卡卡字幕助手(VideoCaptioner)是一款功能强大的视频字幕配制软件。操作简单且无需高配置,利用大语言模型进行字幕智能断句、校正、优化、翻译,字幕视频全流程一键处理!为视频配上效果惊艳的字幕。
- 🎯 无需GPU即可使用强大的语音识别引擎,生成精准字幕
- ✂️ 基于 LLM 的智能分割与断句,字幕阅读更自然流畅
- 🔄 AI字幕多线程优化与翻译,调整字幕格式、表达更地道专业
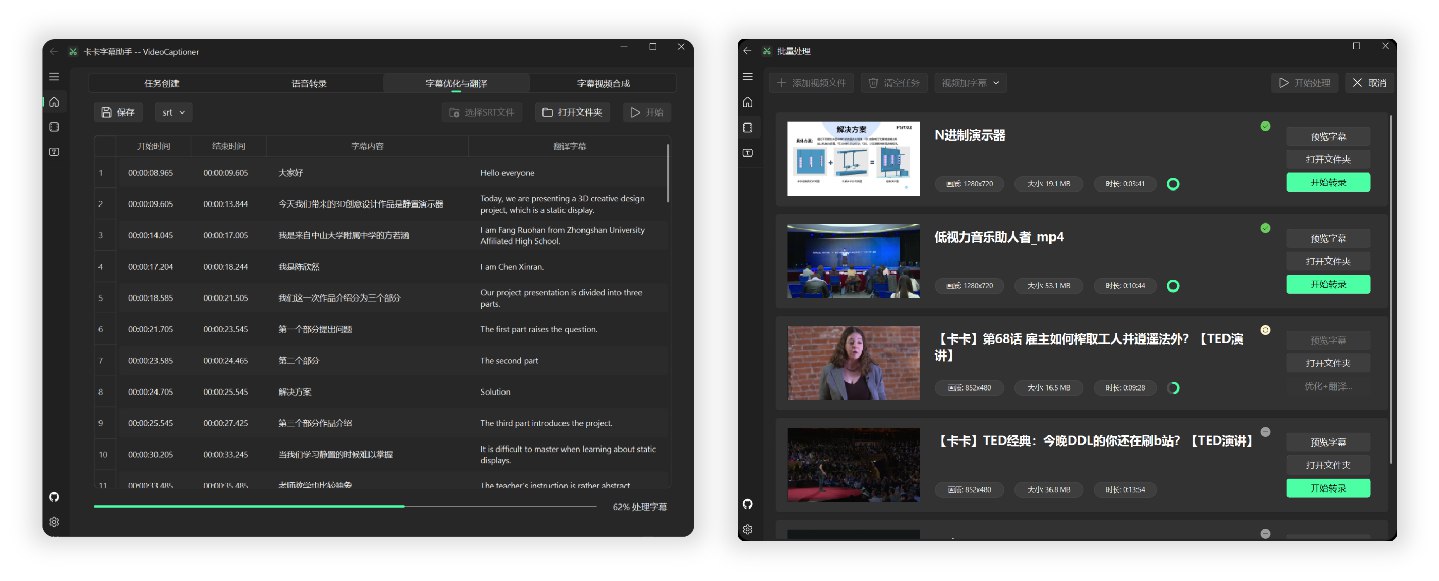
- 🎬 支持批量视频字幕合成,提升处理效率
- 📝 直观的字幕编辑查看界面,支持实时预览和快捷编辑
- 🤖 消耗模型 Token 少,且内置基础 LLM 模型,保证开箱即用

软件较为轻量,打包大小不足 60M,已集成所有必要环境,下载后可直接运行。
-
解压后直接运行
VideoCaptioner.exe -
(可选)LLM API 配置,选择是否启用字幕优化或者字幕翻译
-
拖拽视频文件到软件窗口,即可全自动处理
提示:每一个步骤均支持单独处理,均支持文件拖拽。
MacOS 用户
由于本人缺少 Mac,所以没法测试和打包,暂无法提供 MacOS 的可执行程序。
Mac 用户请自行使用下载源码和安装 python 依赖运行。
- 安装 ffmpeg
brew install ffmpeg- 克隆项目
git clone https://github.com/WEIFENG2333/VideoCaptioner.git- 安装依赖
pip install -r requirements.txt- 运行程序
python main.py软件充分利用大语言模型(LLM)在理解上下文方面的优势,对语音识别生成的字幕进一步处理。有效修正错别字、统一专业术语,让字幕内容更加准确连贯,为用户带来出色的观看体验!
