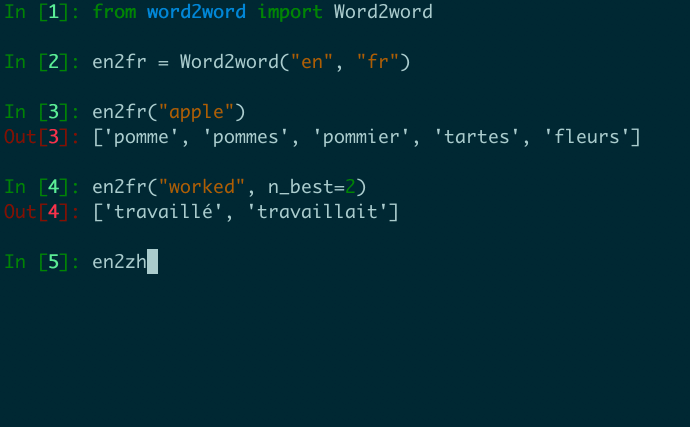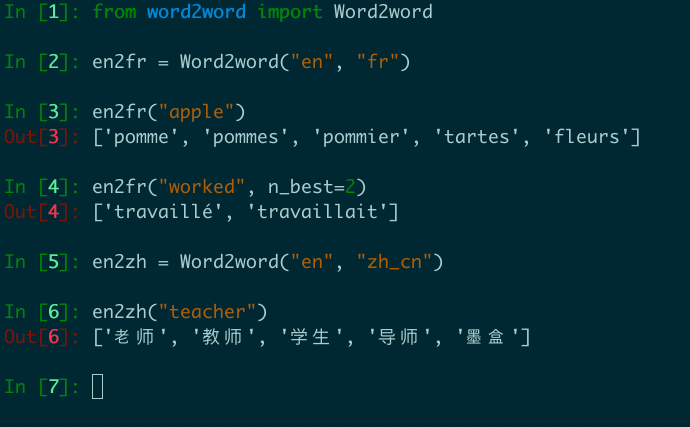
We provide top-k word-to-word translations across all available pairs from OpenSubtitles2018. This amounts to a total of 3,564 language pairs across 62 unique languages.
The full list is provided here.
Our approach computes the top-k word-to-word translations based on the co-occurrence statistics between cross-lingual word pairs in a parallel corpus. We additionally introduce a correction term that controls for any confounding effect coming from other source words within the same sentence. The resulting method is an efficient and scalable approach that allows us to construct large bilingual dictionaries from any given parallel corpus.
For more details, see the Methods section of our paper draft.
A popular publicly available dataset of word-to-word translations is
facebookresearch/MUSE, which
includes 110 bilingual dictionaries that are built from Facebook's internal translation tool.
In comparison to MUSE, word2word does not rely on a translation software
and contains much larger sets of language pairs (3,564).
word2word also provides the top-k word-to-word translations for up to 100k words
(compared to 5~10k words in MUSE) and can be applied to any language pairs
for which there is a parallel corpus.
In terms of quality, while a direct comparison between the two methods is difficult, we did notice that MUSE's bilingual dictionaries involving non-European languages may be not as useful. For English-Vietnamese, we found that 80% of the 1,500 word pairs in the validation set had the same word twice as a pair (e.g. crimson-crimson, Suzuki-Suzuki, Randall-Randall).
For more details, see Appendix in our paper draft.
If you use our software for research, please cite:
@misc{word2word2019,
author = {Park, Kyubyong and Kim, Dongwoo and Choe, Yo Joong},
title = {word2word},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Kyubyong/word2word}}
}(We may later update this bibtex with a reference to our paper report.)
All of our word-to-word translations were constructed from the publicly available OpenSubtitles2018 dataset:
@article{opensubtitles2016,
title={Opensubtitles2016: Extracting large parallel corpora from movie and tv subtitles},
author={Lison, Pierre and Tiedemann, J{\"o}rg},
year={2016},
publisher={European Language Resources Association}
}Kyubyong Park, Dongwoo Kim, and YJ Choe