- 支持国内外主流视频平台(B站、Youtube等)
- 自动提取视频原有字幕处理
- 提供多种接口在线识别,效果媲美剪映(免费、高速)
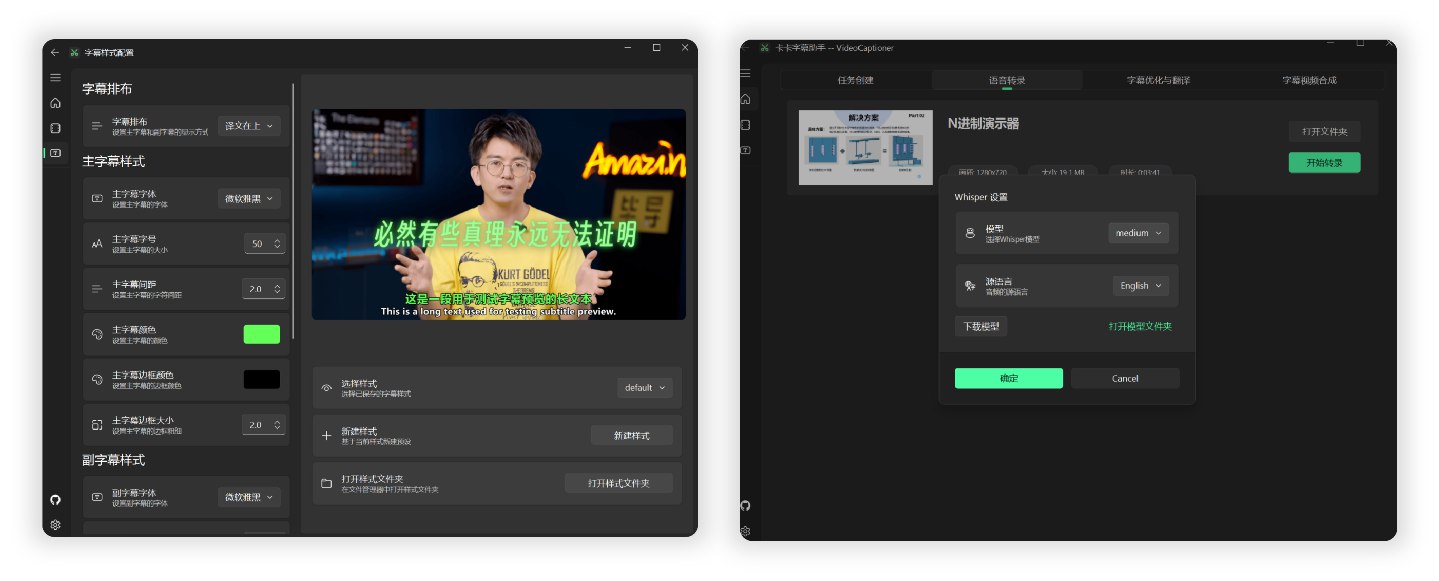
- 支持本地Whisper模型(保护隐私、可离线)
- 自动优化专业术语、代码片段和数学公式格式
- 上下文进行断句优化,提升阅读体验
- 结合上下文的智能翻译,确保译文准确自然
- 通过Prompt指导大模型反思翻译,提升翻译质量
- 使用序列模糊匹配算法、保证时间轴完全一致
- 丰富的字幕样式模板(科普风、新闻风、番剧风等等)
- 多种格式字幕视频(SRT、ASS、VTT、TXT)
- 软件内置基础大语言模型(
gpt-4o-mini),无需配置即可使用。但为获得更好的效果,建议在设置中配置个人 API。 - 支持标准 OpenAI API 格式(兼容通义千问、DeepSeek 等)请自行配置。【招租】
- 追求更高质量可选用
Claude-3.5-sonnet或gpt-4o
- 下载模型:
Tiny,Base,Small,Medium,Large-v1,Large-v2 - 中文识别推荐使用
Medium及以上版本,以确保识别质量
- 主副字幕设置:字体、大小、颜色、边框样式、行距、位置等
- 排版方式:原文在上、译文在上、仅原文、仅译文
程序完整的处理流程如下:
语音识别 -> 字幕生成 -> 字幕优化翻译(可选) -> 字幕视频合成
-
字幕断句的质量直接影响观看体验。我开发了 SubtitleSpliter 项目智能识别句子边界并进行合理分段。将逐字字幕重组为符合自然语言习惯的段落,确保与视频画面完美同步,显著提升观看体验。
-
为提升性能,向大语言模型发送的字幕数据仅包含文本内容,不含时间轴信息,大幅降低模型处理开销。对于返回的结果与原内容进行序列模糊匹配,确保最终得到的时间轴完全一致。
-
翻译过程使用吴恩达的“翻译-反思-翻译”方法,保证了良好的翻译结果和语言表达习惯。
作者是一名大三学生,个人能力和项目都还有许多不足,项目也在不断完善中,如果在使用过程遇到的Bug,欢迎提交 Issue 和 Pull Request 帮助改进项目。